
Data Lake Archival Strategy for Cost-Efficient Cloud Storage
Introduction
At Halodoc, we use AWS’ Simple Cloud Storage (S3) to store our raw, processed, and backup, as well as the source for the bulk load into our data warehouse (for more details on our architecture, please refer to this blog). S3 offers a low-cost storage solution that is highly available (data is always accessible), highly durable (if something goes wrong, like a hardware failure or a disaster, the data remains safe and accessible) and low latency (minimum delay in data retrieval). These are promising features as we hope to make data easily accessible for our users. However, as the business grows, data will accumulate over time at an accelerated rate. As data engineers, it is also our task to make sure our storage is cost-efficient.
Evaluating the value of data
As our data keeps growing, there is a need to evaluate the value of our data. In data engineering, the value of our data is synonymous to its usefulness to deliver actionable insights for business or operational analytics. In most cases, the main factor is its recency as newer data becomes indicators for future strategies. This leads to the categorisation of data into two broad types, hot and cold data. Some data, crucial for immediate decision-making, is accessed frequently ("hot" data). Other data, needed for backup but rarely accessed, is considered "cold" data. They can be stored under different configurations to reduce storage costs.
Even though the S3 storage cost is relatively low, there is always room for improvement. We started evaluating our data and assessed that our raw layer, which stores CDC files from AWS DMS (Data Migration Service) in the form of parquet and JSON files, is rarely accessed after they are processed. This is especially true when compared to the processed layer, which contains raw layer files that had been read and written in a Hudi format and is actively used for the data warehouse layer. Therefore, we decided to move the raw layer to a colder storage and store the objects as backups as we no longer require them soon.
Cold to Freezing Storage in AWS
AWS S3 offers multiple storage classes depending on the data usage behaviour.
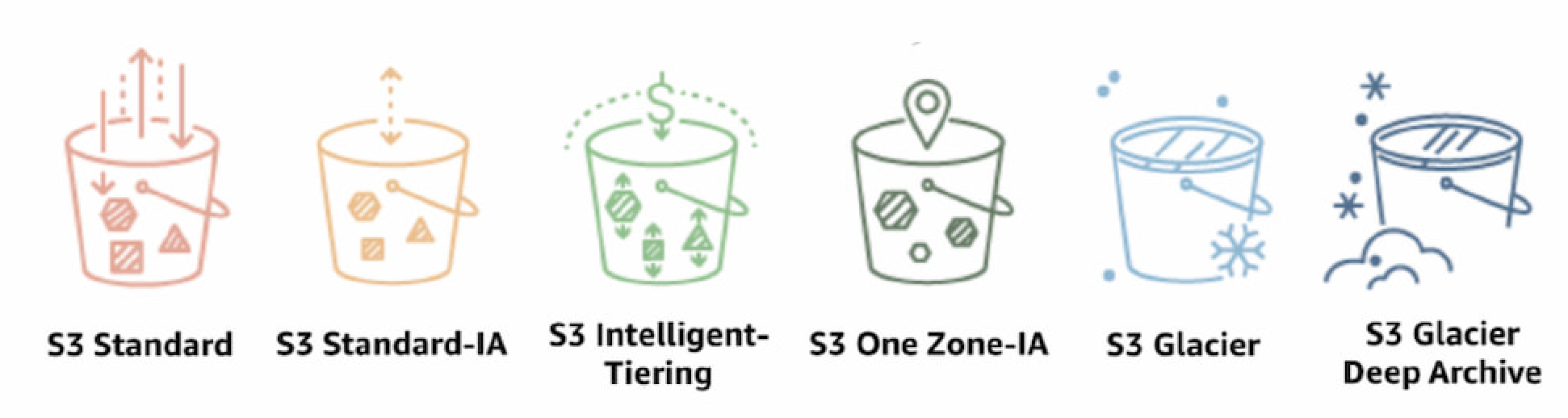
By default, all the objects in S3 are stored in S3 standard. Details on S3 pricing can be found on AWS’ website, but in summary, standard storage incurs no additional fee and only storage and API calls will be charged. Other storage classes offer cheaper storage fees but will charge for early deletion and retrieval fees. In the case of S3 Standard Infrequent Access (Standard-IA), S3 One Zone-IA, S3 Intelligent-Tiering and S3 Glacier (now Glacier Instant-Retrieval by default), there is no delay in retrieving the data, but only S3 Intelligent-Tiering is free from retrieval fee. The rule of thumb is that the cheaper the cold storage, the higher the retrieval fee. However, deletion incurs no charge after 30 days of storage for S3 Standard-IA and S3 Glacier; the full 30 days of storage cost will be billable.
Moving Objects from Standard Storage
AWS provides an automated method called lifecycle retention policy to move the objects from one storage class to another and this can be configured for each bucket. This will be applied bucket-wide unless filtered for a specific prefix, object tag or object size. It could move objects from the Standard class to any other storage class or permanently delete objects after a certain number of days. It is important to note that this policy can only be used to transition singular files that are bigger than 128KB (it has no such restriction for permanent deletion). This restriction for transition also does not apply to “manual” transitioning using boto3 copy_object. However, any file smaller than 128KB stored in Standard-IA, One Zone-IA, or Glacier Instant Retrieval will still be charged a full 128KB, which can be costly if there are a lot of small files.
Our Approach
In Halodoc, these are the conditions that determine our strategy:
Data in the raw layer is cold but necessary for backup, specifically the incremental files.
This is especially important in the case of column type change. By having the raw parquet files, we can use the raw files to rewrite all the Hudi files to prevent column mismatch between files. By storing the files, we also keep all the columns available for a particular table even though those columns are not used in the processed layer.
Plenty of small files.
Due to CDC, we have a large number of files smaller than 128KB. As mentioned previously, this means we can not use the lifecycle retention policy to transition these small objects to a different storage class.
Considering these conditions, we chose to zip the files in the raw layer and store them in a backup folder. Zipping and compressing the files helps us reduce the number of files and get them over the 128KB file size limit for cheaper storage classes.
- Zipping is done either at the month-level or day-level of a specific table.
- After zipping, the zip file is then uploaded onto S3 as a Standard-IA object.
- Individual files that are already zipped are then deleted from S3.
Pipeline Components
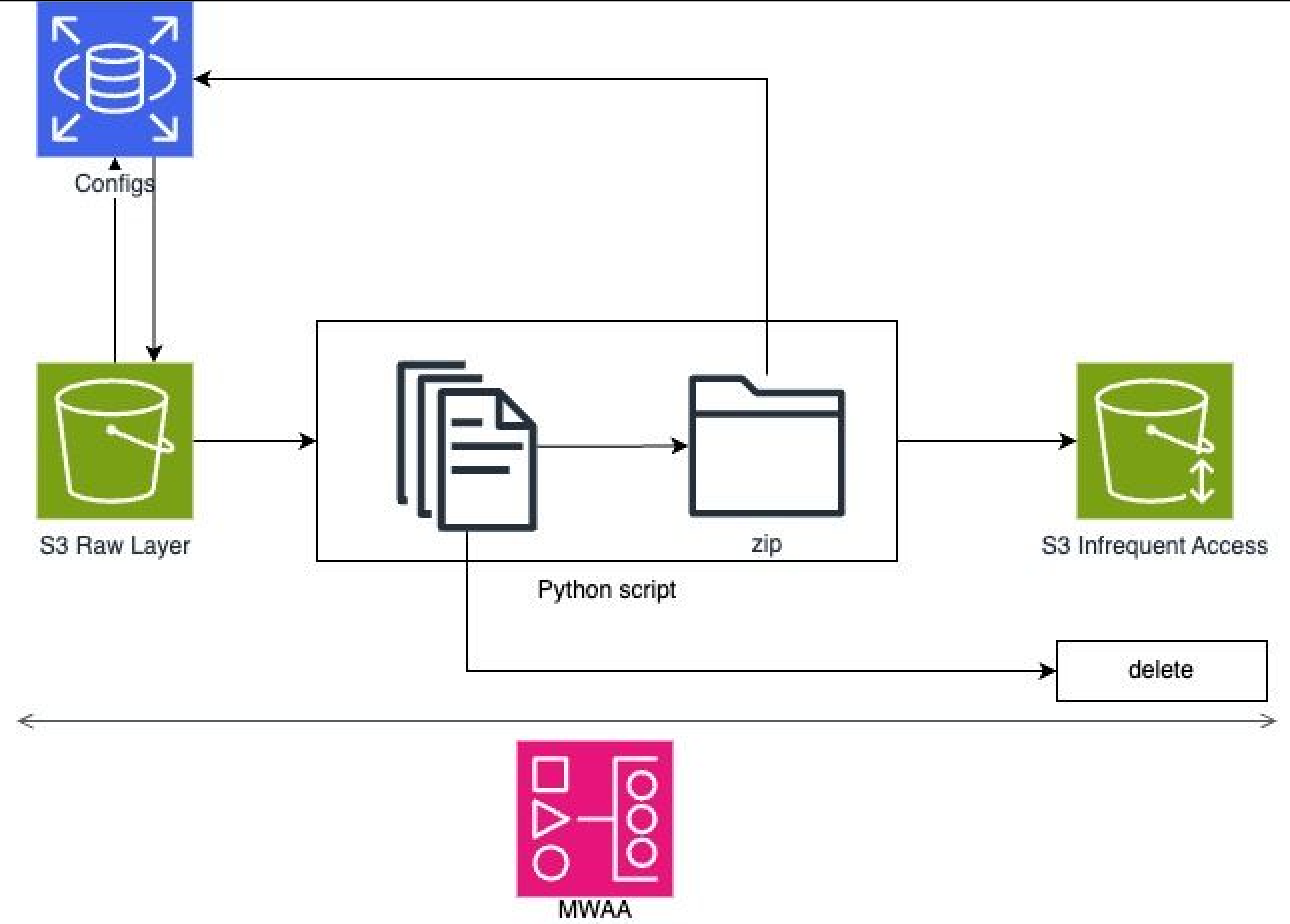
This diagram shows the components of the pipeline and how they interact with each other. Details as follows:
1. MWAA
- The processes mentioned above were all done in Amazon Managed Workflows for Apache Airflow (MWAA), utilising its computing and storage capacity.
- Files to be uploaded are first downloaded into MWAA’s local storage and then uploaded.
2. Config (Control Plane)

- The zipping process refers to config tables stored in RDS. This is mainly used to keep records of the paths, size, compression status, the names of the zip files, and existing raw layer table names (possible targets). This config table also stores the date when the table is inserted/updated. Above is a sample data of this config table.
3. S3
- This process takes the input of an S3 path and path level.
- It will zip existing files in S3, upload the zip and then delete the successfully zipped files.
- The path level determines if the files are going to be zipped at month level or day level.
4. Zipping script
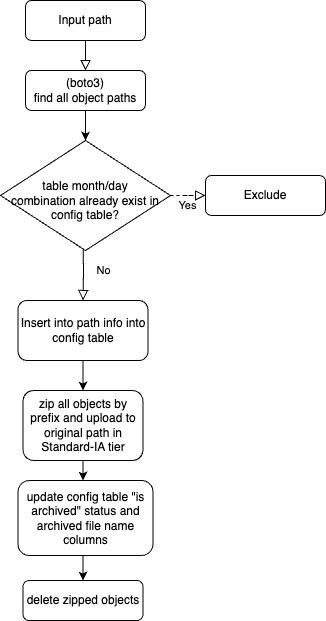
- This diagram above shows the flow of the Python script that processes the files in details:
- We use the threading operator provided by concurrent.futures to improve the concurrency when downloading and deleting files.
- Boto3 is used in the script to list files that follow the pattern of the month or day path, upload objects to S3 for the zip files, and delete objects.
5. DAG
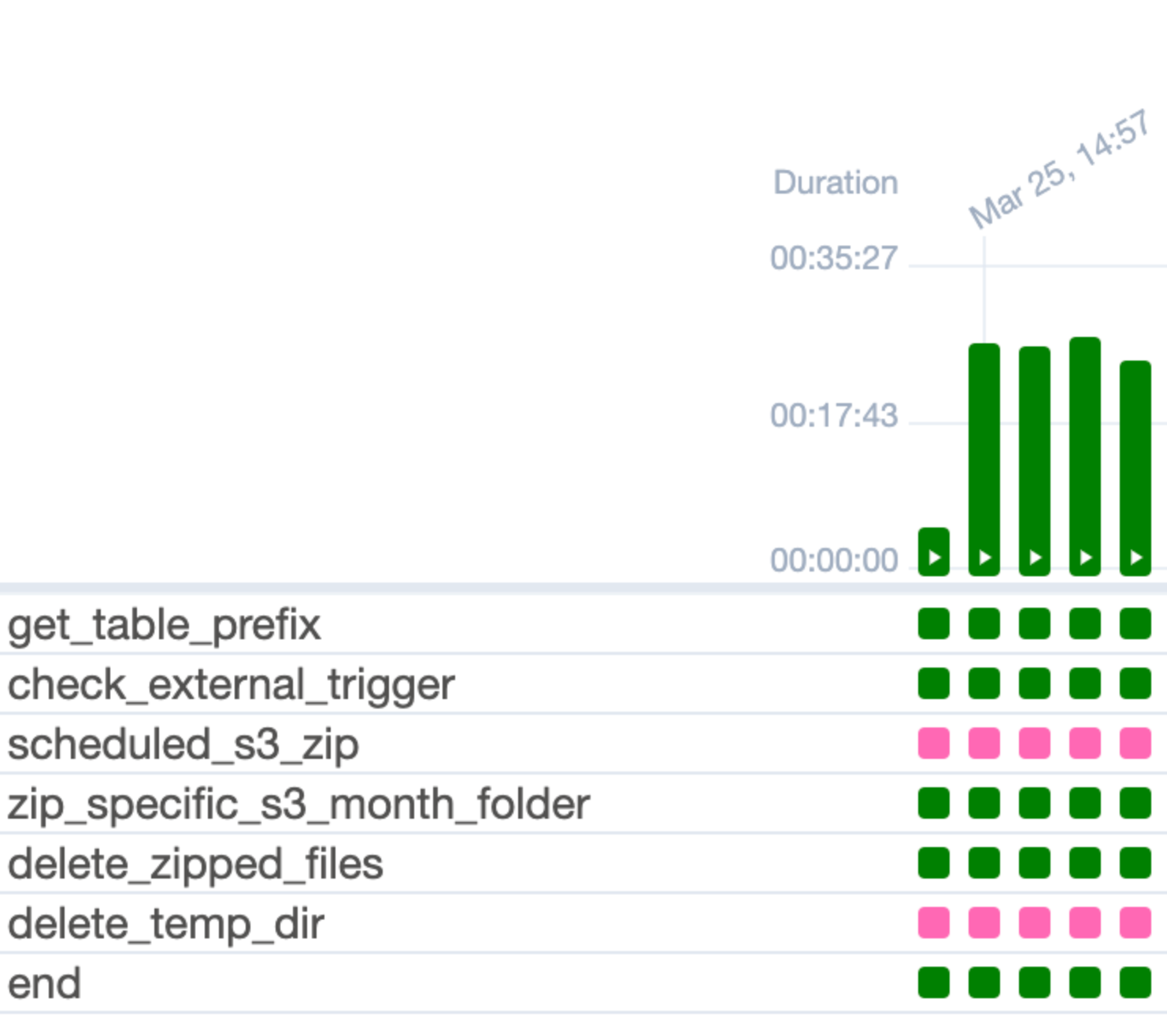
- In the DAG, we separate a few tasks that take longer and might be dangerous to retry, namely remnants of the zipped files in S3.
- In the case of an out-of-memory error during zipping, there is a separate task which clears the temporary directory stored in the local MWAA machine to prevent unrelated files from being zipped together in the next run. We found that out-of-memory errors will result in the task exiting and will be missed by the try-catch in the zipping function.
Unarchiving
We have also prepared a pipeline for data recovery from this archive. This works very similarly with the zipping process.
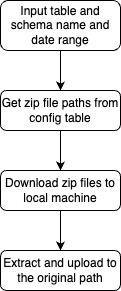
1. It checks the existence of archived zip files in the config table based on some parameters:
- Table name
- Schema name
- Start date - of desired files to recover
- End date
2. Extract and download the individual files inside the zip into a local machine.
3. Upload back onto S3 as Standard objects.
Once the files are accessed, they could be deleted again, and because they are Standard objects, there will be no additional fee.
Further Enhancements
1. Running this job in EMR on EC2
- Prevent jobs from failing due to MWAA’s limited memory and storage. Only some of our incremental data in the raw layer are archived and the rest will be run on EMR.
- Moving the job to EMR might require some consideration on modifying the tasks, e.g. combining zipping and clearing the temporary directory from the local machine.
2. Threading
- Incorporate parallelism to improve the speed of the unarchiving (unzipping) job. This could be applied to file extraction and uploading the files back to the desired S3 path.
3. Enable the scheduled jobs
- Once all of the older data are archived, we will enable scheduled jobs to run, which will be made possible by using another config table which stores all of the paths for different raw layer tables and the archival config table to check whether the files have been archived.
Conclusion
As the data grows, the need to reduce storage costs also becomes more important. This could be easily achievable by identifying data that have low value, or cold data, and moving it to cold storage or deleting it permanently. Thankfully, AWS has several cost-efficient options for cold storage, but we have to be aware of all of the additional costs and rules that apply. In Halodoc, we have begun to take this step of storing more efficiently by archiving our cold data in our raw layer in the form of compressed files. So far, we have been able to reduce the storage cost in our raw layer by 30%.
Join us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. We recently closed our Series D round and In total have raised around USD$100+ million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.