

Reducing LLM Token Costs by 15% by Switching from JSON to TOON Format
Introduction
At Halodoc, LLMs power multiple high-volume healthcare workflows - from clinical decision support and document processing to intelligent routing and classification. Scaling these AI capabilities responsibly means keeping a close eye on efficiency, and one of the biggest levers we found was in how we format the data we send to models.
Token usage directly drives LLM spend, and we discovered that a significant chunk of those tokens was being consumed not by meaningful content, but by the structural overhead of JSON. After evaluating alternatives, we adopted TOON (Token-Oriented Object Notation) - a token-efficient serialisation format - across multiple production AI services. The result: upto 15% overall cost savings across migrated use cases - achieved by optimising input tokens alone, with no degradation in response quality.
This post covers what TOON is, how it compares to alternatives, the SDK and migration approach, and practical lessons from rolling it out.
The Challenge: JSON's Hidden Token Tax
LLMs price requests by tokens. A token is roughly 4 characters in English, but the actual cost depends heavily on how we structure our data. JSON is the default serialisation format for passing structured data to and from LLMs. It's universal, well-understood, and supported everywhere. But it's also verbose - braces, brackets, quoted keys, commas, and deeply nested formatting all consume tokens that carry no semantic value.
Consider a simple patient record:
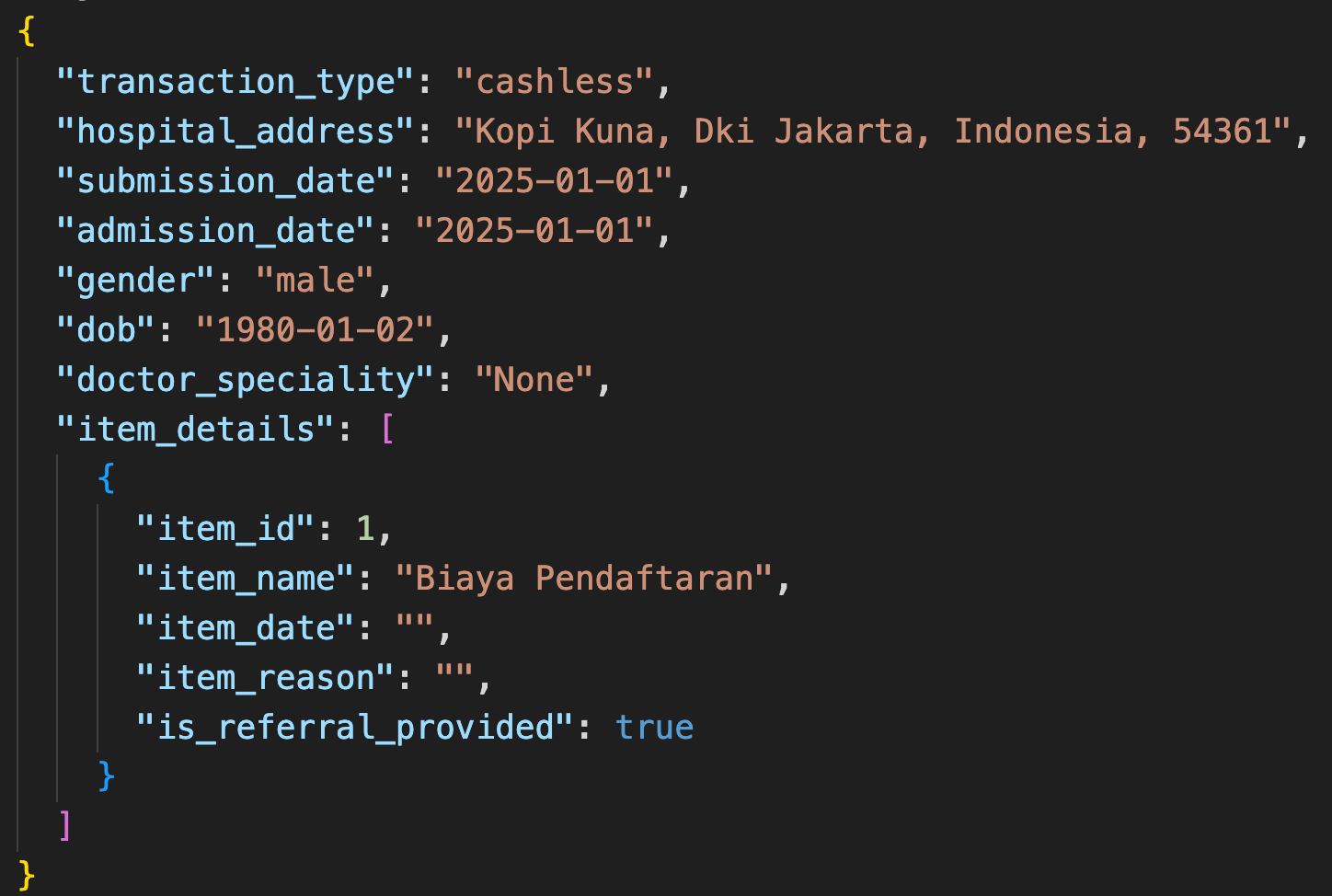
Every quoted key, every brace, every comma is a token the LLM has to process - but none of it adds information the model actually needs to reason about. Across millions of weekly requests, this adds up fast.
The impact is threefold: it increases cost (you pay per token), adds latency (more tokens mean longer processing), and reduces the effective context window (fewer tokens left for actual content).
We set out to find a leaner alternative that could cut costs and latency without compromising the quality of LLM responses.
Why TOON? Alternatives We Considered
Before settling on TOON, we evaluated four serialisation formats as alternatives to JSON for LLM data exchange. The evaluation was analytical - we scored each format across token efficiency, LLM compatibility, implementation effort, human readability, and ecosystem maturity.
Here's a summary of how they compared:
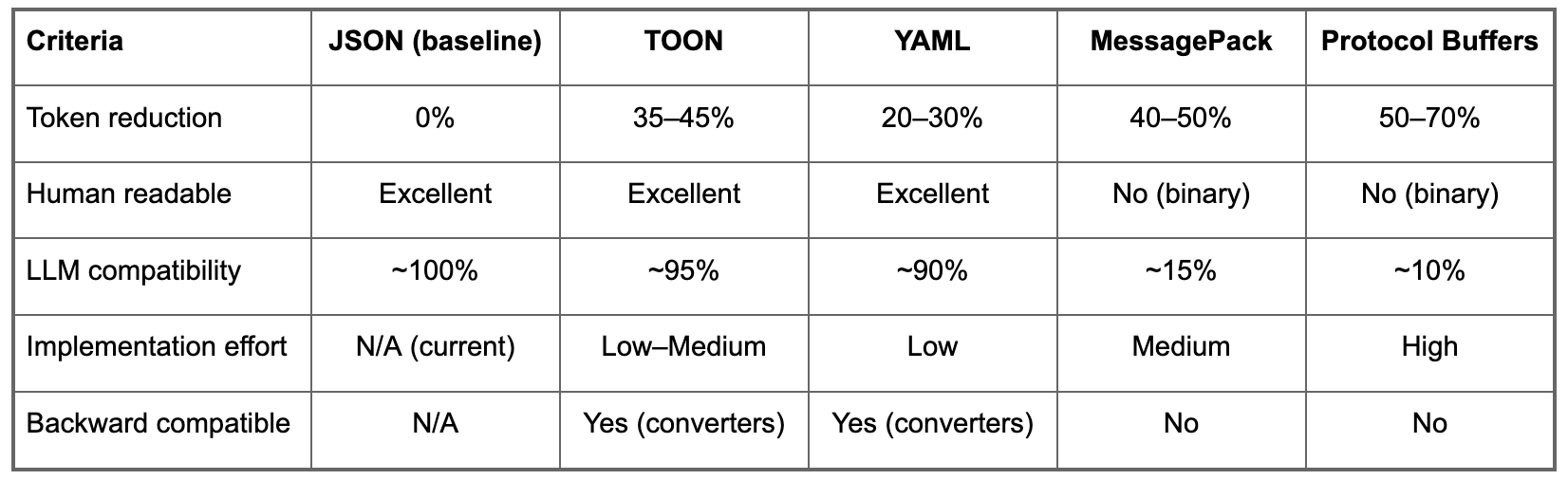
MessagePack and Protocol Buffers offer the highest raw compression (40-70% fewer tokens), but they produce binary output that LLMs cannot read directly. Encoding them as base64 strings for LLM consumption negates most of the size benefit and drops LLM comprehension to 15-25% accuracy. They also require significant integration effort with no backward compatibility.
YAML is human-readable and easy to integrate, but it only reduces tokens by 20-30%. It still quotes strings liberally and doesn't address the core problem - repeated keys in arrays of objects - which is where most of our token waste lives.
TOON offered the best balance. It delivers 35-45% theoretical token reduction while remaining human-readable and achieving ~95% LLM compatibility across providers (OpenAI, Anthropic, Google, AWS Bedrock). Implementation effort is low-to-medium: it integrates with Jinja2 templates, works with Pydantic models via a thin wrapper, and is backward-compatible through converters - meaning we can adopt it incrementally without rewriting existing pipelines. It also has a public specification and benchmark suite.
In our weighted scoring, JSON naturally scored highest overall (4.1/5) because it's the established default with full ecosystem support. But among alternatives, TOON scored 4.0 - significantly ahead of YAML (3.3), Protocol Buffers (2.4), and MessagePack (2.1). The gap between TOON and JSON is almost entirely due to ecosystem maturity; on the criteria that matter for cost optimisation - token efficiency and LLM compatibility - TOON scored higher. That made it the clear choice for our specific problem.
What is TOON?
TOON (Token-Oriented Object Notation) is a simple, token‑efficient format designed specifically for LLM consumption. It strips away the syntactic noise of JSON while preserving structure through indentation and minimal delimiters.
The above patient record in TOON looks like this:
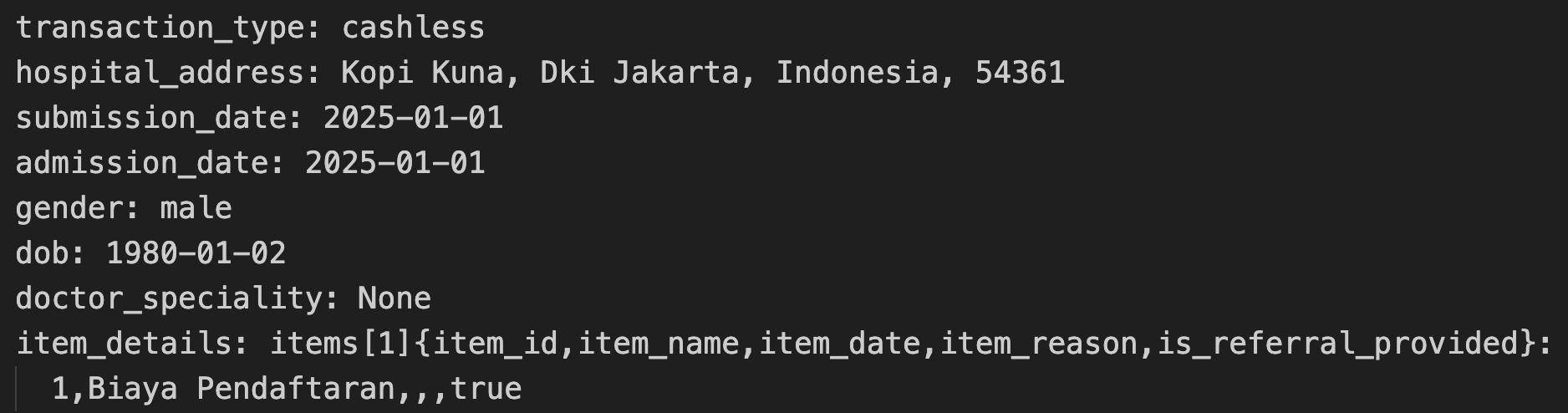
The key design choices in TOON are:
- No braces for objects - structure is conveyed through indentation and key-value pairs on separate lines.
- No quotes around keys or string values (unless they contain special characters).
- Arrays of objects (a very common pattern in our data) are represented as a table header followed by CSV-style rows, eliminating repeated key names across every item.
- Empty values are simply omitted or left blank, rather than being spelled out as
""ornull.
This approach is particularly effective for the kind of data we deal with at Halodoc: structured records with many fields and arrays of homogeneous items, like invoice line items, eligibility rules, etc.
Evaluating TOON: Pre-Migration Analysis
TOON optimisation applies to the message contents sent inside LLM API calls - the prompt data and structured responses. The outer JSON envelope required by LLM API protocols (OpenAI, Bedrock, etc.) cannot be changed. With this in mind, we evaluated TOON across production use cases spanning OpenAI and AWS Bedrock, covering a range of models (GPT-4.1, GPT-5-mini, GPT-4o, Amazon Nova Pro, Amazon Nova Lite, and a GPT-OSS-120B model on Bedrock).
For each use case, we measured token reduction, output token reduction (via POC), cost savings, p95 latency change, and response quality.
Results at a Glance
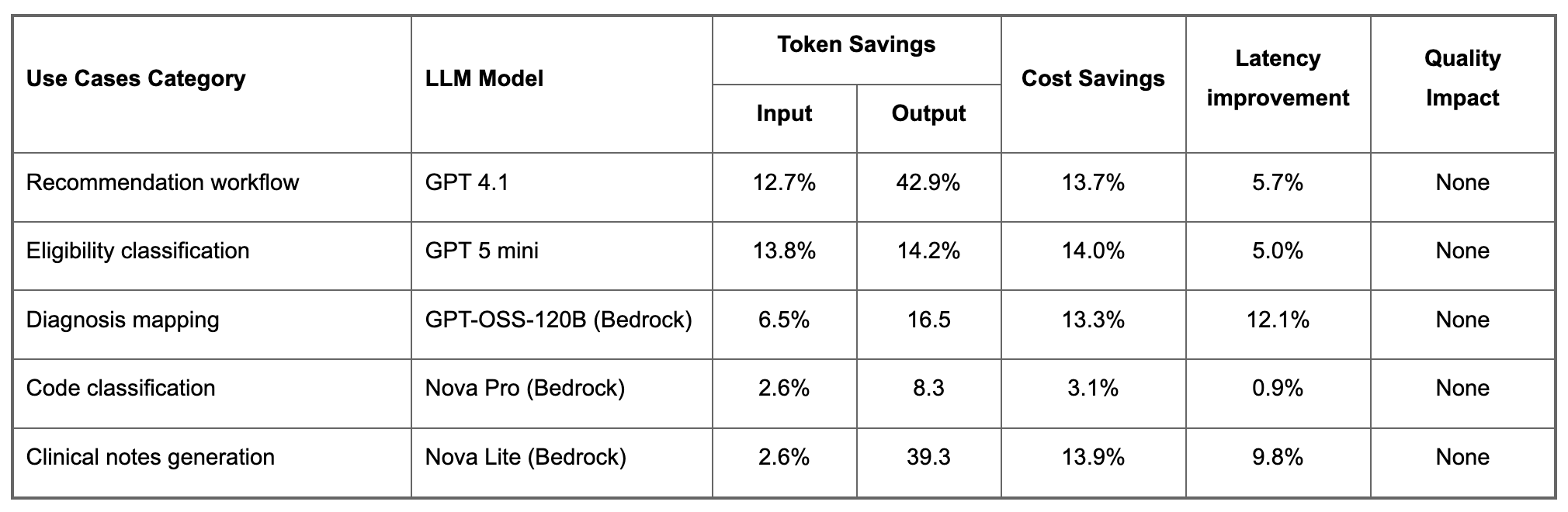
Not all use cases benefited equally. Use cases where prompts were dominated by free-text instructions or non-JSON content (such as base64-encoded images) showed minimal or no input token savings. In one OCR-related use case, input tokens actually increased slightly because TOON format instructions added overhead that exceeded the savings. These use cases were kept on JSON.
How We Validated Quality
To verify that TOON input didn't degrade LLM response quality, we ran each use case through its existing accuracy evaluation pipeline - comparing TOON-input responses against the JSON-input baseline on the same test data. For classification workflows, this meant measuring precision and recall against ground-truth labels. For generation use cases, we manually reviewed a sample of outputs for correctness and completeness. Only use cases that matched or exceeded baseline accuracy were approved for migration.
Key Takeaways from the Evaluation
What drives the input savings variance? The input token reduction depends on what fraction of the prompt is structured JSON data versus free-form natural language. TOON only compresses the structured portions - instructions and context written in plain English are unaffected.
The eligibility classification workflow showed 13.8% savings because its prompt includes large JSON payloads of eligibility rules and item details - arrays of objects with repeated keys, which TOON compresses aggressively. Use cases with prompts dominated by natural language showed only 2-3% savings.
Rule of thumb: If structured data (JSON objects, arrays of records) makes up a large portion of your prompt, expect double-digit input savings. If the prompt is mostly text with a few embedded values, expect low single-digits or none.
Output savings are possible, but we chose not to adopt them yet. During the POC, we tested instructing models to return responses in TOON format via prompt engineering. Results were promising: one use case showed 42.9% output reduction, and models like GPT-4.1, GPT-5-mini, and Amazon Nova produced well-formed TOON output consistently. However, we decided to keep JSON for output in production for now - JSON output is universally supported by downstream parsing, logging, and monitoring tools. Our config-flag architecture means we can enable TOON output per use case in future when needed.
The path to enabling output optimisation is straightforward - the SDK already includes a TOON-to-JSON parser, and the config-flag architecture supports independent output toggling per use case. In the POC, output token reductions ranged from 8% to 43%, with the highest savings on use cases returning structured data (classification results, mapped codes, tabular responses). Once enabled, this would add a meaningful additional layer of savings on top of the input-side gains already in production. We plan to pilot TOON output on select high-volume classification use cases as the next step.
LLMs had no trouble understanding TOON input. Even with nested data up to 3 levels deep, models parsed TOON correctly and maintained response accuracy.
External benchmarks corroborated our findings. The TOON format benchmark showed that across models like Claude Haiku 4.5, Gemini 2.5 Flash, GPT-5-nano, and Grok-4, TOON matched or slightly improved accuracy compared to both standard and compact JSON.
Where TOON Helps (and Where It Doesn't)
Based on our evaluation, here's where TOON makes sense and where it doesn't:
✅ Good fit:
- Structured input data embedded in prompts (arrays of objects, key-value maps).
- Example payloads included in few-shot prompts.
- High-volume, repetitive prompt patterns where both the data source and prompt template are controlled.
- Pipelines where a simple pre-processing step can be added before the LLM call.
❌ Not helpful:
- Prompts that are mostly free‑form natural language with few structured fields.
- Use cases where input data is predominantly non-JSON (e.g., base64-encoded images for OCR).
- Deeply nested structures where compact JSON may use fewer tokens than TOON's indentation.
- Lower-capability models that struggle to follow non-JSON formatting instructions.
⚠️ Limitation
TOON is not yet widely adopted as an industry standard. If you need to share prompts with external partners or maintain compatibility with tooling that expects JSON, keep that in mind. For internal pipelines, however, it's a practical optimisation.
Building the SDK: JSON ↔ TOON Converters
To avoid duplicating conversion logic across services, we built a shared Python SDK as part of our internal commons package. The SDK provides two core modules:
JSON-to-TOON Converter
The converter takes a Pydantic model (or a plain dict) and produces a compact TOON string. It handles scalars, nested objects, and, critically, arrays of objects using the tabular format.

The key optimisation is in how arrays of objects are serialised. Instead of repeating every key for every item:

The converter produces a table header and CSV rows:
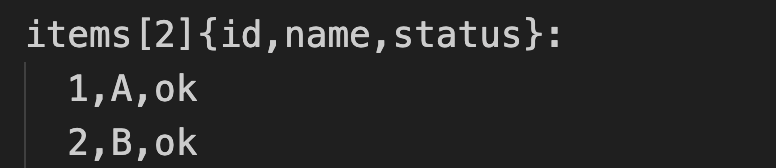
This is where the biggest token savings come from in practice; every repeated key across every row is eliminated.
Values that contain delimiter characters (colons, braces, commas, quotes, newlines) are automatically quoted to preserve parseability:

TOON-to-JSON Parser
The SDK also includes a reverse parser for converting TOON back to structured data. It reads table headers to determine column names, processes rows using a CSV reader, and supports both Pydantic-annotated type coercion and heuristic-based detection. This is built and available for future use with TOON-formatted LLM output.
Error Handling and Fallback
TOON is an optimisation layer, not a hard dependency. If it fails, the system must degrade gracefully.
Input side: TOON conversion happens before the LLM call. If the converter throws an exception (e.g., unexpected data shape), the system catches it and falls back to standard JSON serialisation. The LLM call proceeds normally - just without the token savings. This is logged as a warning for investigation.
Output side: For future TOON output adoption, the parser will fall back to standard JSON parsing if TOON parsing fails.
Config-based revert: TOON is enabled via per-use-case configuration flags (separate for input and output). Any use case experiencing issues can be reverted to JSON instantly by flipping a flag - no code deployment required.
Migrations in Practice
We have migrated multiple AI agents and direct LLM API calls to use TOON input format in production. Here's how we approached it.
Config-Driven Format Selection
Rather than a hard cutover, we implemented TOON adoption through separate configuration flags for input and output. This allows us to migrate input and output independently - for example, enabling TOON input first (where the LLM just needs to *read* the format) while keeping JSON output unchanged.
Prompt Strategy
For AI agents, prompts were restructured into three sections:
1. Input section - describes the format and schema of input data. Two versions are maintained: one for JSON, one for TOON.
2. Common section - the core instructions, reasoning guidelines, and business logic. Shared across both formats.
3. Output section - describes the expected output format and provides examples. Two versions are maintained for future TOON output adoption.
At runtime, the appropriate input and output sections are selected based on the config flags and stitched together with the common section to form the final prompt. Changes to business logic only need to happen in the common section.
For LLM prompts defined as database templates, the templates remain unchanged - TOON-specific instructions are injected at runtime based on configuration.
Data Flow
The data flow adapts based on configuration. If TOON input is enabled, the Pydantic model or JSON payload is serialised using the TOON converter before being injected into the prompt. Otherwise, it is serialised as before. The same config-driven approach applies to output parsing when TOON output is enabled in future.

The config flags control the entire flow - changing a flag switches the serialisation format without any code changes or redeployment.
Post-Migration Results
After migrating multiple AI use cases to TOON input in production, we tracked daily cost and token usage over several weeks. Cost savings across migrated use cases ranged from ~5% to ~15%, consistent with the pre-migration analysis. Latency also improved. Across the pre-migration analysis, p95 latency dropped by 1-12% depending on the use case - a direct result of fewer tokens to process per request.
One important observation: TOON reduces tokens for the structured data portion of the prompt, but input data itself varies across requests in real-world scenarios. On days with larger or more complex records, average token counts may not decrease - or may even increase - despite TOON being active. Cost savings over a sustained period are a more reliable measure of impact than per-request token counts, since they smooth out this natural content variation.
Rollout Strategy
The rollout followed a phased approach. First, a shared SDK was built with JSON ↔ TOON converters and published as an internal package. Next, integration handlers were added to each service, with a config flag controlling format selection per use case. Migrations then proceeded one use case at a time: enable TOON on staging, validate accuracy against the JSON baseline, and promote to production after sign-off. This pattern kept each change small and independently reversible.
Practical Advice for Adopting TOON
For teams considering TOON for LLM workflows, here are the key lessons from this adoption:
Start with high-volume, structured-data-heavy use cases. The ROI is highest where input data contains arrays of objects (tabular data). If the prompt is mostly natural language text or base64 content, TOON won't help.
Use config flags, not hard switches. Being able to enable TOON for input and output independently, and revert per use case, gave us confidence to migrate progressively.
Split your prompts. Separating format-dependent sections (input/output descriptions) from format-independent sections (business logic) makes maintenance tractable and allows a clean comparison.
Measure on real data, not theoretical estimates. Theoretical savings of 35-45% assume all content is JSON. In practice, most prompts mix structured data with natural language instructions, so real savings will be lower - and will vary with input content.
Plan for debugging. TOON isn't supported by standard log viewers and API consoles. We mitigate this by logging a JSON-equivalent alongside the TOON payload and storing all response data in JSON regardless of the LLM format. TOON stays confined to the LLM request boundary - upstream and downstream systems never see it.
Beyond TOON: Other LLM Cost Optimisations
TOON is one piece of a broader cost optimisation strategy. Two other approaches we've adopted complement it:
Response caching. For use cases where the same (or semantically equivalent) input recurs frequently, we cache LLM responses using a hashed request key in DynamoDB. Subsequent identical requests are served from cache without making an LLM call at all - eliminating both cost and latency entirely for cache hits. This is particularly effective for classification and mapping use cases where the same input descriptions appear repeatedly.
Batch API processing. For non-time-critical, high-volume workloads, we aggregate thousands of requests into a single batch job using provider batch APIs. Batch pricing can be significantly cheaper than real-time pricing (exact discounts vary by provider and may change over time), making this a useful lever for use cases that can tolerate asynchronous processing.
Combined with TOON, these three approaches - reducing token count per request, avoiding redundant requests via caching, and leveraging discounted batch pricing - form a layered cost optimisation strategy that addresses different parts of the LLM cost equation.
Conclusion
JSON's verbosity is a meaningful cost driver at LLM scale. TOON provides a practical, LLM-friendly alternative that reduces token usage without degrading response quality for capable models.
The approach that worked well for us - and generalises to any team considering this - was to keep it incremental: build a shared converter as a library, make the format configurable per use case with instant rollback, split prompts so business logic stays format-agnostic, and validate each migration against an accuracy baseline before promoting to production.
Across migrated use cases, this delivered 5-15% overall cost savings by enabling input token optimisation alone. With output token optimisation (tested in POC, not yet in production), blended savings could be significantly higher - the POC showed output token reductions of 8-43% for compatible models.
References
- TOON Format Specification and Benchmarks - github.com/toon-format/toon
- OpenAI Tokenizer - platform.openai.com/tokenizer
- OpenAI Batch API Documentation - platform.openai.com/docs/guides/batch
- AWS Bedrock Batch Inference - docs.aws.amazon.com/bedrock/latest/userguide/batch-inference.html
- Pydantic Documentation - docs.pydantic.dev
Join us
Scalability, reliability, and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels, and if solving hard problems with challenging requirements is your forte, please reach out to us with your resume at careers.india@halodoc.com.
About Halodoc
Halodoc is the number one all-around healthcare application in Indonesia. Our mission is to simplify and deliver quality healthcare across Indonesia, from Sabang to Merauke. Since 2016, Halodoc has been improving health literacy in Indonesia by providing user-friendly healthcare communication, education, and information (KIE). In parallel, our ecosystem has expanded to offer a range of services that facilitate convenient access to healthcare, starting with Homecare by Halodoc as a preventive care feature that allows users to conduct health tests privately and securely from the comfort of their homes; My Insurance, which allows users to access the benefits of cashless outpatient services in a more seamless way; Chat with Doctor, which allows users to consult with over 20,000 licensed physicians via chat, video or voice call; and Health Store features that allow users to purchase medicines, supplements and various health products from our network of over 4,900 trusted partner pharmacies. To deliver holistic health solutions in a fully digital way, Halodoc offers Digital Clinic services including Haloskin, a trusted dermatology care platform guided by experienced dermatologists. We are proud to be trusted by global and regional investors, including the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. With over USD 100 million raised to date, including our recent Series D, our team is committed to building the best personalized healthcare solutions and we remain steadfast in our journey to simplify healthcare for all Indonesians.


