Apache Spark Performance Optimisation Through Effective Metrics Collection And Analysis
At Halodoc, ensuring efficient performance and resource utilisation across our data infrastructure is paramount. As part of this initiative, we utilise Apache Spark to process large-scale data, but with that scale comes the challenge of monitoring and optimising resource usage in near real-time. Working with Spark presented challenges often seen in large-scale data processing, including resource bottlenecks, unpredictable memory usage, and varying job execution times. These challenges underscored the need for an advanced metrics solution that could capture job performance insights in near real-time and offer actionable data to tune resource usage automatically.
In this blog, we'll walk you through the journey we took at Halodoc to implement Custom Spark Listeners - a specialised solution designed to provide fine-grained monitoring of our Spark applications. This helped us in optimising Spark workloads, provide aggregated view of every job and paving a way to dynamically right size resources allocated to Spark applications.
Significance of Spark Metrics
Apache Spark is a core component of our distributed data processing architecture and metrics collection from Spark jobs is essential to ensure that resources are allocated properly. Without sufficient monitoring, we risk:
- Over-allocation of resources, leading to increased costs.
- Under-allocation, causing job failures or performance bottlenecks.
- Inefficient stages and shuffling, affecting job completion times.
Previously, Spark metrics were only available through the Spark UI, which has its own set of challenges:
- Latency in loading the Spark UI for large jobs makes real-time monitoring difficult.
- Critical data is buried within various tabs and views, complicating quick access to an aggregated overview of key metrics such as shuffle size, memory usage, and stage durations.
- No built-in options for viewing aggregated metrics across jobs.
- Limited customization capabilities, making it difficult to tailor the display and tracking of metrics to user-specific needs.
To address this, we needed to persist key Spark metrics in a database and streamline how we visualise and analyse them.
Challenges of Existing Metrics Collection Methods
There are several traditional methods to gather Spark metrics:
- Parsing the Event Logs: In Spark, every event is logged, and metrics can be collected by parsing these event logs. However, post-processing is required to extract meaningful metrics, which often requires adjustments with each version upgrade. This approach is generally not recommended for production systems, as it can be complex and difficult to maintain.
- Spark REST API: Spark provides it's Rest API to access the critical metrics, but they are useful for querying current state, lacks granularity and needs continuous polling.
- Metrics Sink: Allows pushing metrics to external systems, for example Prometheus and Graphana sink or Graphite sink. However, it lacks flexibility to track custom metrics, often resulting in the collection of unnecessary metrics leading to high costs.
Each of these methods had limitations that didn't fully meet our needs. We required near real-time, event-driven metrics, which led us to the decision to implement Custom Spark Listeners, which allowed us to:
- Capture detailed metrics throughout the job lifecycle, such as task completion, executor updates, stage completion.
- Persist these metrics in a centralised database for further analysis.
How the Custom Spark Listener Works
Spark listeners work as part of the event-driven model , allowing developers to listen to and respond to various events within a Spark application by writing a Custom Spark Listener. These events can range from the beginning or end of a task or stage to metrics updates for executors and jobs.
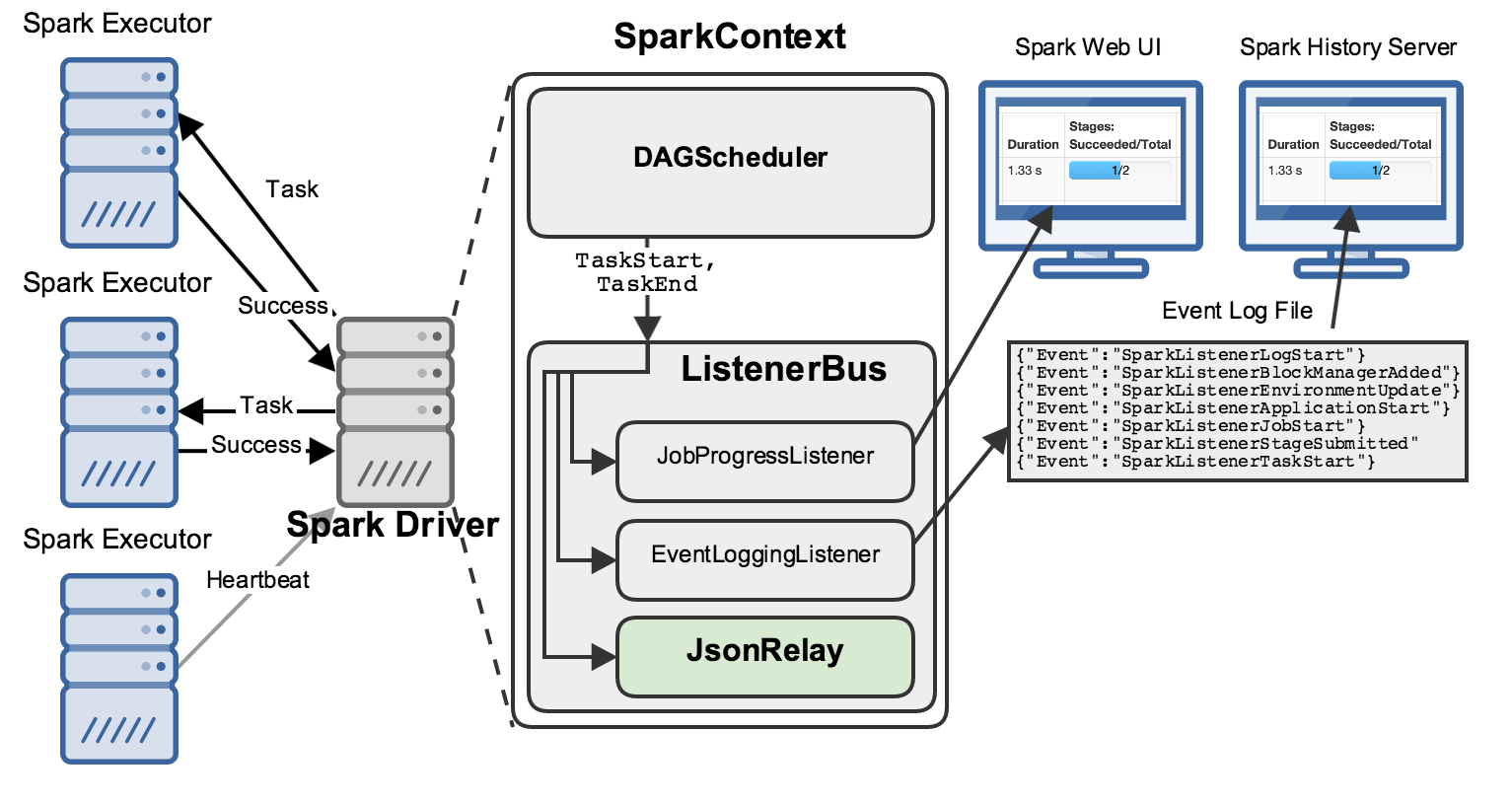
ListenerBus Mechanism
Spark’s listener mechanism is based on a ListenerBus, which is essentially an internal message bus that routes events from different parts of a Spark application to interested listeners. It uses a publish-subscribe pattern, where listeners (subscribers) can register to receive updates on specific events published by the Spark application.
- The SparkListenerBus extends ListenerBus, which acts as the main channel for events.
- When an event occurs, it is posted on the listener bus, which in turn dispatches it to each registered listener.
Event Types
Events in Spark are defined in the ListenerBus class, and they encapsulate information about the different stages and parts of the Spark application, some of them are :
- Application Events: Capture application start, end, and update events (e.g.,
SparkListenerApplicationStart,SparkListenerApplicationEnd). - Job Events: Include job start and end events (
SparkListenerJobStart,SparkListenerJobEnd). - Stage Events: Capture events about stage progression (
SparkListenerStageSubmitted,SparkListenerStageCompleted). - Task Events: Include granular task-level events like task start, end, and failure (
SparkListenerTaskStart,SparkListenerTaskEnd).
Each event, such as a job start or task completion, triggers a corresponding listener method. Internally, Spark captures these events through specific APIs, converts them into SparkListenerEvent objects, and posts them on the listener bus. The ListenerBus processes events asynchronously in the order they are posted. Each listener receives a reference to the event and handles it in its own method, such as onStageCompleted or onTaskEnd
Creating and Integrating Custom Spark Listeners
To track specific metrics or events, custom listeners can be created by extending the SparkListener class and implementing methods for the desired events.
For instance, to capture the GC time of each task, after understanding which event in SparkListener offers it, extending SparkListener class and overriding the event will help getting that metrics ( in this case the event is onTaskEnd ) . This metrics will be inserted to database at the end of application.

In our Spark metrics monitoring setup, we track a range of detailed executor and application metrics to help us analyze and optimize resource usage. Key metrics include:
- App and Executor Identifiers: Unique IDs for each application and executor to easily track metrics by app.
- Execution Performance: Metrics like total_completed_tasks, total_task_duration, and total_cores provide insight into workload efficiency and CPU utilisation.
- Memory Utilisation: peak_execution_memory, peak_jvm_memory_on_heap/off_heap, and max_memory metrics show peak memory consumption patterns and potential memory bottlenecks.
- Data Handling: Metrics such as total_input_bytes_read, total_output_bytes_written, total_shuffle_read_bytes, and total_shuffle_write_records track data I/O and shuffle operations, essential for understanding data movement within Spark jobs.
- Spill and GC Efficiency: total_memory_bytes_spilled, total_disk_bytes_spilled, and total_gc_time indicate memory and garbage collection efficiency, providing actionable insights into memory tuning.
- Reliability Metrics: exec_loss_reason and app_duration help track executor stability and overall application duration to identify issues and improve job resilience.
Integrating a Listener: Custom listener is packaged as a JAR and registered with Spark Application by specifying them in the spark.extraListeners configuration. As the Spark job initiates, the Spark listener will gather metrics and subsequently insert them into the database upon completion of the job.
Spark Job analysis from the aggregated metrics.

We've built a monitoring dashboard in Metabase, it provides valuable insights into workload performance and resource utilisation, allowing us to optimise Spark applications effectively. Key advantages include:
- Comprehensive Weekly Trends: Visualises weekly trends in completed tasks, memory usage, cores utilised, and app duration, enabling a high-level understanding of workload patterns over time.
- Resource Allocation by Stage: The stage distribution chart helps identify where resources are most consumed across stages, such as "Data Extraction Jobs" or "Data Warehouse Jobs" allowing for focused optimisations based on specific stages.
- Memory and Core Utilisation Tracking: Tracks memory consumption and cores used per week, providing insights into resource usage efficiency and potential areas to prevent CPU or memory bottlenecks.
- Identification of Under-Utilised Jobs: Lists the top under-utilised Spark jobs, highlighting areas where resource allocation may be fine-tuned, resulting in cost savings and improved efficiency.
- Detailed Job Execution Metrics: Provides execution times and GC times for top jobs, allowing for targeted performance tuning and minimization of overhead in critical applications.
We have also enabled Job level analysis where dashboard will give aggregated view of single job, helping us to understand the changes in behaviour of the job upon modification in configurations or optimisations in Spark script.

This setup empowers us with data-driven insights, improving our ability to monitor, optimise, and scale Spark applications efficiently while managing resources effectively.
Optimising Resource Allocation: Dynamic Tuning Based on Metrics
The primary benefit of using Custom Spark Listeners at Halodoc is dynamic resource allocation. By analysing metrics like shuffle size, peak JVM heap memory usage, and execution times, we can automatically:
- Reduce resources for smaller jobs, leading to cost savings without sacrificing performance.
- Reduce shuffle overhead: Identify and minimise inefficient stages or jobs that caused excessive shuffling.
- Decrease costs: By avoiding over-allocation of resources, we’ve significantly reduced the operational costs of running Spark on our infrastructure.
This not only helps in right-sizing our Spark jobs but also ensures they run more efficiently, reducing runtime and improving overall throughput.
Dynamic Rightsizing of Spark jobs will be detailed in an upcoming blog.
Results and Future Optimisations
By implementing a basic solution of dynamic resource allocation at Halodoc, we’ve seen a 15% reduction in allocated executory memory due to dynamic right sizing. Significant cost savings by reducing over-provisioned resources. Adding to that we are able to track our costs of spark jobs accurately than before.
Conclusion
At Halodoc, optimising Spark job performance is not solely about achieving greater speed; it is about striking the right balance between efficient resource utilisation and maintaining consistently high throughput. In our pursuit of this balance, we have implemented Custom Spark Listeners, a powerful approach that allows us to gain deep and actionable insights into the behaviour and performance of our Spark jobs. This implementation enables us to monitor, track, and analyze key metrics, providing us with the visibility needed to identify inefficiencies and areas for improvement. By leveraging these insights, we can right-size resources effectively, reducing waste while enhancing job execution efficiency. This continuous optimisation ensures that every phase of the Spark job lifecycle from data ingestion to final output is streamlined, scalable and cost-effective, aligning with our commitment to deliver optimal performance and value across our data-driven operations.
References
Join us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number one all-around healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off, we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. We recently closed our Series D round and in total have raised around USD 100+ million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.