

Harnessing the power of Machine Learning to fuel the growth of Halodoc
Halodoc's Data Science teams work on some of the most exciting healthcare problems, personalization, and optimization. We leverage machine learning and deep learning to build data products for digital outpatients, insurance, and pharmacy. From selecting the right user cohorts for marketing campaigns, accessing the quality of care, serving article recommendations, to adjudicating insurance claims faster, all of this is powered by machine learning.
Machine Learning Life Cycle
One way to categorize a machine learning platform's capabilities is through the machine learning life cycle stages. The typical ML life cycle can be described in the following nine steps:
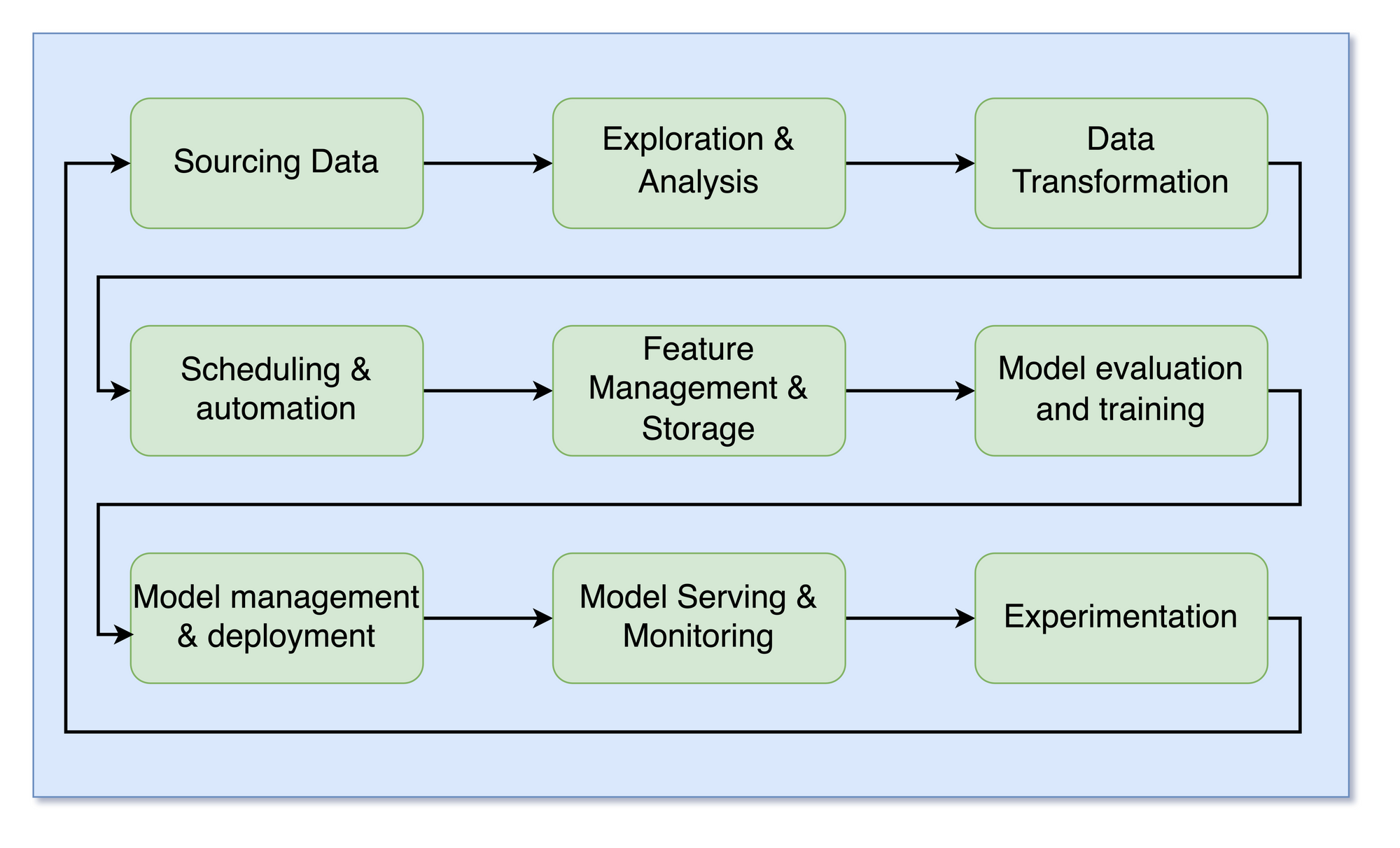
Starting by sourcing data, a data scientist will explore and analyze it. The raw data is transformed into valuable features, typically involving scheduling and automation to do this regularly. The resultant features are stored and managed, available for the various models and other data scientists to use. As part of the exploration, the data scientist will also build, train, and evaluate multiple models. Promising models are stored and deployed into production. The production models are then served and monitored for a while. Typically, there are numerous competing models in production, and choosing between them or evaluating them is done via experimentation. With the learnings of the production models, the data scientist iterates on new features and models.
The problem
With our experience in developing and operating machine learning systems in production, we observe the following problems in the way that they are typically designed:
- The data science development experience can be painful: Data scientists are expected to be full-stack and to be able to take projects end-to-end, but some of the systems and tools they are provided are either painful to use or immature.
- No standard ML life cycle: In principle, most data science projects should follow a very similar life cycle. A common problem is a divergence and lack of standardization at various stages of the ML life cycle. Data Scientists define their approaches to solving problems — which leads to a lot of duplicated effort.
- Challenging to get data science systems into production: The project life cycle for ML systems is typically in the order of months. A considerable time is spent on engineering (infrastructure and integration) compared to data science or machine learning.
- Hard to maintain data science systems once in production: Historically, these systems have been built as proofs-of-concept (POCs) or minimum viable products (MVPs) to ascertain impact first. This causes a problem where scaling to large numbers of model variants, environments. The fact that these systems are relatively brittle means that improvements are not made at the necessary frequency.
The solution
Our vision of the Machine Learning Platform (ML Platform) is to empower data scientists to create ML solutions that drive direct business impact. These solutions can range from simple analyses to production ML systems that serve millions of customers. The ML Platform aims to provide these users with a unified set of tools to develop and confidently deploy their ML solutions rapidly.
We achieve this with the following design principles:
- Easy to compose ML solutions out of parts of the platform: New projects should formulate solutions out of existing products on the ML Platform instead of building from scratch. With the infrastructure complexity abstracted away, ML's entry barrier to driving business impact is lowered. It would allow a lightweight data science team or even non-data scientists to leverage ML power.
- Best practices are enforced and unified at each stage in the machine learning lifecycle: Data scientists should have a clear understanding of all the stages of the ML life cycle, the tools that exist at each stage, and how to apply them to their use cases in a self-service manner with minimal support from engineers. This extends data scientists' capabilities, who can now deploy intelligent systems into production quickly, run experiments with small slices of traffic confidently, and scale their systems to multiple environments, markets, and experiments quickly.
- Integration into the existing Halodoc tech stack: The ML Platform is built with the existing Halodoc tech stack in mind and either abstract away any integration points or makes these integrations easy. Data scientists should not have to be concerned with how their solutions will be consumed.
- Bottom-up innovation: The platform is built in a modular fashion, in layers from the ground up. Given the diversity of use cases and applications that need to be supported, it is necessary to keep the "happy path" and provide flexibility when edge cases arise.
Machine Learning Platform
Halodoc ML Platform is hosted on AWS. Our data infrastructure is a combination of AWS managed services and self-hosted services. Comprising of an EKS cluster running Kubeflow, an open-source machine learning platform designed to enable using machine learning pipelines to orchestrate complicated workflows running on Kubernetes and Airflow for the data transformations and ingesting the data to Feature store (S3).
The critical components of the platform are explained below.
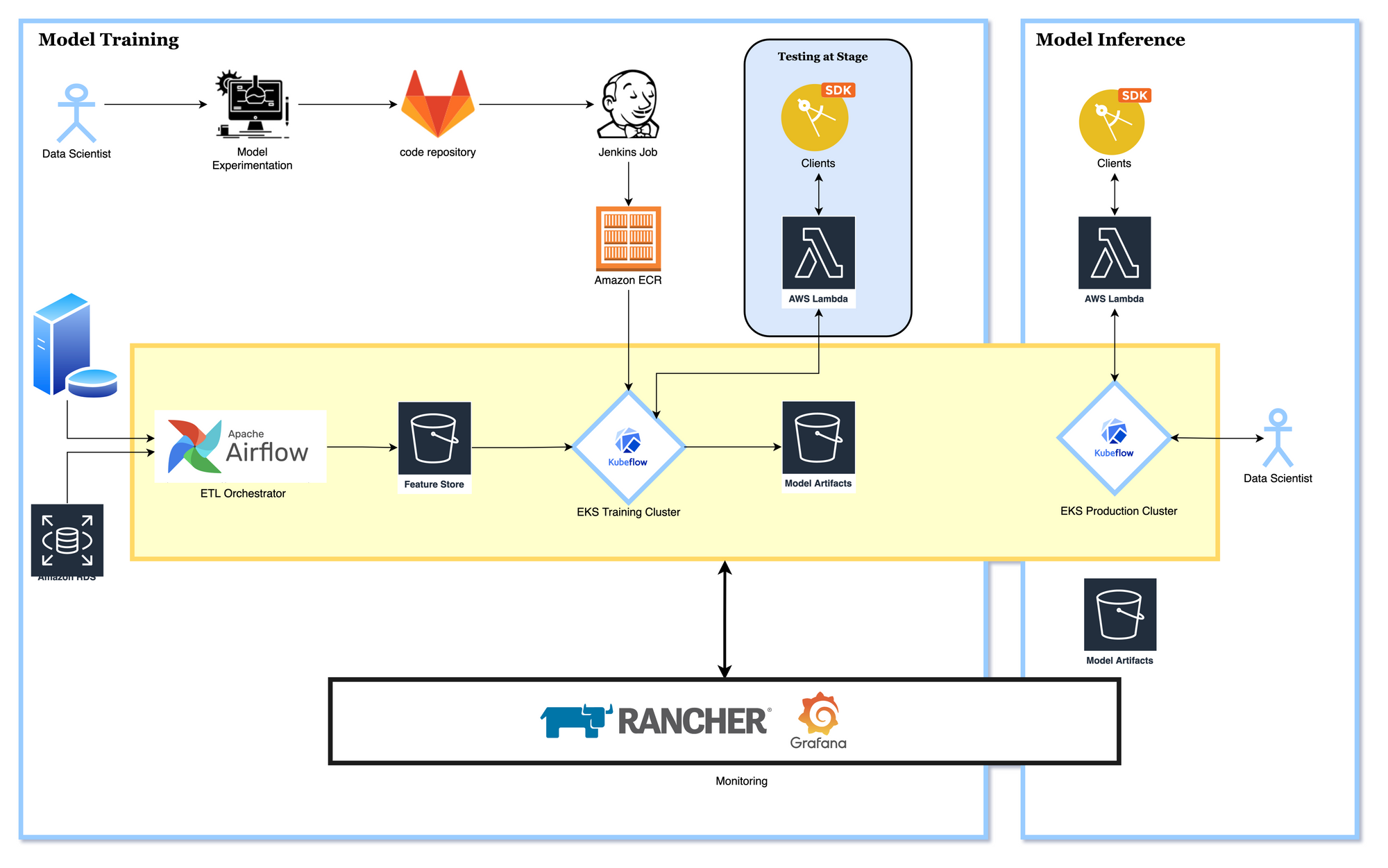
The critical components of the platform are explained below.
Feature Store :
A Feature Store sits between data engineering and data science. On one side, you have data owners (data engineers, data scientists) creating data sets and data streams (outside of the platform) and ingesting them into the system. On the other side, you have Data Scientists who consume these features, either during training or serving.
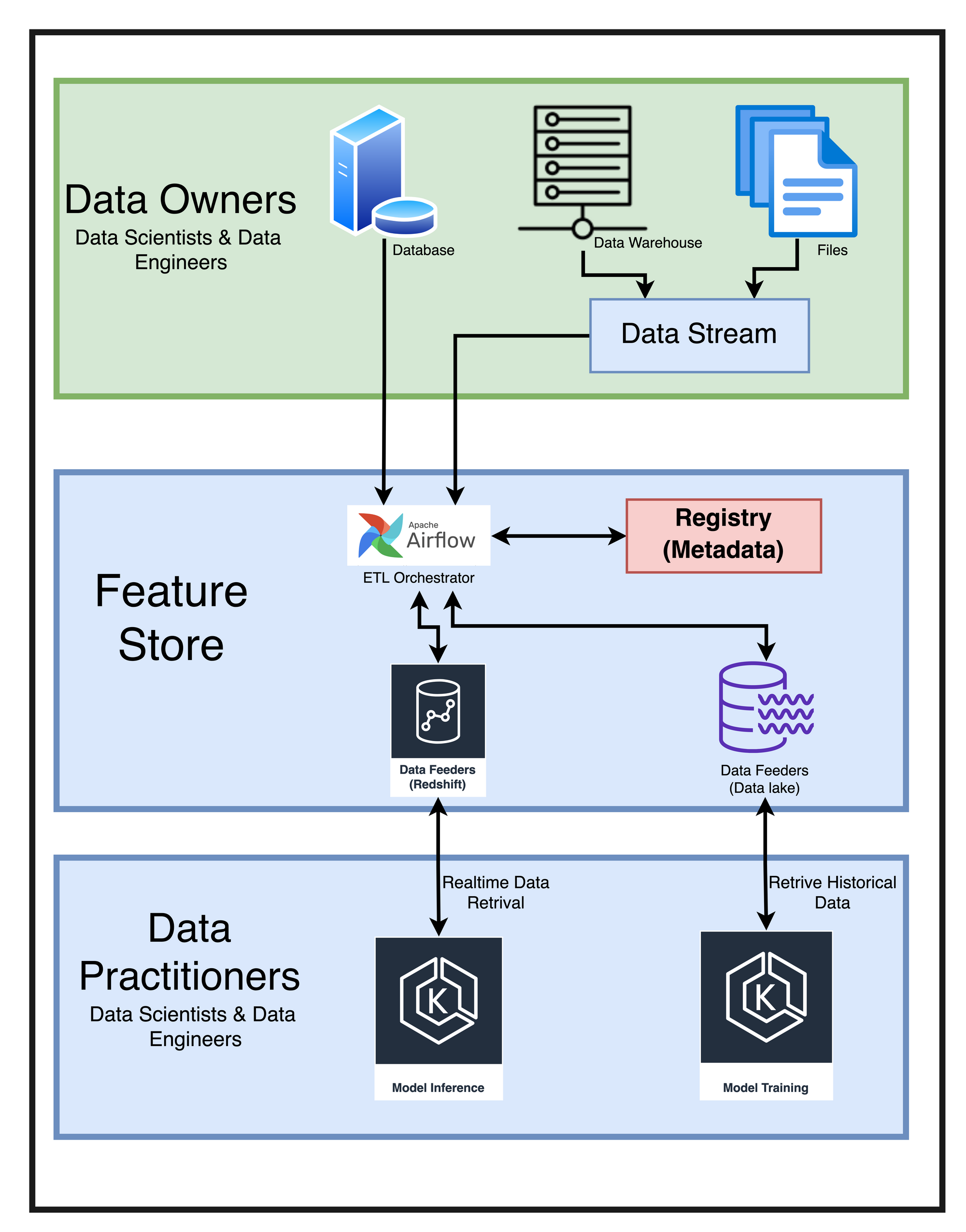
Beyond connecting the feature producers to the feature consumers, It will also provide other conveniences for both parties:
- Consistent feature joins: A data scientist needs to produce a data set from multiple upstream data sources that are being updated at different rates (minutely, daily, etc.), for a specific group of entities, in a particular list of features, over a particular period, and joins the features in a way that is consistent between historical retrieval and online serving. This feature store does out-of-the-box to ensure that there is no training-serving skew between the two stages of the ML lifecycle.
- Project isolation: More recently, we also introduced the concept of 'projects'. Projects allow for resource isolation, meaning users can create feature sets, features, and entities within private namespaces. They also allow for simplified retrieval from the serving API, meaning users can now reference features inside projects directly.
Containerizing Model Training :
Essentially, containers are lightweight, neat capsules containing applications using shared operating systems as opposed to virtual machines that require emulated virtual hardware. Docker enables us to easily pack and ship applications as small, portable, and self-sufficient containers that can virtually run anywhere. Containers are processes, VMs are servers (more).
It is not a common practice to train Machine Learning (ML) models in a containerized fashion. Most people tend to use simple Python scripts and requirement.txt files. However, it is arguable that the containerizing training code can save us a lot of time and trouble throughout the life cycle of an ML model in production.
Let us say that we have a model in production trained on user data that we collect. However, user behaviour changes over time, possibly resulting in a significant shift in the data distribution.
Containerizing a training job allows us to re-train our model on the new data distribution effortlessly. Also, containerization facilitates running the job periodically — or upon a drop in performance on the monitored metrics —, test and deploy it automatically, ensuring that the predictions are consistent and our users are happy. Another case would be that we have multiple servers in our infrastructure used for computation, potentially with different Linux distros, CUDA toolkits, Python versions, libraries, and so on. Arguably, we cannot anticipate every scenario, and our beloved training scripts will most likely break in specific environments. Having a dockerized job can save us time and effort in this case since it will happily run in any environment as long as Docker is installed. Alternatively, one could think of a containerized training job as an encapsulated solution to a given task. After investing months into prototyping, we want to persist our solution somehow since results might have to be reproduced later, or the model could be potentially applied to a similar problem in the future.
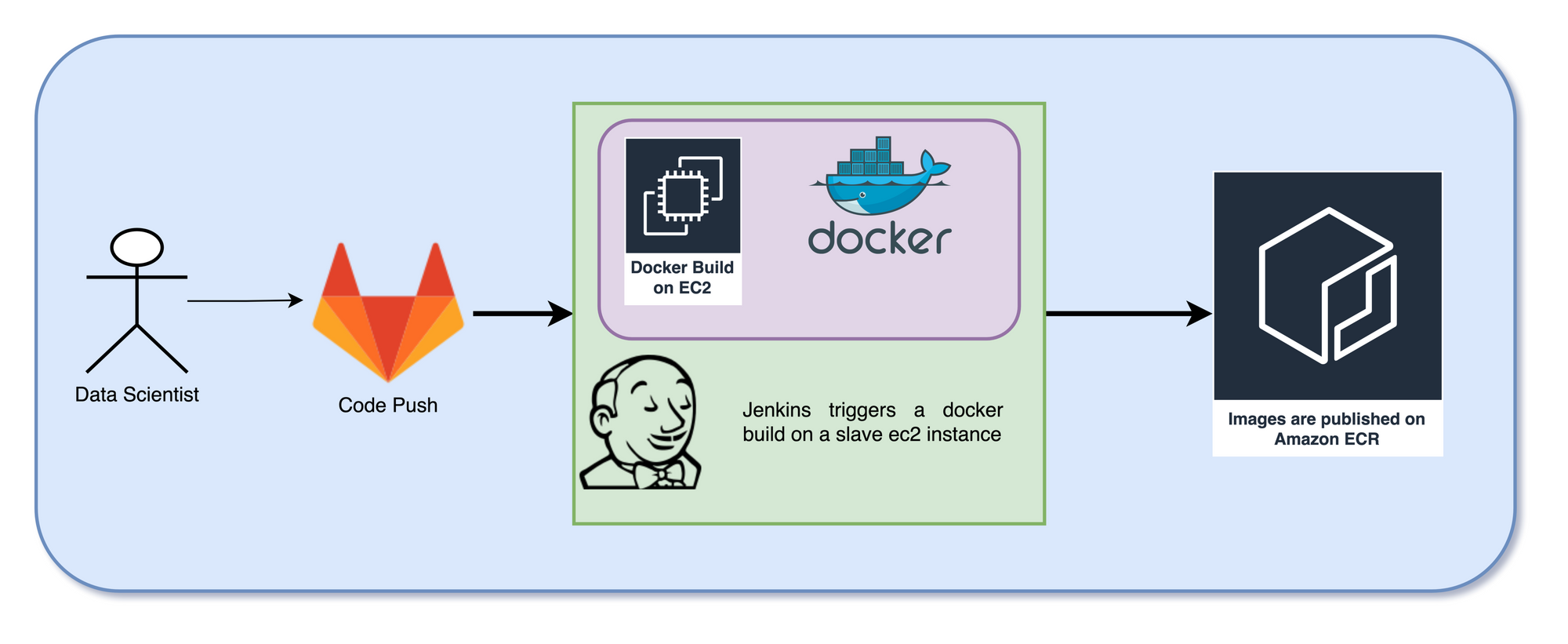
To achieve this, we provisioned a Jenkins job; once the data scientists push the scripts to Gitlab with the Docker config, this job is triggered. The container is created using a base image and published in Elastic Container Registry.
Training and Deployment on Kubeflow :
Model Inference :
Once the training script is containerized and is populated in Elastic Container Registry, the data scientists write a training config in a training, YAML file, mentioning the container to use, command(s) to run, framework, and other operational details. This config is applied to spin up training pod(s).
envsubst < training.yaml | kubectl create -f -
Kubeflow manages the model(s) training and dumps the trained model to an S3 bucket; this is also replicated into another S3 bucket for deploying these models.
Model Inference :
After the model is trained and stored in the S3 bucket, the next step is to use that inference model. A model from training is stored in the S3 bucket. Data Scientists have to write an inference YAML file linking the S3_BUCKET and AWS_REGION where the trained model is stored. Later, the config YAML can is applied on the Cluster, which spins up the inference containers.
envsubst <inference.yaml | kubectl apply -f -
Once the containers are up, the next step is to expose the containers and services via a Load Balancer.
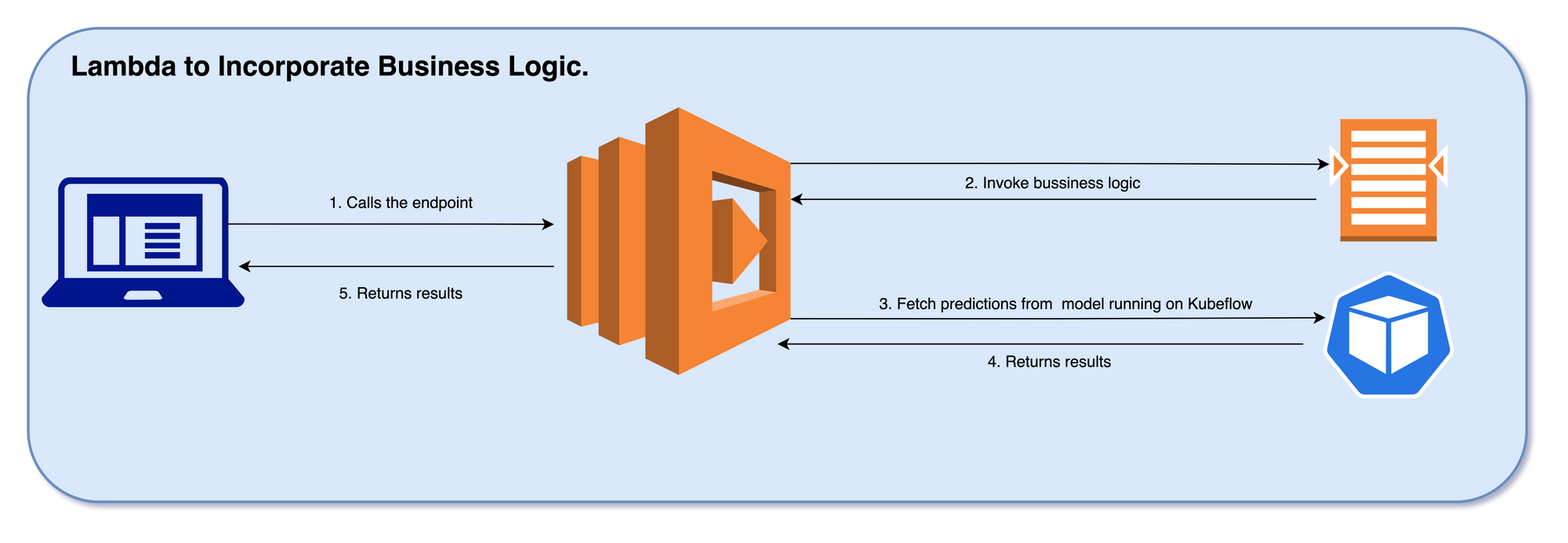
Since the business logic(s) cannot be always incorporated in the exposed endpoint, we introduce a AWS Lambda in-between the client(s) and the exposed model to do the data transformation and accommodate the business logic.
Concluding Notes
With this ML Platform, we have a robust yet straightforward pipeline to automate and manage almost all of our otherwise tedious and time-consuming processes of building machine learning solutions and shipping them. By automating and centrally managing the ML lifecycle, We aim to empower Data Scientists and Data Engineers to focus on what they are good at, i.e. building data-driven solutions. At the same time, together, we continue to simplify healthcare.
The next steps in the ML platform would be to incorporate Airflow to make inferences for batch use cases, leverage Data Lake on AWS as a single source for different variants of data sources and a robust infrastructure meeting all our data needs.
In this blog, we gave a birds-eye view of the ML Platform @ Halodoc, the journey of data from different sources to ML models and deployment. The thought process that we went through while choosing these tools. Maintaining and running this infra is an arduous task, and we continuously challenge ourselves to keep the infra simple and solve the problems more efficiently.
Futher Reads :
- Kubeflow
- Machine Learning using Kubeflow
- Data Science Meets Devops: MLOps with Jupyter, Git, & Kubernetes
Join Us
We are looking for experienced Data Scientists, NLP Engineers, ML Experts to come and help us in our mission to simplify healthcare. If you are looking to work on challenging data science problems and problems that drive significant impact to enthral you, reach out to us at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 2500+ pharmacies in 100+ cities to bring medicine to your doorstep. We have also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off; We launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are incredibly fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, Gojek and many more. We recently closed our Series B round and, In total, have raised USD 100million for our mission. Our team works tirelessly to ensure that we create the best healthcare solution personalized for all of our patient's needs and are continuously on a path to simplify healthcare for Indonesia.


