
Improving API Latency: A Practical Guide
Introduction
In modern software development, APIs (Application Programming Interfaces) are vital for facilitating communication between software components. Optimising APIs allows for efficient resource management, cost reduction, and an improved user experience.
As we expand rapidly, it becomes clear that maintaining standardisation and closely monitoring API performance is crucial. These measures ensure efficiency, reliability, and scalability, enabling us to optimise resources and deliver an enhanced experience for our users.
A Tale of Latency: Why API Performance Matters
Picture this - You’re shopping on your favourite e-commerce site, eager to grab a few essentials. You click to load the landing page and it takes 10 long seconds. You search for an item, and the catalog takes another 10 seconds to appear. By the time you’re trying to check out your items, frustration has already set in. Now imagine this happening when you have an entire list to purchase. Sounds like a nightmare, right?
A slow API doesn’t just frustrate users; it can completely ruin the experience, leading to abandoned carts, lost trust, and even users deciding to never return to the platform no matter how exceptional the logistics or operations behind the scenes are. That’s the kind of cascading impact an underperforming API can have.
At Halodoc, where we’re on a mission to simplify healthcare, ensuring a seamless user experience is non-negotiable. With our rapid growth and expanding user base, we realised we had thousands of APIs in operation, each playing a critical role in connecting users to our services. Monitoring the performance of each API manually? Impossible. But ignoring it? Even worse.
So, we got to work. Our team brainstormed a range of potential solutions to identify and fix slow-performing APIs. Some of the initial approaches we considered included:
- Applying Universal Timeout Thresholds: Setting a fixed timeout for all APIs to highlight outliers.
- Implementing Targeted Profiling: Identifying the most frequently used or critical APIs to prioritise performance enhancements.
- Monitoring Resource Utilisation: Evaluating server and database usage during API calls to detect performance bottlenecks.
While these ideas had merit, they also came with challenges and limitations. Given that our APIs supported diverse use cases with varying complexities, treating them all the same wasn’t the right solution.
Divide and Conquer: A Strategic Approach
A one-size-fits-all approach was never going to work when it came to assessing API performance. To accurately determine whether an API was meeting expectations, we realised the need to first organise them into appropriate categories. By grouping APIs based on their specific purposes, we could establish tailored benchmarks for each category. This strategic categorisation made it much easier to evaluate performance and ensure every API was optimised for its intended role.
"Small wins lead to big victories. Break down your challenges, and each small success takes you closer to the goal."
Benefits of API categorisation are listed below.
- Specialisation and Efficiency: Different API types are designed to handle specific tasks or functions. By categorising APIs based on their roles, it becomes possible to ensure that each type is optimised for its particular use case, leading to more efficient processing and reduced complexity.
- Enhanced System Integration: APIs facilitate communication between various systems and services. Different types of APIs address different integration needs, such as data retrieval, updates, or external service interactions. This specialisation helps in creating a cohesive system where components interact seamlessly.
- Scalability and Flexibility: Categorising APIs allows for better scalability. For instance, bulk data processing APIs can handle large volumes of requests efficiently, while async event handlers manage background tasks without blocking primary processes. This flexibility supports growing applications and evolving requirements.
- Improved Maintenance and Management: Having distinct API types simplifies maintenance and management. Each API type can be developed, tested, and maintained independently according to its specific needs. This separation of concerns helps in tracking performance, handling issues, and making updates more manageable.
- Optimised User Experience: APIs designed for specific functions, such as consumer searches or file uploads, ensure that users receive a streamlined and responsive experience. Specialised APIs can be fine-tuned for performance, enhancing the overall user experience by providing faster and more accurate results.
- Clear Documentation and Development: Different API types come with clear documentation that defines their specific purpose and usage. This clarity helps developers understand how to interact with the APIs, reducing the learning curve and improving the efficiency of development and integration processes.
- Targeted Security Measures: By categorising APIs, it's easier to implement targeted security measures. For example, APIs handling sensitive data (e.g., updates or file uploads) can have stricter security protocols compared to APIs meant for public data retrieval. This targeted approach enhances overall system security.
- Better Resource Management: Different API types can be optimised for resource usage, such as memory and processing power. For example, asynchronous event handlers can manage tasks without consuming resources unnecessarily, while batch processes can handle large datasets efficiently.
Smart Segments, Faster APIs: First Step
The challenge ahead of us was organising this vast collection into meaningful categories to better understand and enhance the flow of information. While the importance of categorisation was clear, we found ourselves standing at a critical crossroads, with several pressing questions looming large.
What are the right categories? How fast is “fast” for each group? Should these categories be further divided? These unanswered queries were our next challenge.
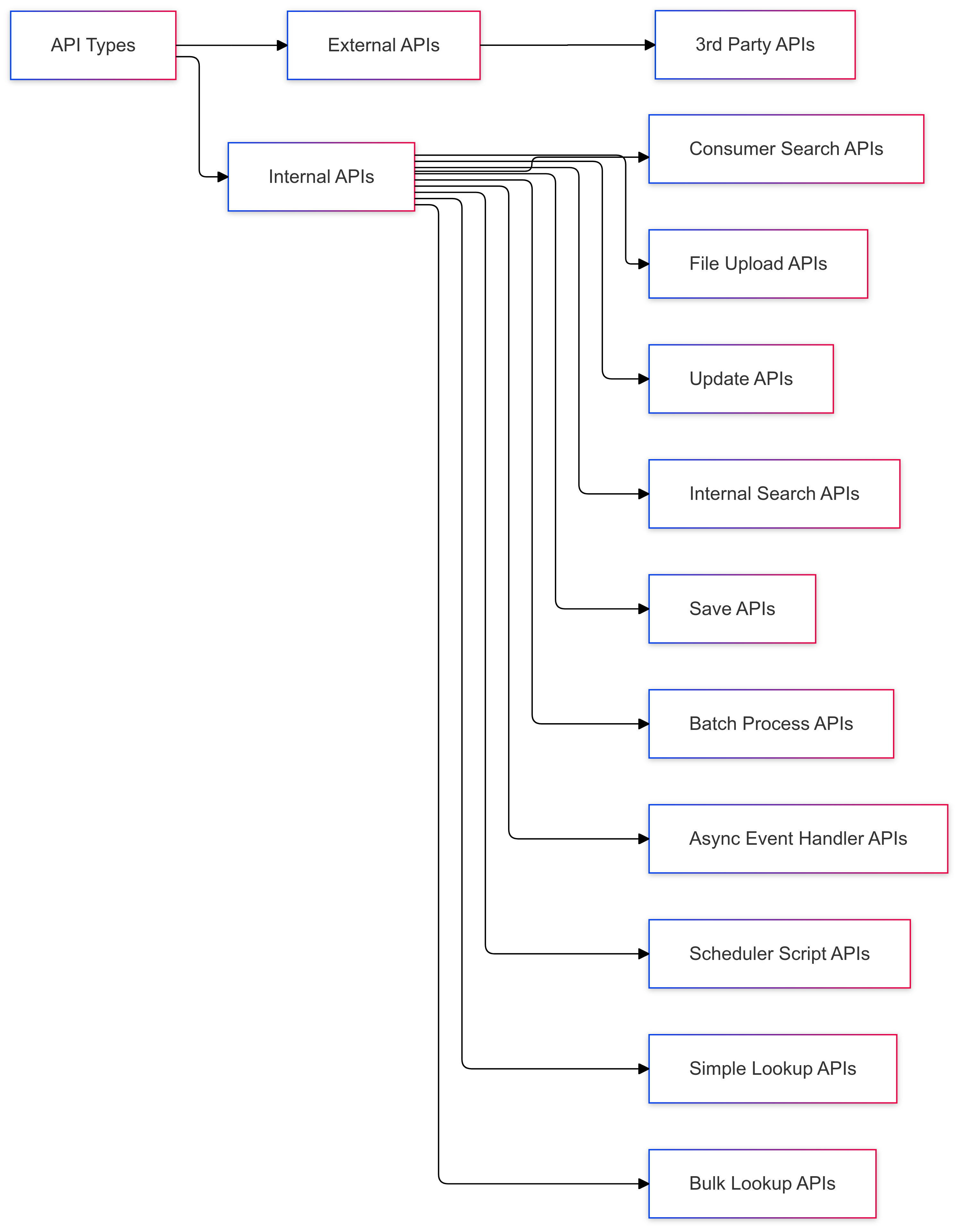
To solve this, we embarked on a deep dive into the labyrinth of services. By analysing the specific purpose of each API, we gradually built groups that provided clarity and answers to our categorisation dilemma. Here's how we defined the different groups:
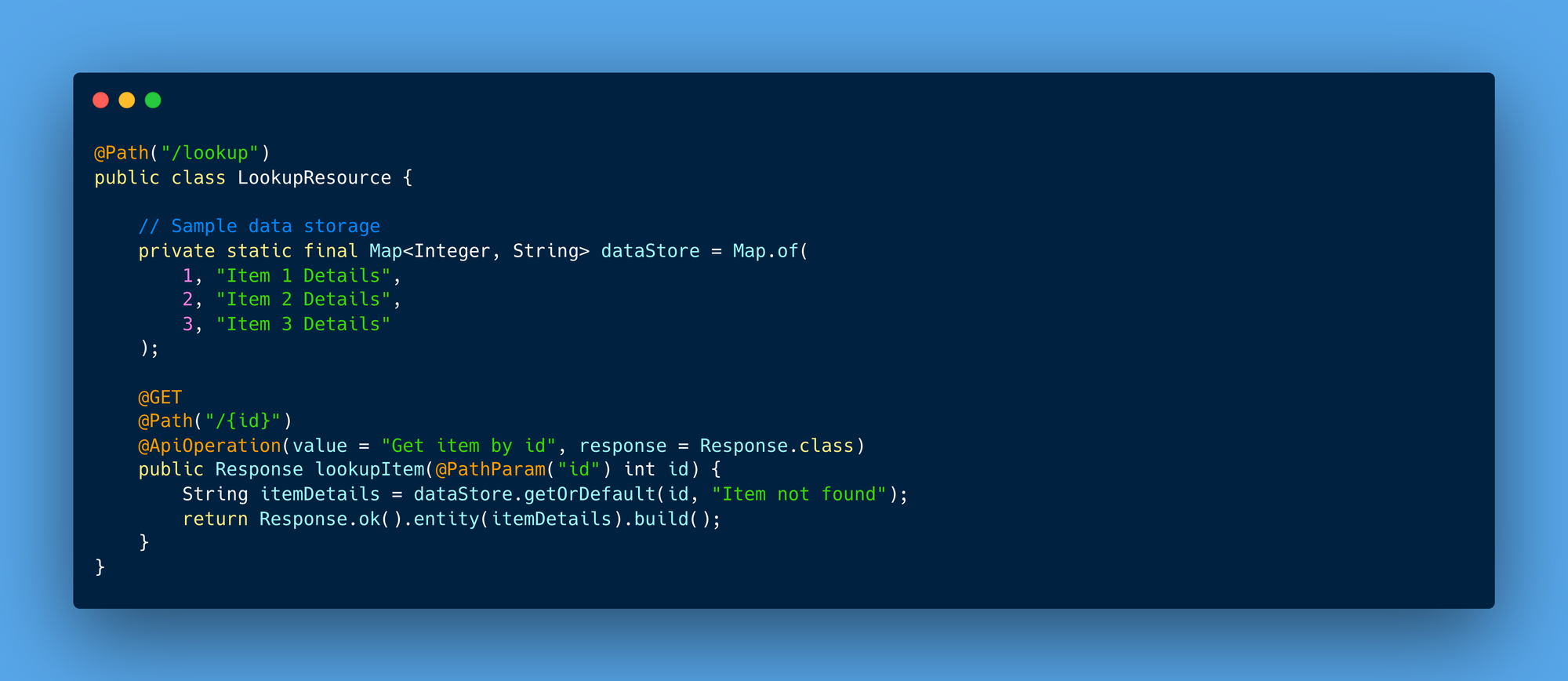
Simple Lookup APIs: These APIs are used for straightforward data retrieval, making them ideal for quick, single-item queries. When a user or system needs fast information, whether it’s pulling details on a specific record or checking the status of an item, Simple Lookup APIs provide an immediate response with minimal processing.
Bulk Lookup APIs: Designed for handling high-volume data requests, Bulk Lookup APIs retrieve information for multiple records simultaneously. Perfect for batch processes, these APIs efficiently gather large datasets without slowing down the system, making them essential for large-scale data access.
Consumer Search APIs: These APIs cater to end-users by providing search functionalities based on user queries. Built with a user-friendly interface, Consumer Search APIs allow consumers to easily search for relevant information—be it services, products, or other resources.
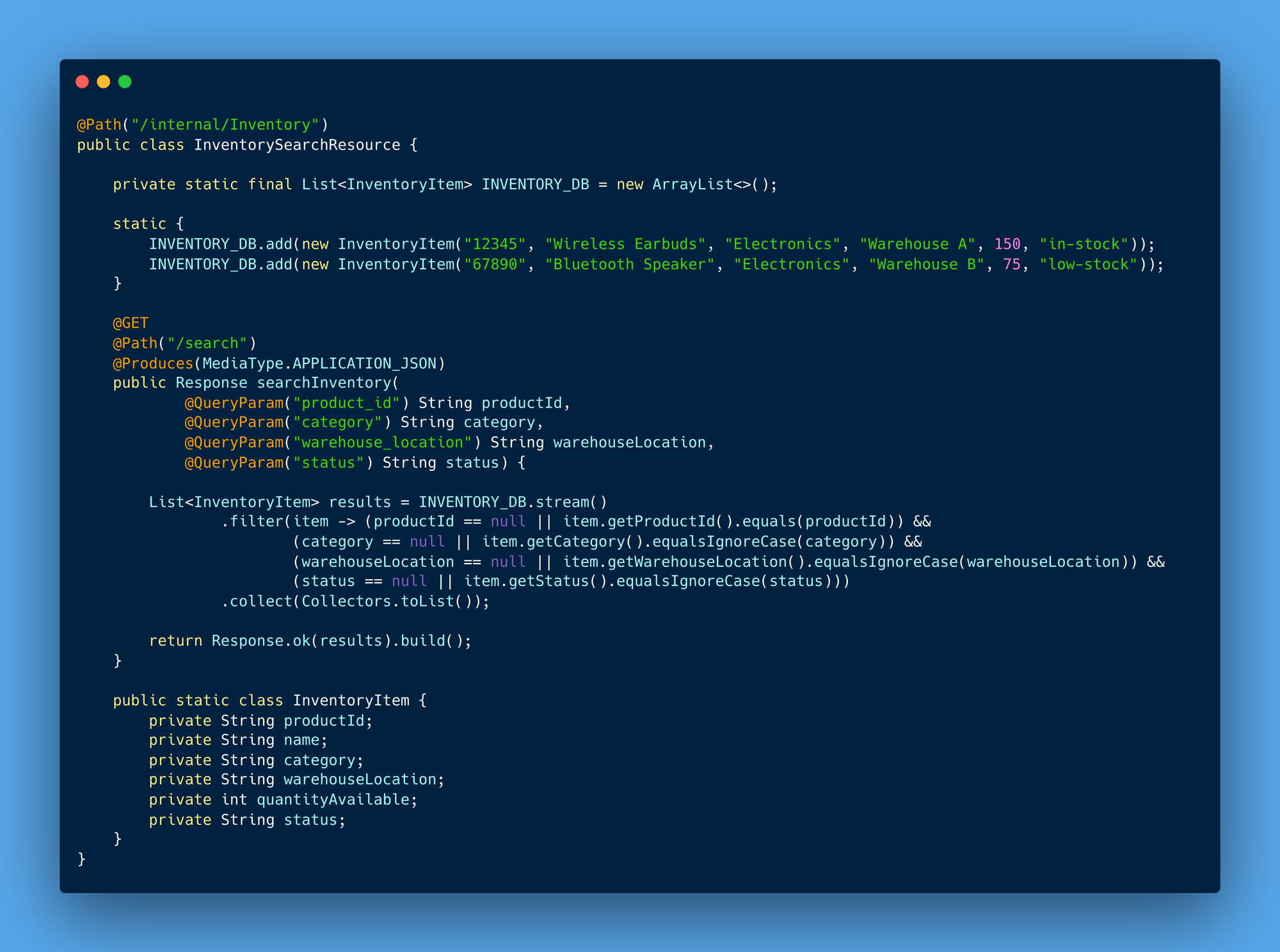
Internal Search APIs: Serving internal data access needs, these APIs support backend processes. Unlike consumer-facing APIs, Internal Search APIs retrieve data for system use only, helping with backend operations, reporting, and internal system functions.
Async Event Handler APIs: These APIs are designed to manage events and tasks that don’t need immediate processing, allowing the system to carry out background operations without blocking main processes. This asynchronous functionality is ideal for deferred tasks, enhancing system efficiency.
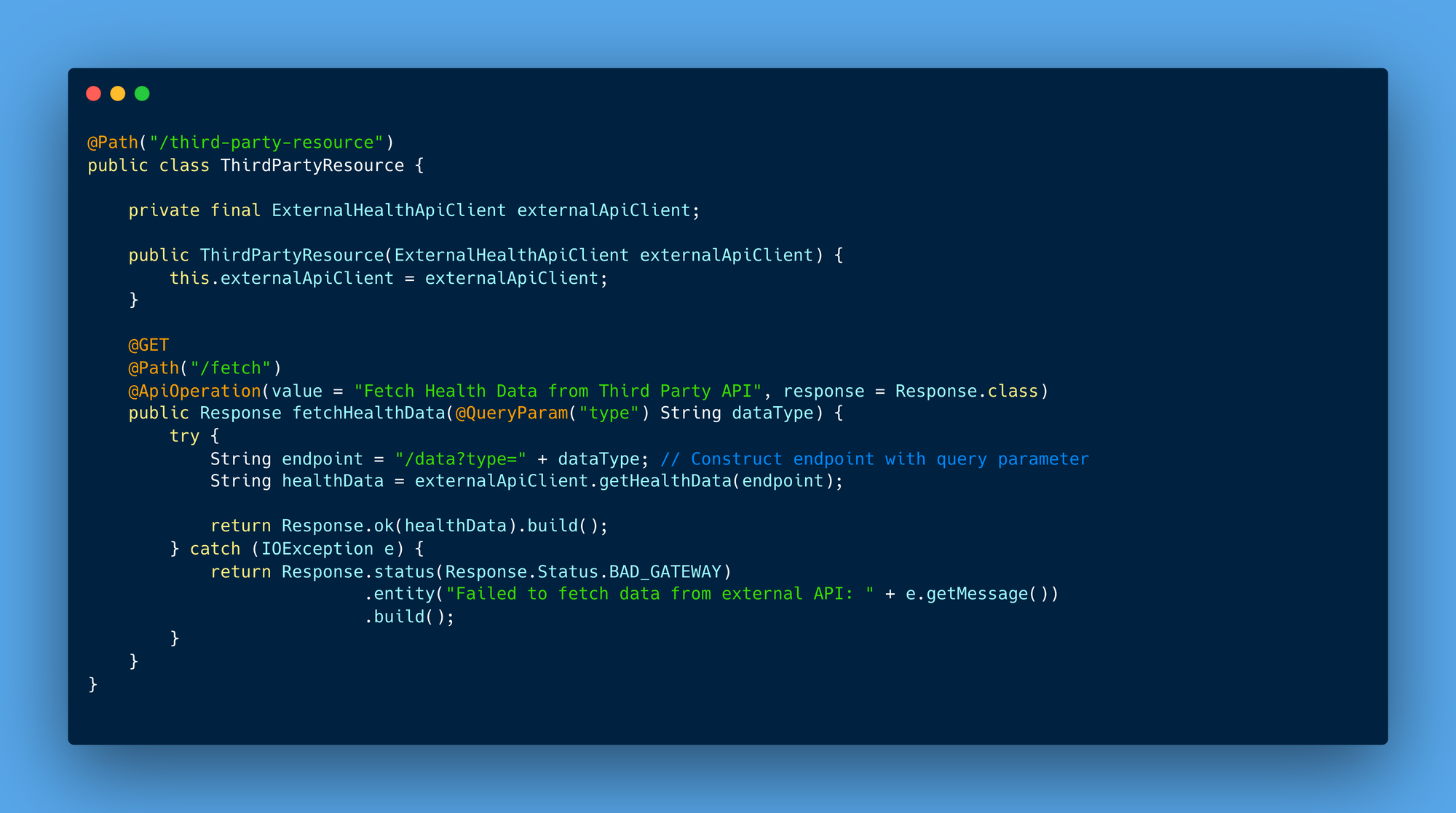
3rd Party APIs: For seamless interaction with external services, 3rd Party APIs enable integration with third-party vendors. These APIs expand our platform’s capabilities by connecting Halodoc to external services, ensuring a smooth experience for both users and partners.
File Upload APIs: Handling file and document uploads, File Upload APIs are used to transfer various media files, medical documents, and other records securely to the server or storage systems, playing a crucial role in managing user data.
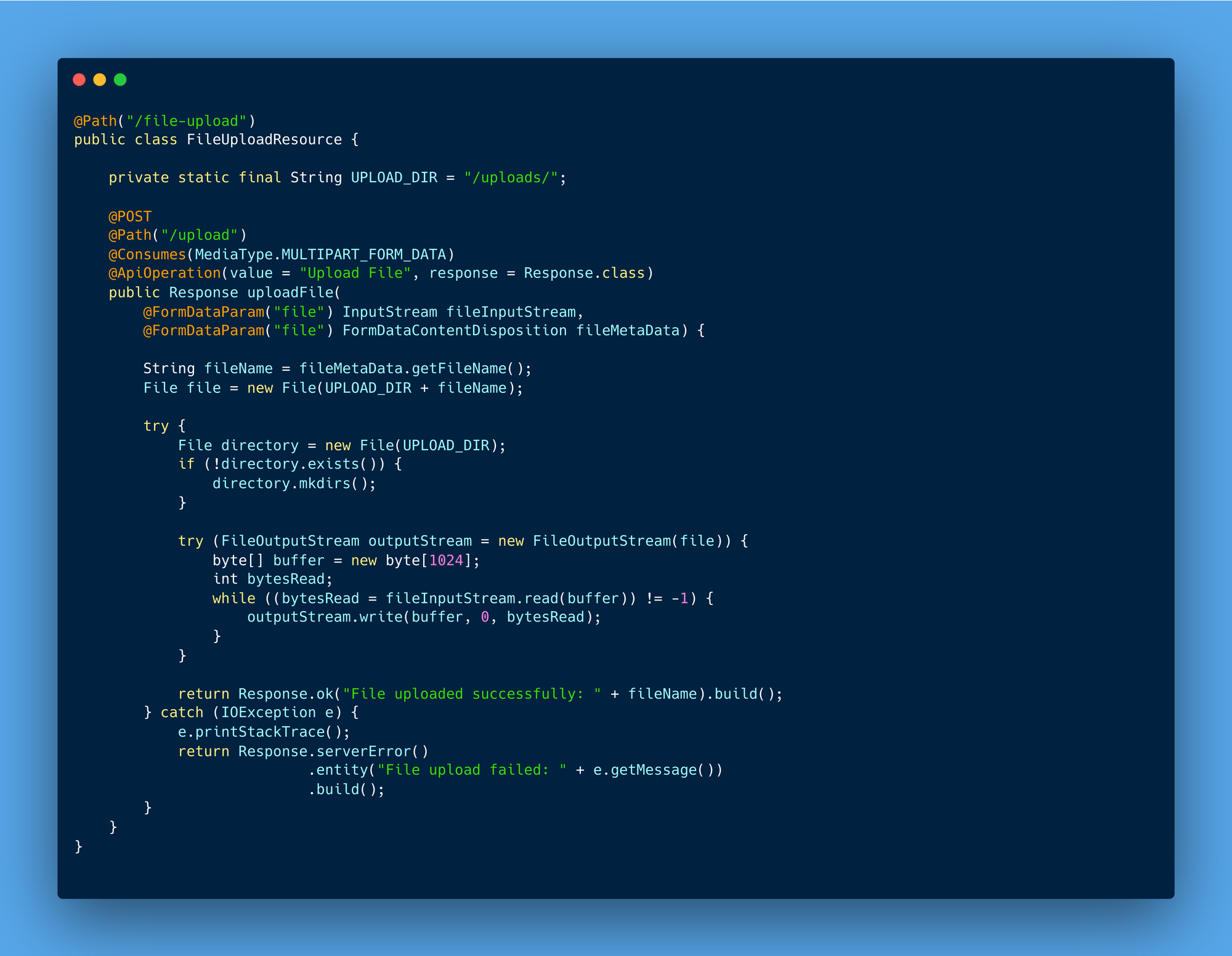
Save APIs: These APIs are dedicated to storing or creating new records within the system. Whether adding a new user profile or creating a transaction record, Save APIs ensure data is reliably stored and persisted for future use.
Update APIs: Update APIs manage the modification of existing records, allowing for data revisions. These APIs streamline updates to stored information, such as changing a user’s address or editing a profile, without duplicating records.
Scheduler Script APIs: Scheduler Script APIs are designed to automate tasks by executing scripts at scheduled times. This functionality ensures that predefined tasks are completed on time, improving efficiency by removing the need for manual intervention.
Batch Process APIs: For processing large volumes of data in groups, Batch Process APIs manage operations in batches. Ideal for handling high data loads, these APIs allow multiple tasks to be processed simultaneously, ensuring our systems remain efficient under heavy workloads.
Unlocking Insights: Tag To Track
While categorising our APIs was a crucial step, we quickly realised that relying solely on traditional config-based approaches, where settings like timeout thresholds, vertical, and category are defined outside of the core code in an external file or centralised system, would not be the most effective solution. Managing these configurations externally will introduce other challenges like
- Increased Complexity: Keeping configurations outside the code would complicate maintenance and introduce a risk of discrepancies.
- A Lot of Extra Work: With ~100 API changes or new additions every month, trying to manually sync external configs with the code would be a time sink and more prone to errors.
- Not Flexible Enough: Managing default overrides through external configurations was adding rigidity and and made the system harder to tweak when needed.
We needed something better, something that kept the process streamlined and close to the code. When managing large-scale systems with multiple APIs, understanding the nature of each API was critical. For example:
- Is the API performing a simple lookup or a batch processing task?
- Does the API handle sensitive data?
- Is it tied to a particular business vertical?
Answering these questions would have helped us prioritise monitoring, allocate resources effectively, and improve system reliability. By categorising APIs and integrating custom metadata into their monitoring workflows, the organisation could have gained actionable insights to enhance both operational efficiency and decision-making.
By implementing a reusable structure to annotate APIs with metadata, we streamlined the process of capturing and analysing crucial information during request processing. This approach ensures consistency, scalability, and actionable insights. Below is a class-by-class generic breakdown of the solution.
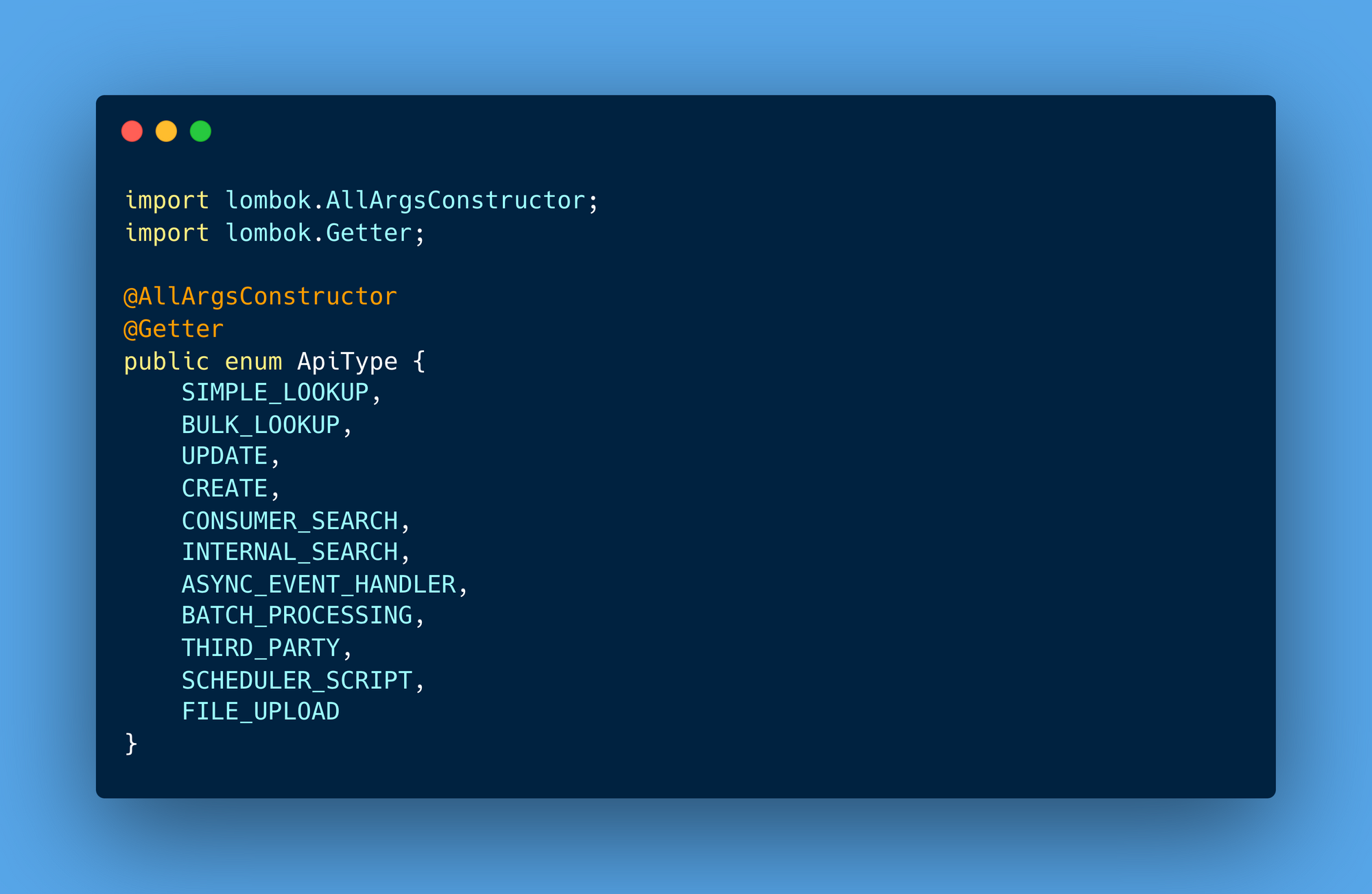
APIs serve different purposes. Using the ApiType enum, developers can assign meaningful categories like SIMPLE_LOOKUP, BATCH_PROCESSING, or FILE_UPLOAD to each API. This categorisation helps monitoring tools group similar API types for analysis, making it easier to spot bottlenecks or unusual behaviour.
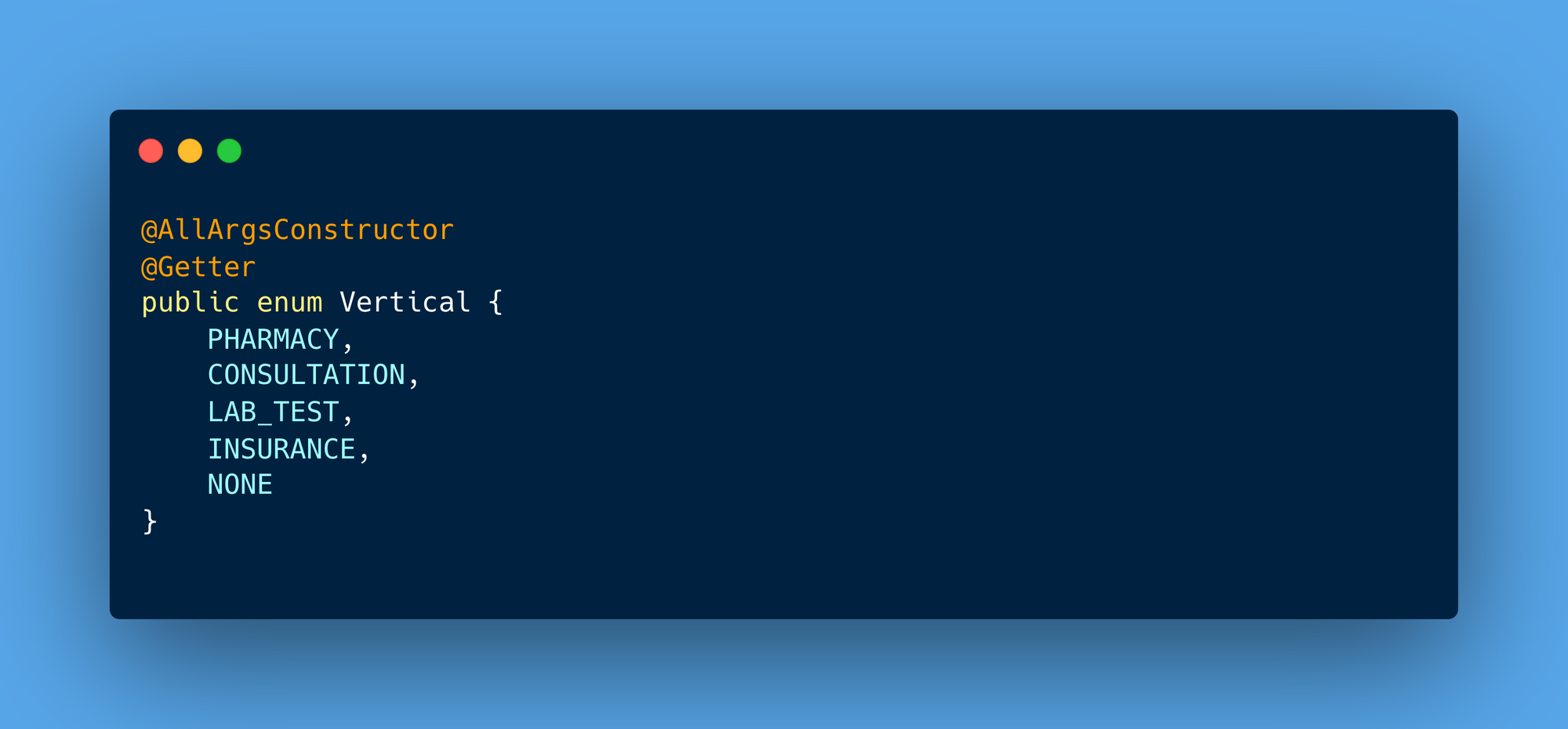
The Vertical enum allows developers to tag APIs with the relevant domain. Tagging APIs by vertical helps align monitoring with business objectives, such as tracking performance metrics for mission-critical domains.
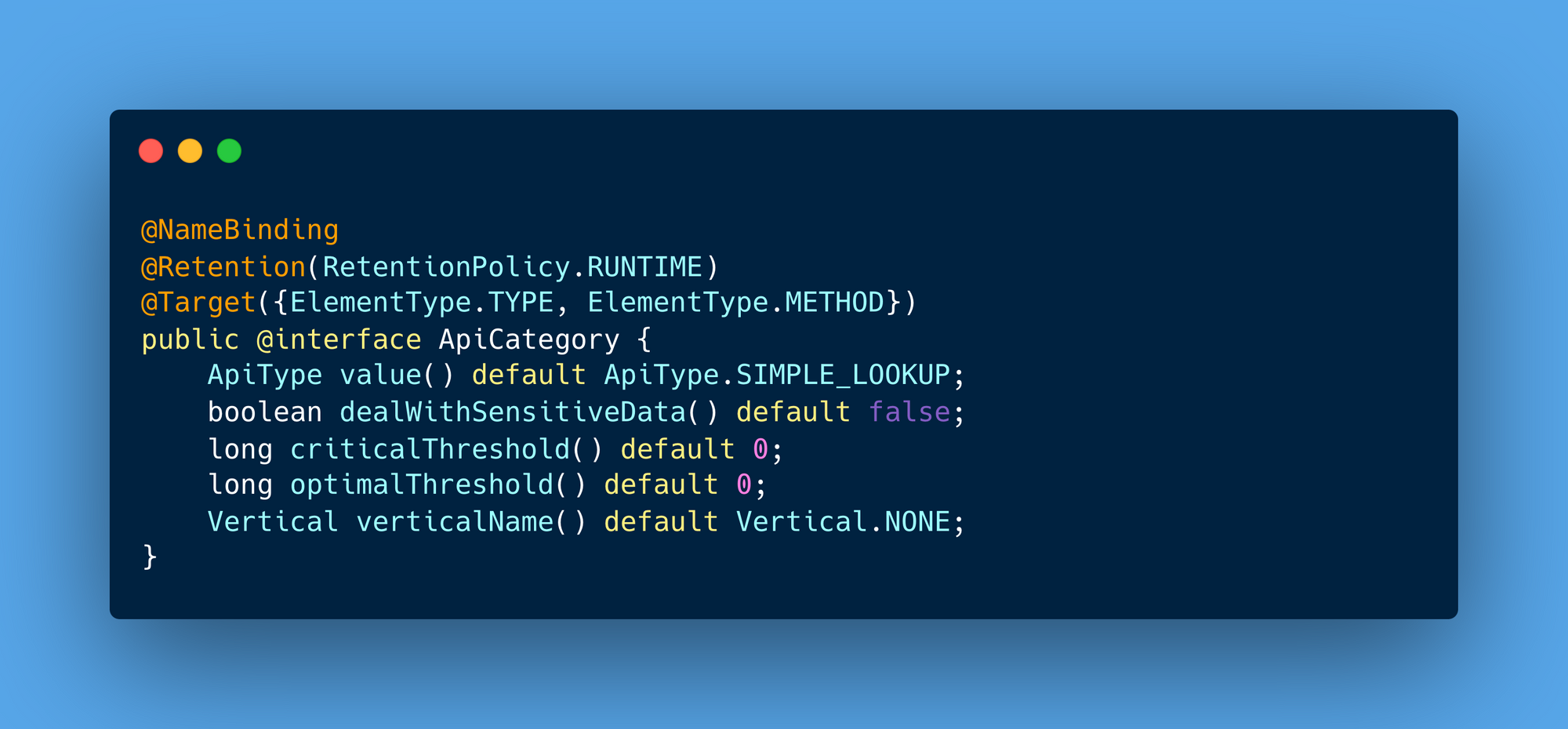
ApiCategory annotation allows developers to enrich APIs with metadata such as:
- API Type: Describes the nature of the API (e.g.,
SIMPLE_LOOKUP). - Thresholds: Defines critical and optimal response time thresholds.
- Sensitive Data Handling: Indicates whether the API processes sensitive data.
- Business Vertical: Associates the API with a specific domain.
Annotations provide a lightweight, declarative way to document and monitor APIs, ensuring consistency across teams.
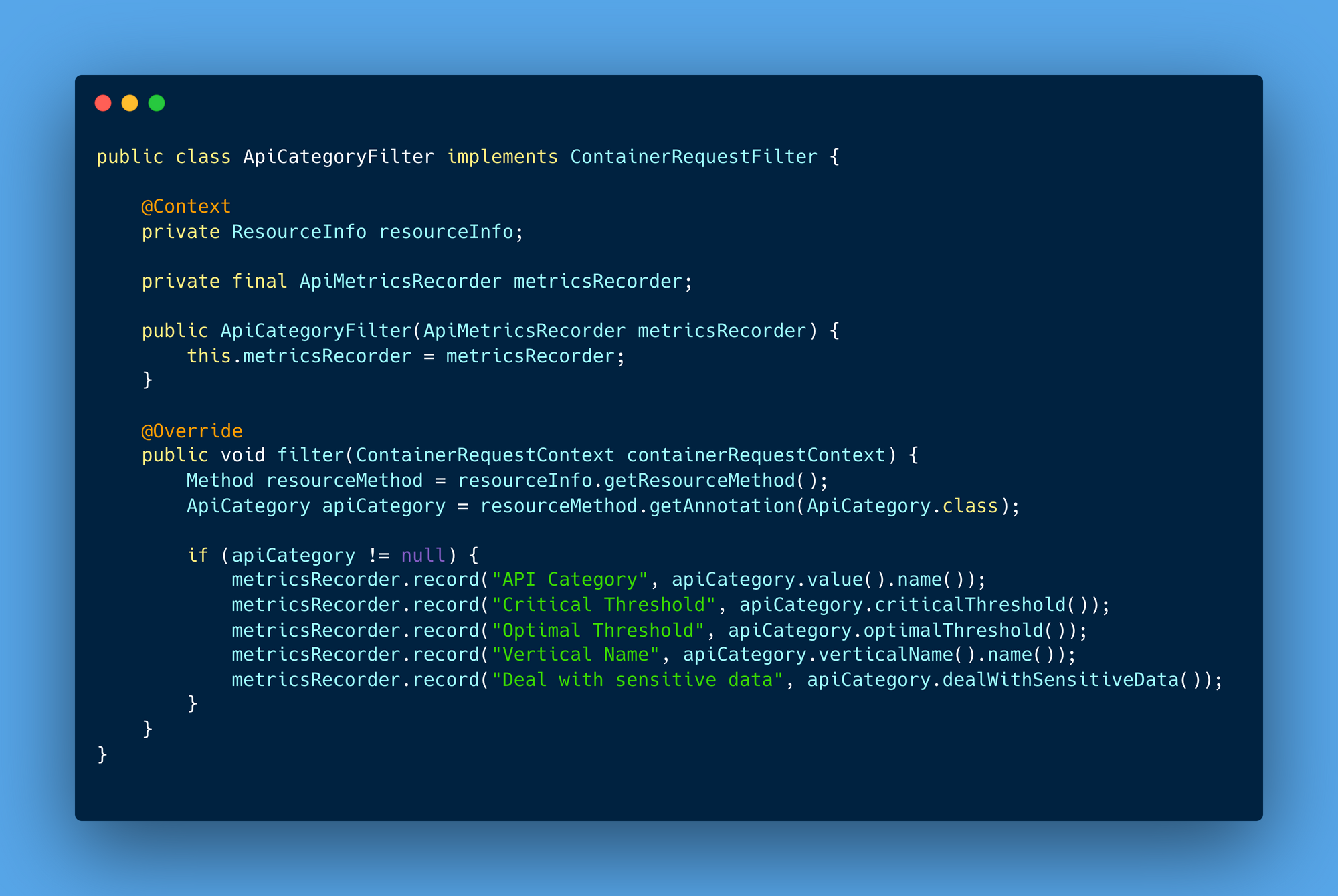
ApiCategoryFilter can act as an interceptor for API calls and extracts metadata from the ApiCategory annotation.
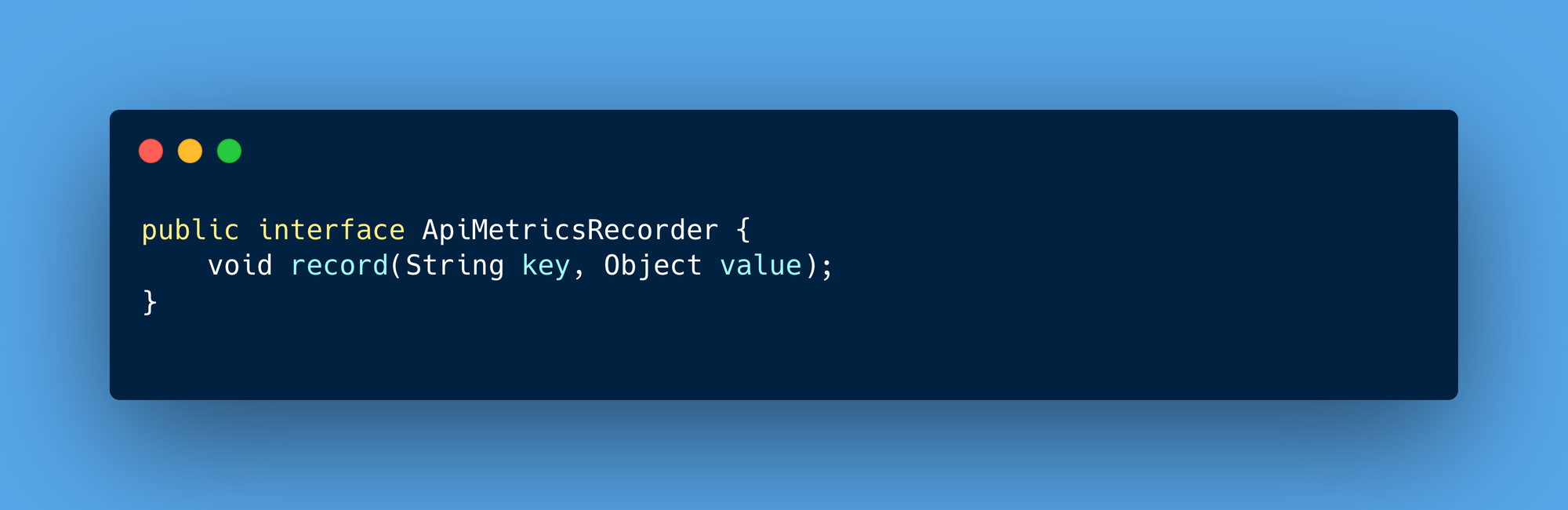
To support multiple monitoring tools, the ApiMetricsRecorder interface abstracts the metrics recording process. Developers can provide tool-specific implementations, such as one for New Relic. This abstraction ensures the solution is extensible, allowing teams to switch or integrate multiple monitoring tools without changing core logic.
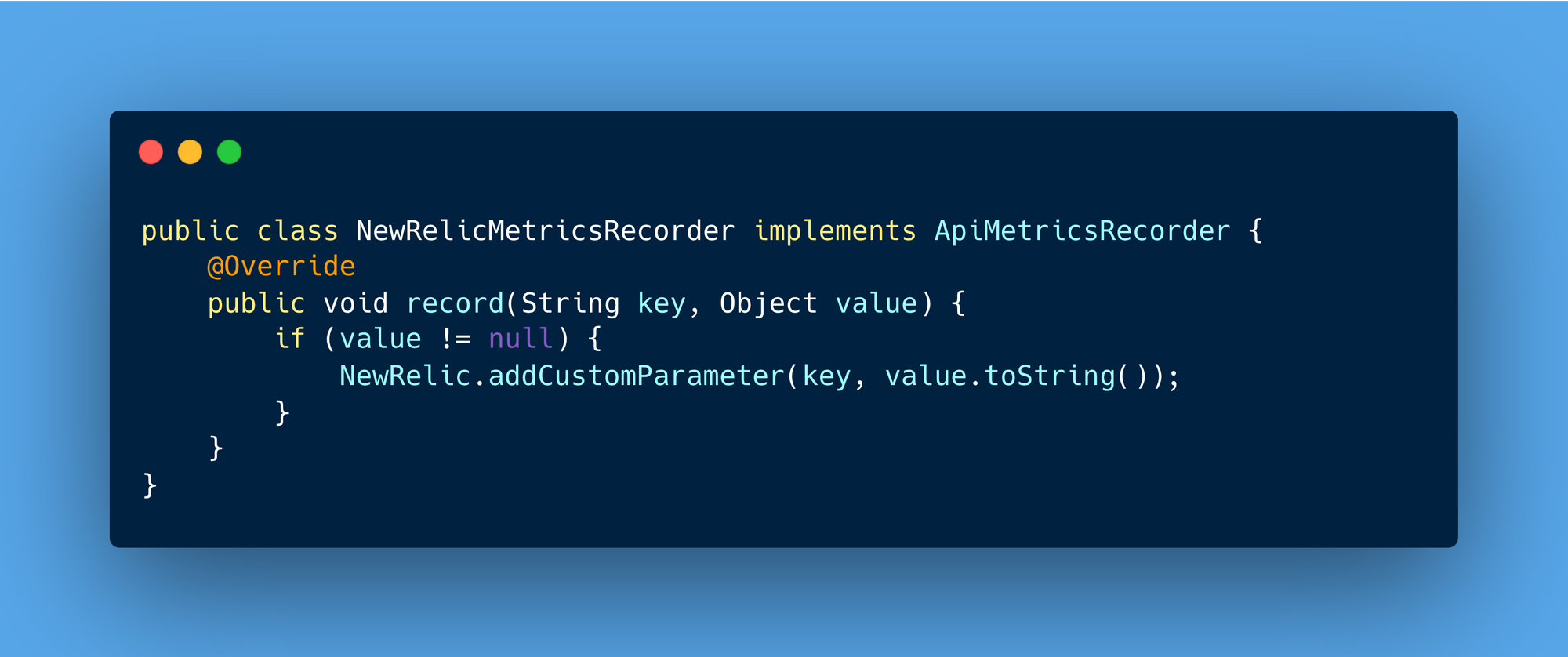
Using the NewRelicMetricsRecorder, the metadata can be seamlessly recorded in New Relic.
Consider an API that retrieves substitute product details. Below example shows how it can be annotated and processed.
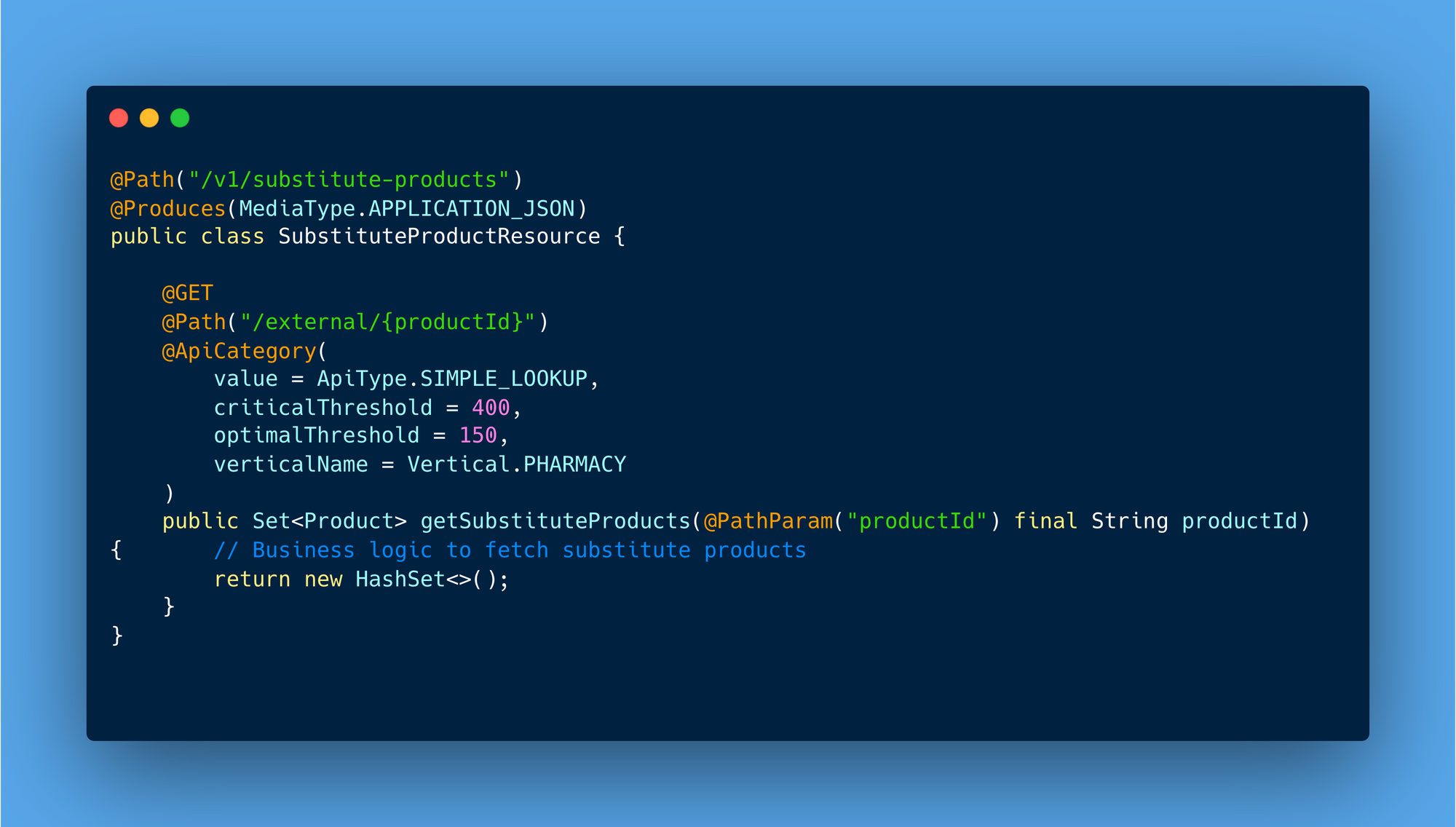
This setup ensures the API's performance is monitored within the appropriate context, e.g., tracking its adherence to the 150ms optimal threshold.
By combining custom annotations, flexible filters, and decoupled monitoring integrations, developers can enhance API observability with minimal overhead. This structured approach ensures that APIs are not just monitored but understood in the context of their business impact and criticality.
Speed or Bust: API Performance Tracking
With the API categorisation now in place, we were ready to take the next crucial step in the journey applying relevant standards to boost performance and ensure consistent quality. We knew that the key to unlocking further improvements lay in setting clear performance benchmarks for each API category. These benchmarks would serve as our guiding light, helping us identify areas that needed fine-tuning or optimisation.
"If you can’t measure it, you can’t improve it." – Peter Drucker
We started to lay down the groundwork, defining the key metrics to benchmark the performance of each API type. By doing so, we could measure success, track progress, and pinpoint areas for continuous improvement. Below table and graph shows a sample metric to tap into good, need improvement and bad apis and their continuous improvement.

But how do we track this? Continuous monitoring became our ally. We couldn’t afford to wait for issues to snowball before addressing them, so our goal was to spot any deviations from expected performance as soon as they occurred. The faster we acted, the less impact the problem would have.
To keep things running smoothly over time, we established a structured process for periodic performance evaluations. These regular assessments would allow us to catch any emerging issues before they became critical, ensuring that our APIs remained fast, reliable, and efficient.
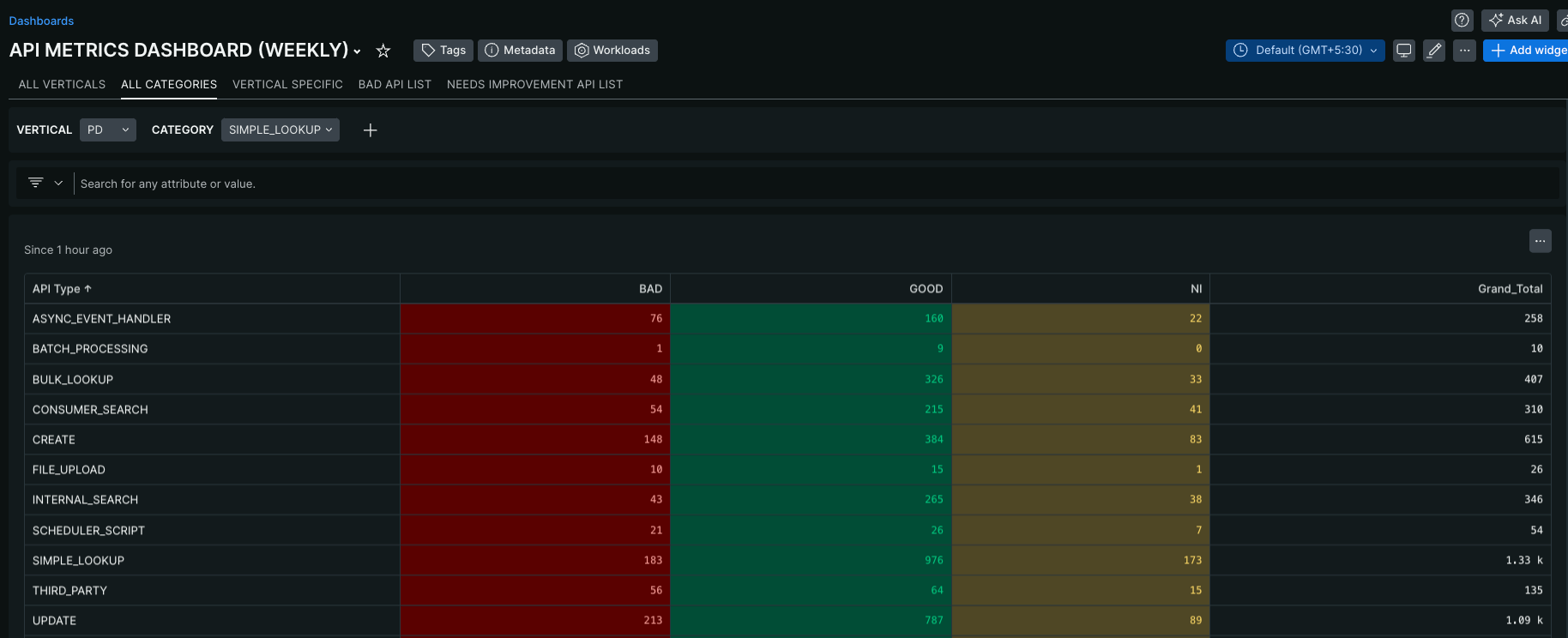
Although we had defined the benchmarks to fit most APIs accurately, our monitoring uncovered a few outliers. While these APIs were correctly categorised, they did not align with the optimisation benchmarks. To prevent false positives and avoid confusion in our continuous monitoring, we chose to exclude these outliers from the defined categories. To address scenarios where APIs have distinct requirements, we introduced the ability to override thresholds directly at the API level. In the code snippet shared, criticalThreshold and optimalThreshold can be customised for specific APIs, if not mentioned specifically it will pick default values. This flexibility ensures that outliers are neither penalised unfairly nor excluded from monitoring altogether. By allowing threshold overrides, we align our performance evaluation with the unique characteristics of these APIs while maintaining a standardised approach for the majority.
API Magic: Dos, Don’ts & Pro Tips!
During development of API resources, the following best practices, dos, and don’ts ensure efficiency, scalability, and maintainability.
For Simple Lookup APIs, prioritise minimising joins and complex queries by breaking down large queries where possible, using proper indexing for fields in WHERE clauses, and leveraging caching to reduce repeated database hits. Avoid retrieving unnecessary data and implement rate limiting to prevent abuse. Performance best practices include lazy loading, data sharding, and read replicas.
For Bulk Lookup APIs, use batch requests to combine multiple queries and optimize data retrieval by indexing and reducing duplicate database calls. Avoid returning excessive data and always test performance impacts when handling multiple requests. Bulk data fetching and connection pooling are recommended to manage traffic effectively.
Consumer Search APIs benefit from data indexing and filtering options to enhance search precision. Avoid complex queries with extensive joins on non-indexed columns, and use search engines like Elasticsearch for scalable search. Support for partial matches and typo tolerance ensures a better user experience.
Internal Search APIs require full-text search indexing and pagination. Avoid overly complex queries, ensure result relevance, and employ search engines for scalable internal search solutions. Implement wildcard and typo tolerance in queries for better accessibility.
For File Upload operations, validate file types and sizes, use streaming for large files, and consider chunked uploads for reliability. Avoid blocking the main thread and ensure files are securely stored. Utilise CDNs and asynchronous processing for better performance.
In Save (Create) operations, wrap database changes in transactions, optimize for short-lived transactions, and consider batch inserts to handle large data volumes efficiently. Use DTOs for data transfer, sanitise inputs, and enforce security checks to prevent unauthorised access. Avoid processing multiple unrelated actions in a single API call and keep payloads minimal.
For Update (Modify) APIs, validate changes, use transactions, and ensure concurrency checks to maintain data integrity. Avoid over-fetching or under-fetching data and overload on single endpoints. Optimistic locking and partial updates can help manage resource usage effectively.
Scheduler Scripts should log execution events, handle retries on failure, and ensure query efficiency. Avoid long-running tasks by breaking them into smaller chunks and scheduling them during off-peak hours. Parallel processing can enhance efficiency.
Async Event Handlers should acknowledge messages post-processing and scale consumers to handle workloads efficiently. Avoid blocking the consumer thread, handle errors appropriately, and use parallel processing for optimal performance.
For Batch Processing, process data in chunks, log progress, and apply retry logic for failures. Avoid processing large datasets at once, and ensure SQL queries are optimised. Using on-demand environments and parallel processing helps manage large data volumes effectively.
When integrating Third-Party services, follow a modular design, adhere to best coding practices, and provide comprehensive documentation. Avoid tightly coupled designs and ensure performance optimisation is part of the integration strategy.
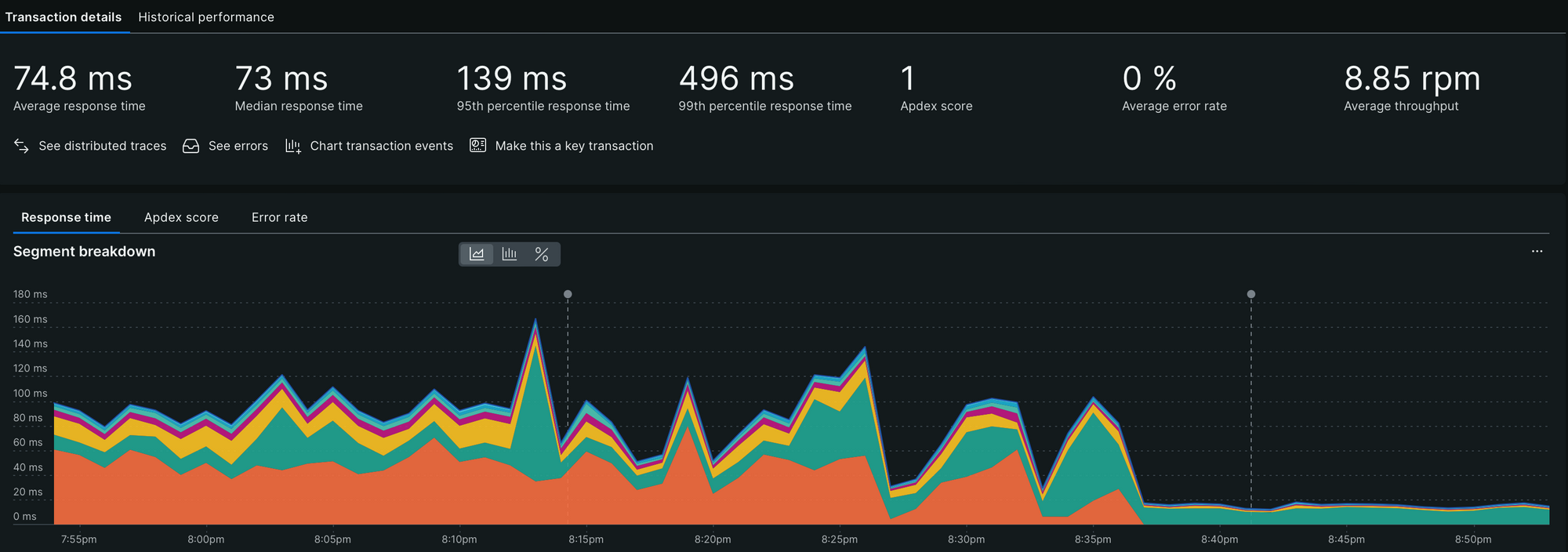
Impact
Using New Relic data, we meticulously tracked high-latency APIs and applied the best practices outlined earlier. These efforts yielded significant performance improvements, which are clearly reflected in the graphs below. They showcase reduced latencies and increased throughput across different APIs in production following our optimisation initiatives.
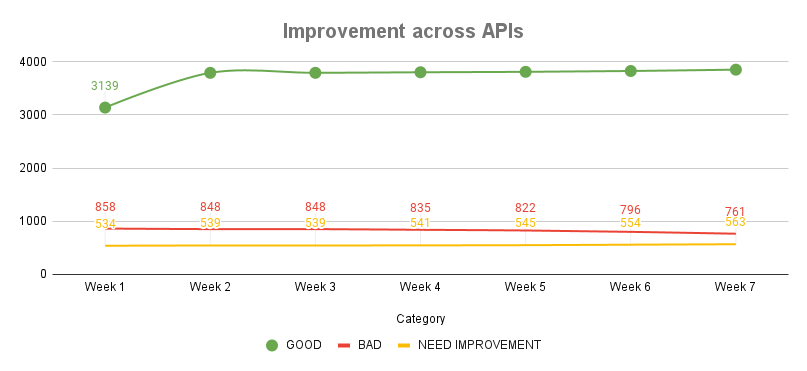
The graphs highlight a positive shift, with a growing number of APIs falling into the "Good" category, accompanied by a steady decline in both "Bad" APIs and those which need performance improvement. An added advantage of categorising APIs with tags is the ability to monitor trends within individual categories, offering deeper insights into performance gains. Refer to the graphs for category-specific trends.
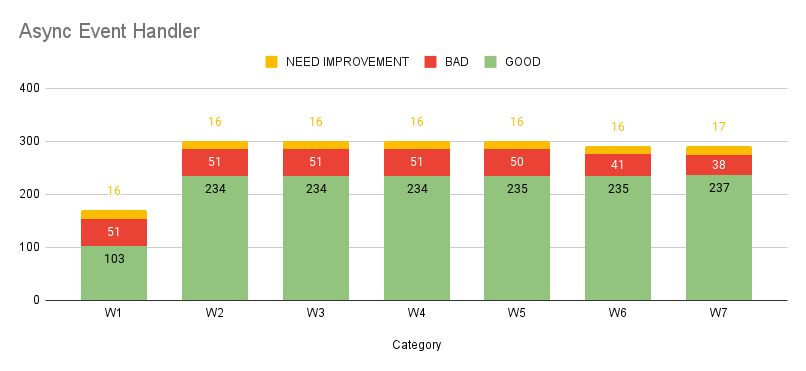
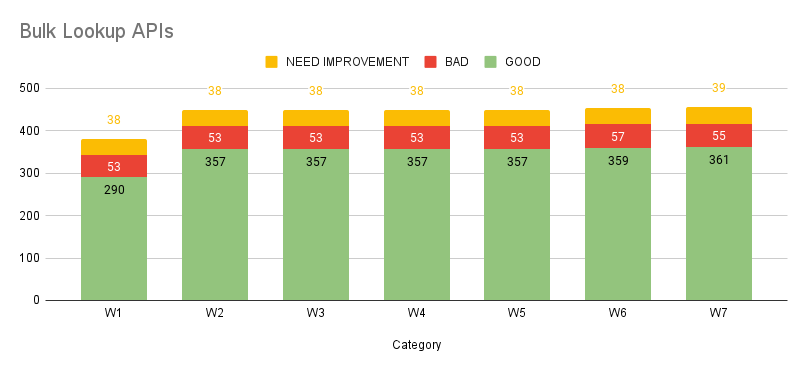
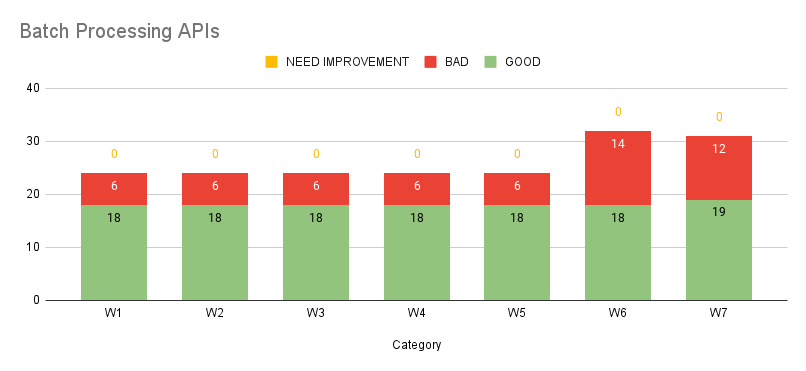
On an individual level, optimisations were tailored to the unique challenges of each API type. For batch processing APIs, we implemented chunked data processing to enhance efficiency. Search APIs benefited from strategies like improved caching mechanisms for faster retrieval. For database-intensive APIs, adding proper indexes significantly reduced query times. By addressing performance issues category-wise and adopting best practices, we have not only improved category-level trends but also achieved measurable gains at the API level
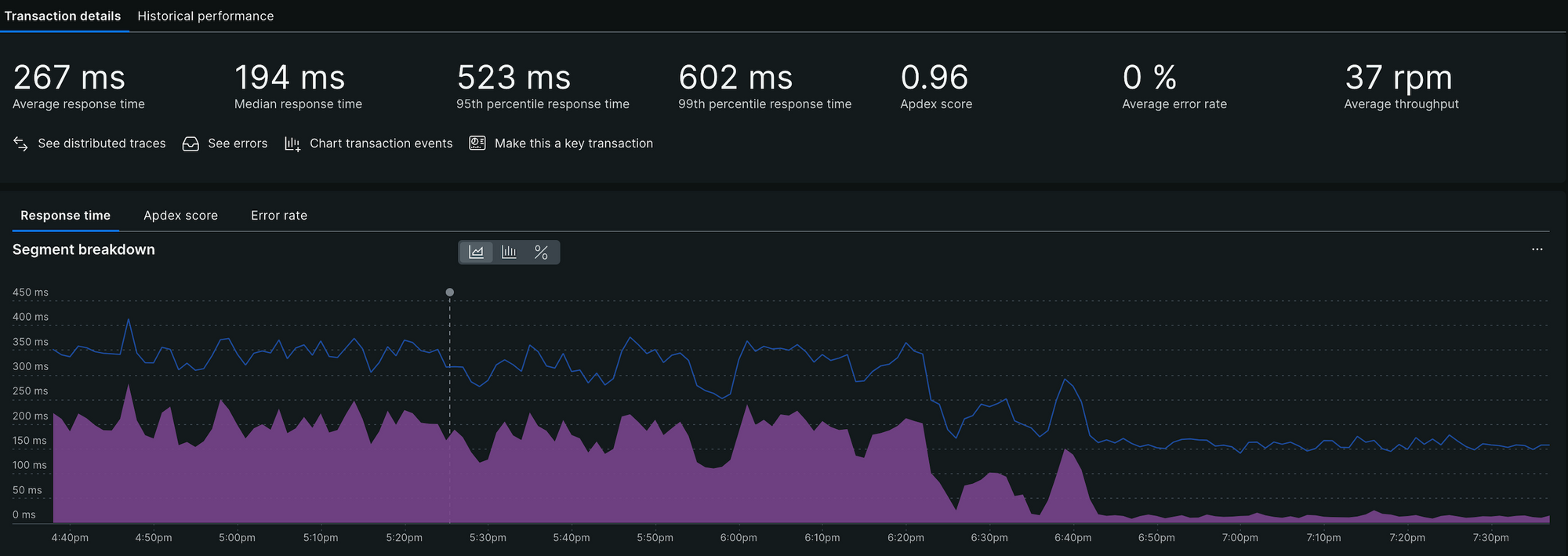
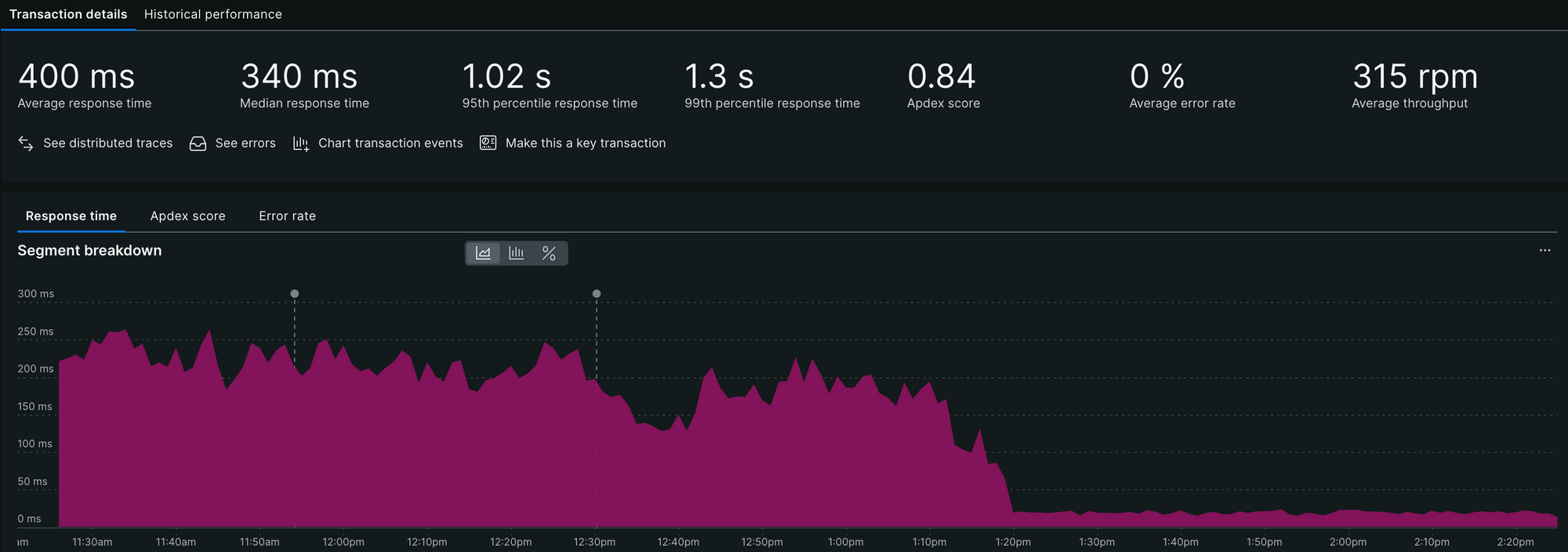
Conclusion
By categorising APIs and applying these best practices, we have significantly improved API performance, enhanced user experience, and optimised resource utilisation. This structured approach to API development is crucial for maintaining a high-quality user experience and achieving operational excellence. At Halodoc, we remain committed to leveraging technology to enhance the patient experience, and we look forward to continuing to innovate and evolve our services.
Join Us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels, and if solving complex problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. We recently closed our Series D round and In total have raised around USD$100+ million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia


