

Improving query performance in ElasticSearch at scale
With the number of doctors for online consultations and hospital appointments growing at a massive scale on Halodoc platform, managing doctor schedules was becoming a nightmare for operations. Our in-house calendar management microservice (called 'Kuta') built for the management of schedules of any entity on our platform. It is primarily catering to our use case of easy management of the schedules of our partner doctors. This microservice was built around the concept of calendars, events, and participants with the capability to handle multiple time zones. Due to the relational aspects of these entities, an RDBMS, MySQL in our case, was the most natural choice of persistence.

Kuta did solve our operational pain point of managing our doctor partners' schedules, by giving them the flexibility of creating events to indicate the availability, and unavailability of the doctors, with an optional recurrence of up to 2 years (configurable) in the future. But, the performance of displaying the doctors' availability on our customer app started deteriorating with the increase in the data. This blog is an overview of our learnings from solving database bottlenecks for timestamp query intensive data.
Where timestamp-based data comes into the picture?
Each of the entities on our platform (e.g. doctor) is associated with a unique calendar in Kuta. The major chunk of the persisted data for the above-mentioned microservice are the events recorded for these calendars. Each of the calendar events created has, a start time, an end time and the timezone, along with additional parameters indicating the source of creation and the participants of each of the events. The querying needs of the consuming applications revolved around computing the availability of the doctors based on the current time.
Evolution of the persistence layer used, with the increase in data
With the number of event records crossing the 5 Million mark, during peak hours or at the time of TV commercials being aired, the increased concurrent timestamp-based queries caused production downtimes. As a resort to this,
- The first performance enhancement made was to store a denormalized form of the events data in Elasticsearch for improved retrieval times
- The trade-off which we had to make was to maintain synchronisation between the data in MySQL and Elasticsearch
The choice of using Elasticsearch as the secondary database was made due to,
- Timestamp based querying and aggregation support which Elasticsearch provides
- Stability of the existing tooling built around Elasticsearch at Halodoc (being the default secondary datastore of choice by practice)
Index mappings and querying pattern description
The following indicates the key mappings from our events index (only contains the fields which are used when querying and relevant for the example),
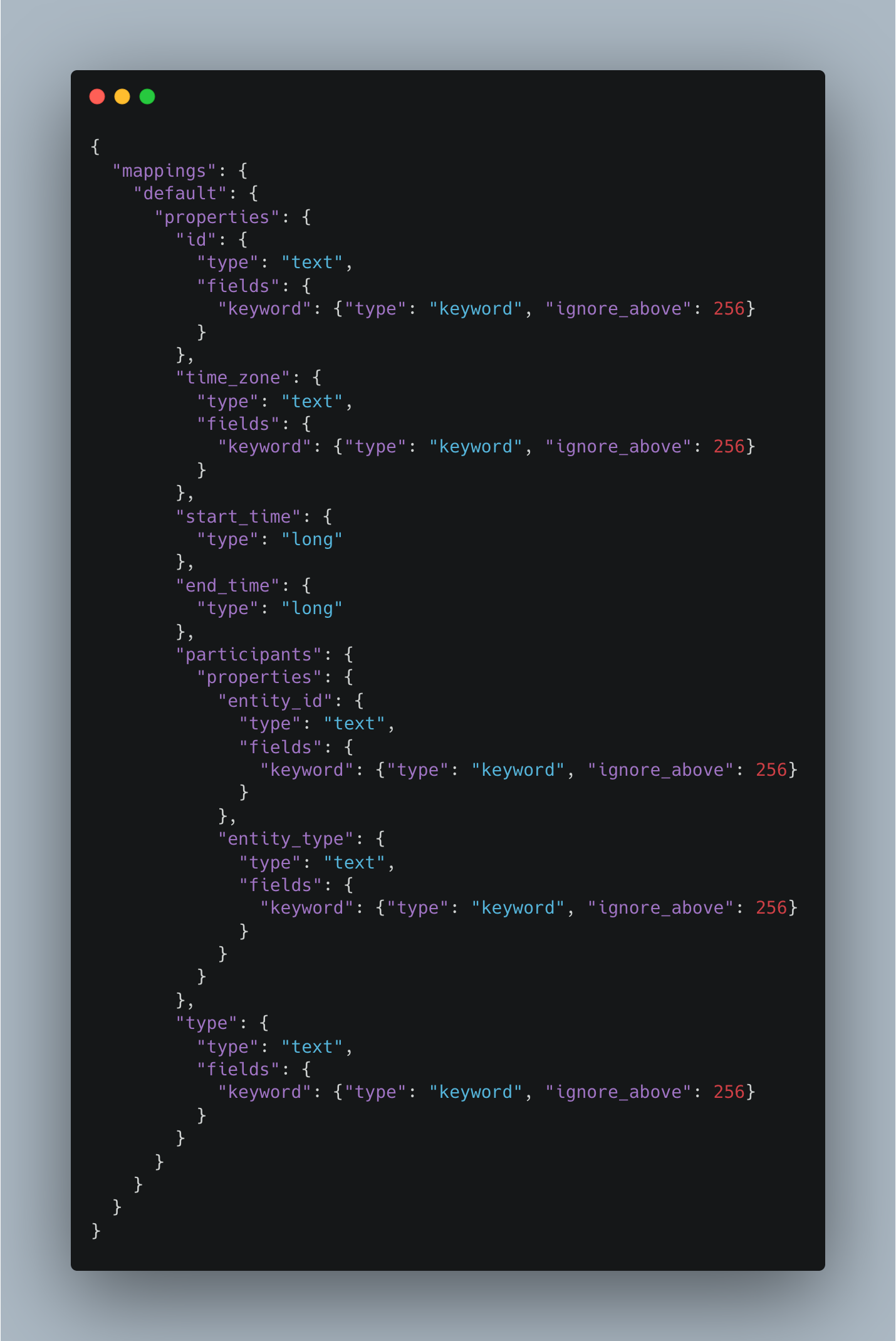
Queries on the above index were to filter documents containing a specific user's (identified by a combination of entity_id and the entity_type) events falling within a given timeframe (identified by the querying on the start_time and end_time) and which is of a certain type.
Issues faced with the increase in data
With the number of events rising by the day to over 14 Million event documents in the Elasticsearch index, we continued to face an occasional increase in query execution times during peak traffic. The major bottleneck in our case was the high CPU utilization in the data nodes of our cluster.
Before, moving to the optimisations, it is important to introduce the following prerequisites
- Partitioning and the partition strategy in Elasticsearch
- Distributed searching
Partitioning and the partition strategy in Elasticsearch
When using a single disk to store data, like when using MySQL in our case, it starts becoming increasingly insufficient as the size of the data starts to grow. Distributed databases, including Elasticsearch, overcome this by partitioning the database into smaller chunks. Each node in the cluster is responsible for handling requests to one or more partitions. The primary use of partitioning is scalability. In Elasticsearch, these partitions are known as shards. Each node of the Elasticsearch cluster can serve queries independently for the partition it manages, thereby increasing query throughput.
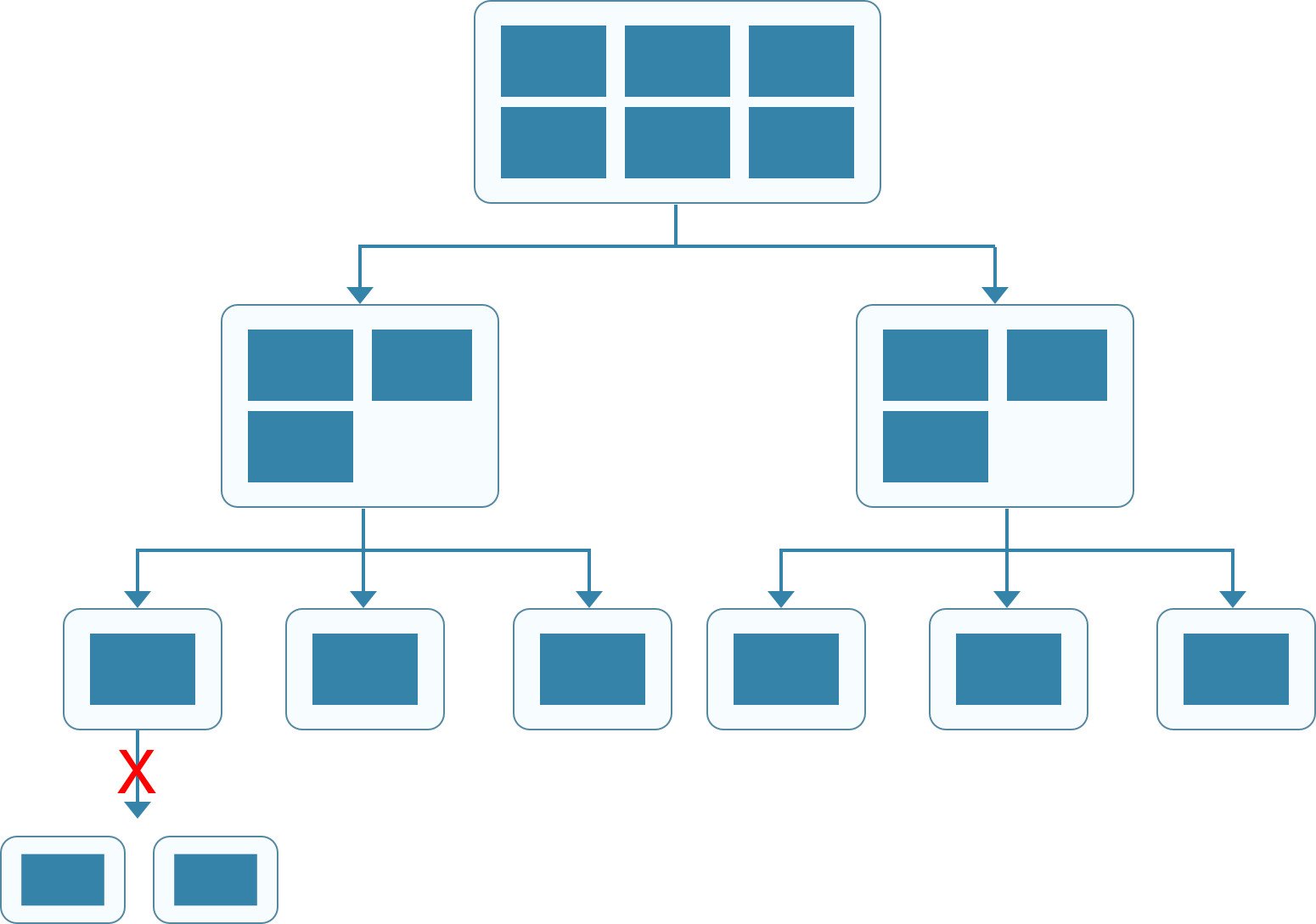
Deciding the number of partitions becomes non-trivial in the case of Elasticsearch as,
- The number of partitions is fixed at the time of the index creation. Each partition is an indivisible chunk of data which can grow in size but not be split into smaller chunks. As the data grows, more nodes may be added to the cluster, but the number of partitions which eventually move to the newer nodes are limited (Fig 3)
- In some sense, as the data grows the database drifts away from being horizontally scalable to being vertically scalable. This to a level can be combated by increasing the replication factor (can be altered post index creation) to effectively increase the number of shards but, the unique shard itself will vertically increase in size with increased data
- Partition size (a deciding factor for the number of partitions) should be chosen such that it accounts for future data growth and at the same time should not be very small as it leads too much overhead when querying. Any changes to the number of partitions require a reindexing and a possible downtime
Distributed searching
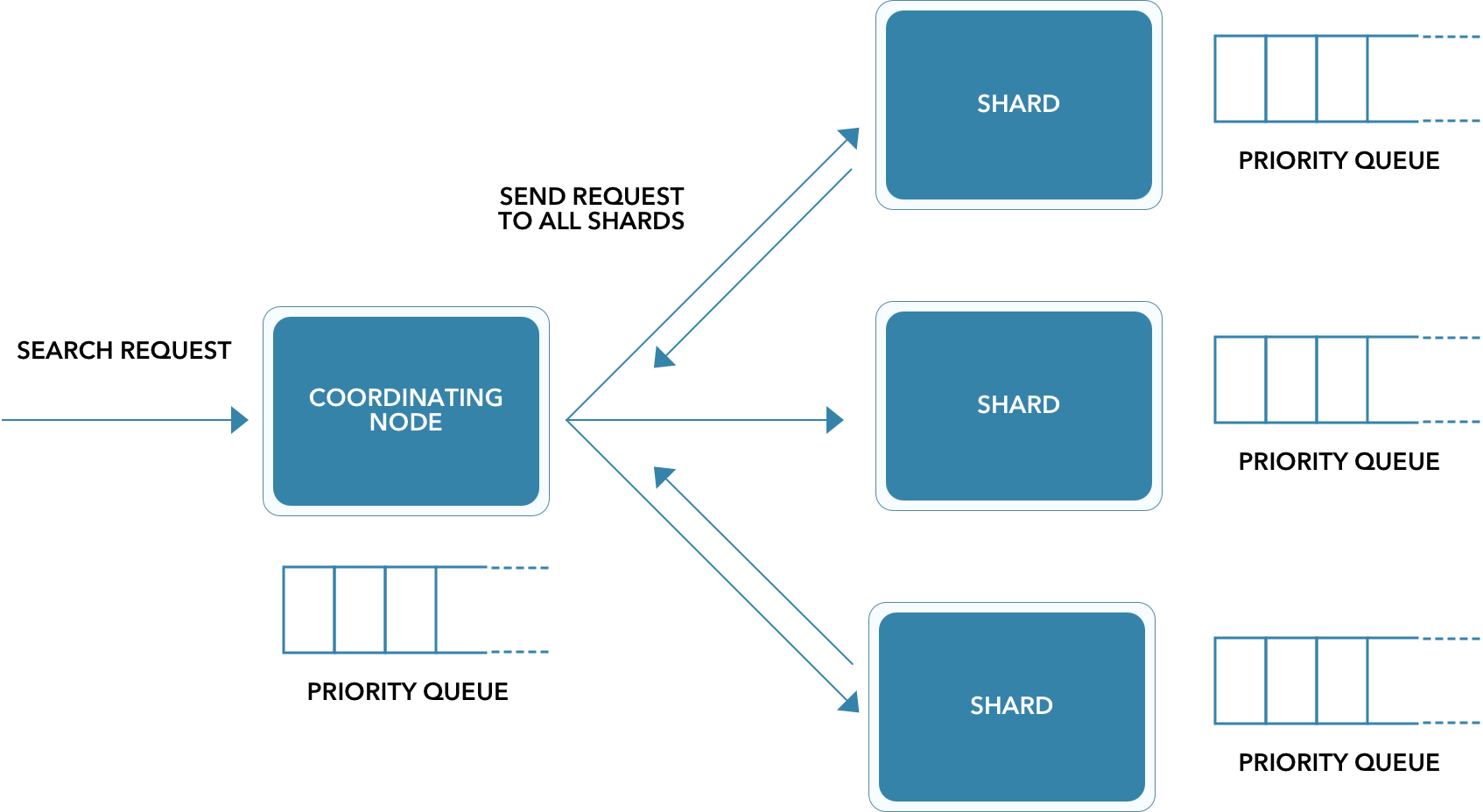
A search request can be accepted by any node in the Elasticsearch cluster. Each of the nodes in the cluster is aware of all the other nodes. The catch being that, the node receiving the search request, by default is unaware of where the data that is to be queried resides. Hence, the node has no choice but to broadcast the request to all the shards and then gather their responses into a globally sorted result set that it can return to the client (Fig 4).
The process of determining which shard a particular document resides in is termed as routing. By default, routing is handled by Elasticsearch. The default routing scheme hashes the ID of a document and uses it as the partition key to find a shard. This includes both user-provided IDs and randomly generated IDs picked by Elasticsearch. Documents are assigned shards by hashing the document ID, dividing the hash by the number of shards and taking the remainder.
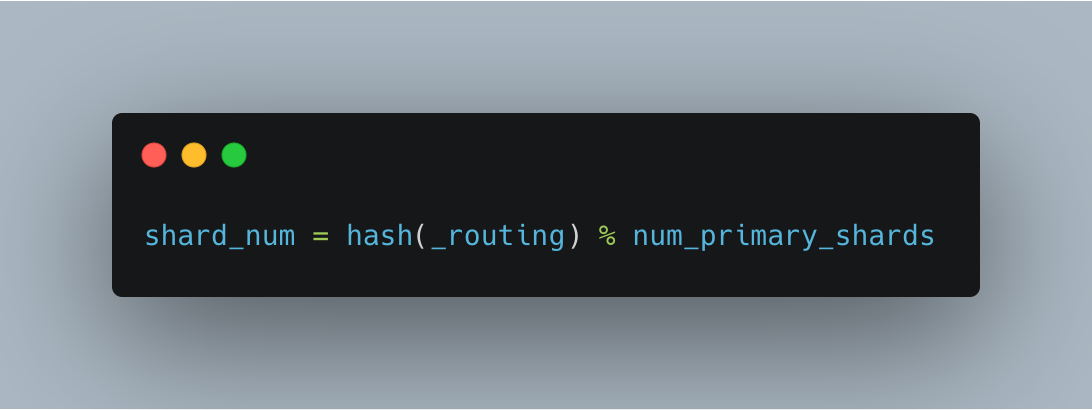
_routing being the document’s _id)The formula in Fig 5 is one of the reasons why Elasticsearch does not allow the update of the number of primary shards post index creation. What the default routing guarantees is that the data will be uniformly distributed across the cluster which would reduce query hotspots when retrieving documents. Elasticsearch relies on simple routing as it accounts for the total number of shards to compute which shard a given document is to be assigned to, instead of approaches like consistent hashing (hashing independent of the total number of shards).
Custom routing to the rescue
Elasticsearch being flexible, provides the capability to define a custom routing strategy. Custom routing ensures that all documents with the same routing value will locate to the same shard, eliminating the need to broadcast searches. To define a custom routing, a routing key (_routing) needs to be explicitly set for each of the documents.
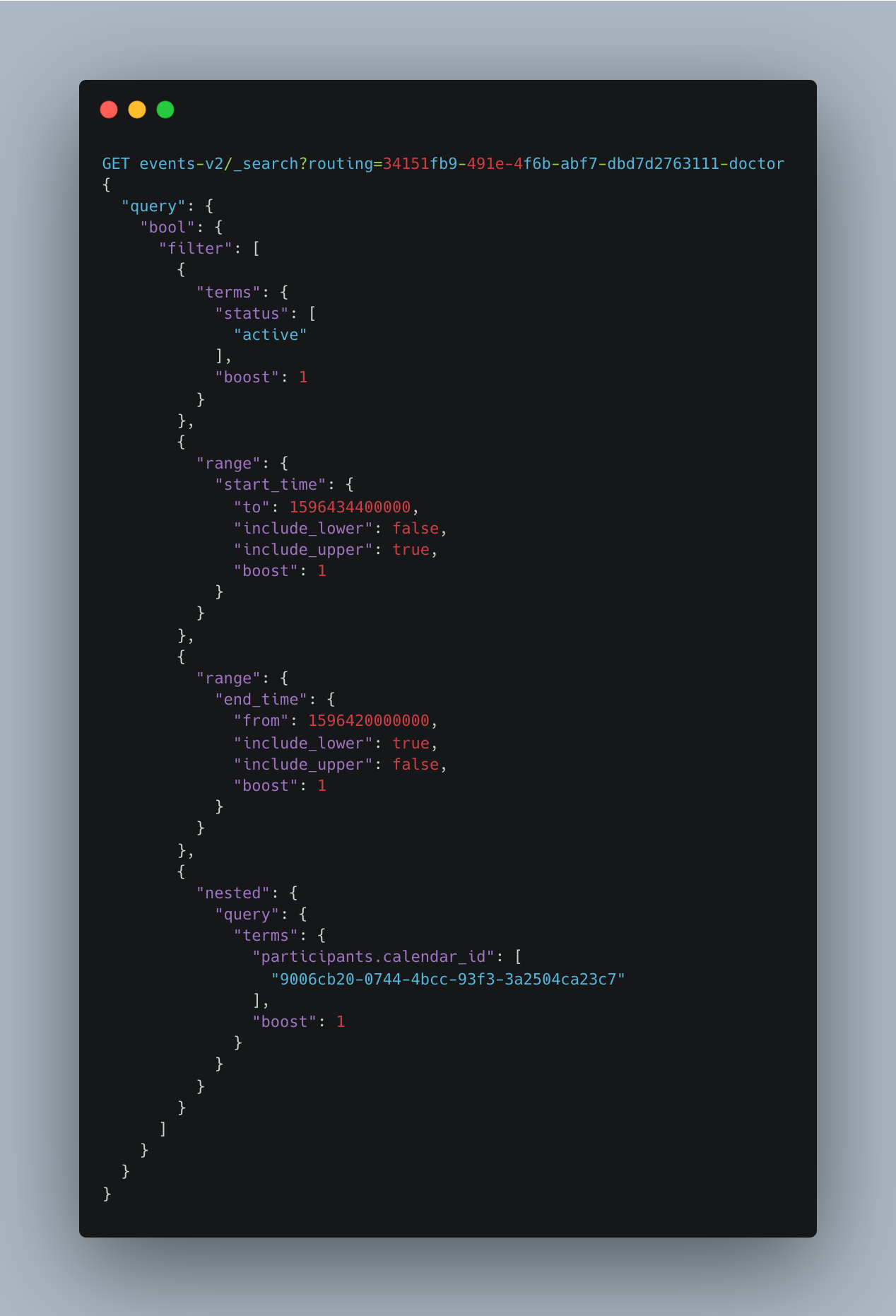
To ensure an even distribution of data across the cluster, we require an even distribution of numbers coming out from the Elasticsearch hashing algorithm which takes the _routing value of the document as the input. The choice of the routing key in our case was a combination of the unique identifier (UUID) and type of the primary participant of each event in a calendar. This choice was made based on the querying patterns of the consuming application and to maintain a degree of uniqueness.
Pros
- The query speeds improve as, instead of instructing Elasticsearch to
Get all the data matching..., you sayGo there and get all the data matching...(Fig 6). If you are querying data with multiple unique routing keys, this guarantees better or equivalent query performance as that of the default routing strategy (reducing the scatter and gather) - The increase in the number of shards does not affect query performance. Custom routing ensures that only specific shards mapped to the provided routing keys are queried
We achieved ~40% improvement in response times, ~15% reduction in the average CPU utilizations of the data nodes in the cluster, and better overall availability of the application post introducing custom routing.
Cons
- If it does not fit your use case, this can very easily introduce query hotspots. As multiple routing keys with a large number of actively queried documents can get directed to the same shard
The "Painless" data migration
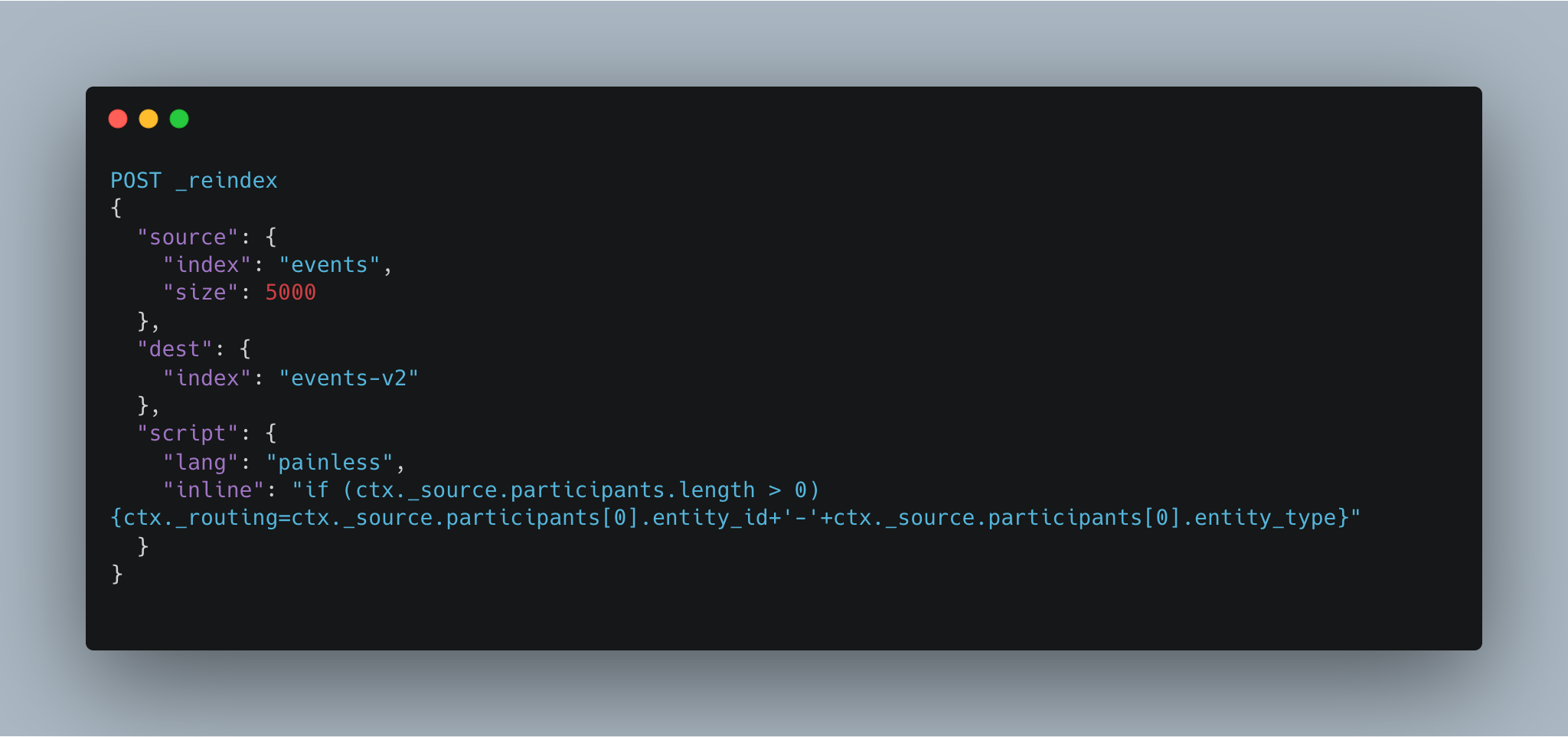
- Another challenge was to incorporate the above changes for the existing data i.e. increasing the number of shards and defining a custom routing key for each of the document. The existing index had close to 33 MN documents at the time of the change
- Given that the routing key and the number of shards needed to changes, a new index had to be created and the existing data was to be reindexed
- Routing Key: In our case, a combination of certain fields of the document itself had to be used as the routing key
- Using the reindex API provided by Elasticsearch (which also supports batching) along with the help of painless (a scripting language compatible with elasticsearch) made this easy. (Fig 7 - Indicating reindexing data from events to events-v2)
Conclusion
The use of Elasticsearch with a combination of custom partition routing helped us improve both the query performance and the overall availability of the application. Further steps would include coming up with an automated strategy to archive the data in the above Elasticsearch index!
Join Us
We are always looking out for top engineering talent across all roles for our tech team. If challenging problems like this, that drive big impact, enthral you, do reach out to us at careers.india@halodoc.com
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek and many more. We recently closed our Series B round and In total have raised USD 100million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.
Further Readings
- When routing does matter - Rafał Kuć, Marek Rogoziński, Available at https://subscription.packtpub.com/book/big_data_and_business_intelligence/9781849518444/1/ch01lvl1sec18/when-routing-does-matter.
- Customizing Your Document Routing - Zachary Tong, Available at https://www.elastic.co/blog/customizing-your-document-routing.


