
Log Standardization: Best Practices for Achieving End-to-End Traceability
Introduction: Consistent and Traceable Logging
Imagine you're investigating a critical system failure in a complex microservices ecosystem. You open the logs, expecting a clear trail of events—but instead, you find scattered, disconnected messages across multiple services, concurrent tasks, and Kafka queues. It's like trying to solve a puzzle with half the pieces missing.
Without a standardized logging approach, debugging becomes a nightmare. Finding the root cause of an issue means manually correlating logs across various services, tracking requests through multiple systems, and dealing with lost context in concurrent operations.
This blog explores how we achieve structured logging across HTTP requests, Kafka events, and concurrent processing in Java, Golang, and Python. We also discuss how to overcome Context Loss in Java's multi-threaded environments by wrapping CompletableFuture and ExecutorService as MDCAwareCompletableFuture and MDCAwareExecutorService—ensuring traceability even in highly concurrent systems.
The Challenge: Tracing Complexity in Distributed Systems
Let’s say a user initiates a request in your application. That request triggers multiple microservices, each making its own HTTP calls, producing Kafka events, and executing Concurrent tasks. Now imagine an error occurs midway—how do you trace its origin?
Here are some common challenges we face in such scenarios:
1. Tracing Complexity Across Microservices
- Each microservice processes requests independently, making it difficult to correlate logs across services.
- Debugging failures requires manually searching logs across multiple services without a consistent transaction identifier.
2. Kafka Operations
- When a service publishes an event to Kafka, the consumer processing the event had no direct link to the original request.
- This lack of correlation made it challenging to trace an event’s lifecycle, especially when multiple services consumed and reacted to the same event.
3. Context Loss in Multi-Threaded Environments
- Concurrent tasks (executed via CompletableFuture or ExecutorService) did not retain the original transaction context.
- Logs for concurrent operations appeared detached from the originating request, making debugging cumbersome.
Without a standardized logging approach, logs are fragmented, debugging is time-consuming, and system failures become harder to resolve. It’s like trying to find a needle in a haystack.
Standardization of Logging Across Operations
To solve these challenges, we implemented a structured logging approach that ensures every request, Kafka event, and Concurrent operation retains a traceable identity.
At the core of our approach are three key identifiers:
- Request ID: A globally unique identifier that remains constant across all services for a given request, ensuring cross-service traceability.
- Transaction ID: A unique identifier generated for each operation (HTTP call, Kafka event, Concurrent operation), allowing granular tracking.
- Parent Transaction ID: Links each operation to its predecessor, maintaining a clear request flow.
With these identifiers embedded in logs, debugging becomes straightforward. Monitoring tools like New Relic and ELK Stack can now stitch together related events, providing a complete picture of a request’s lifecycle.
How This Approach Solved Our Challenges
By implementing standardized logging, we created a reliable way to track request flow across services, message queues, and concurrent tasks. This approach ensures that every log entry maintains a consistent trace, making it easier to debug failures and monitor system performance.
Here’s how this strategy improved traceability across different operations:
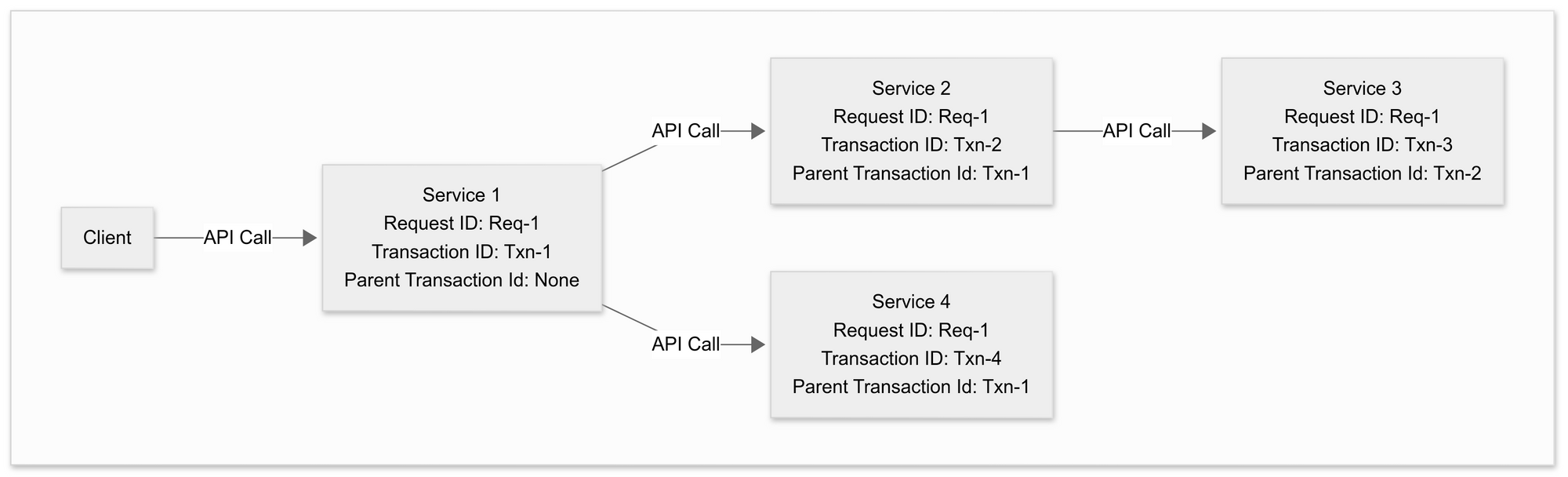
1. For HTTP Calls
- Every incoming request generates a new Transaction ID, ensuring each operation within a service is uniquely identifiable.
- The Parent Transaction ID links related service calls, enabling seamless traceability across multi-level HTTP interactions.
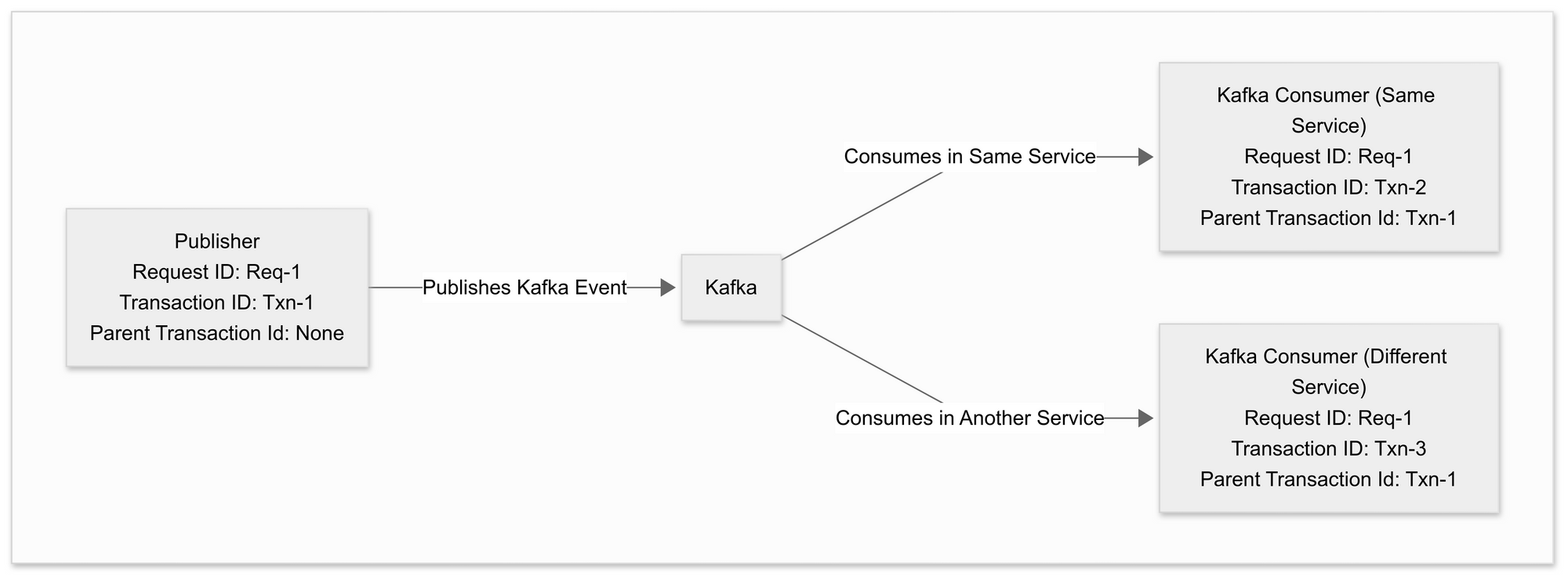
2. For Kafka Operations
- The Kafka producer propagates the Transaction ID with the event.
- Consumers derive a new Transaction ID while retaining the Parent Transaction ID, establishing a direct link between producers and consumers for better event traceability.
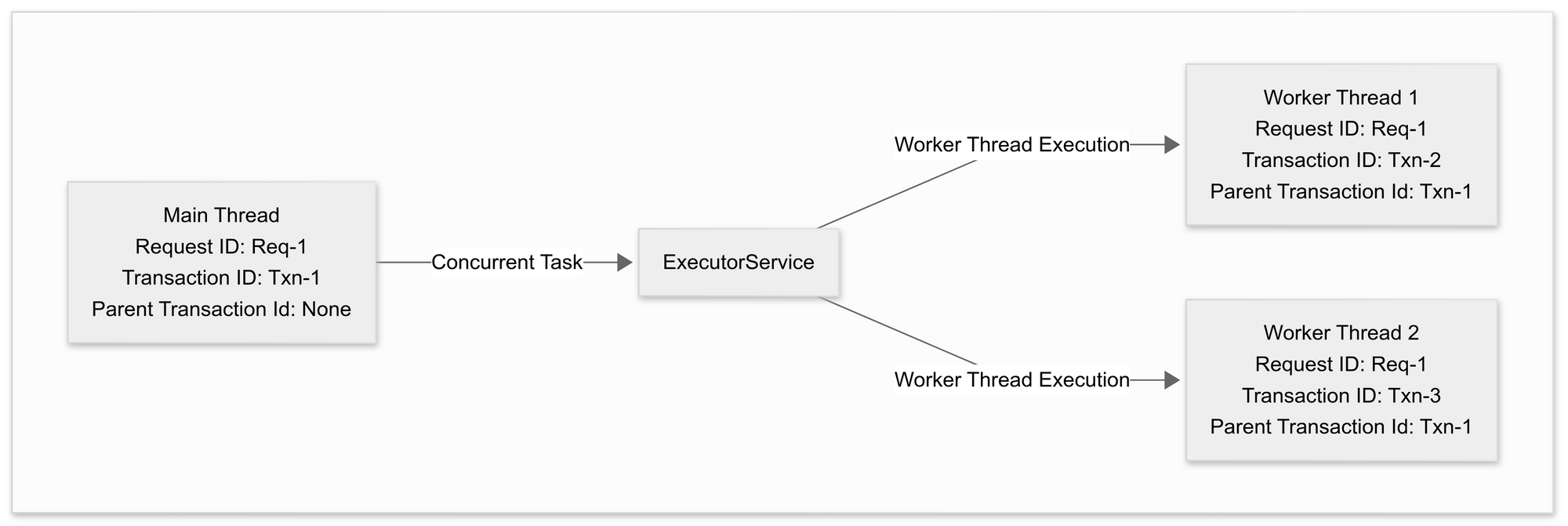
3. For Concurrent Operations
- The main thread’s Transaction ID is passed down to worker threads, ensuring concurrent tasks remain correlated with the original request.
- The Parent Transaction ID maintains the relationship between parent and child tasks, preserving end-to-end visibility even in concurrent executions.
By adopting this standardized logging approach, we eliminated traceability gaps and enabled faster debugging and monitoring across complex microservices, Kafka-based event-driven systems, and concurrent workflows.
Java Implementation: Code Patterns and Pseudocode
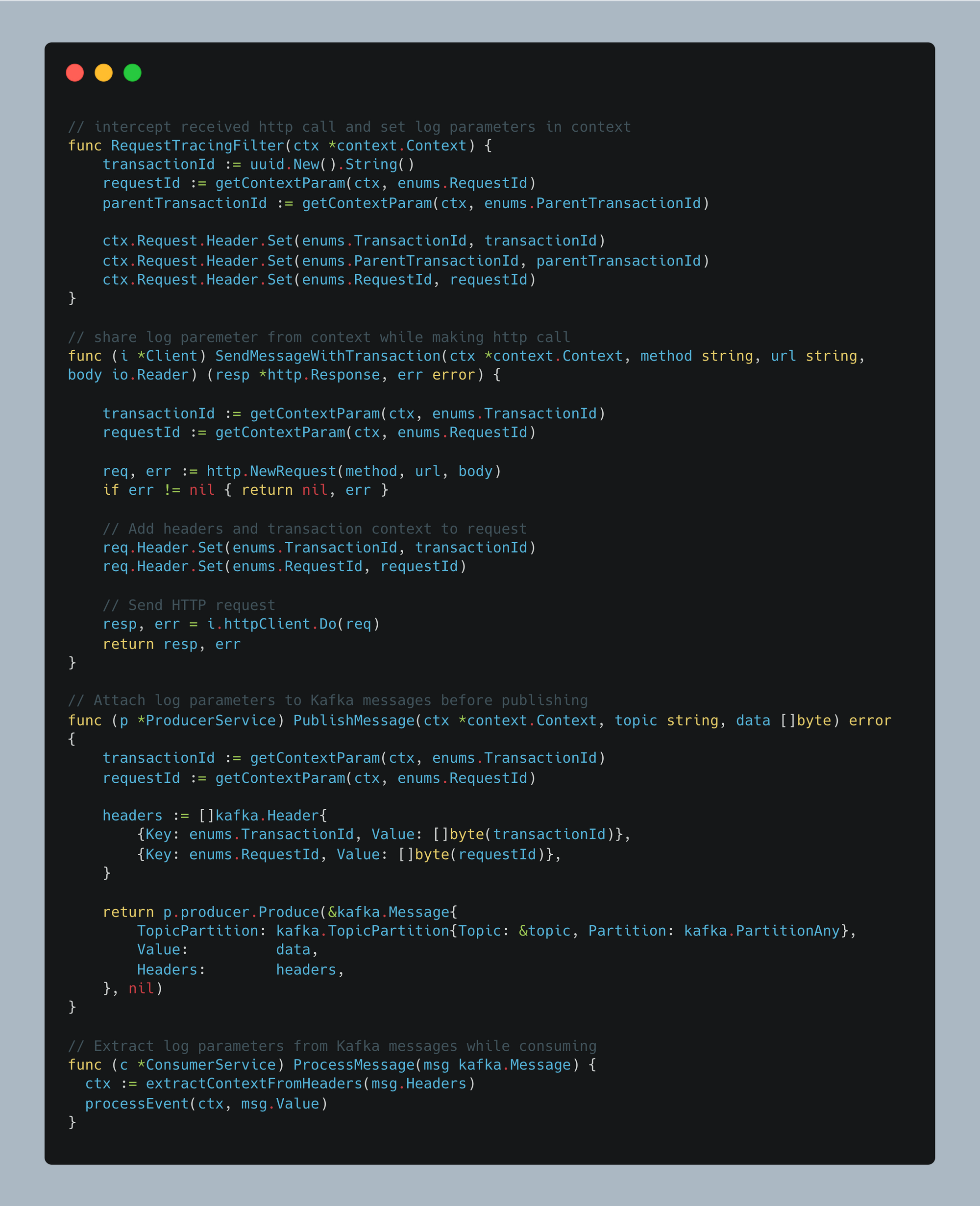
1. HTTP Request Handling
Standardizing logs for HTTP calls ensures that each API interaction is uniquely identifiable while maintaining cross-service traceability.

2. Kafka Event Handling
When producing a Kafka message, we attach the Request ID and Transaction ID as headers to ensure log continuity.
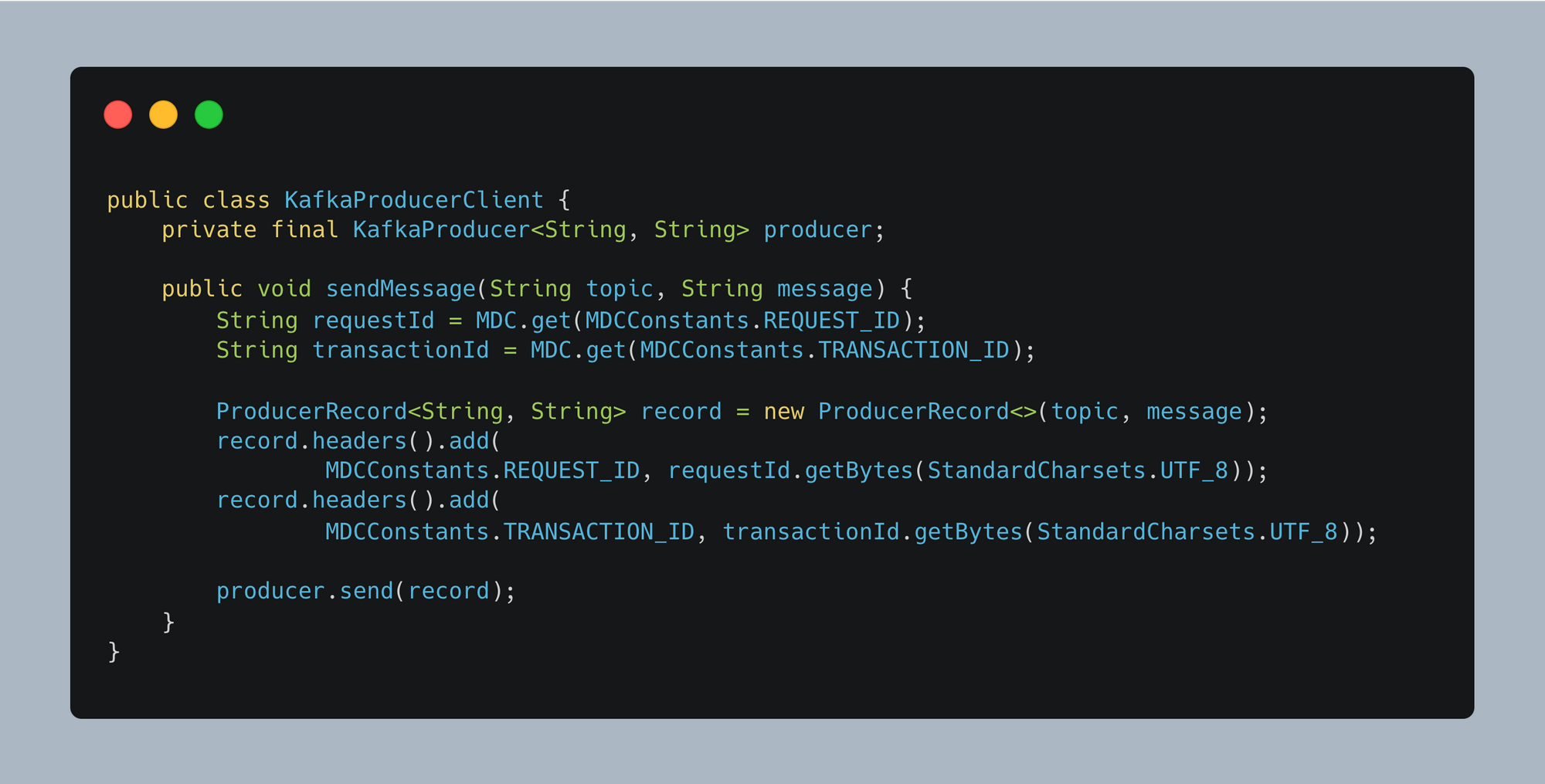
When consuming a Kafka event, we extract and set the tracing identifiers in MDC (Mapped Diagnostic Context).
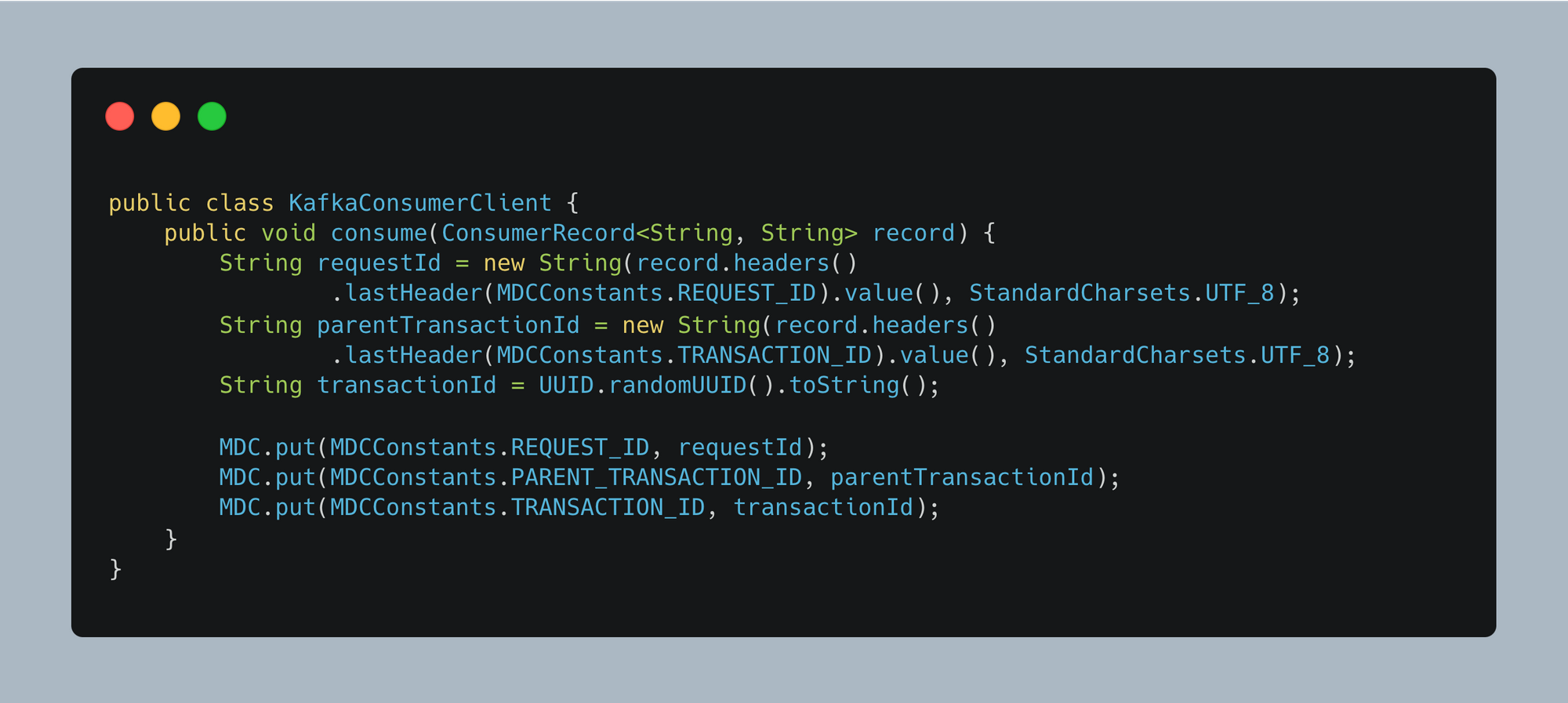
3. Concurrent Operations
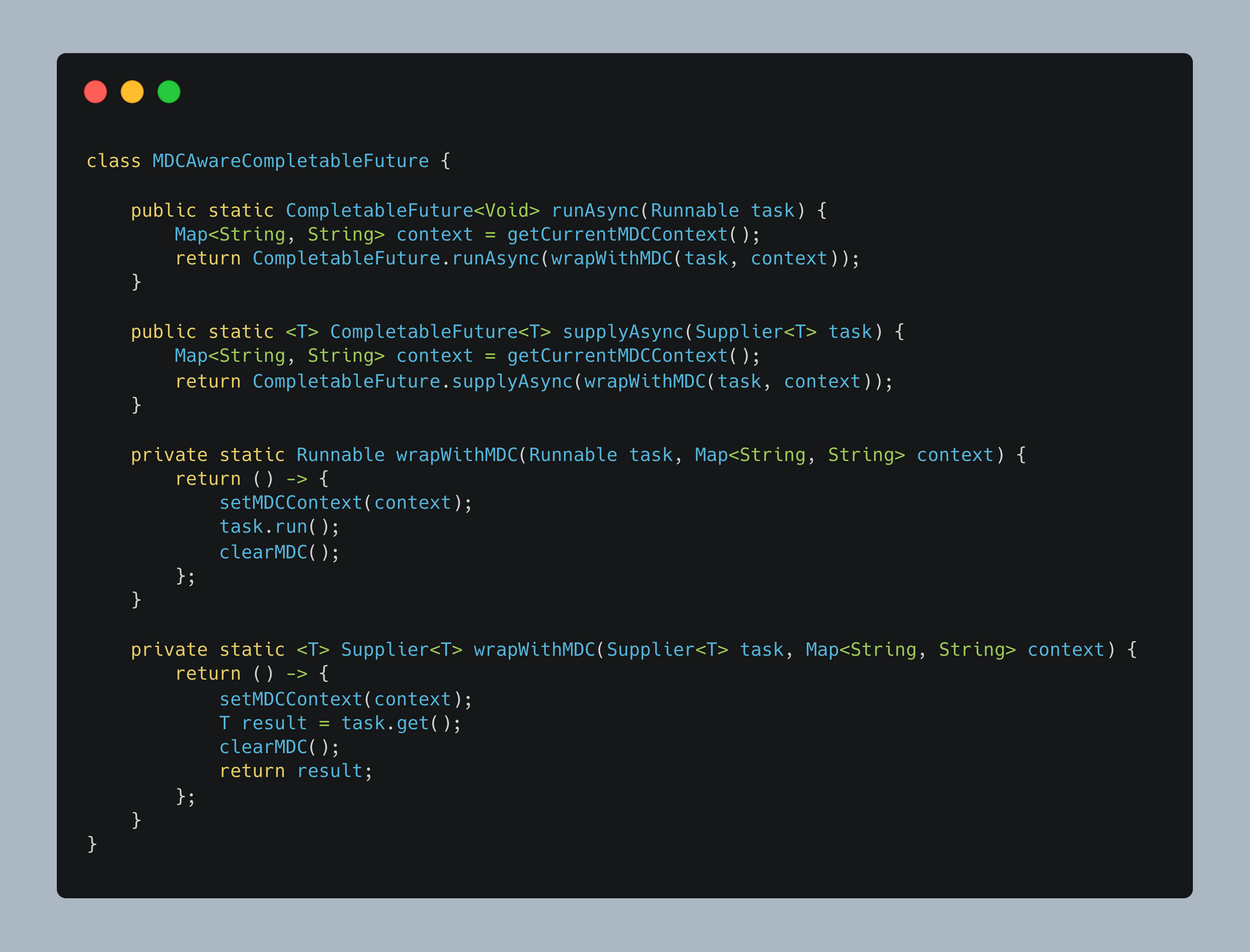
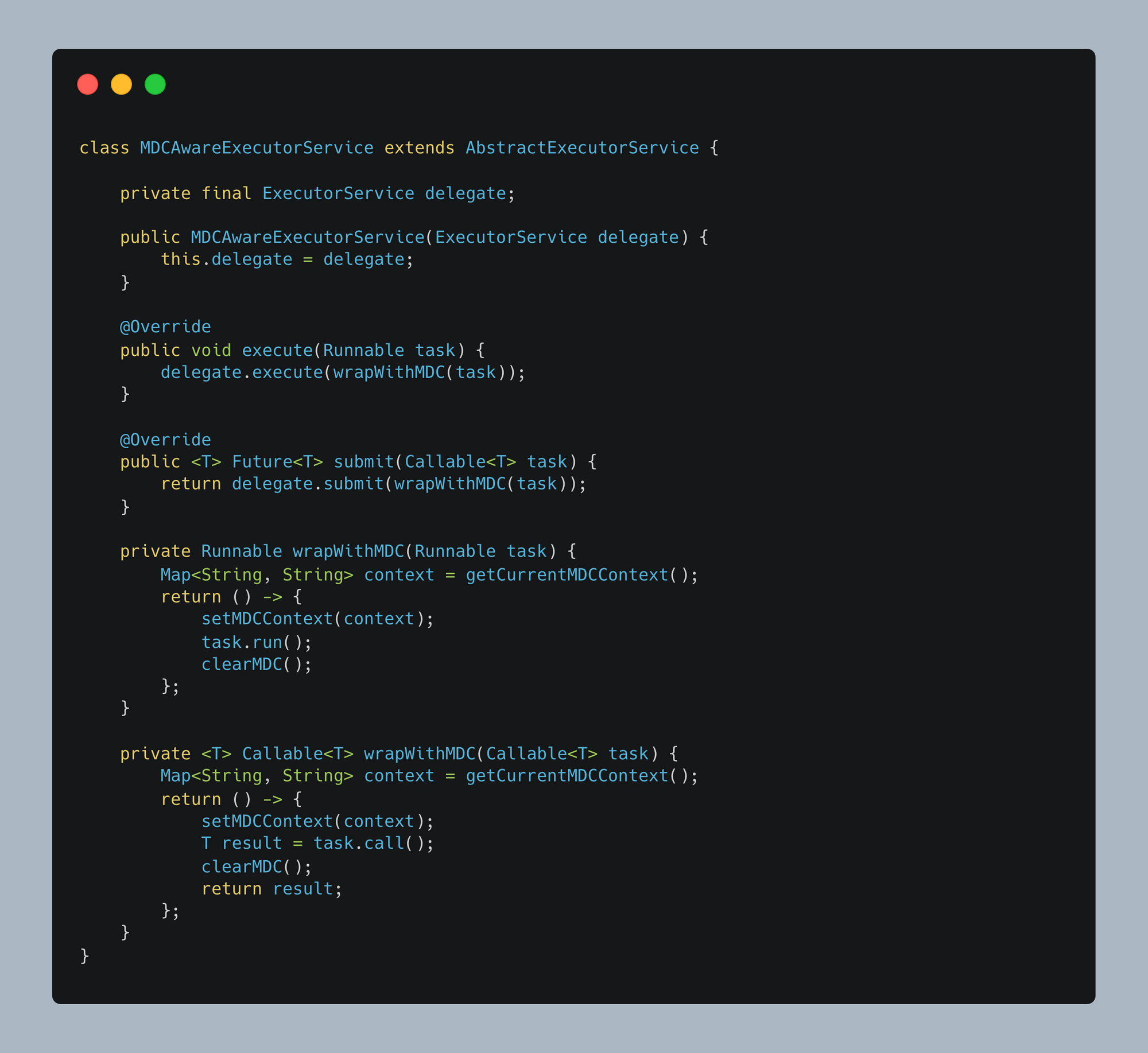
Problem: In Java, MDC (Mapped Diagnostic Context) stores contextual information in ThreadLocal storage. However, since concurrent tasks execute in different threads, they lose this context, making logs inconsistent.
Solution: We introduce MDCAwareCompletableFuture and MDCAwareExecutorService to manually propagate MDC context across concurrent executions.
MDCAwareCompletableFuture
MDCAwareExecutorService
By wrapping CompletableFuture and ExecutorService, we ensure that logs retain tracing context even in multi-threaded environments.
Golang & Python Implementation: Code Patterns and Pseudocode
Unlike Java, Golang and Python don’t have ThreadLocal storage. Instead, they use Context to explicitly pass request-specific data throughout the lifecycle.
How Context Helps :
- Prevents fragmented logs by ensuring trace propagation.
- Enables cross-service request correlation.
- Works across API calls, goroutines, and Kafka processing.
Context-Aware Logging and Tracing
To address these challenges, we implement a structured approach for context propagation in Go, focusing on key areas:
- HTTP Request Interceptor: Intercepts HTTP requests, extracts existing trace identifiers, or generates new ones, and injects them into the request context.
- Outgoing API Calls with Trace Context: Outgoing requests must carry the trace headers for consistent logging and better traceability across services.
- Kafka Producer - Context Propagation: When publishing Kafka messages, trace identifiers must be included in headers to ensure logs remain consistent and traceable across services.
- Kafka Consumer - Extracting and Setting Context: Consumers must extract trace identifiers from the Kafka message headers and initialize the logging context to maintain traceability across events.
Golang Implementation
Python Implementation
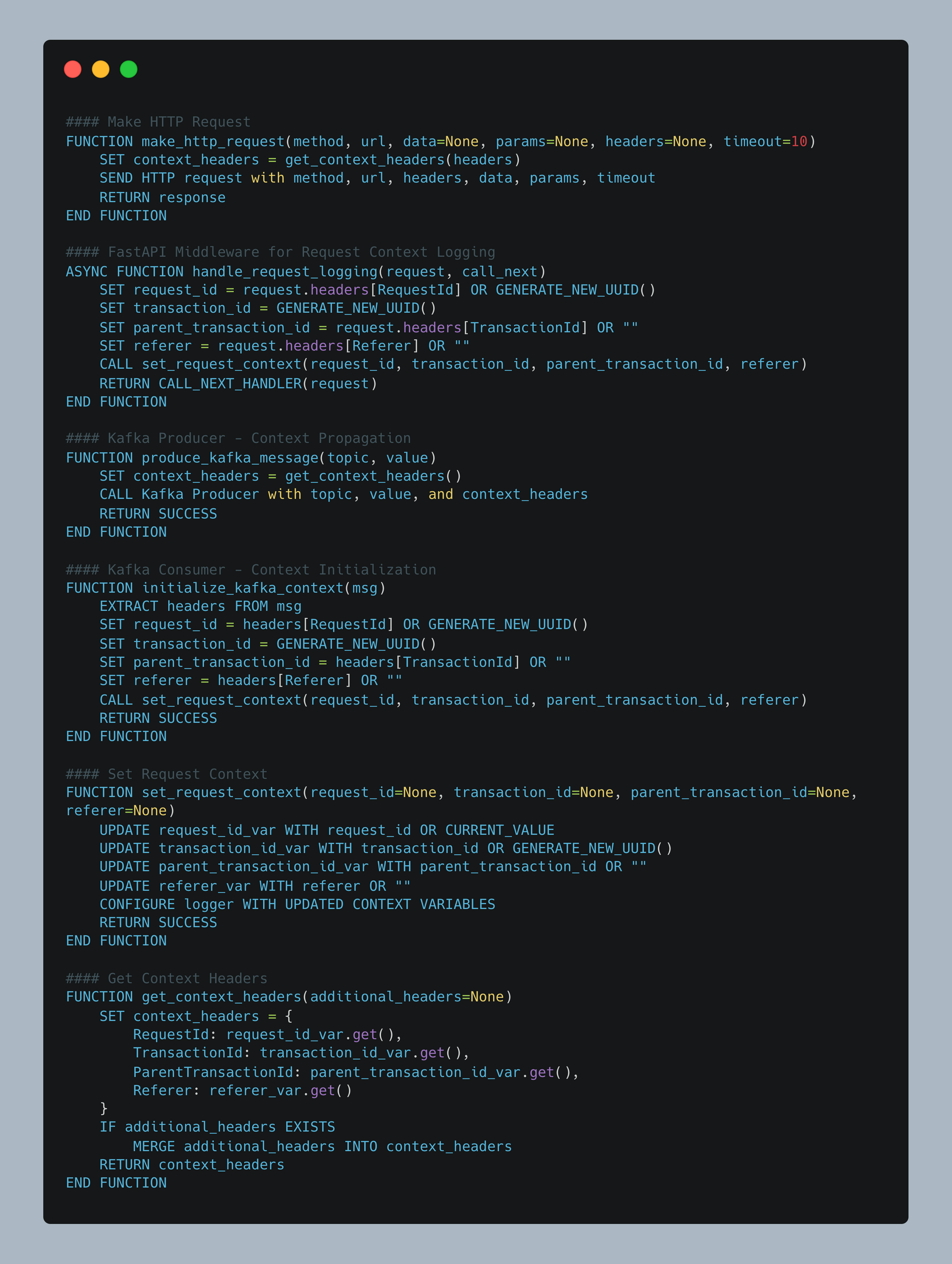
This context-aware approach ensures that every service in the system can maintain a consistent logging structure, regardless of the type of operation—whether it's an HTTP request, or Kafka event processing. It enhances traceability, simplifies debugging, and improves observability across microservices.
Log Tracing with Structured Logging
A well-structured log format ensures that key identifiers are consistently captured, making it easier to trace and debug issues across microservices and asynchronous operations. Below is an example of a standardized log format that helps capture key identifiers for better traceability:
[{Timestamp}] - [{Parent-Transaction-Id} - {Transaction-Id} - {Request-Id}] - [{Referer}] - [{Message}]
Using this structured logging approach, we can effectively trace logs across services, concurrent tasks, and Kafka events by following these steps:
1. Search for a specific log message and extract Key Identifiers.
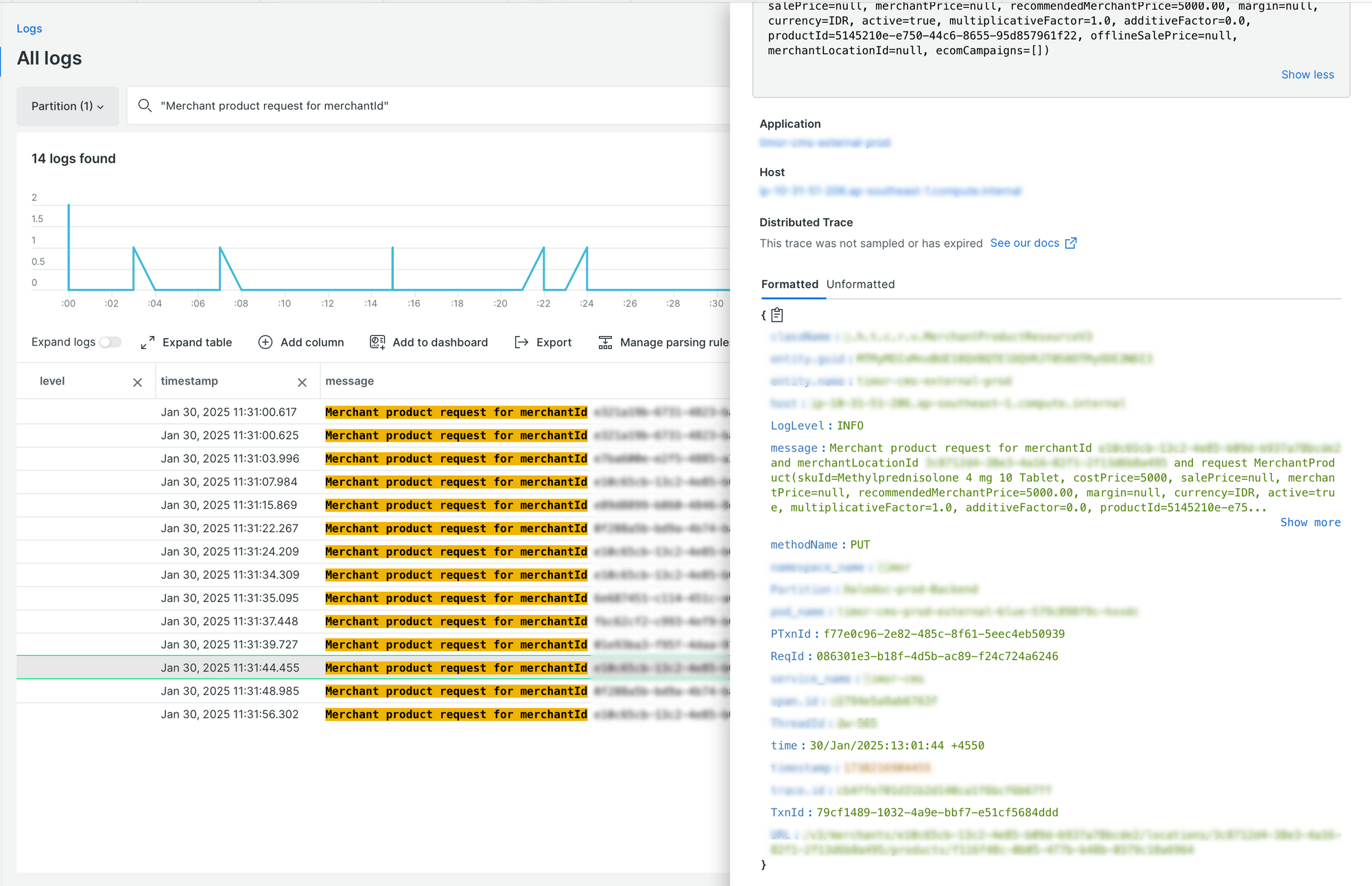
2. Find all logs related to a specific service using the Transaction ID
3. Trace logs of the upstream service by correlating entries using the downstream Parent Transaction ID as the Transaction ID
4. Correlate logs across multiple services using the Request ID.
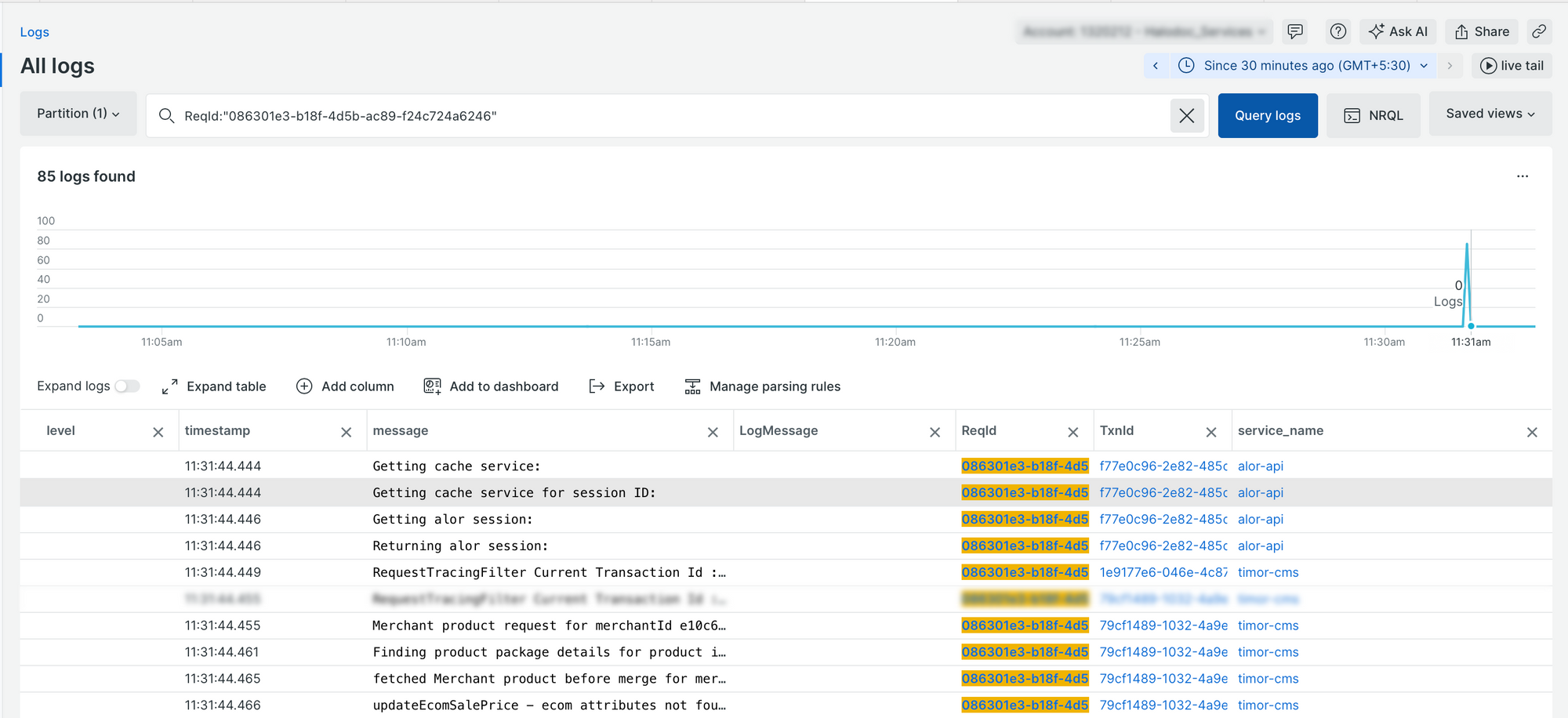
By leveraging these techniques, debugging becomes systematic and efficient, eliminating the need for manually piecing together fragmented logs.
Conclusion
By implementing Request ID, Transaction ID, and Parent Transaction ID, we have established a structured logging approach that ensures end-to-end traceability in distributed systems. This approach significantly enhances debugging efficiency and operational observability.
This structured approach provides several key benefits:
- Seamless request tracking with Request ID, allows us to trace a request across multiple services.
- Granular visibility into operations with the Transaction ID, ensuring that every service call, Kafka event, and concurrent operation is uniquely identifiable.
- Context propagation across service boundaries using Parent Transaction ID, maintaining clear relationships between dependent operations.
- Consistent log correlation in concurrent workflows with MDCAwareCompletableFuture & MDCAwareExecutorService, eliminating context loss in multi-threaded executions.
- Improved traceability in Golang applications by ensuring goroutine-level context propagation.
By standardizing our logging strategy at halodoc, we have established a more structured and efficient approach to tracing requests across distributed systems. This structured logging methodology enables faster issue resolution, reduced debugging effort, and enhanced system observability.
Join Us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels, and if solving complex problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our teleconsultation service, we partner with 1500+ pharmacies in 50 cities to bring medicine to your doorstep, we partner with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allows patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, Gojek and many more. We recently closed our Series B round and in total have raised USD$100 million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalized for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.