

Scaling Kafka by Parallel Processing
Apache Kafka has emerged as a cornerstone technology for building real-time data pipelines and streaming applications, offering high-throughput, fault-tolerant messaging at scale. One of the key challenges in Kafka-based architectures is optimising the processing of messages to ensure efficient resource utilisation and low latency.
To address this challenge, there are parallel consumer strategies, which enable concurrent processing of messages from multiple Kafka partitions. By parallelising message processing, we can enhance throughput, reduce latency, and improve overall system efficiency.
In this blog post, we will delve into the world of parallel consumer strategies for Kafka, exploring various approaches and techniques for achieving parallelism in message processing. We will discuss the benefits and trade-offs of each approach, along with best practices for implementation.
Introduction
At Halodoc, Kafka is not just used as a conventional message queue system; instead, it operates as a streaming platform built on a commit-log architecture.
Central to Kafka's design is the concept of partitions, which act as the basic unit of parallelism. Each partition can be consumed by only one consumer at a time, following a strict FIFO (first-in, first-out) order. When producing messages, a producer can either specify the partition number directly or rely on Kafka to determine it automatically using a hashing function (% number of partitions).
While partitions enable parallelism, Kafka's design imposes limitations on how messages can be processed in parallel. These constraints are important to consider when designing Kafka-based systems to ensure optimal performance and scalability.
The more partitions there are, the higher the processing parallelism. For example, if a topic has 30 partitions, then an application can run up to 30 instances of itself, such as 30 Docker containers, to process the topic's data collaboratively and in parallel. Each of the 30 instances will get exclusive access to one partition, and it will process the messages in that partition sequentially. Any instances beyond 30 will remain idle. The partition construct also guarantees message ordering, ensuring that each message is processed in the order in which it is written to the partition.
Need for parallel processing
We run Kafka consumers within our service pods, with each consumer running a single thread to process messages. Within a consumer group, one Kafka consumer can read from multiple partitions, but messages in one partition can only be processed by one consumer at a time.
- If the number of partitions is greater than the number of consumer pods, some consumers will process multiple partitions in a single thread.
- If the number of partitions is less than the number of consumer pods, some consumers will be idle, leading to underutilisation of resources. However, Kafka does not allow idle resources to be utilised to concurrently process messages in this scenario.
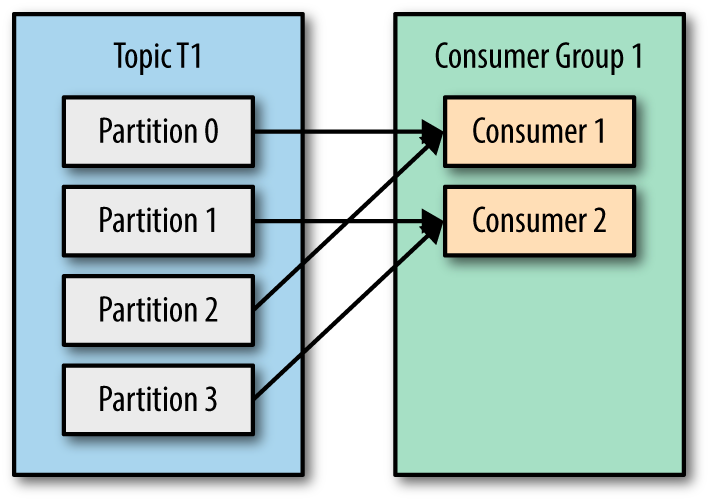
Since consumers are mostly waiting on I/O, parallelism in request processing is crucial for efficiency.
Maximum number of parallel processing threads will be limited by the lesser of the number of partitions or the number of consumer pods.
maximum concurrency <= min(noOfPartitions, noOfConsumerPods)We cannot concurrently process more than noOfPartitions or noOfConsumerPods. Note that both noOfPartitions & noOfConsumerPods add to $$ cost. On top of that, every additional pod resources will be wasteful since it just runs a single thread waiting on I/O. It’s not possible to dynamically increase noOfPartitions. Even worse, once increased Kafka doesn’t permit it to decrease.To decrease partitions, we have to recreate the topics. You never know you over-provisioned or under-provisioned.
Our main goal is to achieve parallelism without increasing noOfPartitions or noOfPods.
- If we need in-order consumption - ideally we should be able to boost our
concurrencyof processing messages upto number of partitions. - If we don’t need in-order consumption - we should be able to boost our
concurrencyof processing messages even higher - as high our resources(cpu/ram/db/rate-limiter) permit.
While Kafka has proven its prowess in diverse use cases, its streaming platform nature and reliance on partitions present unique challenges for achieving optimal parallel processing of messages.
Solutions for parallel processing
- Multiple consumers per pod
- Multi-threaded consumers
- Confluent parallel consumers
Multiple Consumers per Pod
Implementing multiple consumers per pod can indeed increase the concurrency of processing messages from multiple partitions. Each consumer can handle messages from a different partition, allowing for more efficient processing within a single pod.
- This is the simplest option. Basically we just create multiple consumer instances per pod to consume messages and increase concurrency of message processing from different partitions.
Result summary of load test
Below is the use cases we have simulate to check the efficiency of parallel processing approaches
One of our product services receives 80k events in a day to index new pharmacy products. By introducing multiple consumers per pod, we were able to reduce the time to process these events from 20 hours to 6 hours.

Having 5 consumers per pod and 4 pods processing results in a maximum concurrency of 20, which should help efficiently process the product updated events. It took around 6 hours to process all the events.
Reducing overall processing time demonstrates the effectiveness of this approach.
We have achieved parallel processing of messages from multiple partitions, but increasing further concurrency requires registering new consumers. Unfortunately, this increases Kafka cluster network overhead and imposes strain on the Kafka Consumer group lead, especially in case of a rebalance.
Multi-threaded Consumers
To reduce total time in processing events further and reduce number of pods required in multiple consumers per pod approach, we have implemented another approach of multiple threaded consumers.
Implementing multiple threaded consumers per pod is a smart approach to increase the concurrency of processing messages from multiple partitions. This allows for more efficient processing within a single pod, reducing the overall time of parallel processing and optimising further.
- To create a pool of fixed number of threads, not more than the number of partitions, where each thread starts processing messages from its respective partition, and the main thread goes back to polling, we can use Java's
ExecutorServicealong with Kafka's consumer API. Here's a simplified example:
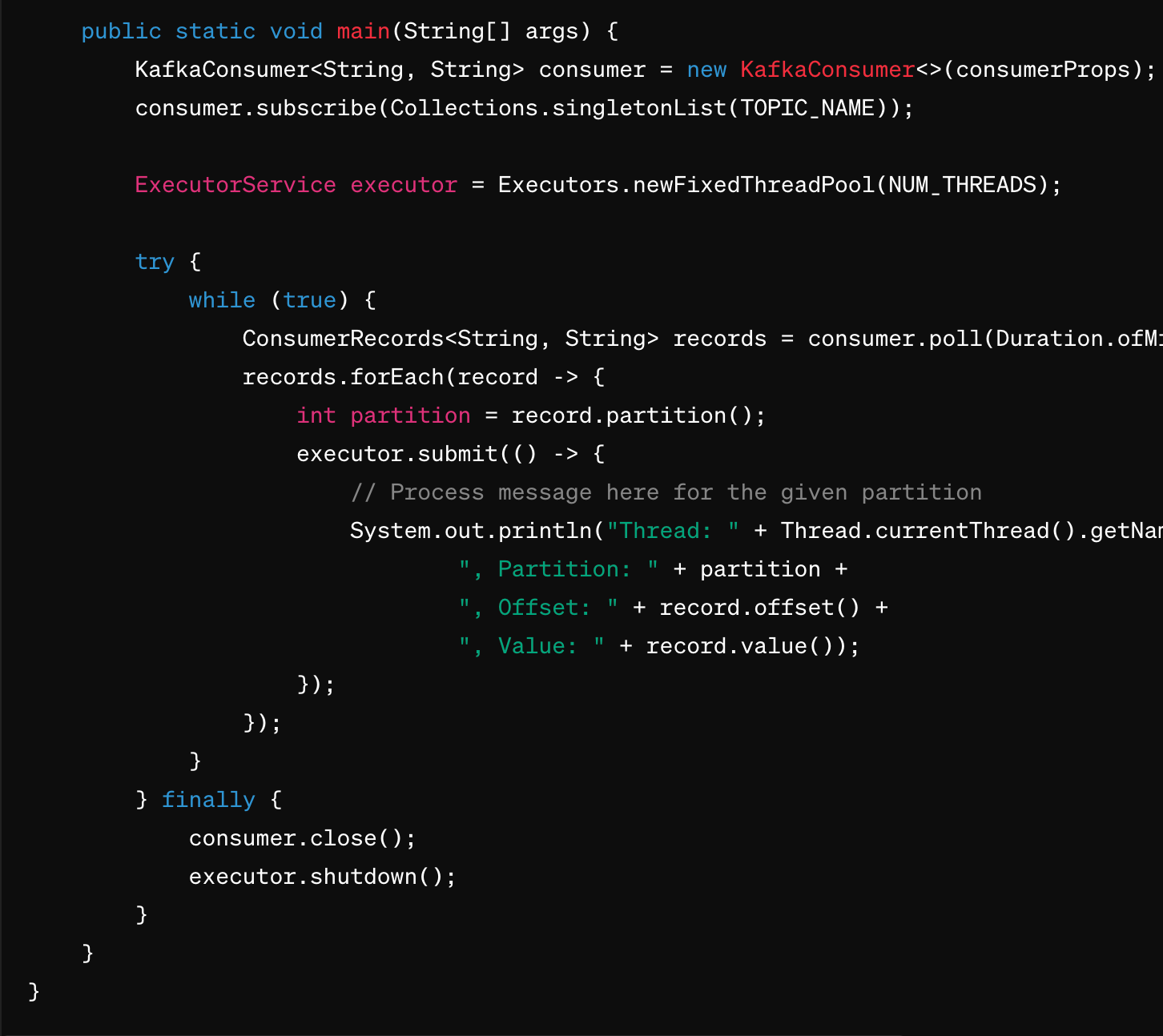
In this example, the ExecutorService is created with a fixed number of threads (NUM_THREADS). Each thread is responsible for processing messages from its respective partition, allowing for concurrent processing of messages from multiple partitions. The main thread continues to poll for new records while the processing is done in parallel by the worker threads.
Result summary of load test
Having 2 pods, each with 1 consumer and a thread pool executor of 10 threads, results in a maximum concurrency of 20. This setup helped us efficiently process the product updated events.
Reducing the total pod count from 4 to 2 while also decreasing processing time by around less than half demonstrates the effectiveness of this new approach.
Here are the advantages we have observed from using multi-threaded consumers:
- Improved Concurrency: Multi-threaded consumers allow for parallel processing of messages from multiple partitions, increasing overall throughput and reducing processing times.
- Resource Efficiency: By utilising multiple threads within a single consumer, we can achieve higher levels of parallelism without the need for additional resources such as pods or partitions.
- Reduced Latency: Parallel processing can help reduce message processing latency, ensuring that messages are processed more quickly and efficiently.
- Scalability: Multi-threaded consumers can easily scale to handle increased message loads by adding more threads within existing consumers, providing a cost-effective scaling solution.
- Simplified Management: Managing fewer consumers with multiple threads each can be simpler than managing a larger number of individual consumers, reducing management overhead.
Overall, the use of multi-threaded consumers has proven to be a valuable strategy for improving the efficiency and scalability of our Kafka-based event processing systems.
While multi-threaded consumers offer various benefits, they also come with limitations:
- Complexity: Implementing and managing multi-threaded consumers can be more complex than single-threaded or parallel consumer approaches. It requires careful management of thread synchronization, error handling, and resource allocation.
- Resource Overhead: Each additional thread consumes system resources, such as CPU and memory. Managing a large number of threads can lead to resource contention and inefficiencies.
- Concurrency Control: Ensuring proper concurrency control, such as avoiding race conditions and deadlocks, can be challenging in a multi-threaded environment.
- Scalability: While multi-threaded consumers can improve performance, scaling them to handle increasing loads may require additional infrastructure and careful tuning.
- Here our concurrency is limited by
noOfPartitions. So we save pod cost, but we are still left with cost of partitions & their management for which we have explored another approach parallel consumer library of confluent.
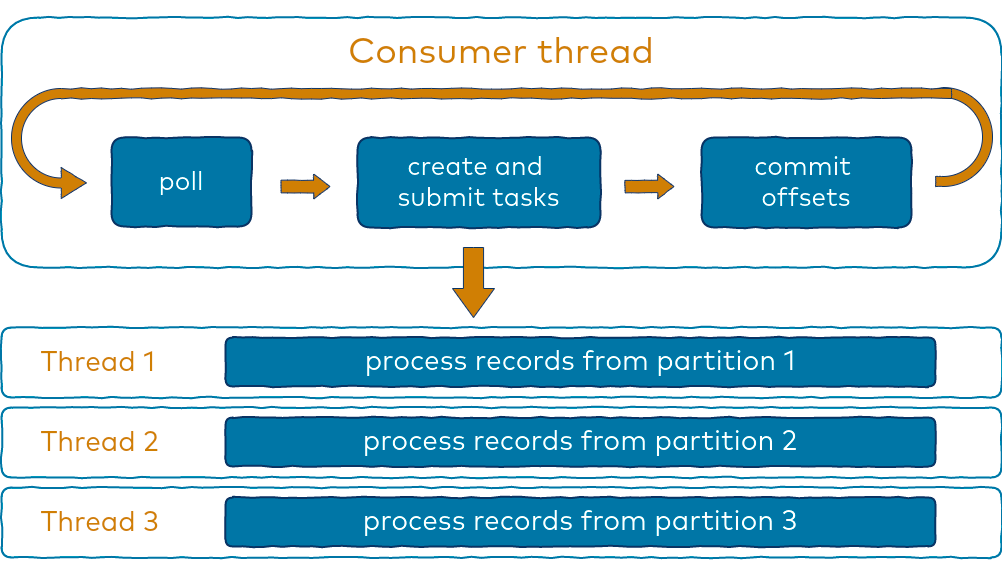
multi-threaded consumers
Confluent parallel consumer
This is another approach we have explored and implemented to maximize the parallel processing of messages from multiple partitions.
Implementing Confluent's parallel consumer library, offering configurable concurrency hard-limits and three processing options: PARTITION, UNORDERED, and KEY.
The Confluent Parallel Consumer allows you to parallelise processing at three different levels:
- PARTITION - Same as above multi-threaded Consumer -
maxConcurrency = noOfPartitionsThis provides the same semantics as a regular consumer group, as data in a single partition will always be processed in order. The difference is that the Parallel Consumer can provide these guarantees using fewer resources than an equivalent consumer group (a thread in the Parallel Consumer typically uses less resources than a single Kafka consumer in a consumer group) - UNORDERED - This is the fastest option possible with no limit on
maxConcurrency. Kafka becomes per-message-ack queuing system with no FIFO guarantee. Different threads will process messages from a single partition in an arbitrary order.
UNORDERED level guarantee
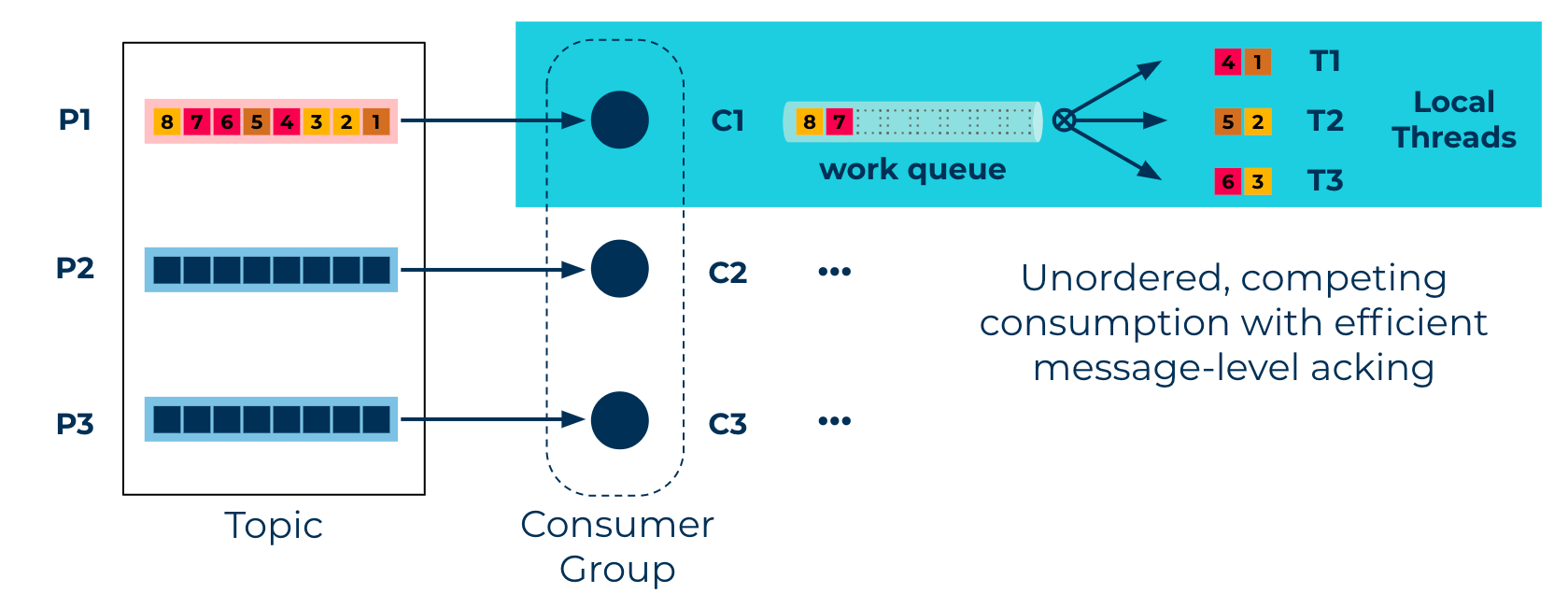
partition-level parallelism using the Confluent Parallel Consumer
- KEY - A novel option. Instead of partition,
messageKeybecomes the basic unit of concurrency. We can go beyond noOfPartitions while still maintaining FIFO order. SomaxConcurrency = noOfKeysat a given poll call. Different threads will process messages from a single partition in parallel while maintaining Kafka’s key-based ordering guarantees.
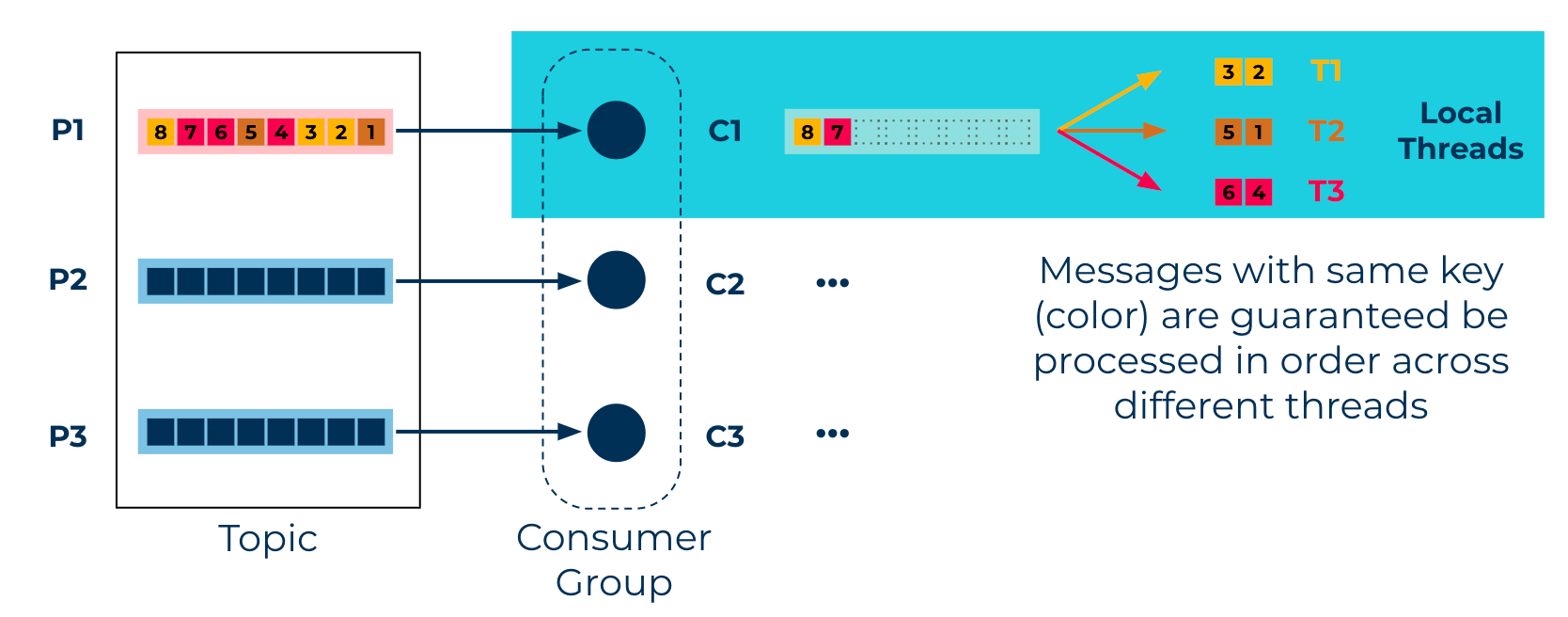
key-level parallelism using the Confluent Parallel Consumer
Implementing this type of processing is simple. Here is an example:
var options = ParallelConsumerOptions.builder()
.consumer(kafkaConsumer)
.ordering(KEY)
.maxConcurrency(1000)
.build();
parallelConsumer = createEosStreamProcessor(options);
parallelConsumer.poll(record -> {
log.info("Concurrently processing a record: {}", record);
});Result summary of load test
Having 2 pods, each with 1 consumer, and a maximum concurrency of 20 with processing order set to UNORDERED means that 20 parallel threads consume messages from the same partition with a random processing order to reduce the total time in processing all the events with less complex system configurations.
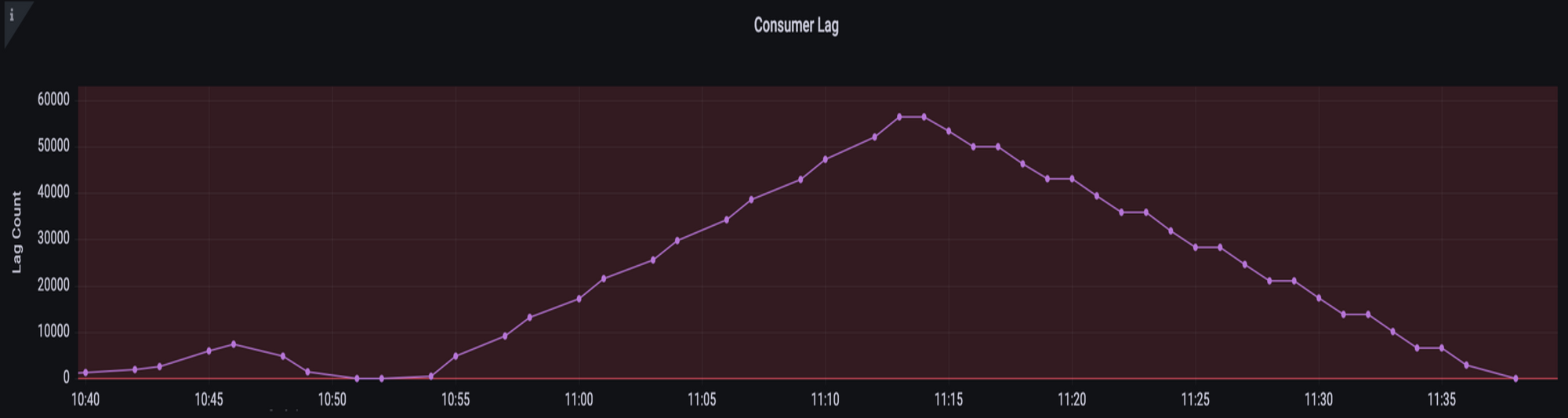
It is observed that with new approach with 20 parallel threads consuming messages from the same partition with a random processing order is more efficient in achieving parallel processing than the previous multi-threaded consumers approach. Also, overall processing time reduced from 3 hours to 1 hour. Additionally, by increasing the maximum concurrency to 50, we have reduced the partition count from 16 to 4.
Total pods & partitions reduction saved around ~$44 / month.
The Confluent Parallel Consumer library offers several advantages over traditional multi-threaded consumer approaches:
- Simplicity: The library abstracts away much of the complexity involved in managing multiple threads for parallel message processing, making it easier to implement and maintain.
- Efficiency: It is designed to optimise resource utilisation, ensuring that parallel processing is done efficiently without unnecessary overhead.
- Scalability: The library provides built-in mechanisms for scaling consumer instances based on workload, allowing for seamless scalability as the message load increases.
- Fault Tolerance: It includes features for handling failures gracefully, such as automatic partition rebalancing and offset management, ensuring that message processing is not interrupted.
- Integration: The library integrates seamlessly with other Confluent Platform components, such as Schema Registry and Kafka Connect, providing a unified platform for building streaming applications.
Overall, the Confluent Parallel Consumer library offers a more robust and efficient solution for achieving parallelism in message processing compared to traditional multi-threaded consumer approaches.
Limitations of using confluent parallel consumer library -
- Kafka lag based HPA solution is difficult to achieve due to incorrect kafka lag count. Since we are processing in parallel, a consumer might read many messages from partition but some of them are being processed & some are just waiting. The actual lag might be incorrect, but it can still be used to get general idea. While the Kafka lag count may not be entirely accurate due to parallel processing, it can still provide a general idea of the lag and be used as a rough metric for autoscaling. Fine-tuning the autoscaling based on your specific use case and workload patterns can help mitigate some of the inaccuracies.
- Kafka parallel library will help when the consumer pods are idle - waiting for i/o etc. So we can process more messages in parallel on same pod instead of adding a new one. If pod is already busy, it won't help.
Conclusion
In conclusion, implementing parallel consumer strategies for Kafka demonstrates a commitment to optimising message processing efficiency. Each solution has its trade-offs, but Confluent's Parallel Consumer library stands out for its flexibility and advanced features, making it a strong choice for efficiently processing messages from Kafka.
We have successfully integrated confluent parallel consumer library in all our services and it seems to have been a successful solution for achieving parallelism in message processing without the need to increase partitions or pods.
References
- https://github.com/confluentinc/parallel-consumer
- https://developer.confluent.io/tutorials/confluent-parallel-consumer/confluent.html
- https://www.confluent.io/blog/introducing-confluent-parallel-message-processing-client/
- https://www.confluent.io/blog/introducing-confluent-parallel-message-processing-client/#:~:text=In Kafka%2C the topic partition,data collaboratively and in parallel.
Join us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. We recently closed our Series D round and In total have raised around USD$100+ million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


