

Optimizing ETL data scan in Redshift
In Halodoc, we extract and transform millions of data points on our platform every day. Data transformation is a critical step in the data management process that involves converting raw data into a format that is ready for analysis or further processing. We are using Apache Airflow to run scheduled transformation SQL (ETL) and Redshift as our Data Warehouse.
As the data grows, it will affect scanning time when ETL performs a query and also consume more CPU resources & Disk space from the instance that makes the instance pushing to the limit.
What is Data Scan:
When we execute a query in Redshift, the query planner will determine how to retrieve the data needed by the query. If the query requires data from one or more tables, Redshift will need to perform a scan of the table(s) to locate the required data.
In summary, a data scan in Redshift refers to the process of reading and processing data from one or more tables in the Redshift cluster to satisfy a query.
Our current Presentation Layer
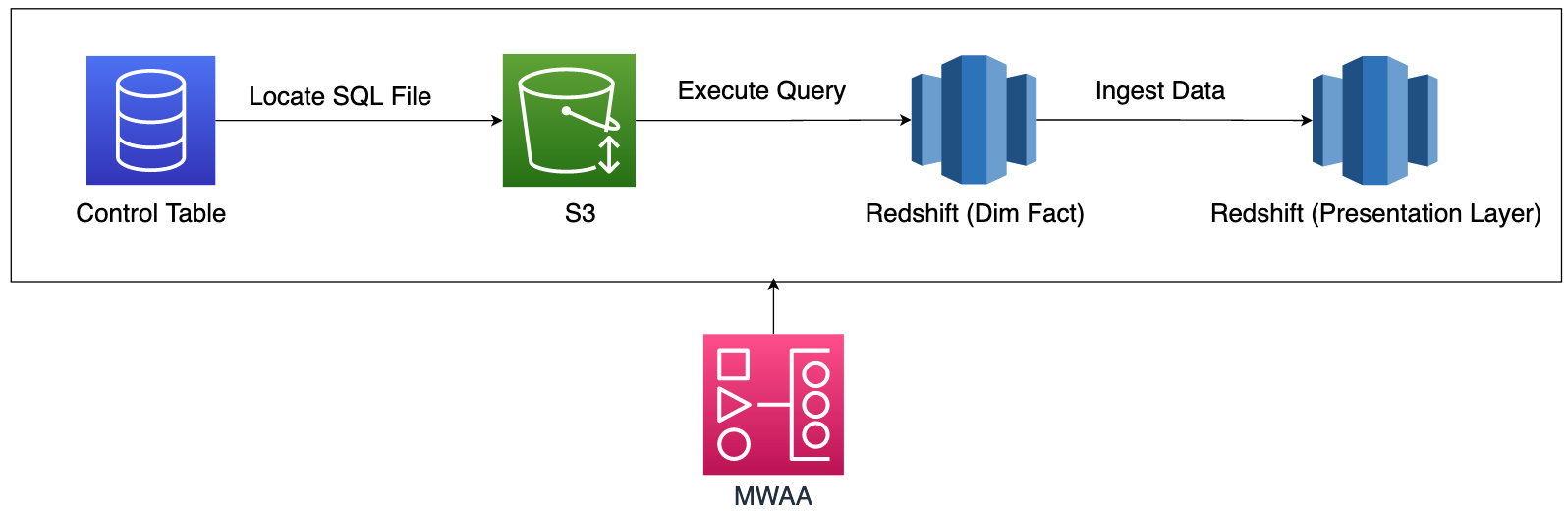
From the above picture, we execute the sql file and read the data from Redshift Dimensional / Fact schema before ingested into the Presentation layer. One single SQL file could have multiple join conditions for transforming the results. Here is the sample from part of our ETL query before optimization.
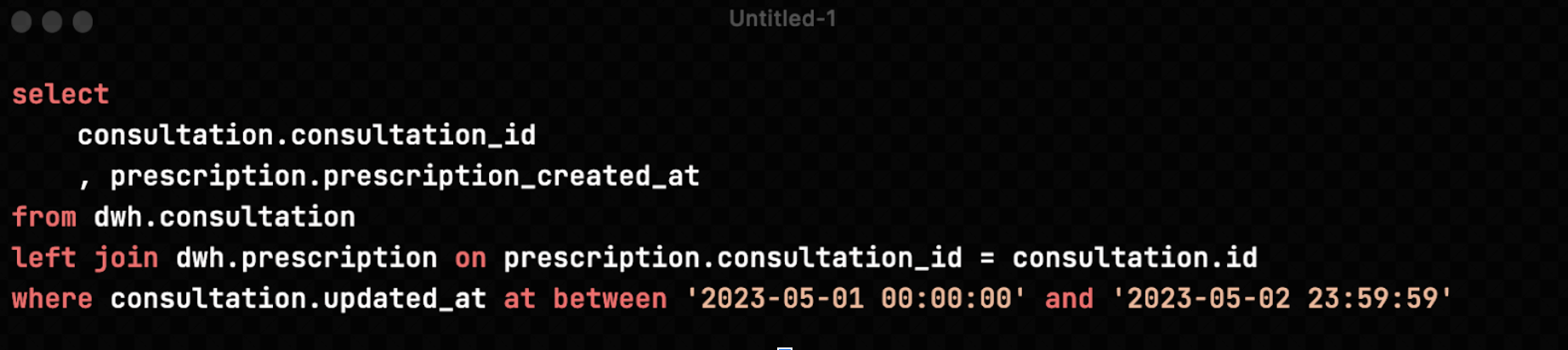
From the given query above, we want to fetch the consultation id and prescription time. This information will be useful for the analytics team to analyze how many consultations have a prescription or not. We use the left join clause to combine the two pieces of data, since not all consultations ended with doctor prescription.
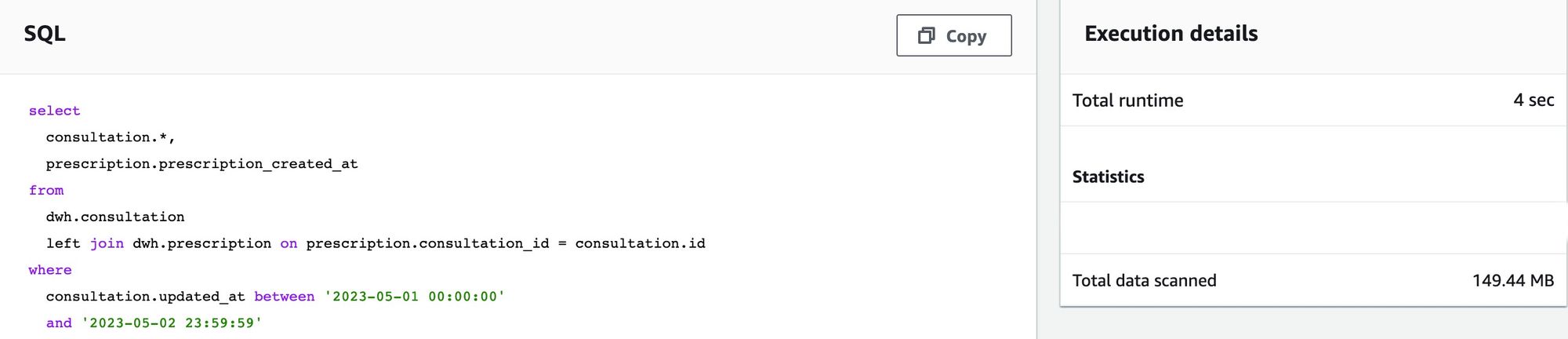
Before we optimized the query, this simple query took 4 sec runtime and 149,44 MB of total data scan. From AWS documentation, there are several way to help optimizing the query, such as :
- Implementing Distribution Key : The distribution key, also known as the distribution column, is a column or set of columns that determines how data is distributed across the compute nodes in a Redshift cluster.
- Implementing Sort Key : The sort key is a column or a combination of columns used to determine the order of data storage within each block on disk.
We have implemented distribution key and sort key in our data warehouse. Implementation of the distribution key should help us to reduce the data scan when joining two tables provided if the joining is applied on the distribution key of the two tables and sort key should help us when we are filtering the data.
Observing the current data warehouse table, we always include the updated_at column of the main driving table. The updated_at column tells us when the last time the data changes, which means updated at guarantees the data freshness of the data warehouse tables. Realizing this we pick the updated_at column as the sort key and we put a filter on the updated_at column in every CTE / Join clause because sort key help to reduce the data scan by eliminating the need to scan all blocks to get the data we require and Redshift will only scan the relevant blocks that is expressed in the given sort key filter. We called this buffer time.
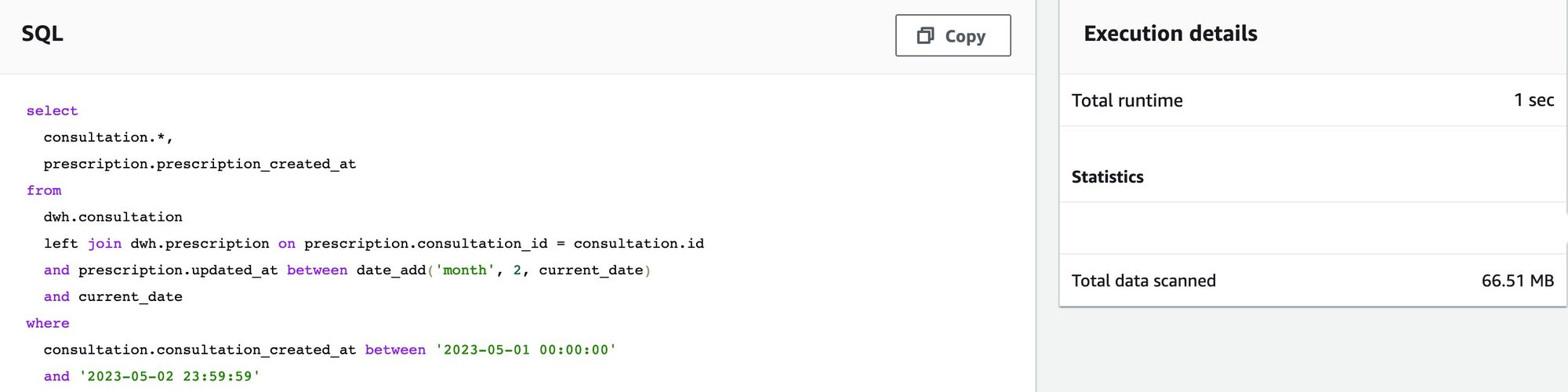
After we put buffer time, the total number of rows scanned decreased from 149,44 MB to 66,51 MB. In this case we put a buffer for the data which had an update in 2 months back from the current date so Redshift only scans the data from the particular date range and also allows us to fetch the latest data and the data that are not updated will not get extracted.
We are able to parameterize the buffer time by utilizing the start_time variable from Airflow. By having this, whenever the job runs the variable will replace the value into execution time.
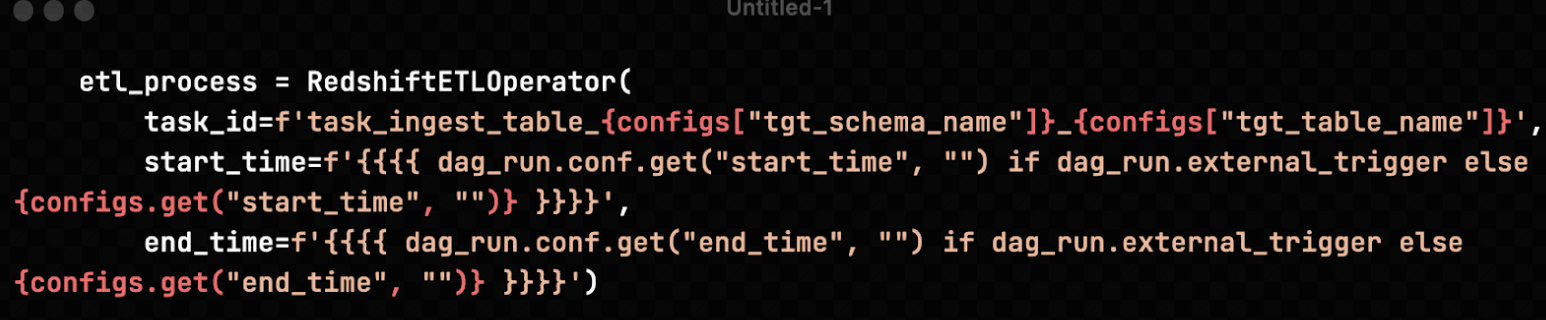
The custom operator that we develop will take the corresponding sql script from S3 bucket (also specified in the metadata table) and dynamically adjust the buffer time according to the parameters that we pass to the custom operator. We also need to adjust the sql file to receive the parameter from the Airflow operator.

Summary
Buffer time will be useful when we have many Join clauses in our query. That will remove unused data from the scanning phase and make the query more faster when fetching the results. Buffer time will be more optimized if the column is applied with sort key. Do analysis before applying buffer time in every CTE or Join clause because in some cases, some old data also gets updated due to business requirements. Understanding the business process is critical when determining the buffer time.
Join us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek and many more. We recently closed our Series C round and In total have raised around USD$180 million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


