

Platformisation of LLM Calls and its Benefits
Introduction
The use of Large Language Models (LLMs) is rapidly increasing across industries, aiding automation, content generation, and intelligent decision-making. Initially, different teams integrated LLM models into their services independently, leading to inconsistencies and inefficiencies. To address these issues, we developed a centralised LLM service that standardises integration, enhances scalability, and simplifies maintenance.
Challenges With The Earlier Approach
Before the introduction of the centralised platform, LLM calls were managed by different services, each implementing its own integration. This approach led to several challenges:
- Inconsistencies in implementations: Different services used various SDKs, APIs, and configurations, leading to inconsistent response formats and integration behaviours.
- Complex key management: API keys and whitelisting connection integrations for LLM providers were distributed across multiple services, increasing security risks and making key rotation cumbersome.
- Difficulties in model switching: Upgrading or switching between LLM models and their versions required significant effort and custom changes in each service.
- Security and privacy concerns: Without a centralised gateway, it was difficult to track what data was being shared externally, posing potential security risks.
- Performance bottlenecks: Features like parallel processing, rate limiting, retry mechanisms, and timeout handling were inconsistent or absent, leading to inefficiencies.
- Scalability concerns: As the number of LLM usage instances increased, maintaining separate integrations became difficult, leading to performance constraints and operational overhead.
- Lack of centralized logging: Debugging and monitoring were challenging due to the absence of a single source of truth for request-response tracking.
- Redundant efforts: Multiple teams replicated similar functionalities, increasing development and maintenance overhead. Additionally, writing and maintaining individual test cases across services resulted in wasted effort as those could not be reused.
- Cost management challenges: Tracking LLM usage costs across different teams and projects was difficult, leading to inefficiencies in budgeting and resource allocation.
The New Centralised Platform
To mitigate these challenges, we introduced a centralised LLM service, a Python-based platform that unifies and standardises LLM interactions across the organisation.
Key Features Of The Centralised Platform
- Standardised LLM SDK integration: The platform interfaces with various LLM providers using their SDKs, ensuring consistency.
- Database-driven configuration: API keys, model settings, and other configurations are centrally stored, reducing security risks.
- Request and response logging: All LLM requests and responses are stored in the database for tracking and analysis.
- Template-based requests: Instead of constructing requests separately, parameterised templates are stored in the database and used dynamically.
- Support for synchronous and asynchronous calls: Responses can be delivered immediately or processed later via callbacks, depending on the use case.
Implementation Details
High Level Sequence Diagram:
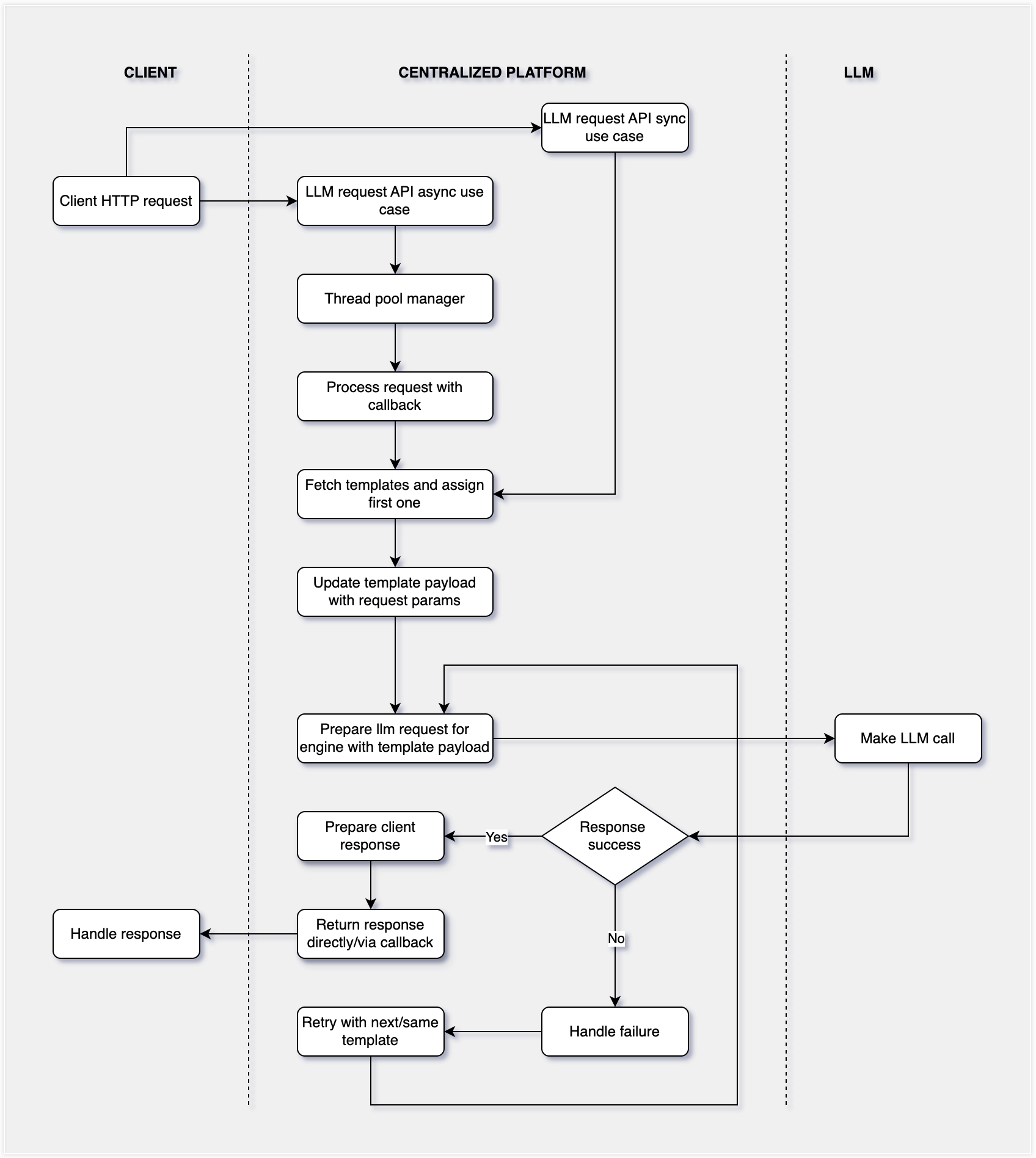
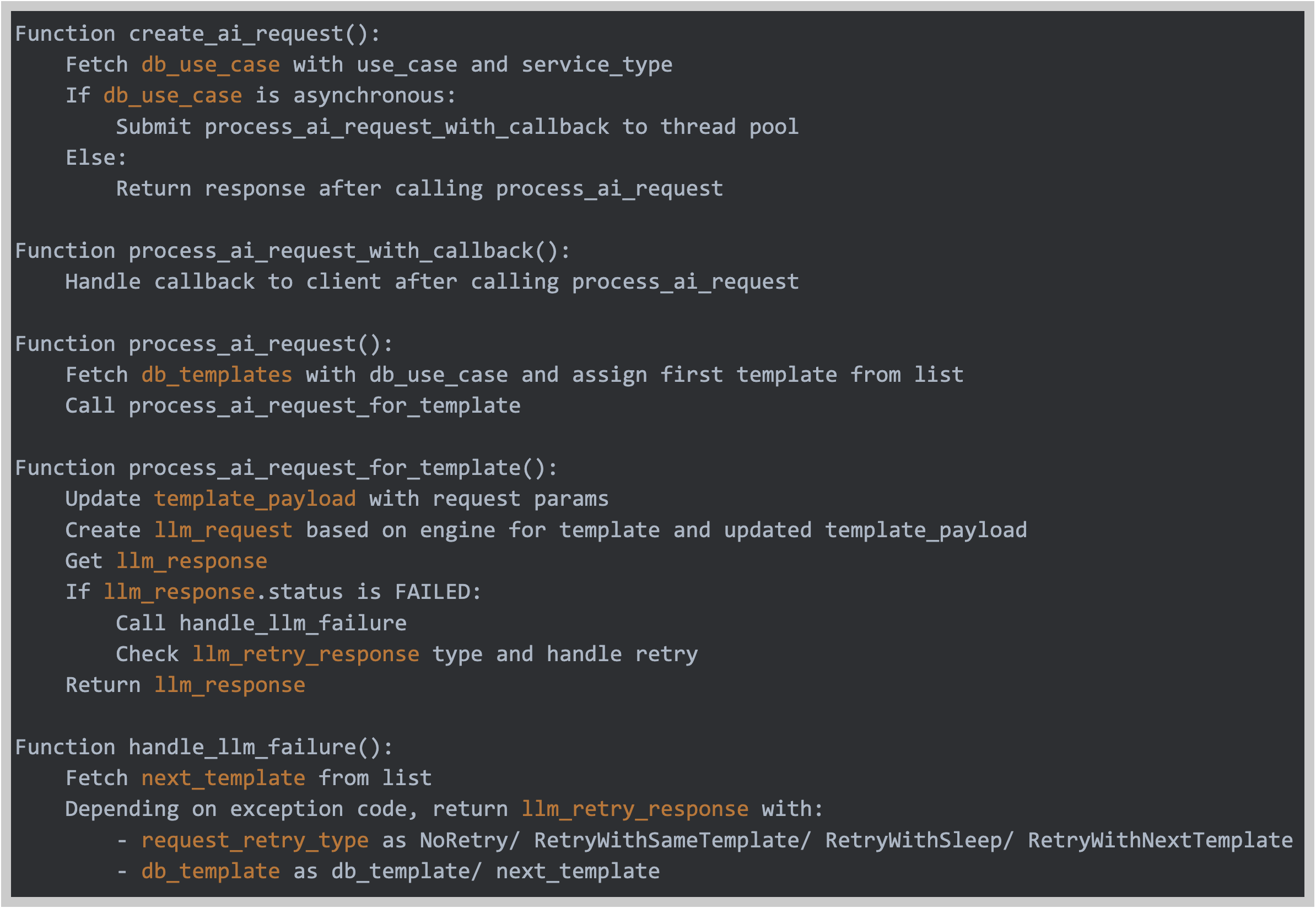
Request Processing:
Clients send requests to the centralised platform containing:
service_type: Defines the different business verticals.use_case: Specifies the function of the request.params: Key-value pairs for populating the request template.
The platform processes the request based on multiple criteria:
- It fetches
use_casedatabase record to be considered for request depending on combination ofservice_typeanduse_casefrom request body. - Depending on above
use_casebeing sync/async, it starts processing request immediately to send back the response or processes it using a thread pool so that client can get response via a callback later. - The service retrieves a template from the database based on above
use_case. If multiple templates exist, it proceeds with the one with the highest priority. - The retrieved template is populated with actual values from
paramsto create the request payload.
Making LLM Calls:
- The platform selects the appropriate LLM SDK based on template configurations.
- The constructed payload is passed to the LLM API.
- Platform request parameters, LLM request objects, and responses are captured and stored in the database.
- In case of failure, the system can retry the request using the same or next available template for the above
use_case, depending on the failure logic handler. If using the same template again, the retry can be immediate or delayed based on whether theuse_caseis synchronous or asynchronous.
Managing Synchronous And Asynchronous Calls:
- Synchronous (Sync) Requests: The platform returns the response immediately after receiving it from the LLM API.
- Asynchronous Calls: If a callback HTTP API or Kafka event is configured, the platform triggers it with the response once available.
- If no callback exists, callers can retrieve response later usingrequest_id.
Pseudo Code
Benefits Of The Centralized Approach
- Consistency across services: A unified system ensures that responses follow a uniform structure, reducing inconsistencies and simplifying downstream processing..
- Simplified credential and model management: API keys, model configurations, and access control are centrally managed, improving security, reducing manual effort, and making key rotation seamless.
- Seamless model upgrades and switching: The centralized architecture allows easy upgrades to new LLM models and versions without requiring individual teams to modify their integrations.
- Improved security and compliance: A single controlled gateway ensures that all data flowing through the system is monitored, reducing the risk of sensitive information being inadvertently shared externally.
- Enhanced monitoring and debugging: Storing requests and responses in a database enables easy tracking, troubleshooting, and analytics. Logging all requests and responses simplifies issue resolution and performance tracking.
- Reduced development and maintenance overhead: Instead of multiple teams building and maintaining redundant integrations, the centralised platform handles all LLM interactions, reducing duplication of effort. Test cases can also be reused, further minimising development workload.
- Better cost management: Centralised tracking of LLM usage allows to monitor costs per project or team, enabling better budgeting and resource allocation.
- Ease of use and time efficiency for clients: With a single point of integration, clients can quickly onboard and start making LLM calls without worrying about configurations, API key management, or response handling. The implementation of template-based request processing further reduces manual intervention, making the process seamless and time-efficient.
Challenges Of The Centralized Approach
- Handling diverse prompts and use cases: Different teams require LLMs for various purposes, leading to a wide range of prompts and expected outputs. Managing these diverse requirements within a single platform is complex.
- Response validation and error handling: Since different teams have different response expectations, validating and ensuring that responses adhere to specific formats remains a challenge. Additionally, handling errors dynamically without disrupting workflows requires careful design.
- Potential performance bottlenecks: Centralising all LLM requests means the platform must efficiently handle high traffic volumes without creating delays or single points of failure.
- Dependency on the platform: Teams relying solely on the centralised service may face delays if the platform encounters issues, requiring a robust fallback mechanism.
- Scalability for new models and APIs: As newer models emerge, the platform must continuously evolve to support them without disrupting existing workflows.
Navigating Limitations Of The Centralized Approach
- Template-driven prompt standardisation: To manage diverse prompts, we implemented a template-based approach. Use cases and service types are mapped to predefined templates, ensuring consistency while allowing customisation through parameterised placeholders.
- Partial resolution of response validation: While response formatting is still an ongoing challenge, templates help ensure that input requests are structured correctly. However, validating and transforming responses into a standardised format remains a work in progress.
- Error handling mechanisms: We incorporated retry mechanisms, alternative template selection, and structured failure handling to improve error resilience. However, response validation across various use cases is an area for future improvement.
Next Steps
Moving forward, we plan to implement an internal smart rate limiter to manage API limits imposed by LLM providers. However, we do not want this limiter to block high-priority requests due to rate limits. To address this, we will implement a dynamic rate limiter that adjusts allocation based on request priority. This means:
- High-priority requests will always be served first, even if rate limits are close to being reached.
- Lower-priority requests will be throttled dynamically based on the system’s available capacity.
- Adaptive strategies will be used to redistribute API call quotas intelligently, preventing unnecessary failures and optimising overall throughput.
Conclusion
By consolidating LLM interactions into a single platform, organizations achieve better efficiency, security, and maintainability. This approach not only streamlines integration but also provides a solid foundation for scaling AI-driven solutions. With structured request handling, parameterised templates, and robust logging, the centralised LLM service enhances standardisation and usability across the enterprise. Additionally, planned improvements like dynamic rate limiting will further optimise resource utilisation and ensure seamless service delivery.
Join Us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels, and if solving complex problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our teleconsultation service, we partner with 1500+ pharmacies in 50 cities to bring medicine to your doorstep, we partner with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allows patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, Gojek and many more. We recently closed our Series B round and In total have raised USD$100million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalized for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.

