

Schema Change Management at Halodoc
The data platform at Halodoc leverages Apache Hudi and PySpark for data processing. Our pipeline begins by loading data from Source RDBMS into the Amazon S3 raw zone, then using PySpark and Hudi to transform and clean the data in the processed zone. We use AWS Glue Data Catalog for metadata management and load the processed data into a data warehouse layer in Amazon Redshift. Schema changes in the source database are common due to business growth, evolving requirements and new product developments. As the data platform team, we must continuously adapt to these changes to ensure data consistency and reliability. In this blog, we will discuss how we handle schema changes in our Lakehouse architecture.
Why We Built an In-House Framework
While Hudi provides automatic schema evolution, we built an in-house framework to extend support for schema evolution features that Hudi does not natively offer.
- Glue Data Catalog Limitations
We rely on Glue Data Catalog for metadata management and while it allows altering table schemas, including data type changes, these changes do not propagate to the actual data stored in our S3. If a column in the source RDBMS changes fromSTRINGtoINTEGER, we can update the schema in Glue Data Catalog, but the data remains in its original format in S3. Since our data is stored in Parquet format, the column’s actual data type remains unchanged at the file level, which can lead to compatibility issues when reading or querying the data. This limitation makes it difficult to fully leverage Hudi’s automatic schema evolution. - Maintaining Source RDBMS Schema in a Control Plane Table
We store the source schema in a configuration table to prevent data type mismatches when performing incremental loads. This ensures the schema remains consistent across runs and data type differences between Source RDBMS, PySpark and Glue Data Catalog are properly managed. - More Control Over Schema Changes
By handling schema changes in-house, we can detect and manage column additions, deletions and data type changes. This approach allows us to maintain schema consistency across all stages and prevent potential issues caused by unexpected schema modifications.
Schema Comparison Module
To efficiently track and manage schema changes, we developed a Schema Comparison Module. This module compares the schema stored in our configuration table with the schema generated by PySpark.
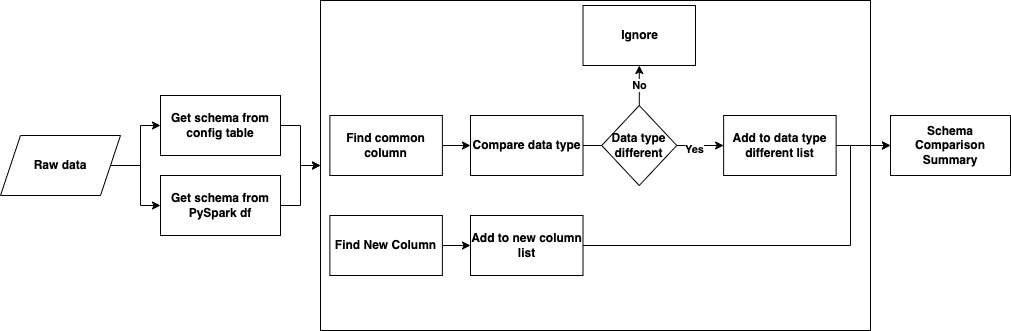
The process begins by extracting the schema from two sources: PySpark’s auto-inferred schema and the predefined schema stored in our configuration table. After both schemas are retrieved, they are compared to identify any differences, including newly added columns and data type changes. The result from this module will help in handling schema changes in our framework.
Types of Schema Changes
There are three primary types of schema changes:
- Column Addition
- Data Type Changes
- Column Deletion
Column Addition
When a new column is introduced in the source RDBMS, our pipeline must detect and accommodate the change to maintain data consistency. Here’s how we handle it:
- Schema Detection
Using the Schema Comparison Module, we identify discrepancies between the existing schema and the incoming incremental data. If a new column is detected, it is flagged for further processing. - Schema Retrieval from RDBMS
Instead of immediately modifying the schema, we first retrieve the latest schema definition directly from the source RDBMS to ensure accuracy in column names and data types. - Updating the Schema Configuration
Once the updated schema is retrieved, we update our schema configuration table to reflect the changes. - Processing Data with the New Schema
After the schema is updated, we continue reading data using the new schema definition. For historical consistency, older records will haveNULLvalues for the newly added column to ensure seamless data integration.
Glue Data Catalog Synchronization
Glue Data Catalog allows adding new columns without requiring a full table recreation. Our framework will update the Glue Data Catalog schema to reflect the newly added column.
Column Deletion
Column deletions in RDS can occur due to various reasons, such as business changes or a particular column becoming obsolete with no more data being written to it. However, this is a rare case in our RDBMS source, as column deletions rarely happen at the source level. If a column is missing in the new schema but still exists in the Glue Data Catalog, we do not remove it to avoid breaking downstream processes and also Glue does not support dropping columns without affecting the table structure. Instead, we modify the PySpark DataFrame by adding the missing column back and filling it with null values. This ensures that Hudi table creation continues without failure and that existing queries expecting the column do not break.
Data Type Changes
Data type changes do not always require manual intervention. In most cases, we do not need to take any action for certain data type modifications. For example, increasing the length of a VARCHAR does not require handling, as Glue Data Catalog stores it as a STRING. Similarly, changing an INT to a LONG is not an issue since we treat it as a LONG by default. The only cases that require intervention are increasing DECIMAL precision and converting a column to DECIMAL as these can break the pipeline.
To handle these cases, we implement a workaround by creating a separate pipeline. This approach ensures that necessary schema changes, such as increasing DECIMAL precision or converting INT to DECIMAL, are handled without disrupting existing data pipelines.

- Schema Detection
Using the Schema Comparison Module, we identify columns where data types have changed and determine the expected new data type. - Reading Existing Data & Applying Transformations
We load the existing data from the Hudi table into a PySpark DataFrame and apply the necessary transformations to align with the updated schema. - Creating a Temporary Hudi Table
The transformed data is stored in a temporary Hudi table that follows the updated schema. - Dropping & Recreating the Glue Table
Since Glue does not support altering column data types, we drop the existing Glue table and recreate it using the new schema extracted from the temporary Hudi table. - Replacing the Old Table with the Updated Schema
After the Glue table is recreated, we move the transformed data from the temporary Hudi table back into the main table. The temporary table is then dropped to free up resources, ensuring a seamless transition to the new schema.
Benefits of Automating Schema Change
- Automated Handling
On average, five such schema changes occur each month. Our automated pipeline handles these changes seamlessly without requiring manual intervention. - Significant Effort Savings
Manually handling each schema change takes approximately 2-3 hours. This includes reading the new schema from the RDBMS source, fetching the updated schema, modifying the control table, determining when the new column was introduced and reprocessing data from that table. By automating this process, we eliminate the need for manual effort, saving up to 15 hours per month.
Conclusion
In summary, our in-house schema evolution framework ensures seamless schema changes in our data pipeline by detecting and handling column additions, deletions and data type modifications. By leveraging a structured approach with the Schema Comparison Module and automated schema validation, we maintain data consistency, significantly reduce manual effort and prevent disruptions. This approach gives us greater control over schema changes, mitigates Glue's schema limitations and ensures reliable data processing as our platform evolves.
References
 Jitendra Shah
Jitendra Shah


 apache
apacheJoin us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek and many more. We recently closed our Series D round and In total have raised around USD$100+ million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs and are continuously on a path to simplify healthcare for Indonesia.


