

Data Archival Strategies at Halodoc
The database is the core component of any technology company. We at Halodoc, use both RDBMS and NoSQL databases for our services along with ElasticSearch to cater to our search requirements.
Since the inception of Halodoc, MySQL has been our primary choice for the data storage for all our major services i.e. Pharmacy Delivery, Tele Consultations, User Communications, User Management, etc, due to its cost effectiveness. It has scaled really well with time, helping us records millions of transactions in a month for both tele-consultations and pharmacy-orders.
We use the master-slave architecture of MySQL and have split our databases across various AWS-RDS clusters to balance the loads on the servers. Even with this architecture, there are few services that created hundreds of thousands of entries in the database every day and grow at very rapid pace (like OTP, orders, push-notifications/communications, etc.)
What is Data Archival ?
Data archiving is the process where data that is no longer actively used is moved into a separate storage device for long-term retention. The archived data consists of older data that remains important to the organisation and must be retained for future reference or regulatory compliance reasons. Data archives are usually cheap, indexed and have search capabilities, so documents can be retrieved as per the requirements in the future.
Why we need to Data Archival ?
Huge amounts of data which are non-essential to the system’s transactional flows (historical data like orders from the last year, audit data like the history of order transitions, etc), if present in the primary databases, add a significant performance bottleneck and cost impact when data is queried from the underlying data source.
Cost Optimisation
We wanted to reduce the spending on our RDS storage (cost of per GB of long term storage of data is less than per GB cost of data stored in RDS). Since the MYSQL follows the master-slave replication, as the data grows, we have to scale it vertically - i.e. moving to bigger machines. With the increase in the size of RDS, we would be paying more and this cost will always grow with the growing business. Also, the AWS managed RDS can only be scaled up (storage once added cannot be removed).
Performance Optimisation
With the increase in the size of the table, the B-tree index size (tree height) would also increase, which means all the queries would take a hit. MySql hits performance benchmarks for about the cluster size of around 200 GB and we had reached this limit for a few of our databases. Removing the older data which would be seldom used would give significant boost to the time taken by the DB queries.
Categorising the Datasets
Identify the different types of data and bucket them into various groups. We can categorise the data majorly in 2 Buckets -
Transactional Data
This data has to be removed very carefully as this could lead to foreign key violations and could create problems in the system -
- Orders
- Items
- Attributes
Non Transactional Data
This data could be achieved as this is rarely used after its lifecycle. This data could be removed from the database and kept as snapshot into low cost storage
- Communications
- Audits
- OTP
Data Archival Strategies
Using MySQL Data Partitioning
In this approach, we move a specific amount of rows (based on partitioning policy) to a different partition of the table which can be easily deleted/moved. The application doesn’t need to get the context of these partitions, for connected applications the partitions will come together and serve as a single table. The reads become faster as the application will read from a fraction of the table.
Limitations
Partitioned InnoDB tables cannot have foreign key references, nor can they have columns referenced by foreign keys. “Every unique key on the table must use every column in the table's partitioning expression“ - so the column used in the partitioning strategy must be part of all the unique key. These limitation made us look into the other strategies for the archiving the database.
Data Archival using Scripts
There are two approaches which we followed here -
Renaming Approach
- Create a new table named
orders_latestwith the same schema. - Copy the recent data from original table
ordersto this table - Now swap the table names
orders->orders_archiveandorders_latest->orders
Problems faced with this approach
- We can use
CREATE TABLE LIKEcommand to create similar schema table but this command does not copy foreign key constraints and index data. Alternately, we can useSHOW CREATE TABLEto get the table SQL and use the same to create new table - In this case as well, we would need to take care of duplicate foreign keys - those would need to be renamed as foreign key names needs to be unique. - We need to take care keeping the data of
ordersandorder_latestin sync while the copy operation is going on so that we don't lose the new inserts/updates happening on theorderstable - this could be achieved usingtriggersoncreateandupdateoperations along with running the script in non business hours.
Deletion Approach
- Create a new table named
orders_archivewith the same schema. We can useCREATE TABLE LIKEstatement to do so since we would not need the foreign key constraints for the archive data store. - Copy all the data older data from
orderstable to theorders_archivetable for the specified date range. Here we would fetching theidsof the records to be copied and use the sameidsto fetch the records from referencing(child) tables - Delete the older data from the original table
orders(starting from the referencing tables) - the delete operation has to be done very carefully in batches as it could result in locking the tables and making system down
For both the above approaches, in case of multi referenced tables, we would need to handle the data of the child/referencing tables as well as the parent tables to ensure that the foreign key constraints of MYSQL are not violated. We had to handle this since use NO ACTION on delete cascades. The following command can be used to find all the referencing tables, relationship and the columns used in foreign keys -
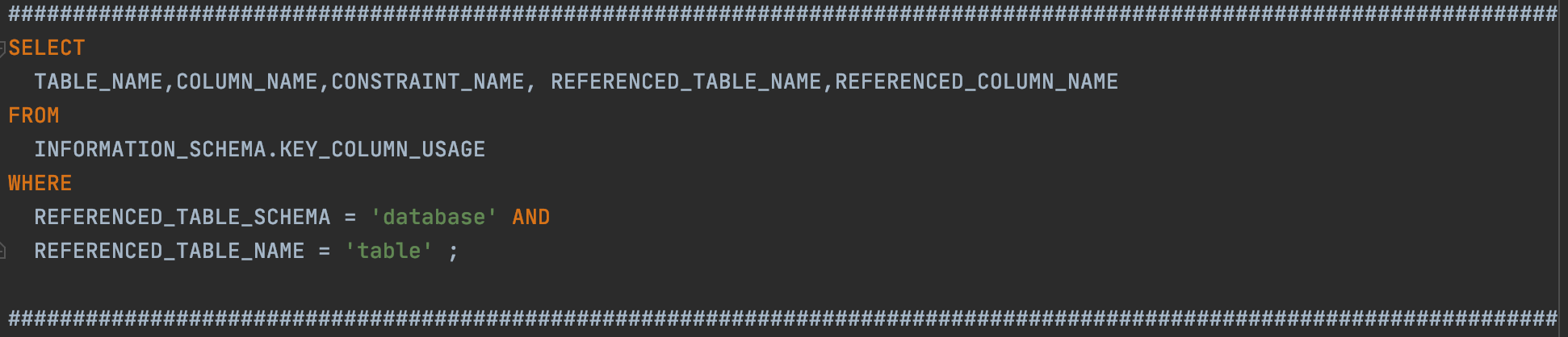
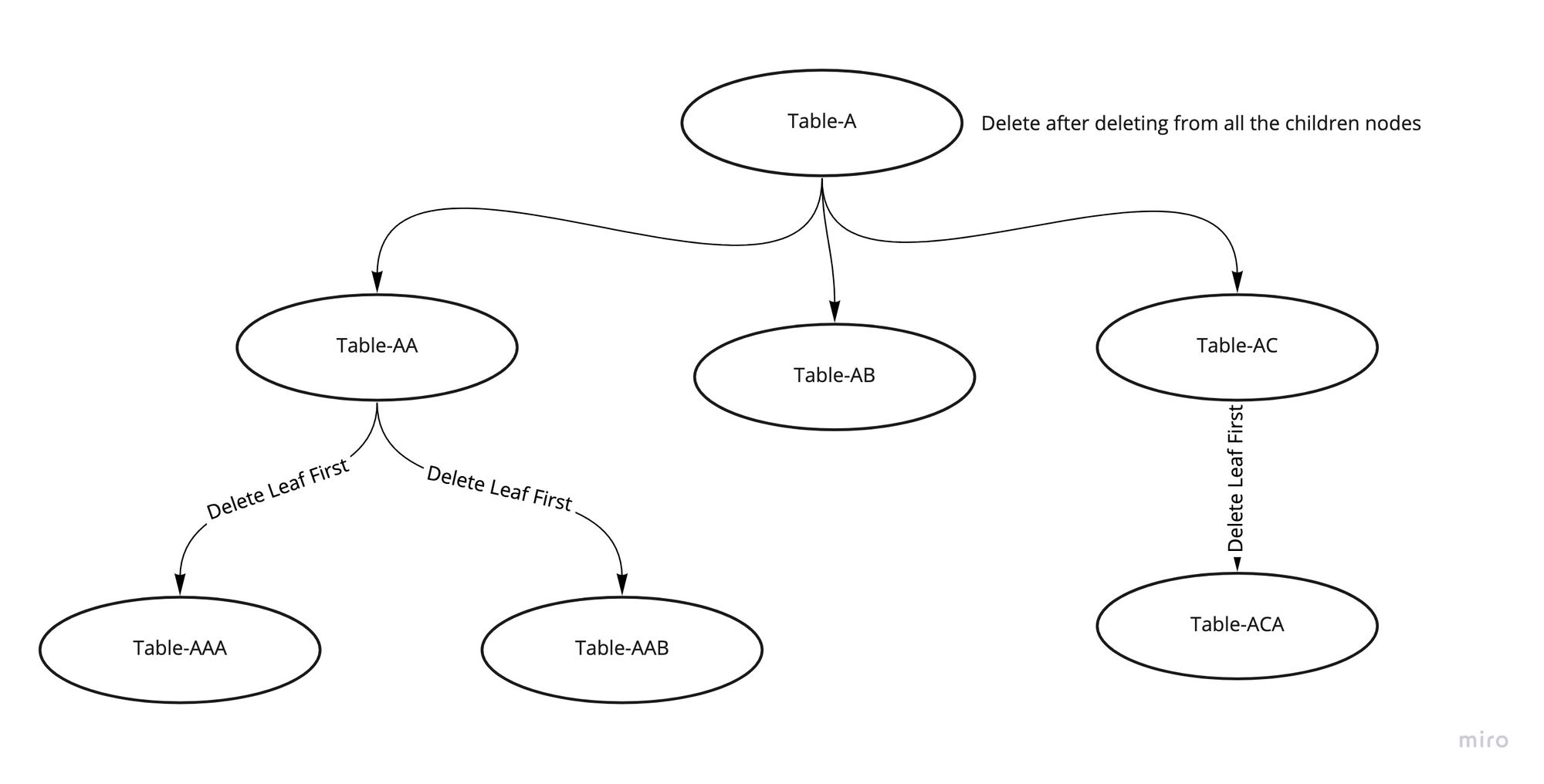
In our case, we went ahead with the deletion approach, we had around 20 dependent tables for our main entity - to delete the data from the main table, we created a tree for the dependent tables and used BFS(Breadth First Traversal to delete the data - starting with the leaf node to the root table (basically level order traversal of the tree and processing the lowest level first and then moving up)
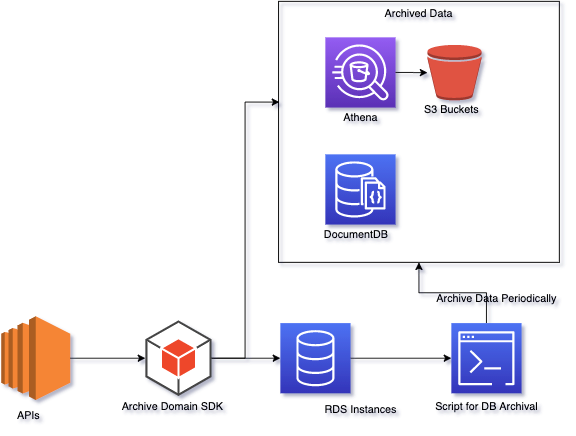
Moving Archived Data to the other Source
After removing the archived data from MYSQL we need to move this data to other data sources which are comparatively cheaper than RDS - the following have been considered -
- S3 - made queryable via Athena
- DocumentDB
We created in-house SDK for querying the data from configured data source as the use-case would wary based on the type of data - the SDK would fetch the data from the archived data source in case the record was not found in the main data source.
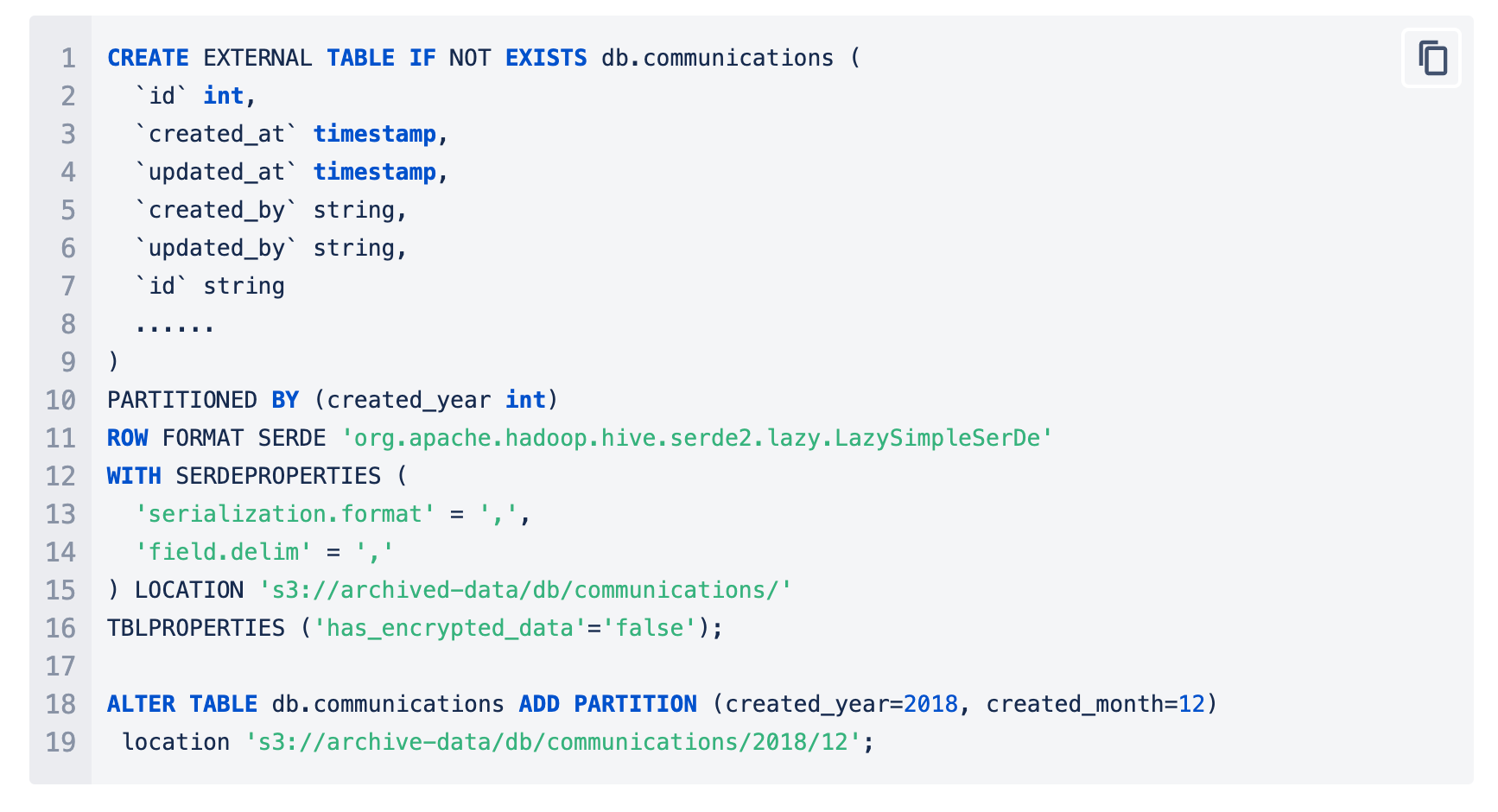
For non-transactional data - we moved all the data to S3 and created the tables in Athena making it queryable. In Athena, we can make use of partitions to reduce the scans and improve the performance of the queries. The cost for querying on Athena would be ~5USD/1TB of scan - this cost could be reduced drastically using the partitions and querying the data using those partitions. In our case, for the non transactional data like communications we partitioned it based on the year and month which reduced the data-set.
For transactional data, using scripts and the in-house SDK to push the records to the documentDB data store in batches. We created @ArchivedDomain Annotation that needs to be added over the domain which has to be archived along with all the dependencies. The parameters required for the annotation would be -
name- table/collection name in the archive data store.clazz- archived domain.provider- archive data store provider (DocumentDB/Athena)
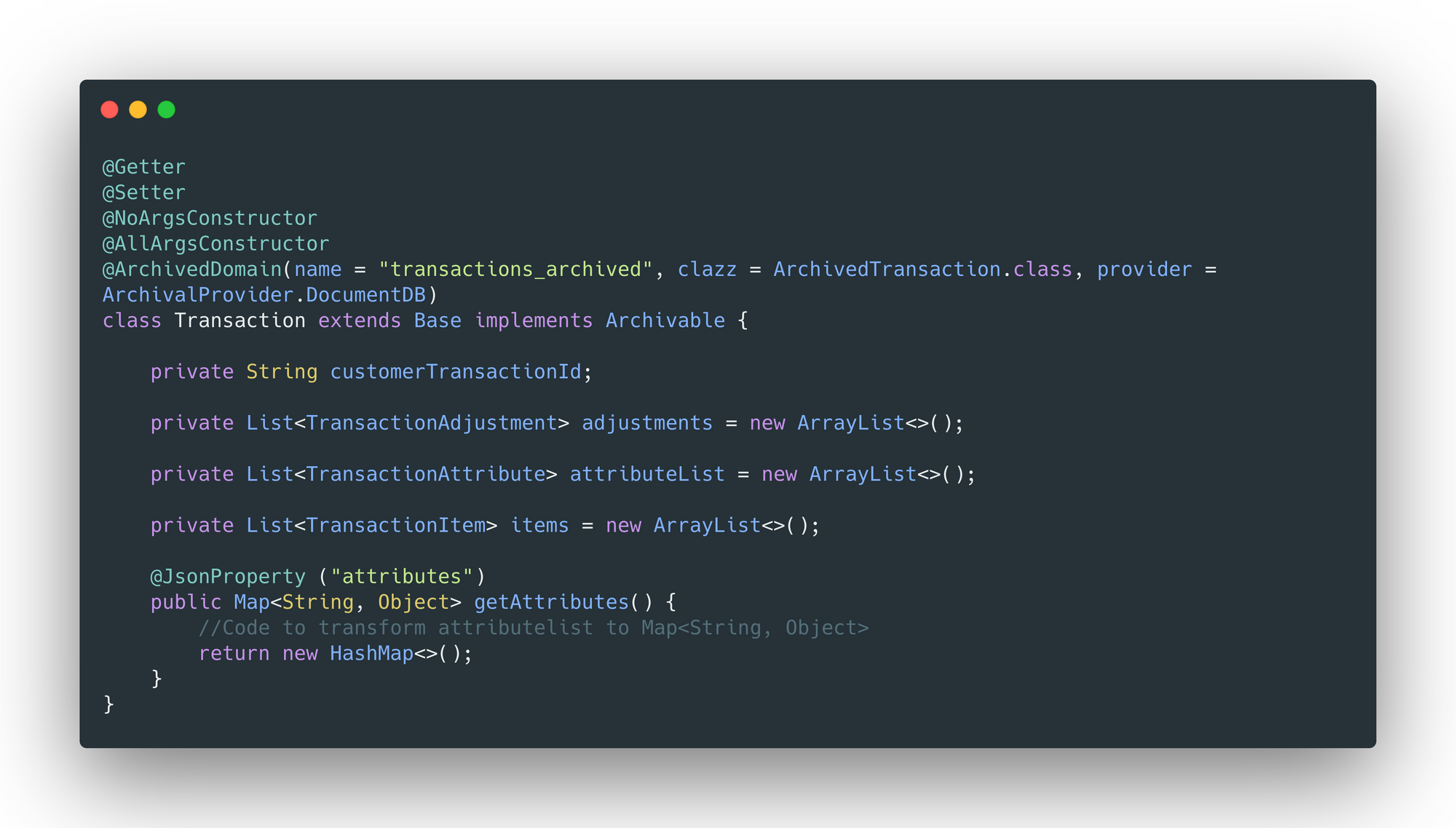
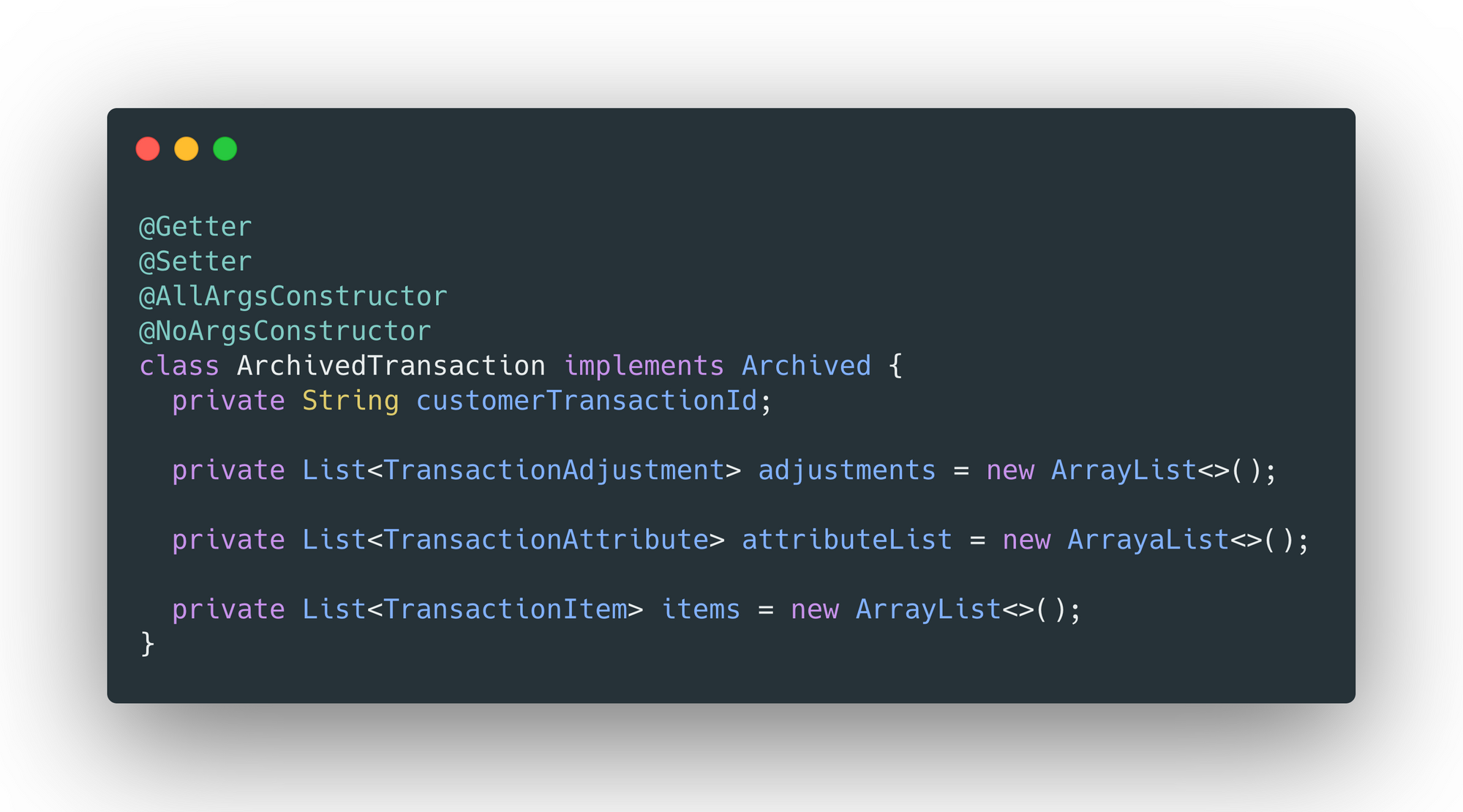
The domain that needs to be archived, must implement Archivable interface. And the replica domain needs to implement the Archived interface - Data will be retrieved and archived in the format specified in the structure of this domain
Conclusion
Archiving the data from our major services like otp, communication, user-transactions has given us both cost and performance benefits. We were able to reduce the size of the databases by about 45% overall and improve DB performances
Data Archival is an ongoing process which needs to be done after a certain period, as next steps - we are now looking forward to automate this process so the archival process would trigger based on the configured threshold.
Join Us
We are actively looking for engineers across all roles and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our teleconsultation service, we partner with 1500+ pharmacies in 50 cities to bring medicine to your doorstep, we partner with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allows patients to book a doctor appointment inside our application.We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates foundation, Singtel, UOB Ventures, Allianz, Gojek and many more. We recently closed our Series B round and In total have raised USD$100million for our mission.Our team work tirelessly to make sure that we create the best healthcare solution personalized for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


