

Demystifying Redshift Cluster Resizing
Amazon Redshift is a massively parallel processing data warehousing solution that allows organisations to process vast amounts of data quickly and efficiently. As the data volumes and processing requirements evolve, it becomes crucial to resize Redshift clusters to optimize performance and accommodate changing workloads.
In our previous blogs, we focused on building a platform with a decoupled architecture having storage and computation capabilities at scale. As we marched closer on our journey toward’s the datalake house architecture, we simultaneously had the responsibility of gracefully downscaling the existing Redshift cluster and planning for the upgrade of the new cluster to cater to the upcoming demands. In this blog post, we will explore different techniques for resizing Redshift clusters and some of the challenges faced during the expansion and reduction.
Resizing Techniques
Amazon Redshift offers two types of resizing techniques,
- Classic resizing
- Elastic resizing
What is Classic resizing?
Classic resizing support vertical and horizontal scaling and it ensures the data is redistributed across all the nodes and not restricted to any of the cluster types. This support the following cluster types.
- RA3
- DC2
- DS2
What is Elastic resizing?
Elastic resizing support both vertical and horizontal but with certain limitations with node type changes and node counts. This supports the following cluster types,
- RA3
- DS2
- DC2
Elastic Resize vs Classic Resize
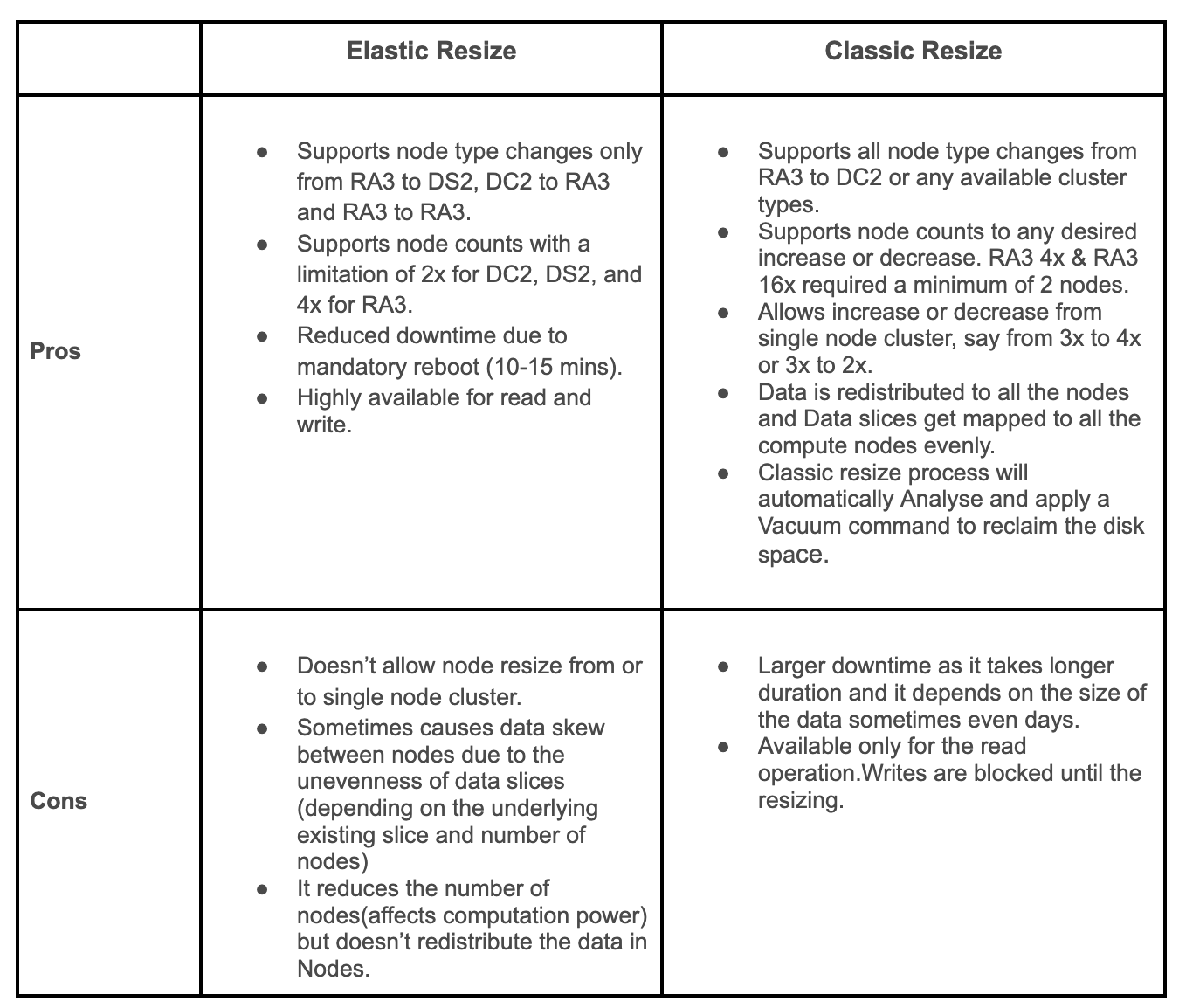
Lets see how Downscale and Upscale operations can be performed using these resizing techniques
Scenario : Downscaling by using Elastic Resize
Why Elastic Resize?
As we explained earlier, we had to downsize our existing cluster which is 5x RA3 x plus to 3x RA3 xplus with several TB's of volume. Hence we opted Elastic resize on the following basis
- Downtime: Since some of the critical dashboards consume the data and to keep the ETL’s refresh in the existing redshift it is important to resize the cluster with minimum downtime. Also with past experience while scaling up the cluster using classic resize we had to spend ~8 hours for ~ 1 TB. Hence keeping the write downtime of 10 ~ 14 hours and this can take longer duration which is not an ideal scenario from the business continuity perspective.
Observations:
- The process took around ~15 to 20 mins.
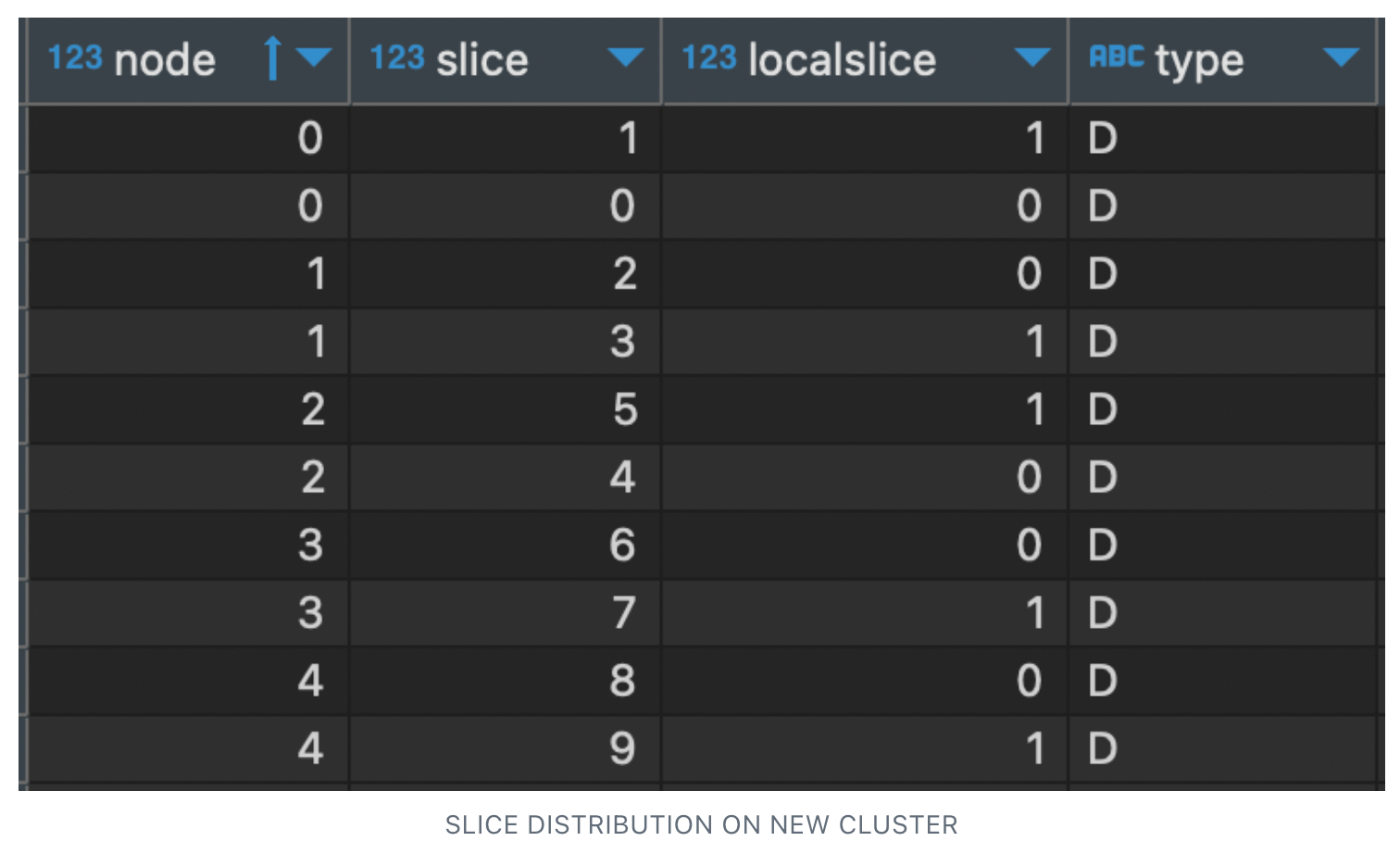
- Initially, we had 10 slices, i.e. 2 slice per node (2 * 5 = 10 slices). Hence each of the compute nodes was holding 2 slices which are evenly distributed.
“Select * from STV_SLICES”
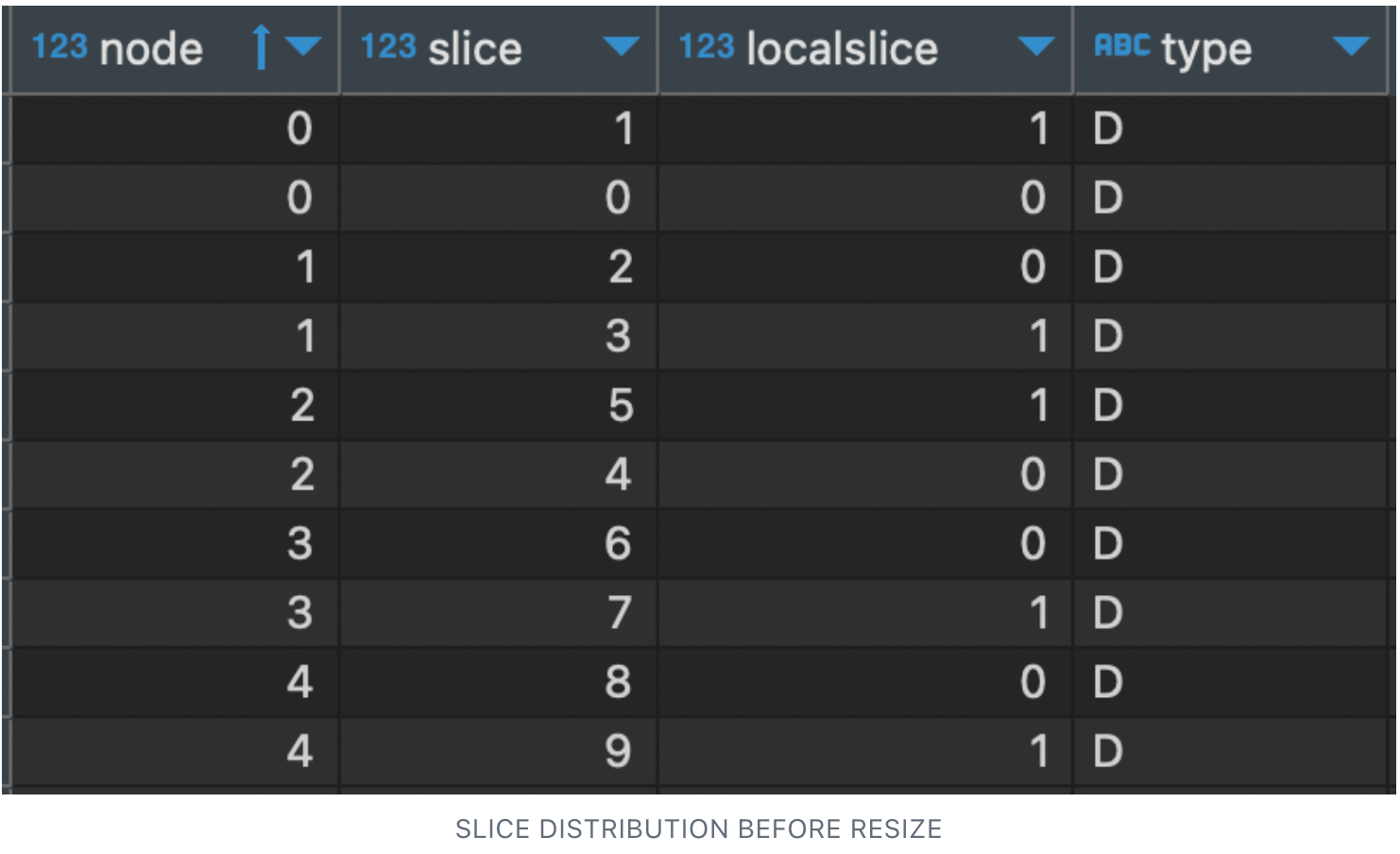
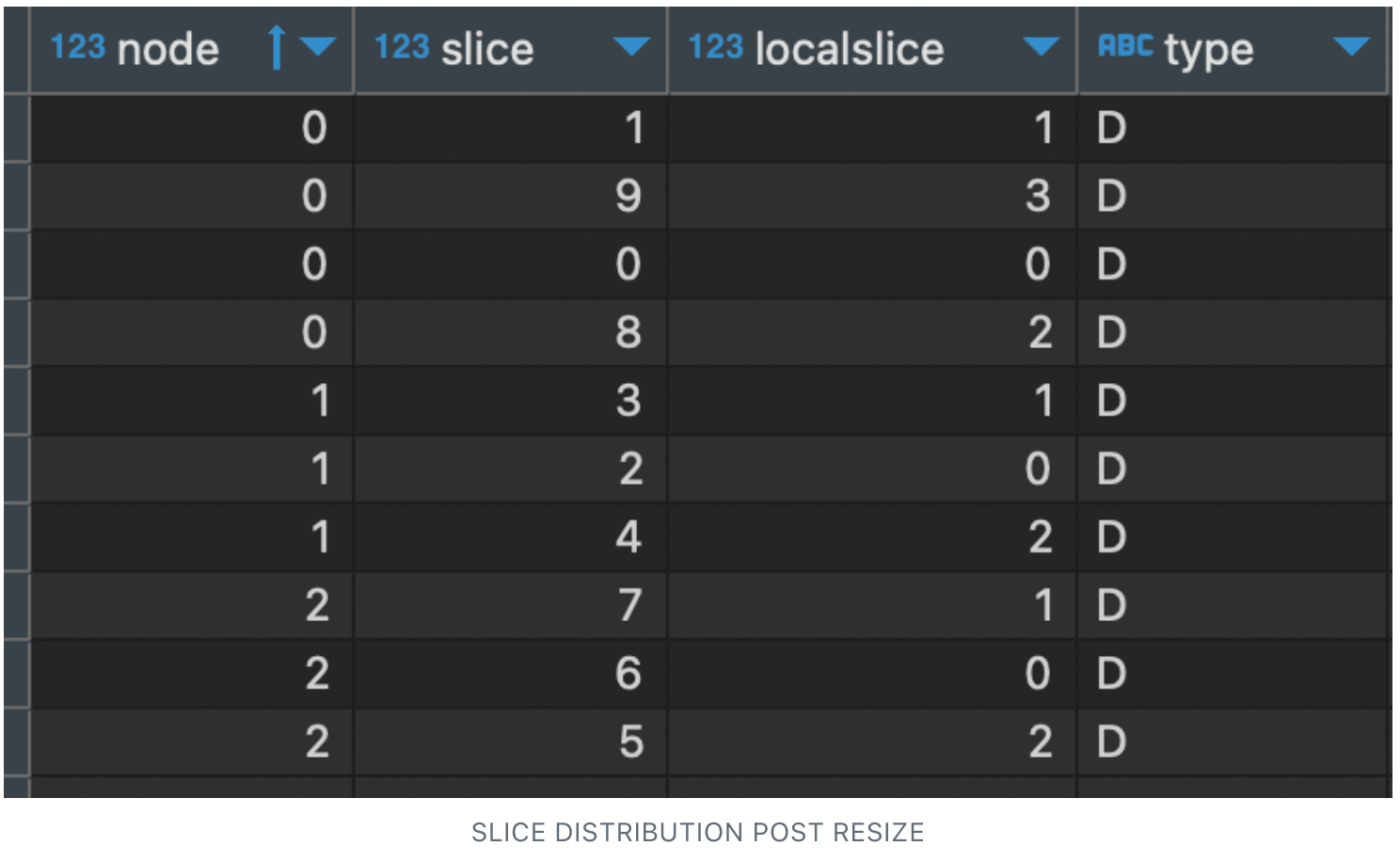
We observed the Elastic resize didn’t redistribute the data slices evenly, but rather mapped the slice from the reduced nodes 4 and 5, which resulted in node 0 getting an additional slices. Also this increased usage of the compute 0 compared to 1 and 2, which means the compute 0 has to process more records.
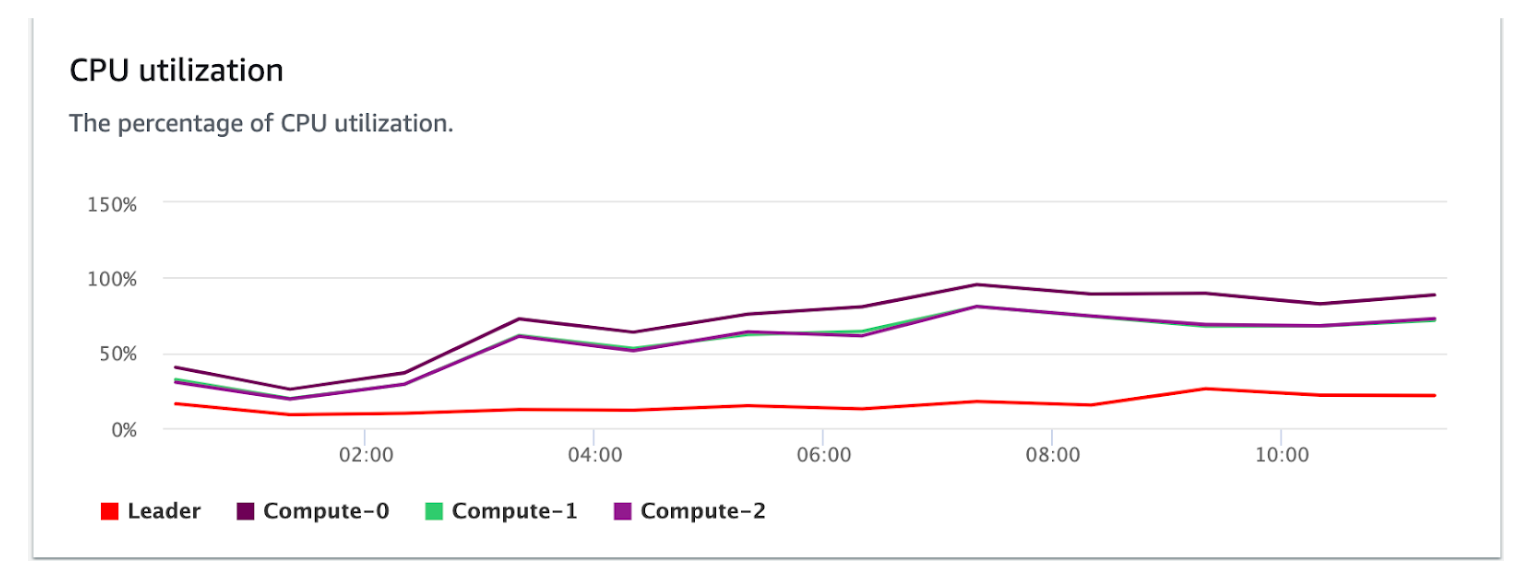
What is the challenge ?
Redshift operates the incoming query in parallel across all the compute nodes, though the query result from compute 1 and 2 are processed quickly, still, the query result will be running state until the compute 0 data slices are also gets processed. This eventually increases the query runtime and caused the new incoming query to be queued.
To solve the problem:
The idea is to keep balance between the compute nodes as much as possible and reduce the waiting time of the queries.
- Understand the queued-up queries in the redshift and get clear information on the current redshift queuing behavior, using the below query.
“select service_class, state, count(query) from STV_WLM_QUERY_STATE group by service_class,state order by service_class,state “
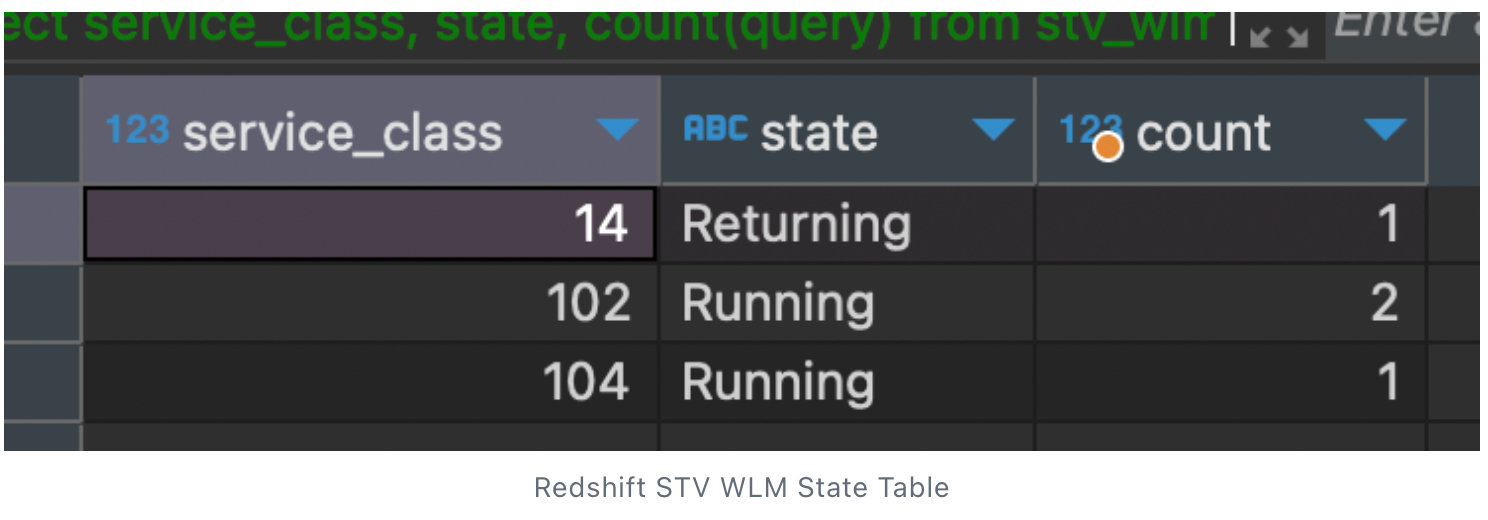
- Modifying the Work Load Management (WLM), by providing high priority for the required service class, i.e. providing the normal priority for the ETL user and high for the BI application for dashboard related. Also moving the rest of the service to default to the Low priority.
“select * from STV_WLM_CLASSIFICATION_CONFIG”
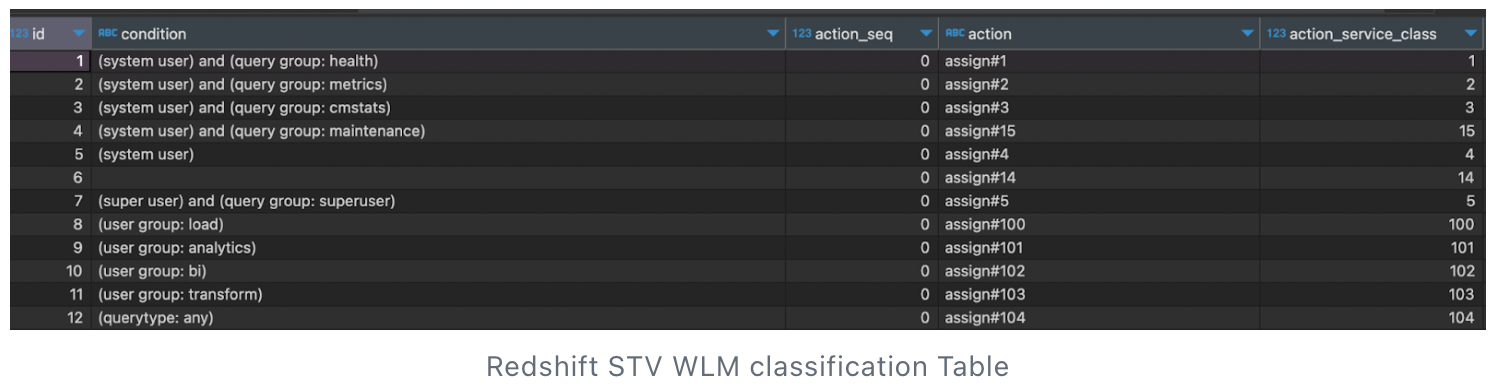
- Pushing the ETL’s refresh post-business hours and reducing the number of frequencies from 6 to 4 each to reduce the write operations.
- Using the Concurrency scaling cluster to avoid the queuing of the queries during peak hours. currently, we have 5 clusters, which can be utilised over a 2 hours interval per day.
Scenario: Upscale using Classic Resize
Why Classic Resize?
We need to upscale the Redshift cluster from 4x DC2 to 5x DC2. Hence we opted classic resize on the following basis,
- Availability of cluster node: The required resizing configuration was not available in Elastic Resize, due to the service limitations.
- Downtime: Unlike the existing cluster, we had the flexibility with the downtime, since most of the ETL’s task runs as an overnight batch. Hence even 5 ~ 8 hours of write operation downtime can be accommodated as long the BI application were able to read the data.
- Storage: Expected growth with contingency of 10% to 15 %, ideally one more node should be sufficient.
Observations:
- The process took around 3 ~ 4 hours.
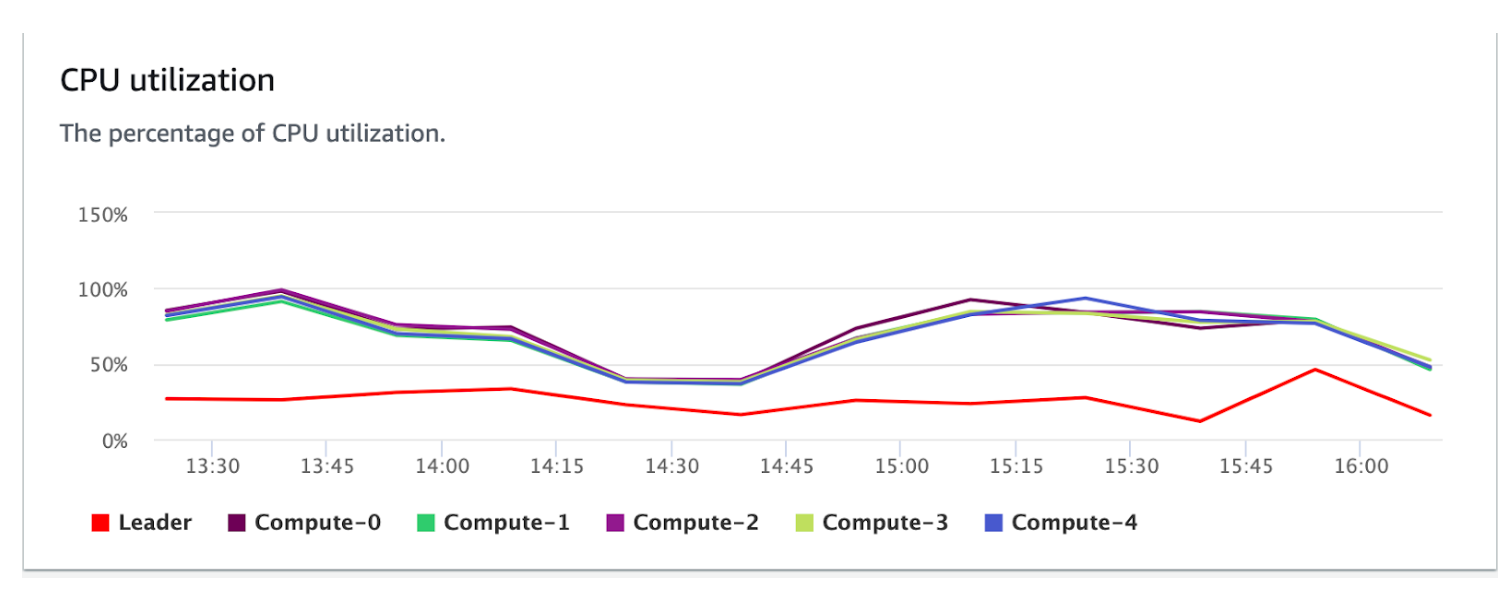
- Redistribution of data and data slices gets evenly distributed to the nodes.
- Computation was even across all the compute nodes.
Some of the best practices:
- Before resizing your cluster, closely analyse and monitor the workload patterns. Identify periods of high query concurrency and any performance issues during peak usage times. This information will guide in resizing decisions and help to choose the right cluster configuration.
- Understand the current slice distribution on the redshift cluster and plan for the desired cluster nodes.
- Take snapshots before resizing the cluster for backup purposes. It act as restore points in case any issues arise during or after the resizing process. This will also help in restoring the previous cluster state during failures.
- Ensure to note the snapshot cut over time. This will help to locate the point when to rerun the ETL processes to load any post-snapshot data into the target database during the snapshot-based resize process or classic resizing.
- After resizing, test and validate the cluster by checking the redistribution of the data and running a few queries for data integrity checks.
- Set up the cloud watch alarm and regular housekeeping checks to monitor the health of the system post-scaling.
Conclusion:
In this blog, we have discussed the different approaches for resizing the Redshift cluster and some practical observations, challenges during this process. As per our experience we can go with elastic resize, if the desired target node configuration is available and data node slices are mapped evenly. We can go with classic resize if we can observe the downtime of the cluster or cannot find the desired cluster node configuration under Elastic resize.
References:
- https://repost.aws/knowledge-center/redshift-elastic-resize
- https://docs.aws.amazon.com/redshift/latest/mgmt/managing-cluster-operations.html#classic-resize-faster
Join us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek and many more. We recently closed our Series C round and In total have raised around USD$180 million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


