Integrating EMR with MWAA in Our Data Platform
The Halodoc data platform plays a crucial role in providing essential data for our decision-making process. We use Amazon EMR(Elastic Map Reduce) for our core data processing utilizing PySpark framework, and MWAA(Managed Workflow for Apache Airflow) for job orchestration. In our previous blog, we discussed how we built a Metadata Driven Architecture. By following this approach, we created a framework where we can dynamically introduce new tasks, re-configuring an existing task as well as scale our resources based on need.
In this blog, we will focus on how we integrated MWAA and EMR within our data pipeline. We'll explore how we developed a system that automatically creates an EMR resource, runs PySpark code on it, and then shuts down the EMR cluster once the job is done, all managed through MWAA.
Overview of EMR in Our Pipeline
In this blog we described our Lake House Architecture where we have 2 main layer, Data Lake and Data Warehouse layer. In the Data Lake layer, we categorize the process as Raw to Process and Process to Report. Raw to Process is where we use EMR to process our source CDC (Change Data Capture) raw data using PySpark+Hudi to create a processing layer. Process to Report is where we create an aggregated/reporting layer by processing the processed data presented in Data Lake by using PySpark. Our choice of target can vary, including options like Amazon Redshift, MySql or S3 files, depending on our specific business needs.
Since we are supporting various Halodoc businesses, we cannot avoid creating hundreds of aggregated/reporting tables to support our various use cases. We use batch processing for Raw to Process and Process to Report, that means we will only need EMR when the process is scheduled. That is why we built the MWAA and EMR integration. MWAA can orchestrate the EMR cluster by creating it, running the PySpark code, and terminating it once the process is completed. This approach optimizes costs and resources as EMR is not running continuously.
EMR Operator in MWAA
MWAA as a job orchestration comes with many operators and hooks, including EMR operator. We are utilizing EMR operator to manage EMR resources and we build it in MWAA code. There are several EMR Operator functions available[1], but mostly we only use 4 operators.
- EmrCreateJobFlowOperator is used to create a new EMR based on configuration. We can create EMR based on parameters we provide, for example, EMR version, Instance type, AMI version, and many others. All of these parameters pass through the Job Flow Override parameter[2].
- EmrAddStepsOperator is used to add the main PySpark code to our EMR cluster. Our main PySpark code will be submitted using the EMR step.
- EmrStepSensor is used to wait for any EMR steps to be completed.
- EmrTerminateJobFlowOperator is used to Terminate EMR after all steps are complete.
Here is how we structure the Airflow code.
dag/
|- templates.py
|- template_generator.py
|- job_group1_dag.py
|- job_group2_dag.py
We utilize a 'templates.py' file to store our EMR configuration template. Additionally, we have 'template_generator.py' to create a JSON object as needed for Airflow operators. The next 2 files, 'job_group1.py' and 'job_group2.py' are the sample of Airflow DAG that contain the main code.
Template
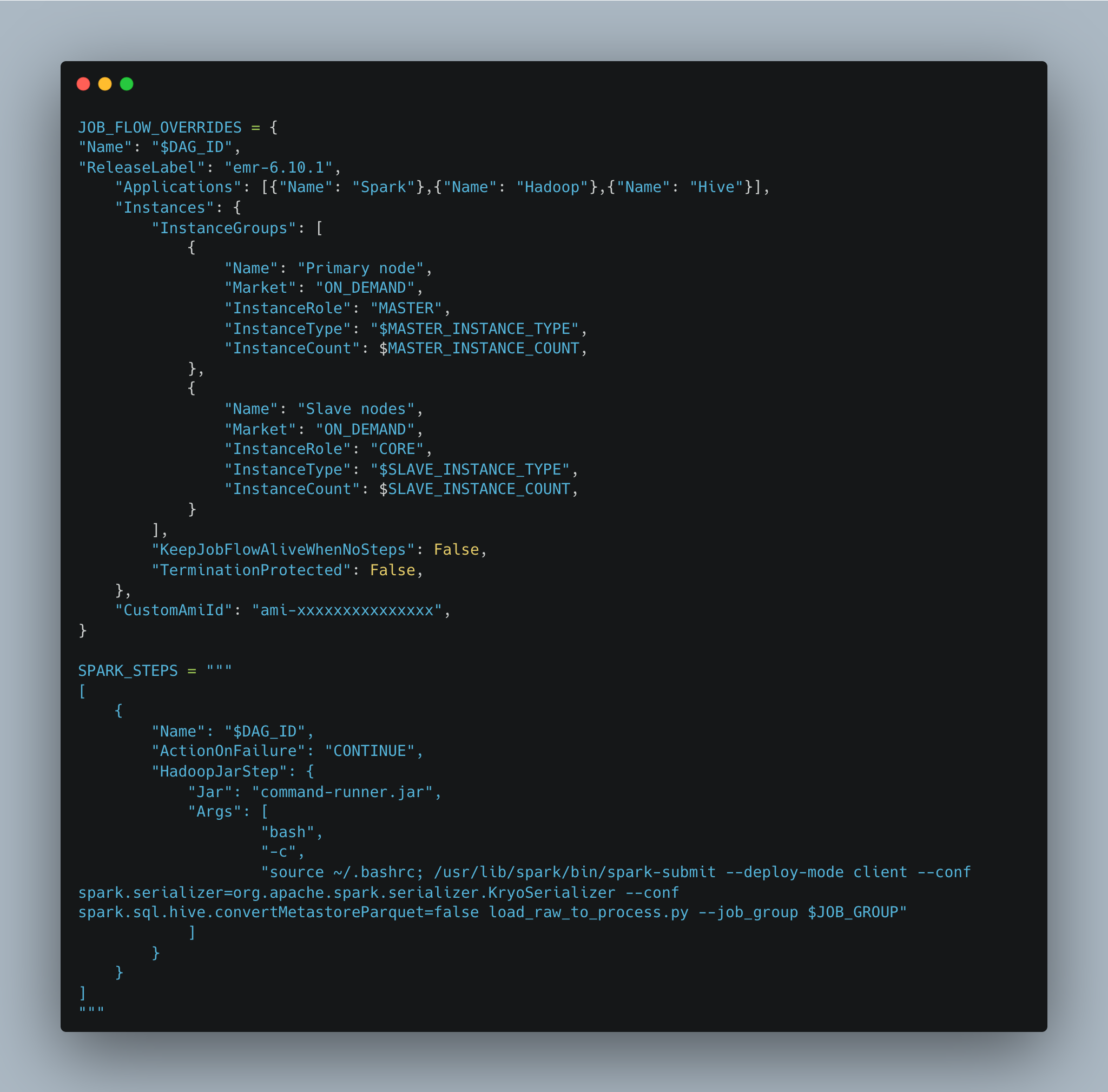
There are 2 variables in this template.
- Job Flow Override
This is a template for all EMR Cluster configurations. We can parameterize several variables to create EMR, for example, we want to pass the Node size of EMR, so we can create value for variable InstanceType and InstanceCount as a parameter that we can generate on Airflow DAG code itself. - Spark Steps
This is the template for the PySpark code. We can submit the job and pass parameters to the PySpark code, following the same concept as Job Flow Override. The value of the parameter can be generated within the Airflow DAG code. In this example, our PySpark code is named 'load_raw_to_process.py', which includes an argument called 'job_group'. We can assign the arguments to dynamically receive a value. We can differentiate processing conditions in the 'load_raw_to_process.py' based on 'job_group' values.
Template Generator

Template generator is just a function to replace parameter we provide on the template with actual value that we can pass on airflow code.
Job Group
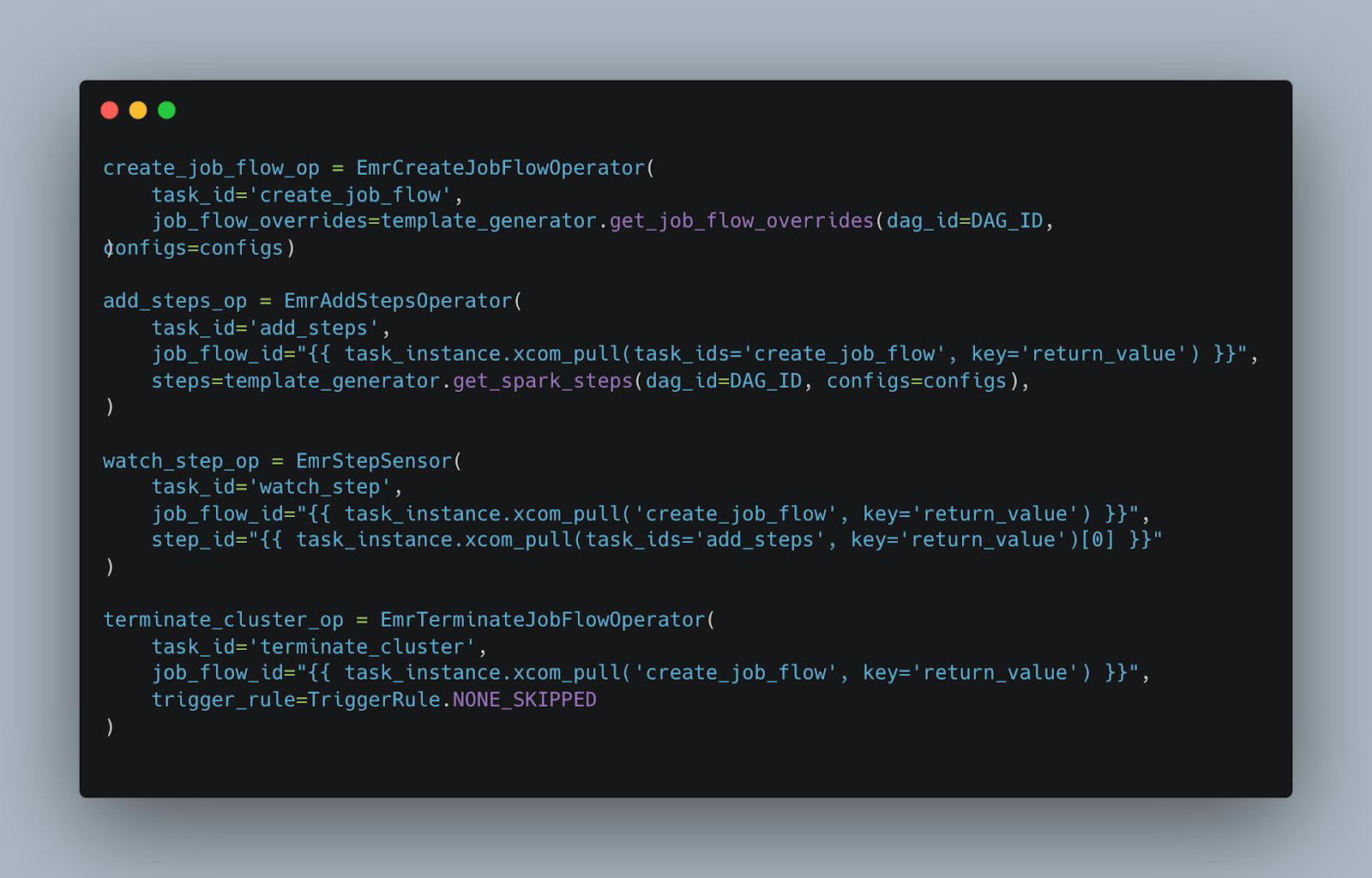
- Create Job Flow (Create EMR Cluster) using EmrCreateJobFLowOperator we are creating an EMR cluster used on the the template and parameter we provide.
- Add StepEmrAddStepsOperator is used to add PySpark code to the EMR cluster. We need the job_flow_id parameter, which is the EMR cluster id that we created in the first step by using xcom_pull function.
- Watch StepEmrStepSensor will keep running until the spark step is completed, to ensure the code we submitted is completed.
- Terminate Cluster (Terminate EMR Cluster)EmrTerminateJobFlowOperator is used to terminate the EMR cluster after all the upstream tasks are completed. This is how we ensure the EMR is only running on the batch schedule and terminated after the code is completed.
Since we already parameterized the EMR and PySpark config in 'template.py' file, now we can store the configuration in Airflow variable, for example:

This parameter can be dynamically changed from MWAA UI, since it is an Airflow Variables. We can scale the EMR instance by changing the instance count or change the instance type by changing the value from this variable.
Summary
We discussed how we integrates EMR and MWAA to achieve efficient management and cost-effectiveness of EMR clusters. We created a template file containing the EMR Cluster configuration and PySpark submit script. We utilize the MWAA EMR Operator to create an EMR cluster, execute the code, and terminate after completing the process. We can create a scalable EMR cluster, we can scale up or scale down EMR resources by just passing a parameter to the template we have. It assists the Data Engineering team in dynamically scaling up, scaling down, and introducing new job groups as needed to support our rapidly growing business.
Reference
Join us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. We recently closed our Series D round and In total have raised around USD$100+ million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.