

Metadata Driven Architecture
At Halodoc, we are always committed to simplifying the healthcare services for our end-users and the primary goal is to continue to evolve as a data-driven organisation. In our previous blog, we focused on building data models for our Enterprise warehouse and explained some of the challenges we faced during the decision-making process. In this blog, we will be covering the Processing Layer Framework which is responsible for building seamless pipelines and onboarding the data assets for the Semantic layer using metadata.
Some of the key considerations we had before building this framework,
Build pipelines at ease and onboard data assets.
- Developers should find it easy to interact with the applications within the ecosystem and build the pipelines.
- Onboarding semantic layer-related data assets should be more flexible giving provision to do auto backfilling.
Control and checkpoints:
- To have better control of the pipelines to handle the failures and triggering rules.
- One place to stop and start or build your pipelines in the Data Platform.
- Auto heal of pipelines ensures less manual intervention.
Democratised:
- The framework should be capable of providing features to modify the necessary configuration.
- Use cases like backfilling of any specific pipeline require clusters of different sizes on an ad-hoc basis.
Maintainability:
- The framework should provide various connectors to perform transform logics like upsert, insert or just append to the DWH, to have consistency in the code base by avoiding different versions of code.
- Provision to extend the current framework without affecting the existing modules.
Monitoring and Alerting:
- Monitor the time taken for ETL, like processing time to measure the performance of pipelines.
- Alerting on upstream or downstream failures and report re-freshness.
Current Tech stack:
As part of our architecture, we use the following components to build the transformation layer
- AWS EMR
- AWS S3
- AWS MWAA - managed Airflow
- AWS Redshift
Architecture - Processing(Transformation) layer:
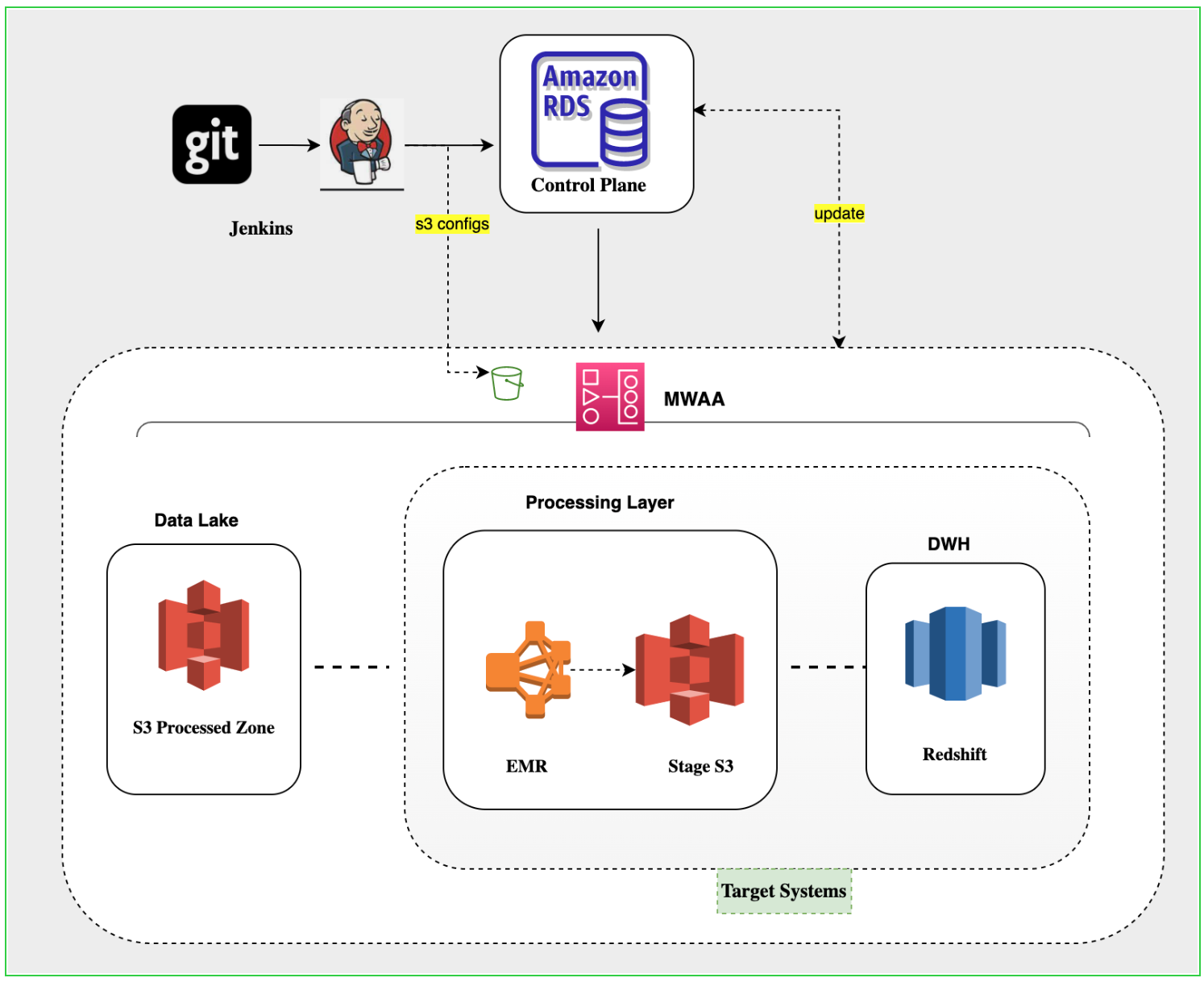
Control Plane:
Our Control plane is the entry point for all our components and is completely controlled by the metadata which is maintained in the form of control tables and following controls are used in our processing layer framework.
Airflow DAG control: Control the entry for dags, which is primarily responsible for pipeline creation and we ensure dag-related information is controlled here and democratised by providing the opportunity for engineers to have the necessary processing layer configuration.
- DAG variables: Schedules, SLA, Environment (prod or stage ), DAG ID, DAG Name.
- Templates: whether it’s from lake to warehouse or presentation layers or MV. We have different DAG templates for performing a certain action.
- EMR cluster config: To include EMR Instance type, master, and slave count.
- Target schema & Table: Used by framework while submission of spark jobs.
- Job groups: Helps in segregating the jobs based on business or SLA and used by framework while submitting the spark jobs.
- Active flag: Yes or No to inform the framework the dag is ready to be deployed.
Transformation control: Controls all the components required to run a transformation and populate the data into the DWH or within DWH. This control is crucial for us because 70 % of the data is in the form of Semantic layers, hence making it BI-friendly is our top priority. From the maintainability standpoint, this is reducing the code base by providing standard wrappers for the SQL logic to get resolved and inserted into DWH. The table holds,
- s3 paths: Provides the framework to pick the transformation logic and target location to store the results.
- Incremental key: Responsible for pulling incremental data based on this column from the source. For example, “updated_at”.
- Business key: Key column to compare the source versus target records and helps during the load types example Upsert operation. Can have multiple keys.
- Load Type: SCD1, SCD2 or Append.
- SCD columns: Columns that required the history to be maintained in the target tables if any.
- Target Schema/Table: schema and Table name.
- Dependencies: List of source tables or driving tables participating in the transformation logic SQL.
- Active flag: Yes or No, To inform the framework to pick this transformation and it gets updated by the framework if there is any failure during the transformation process.
- Comments: Error message or other warning captured here by the framework.
- Column list: List of columns of the target tables, used to build the intermediate staging tables, which is required for our copy command to execute.
Watermark control: Controls the execution of the pipelines, and eventually gets updated through the framework execution. We perform the dependency checks of the source and trigger the pipeline only if there is incremental value present. It helps the data platform to save computational costs by pushing only the qualified candidates to the processing layer. The table holds,
- Watermark time: Pipeline Executed Time.
- Latest water-mark time: The timestamp column provides start and end times for the transformation job and helps in incremental load.
- Schema/Table name: source schema and table information.
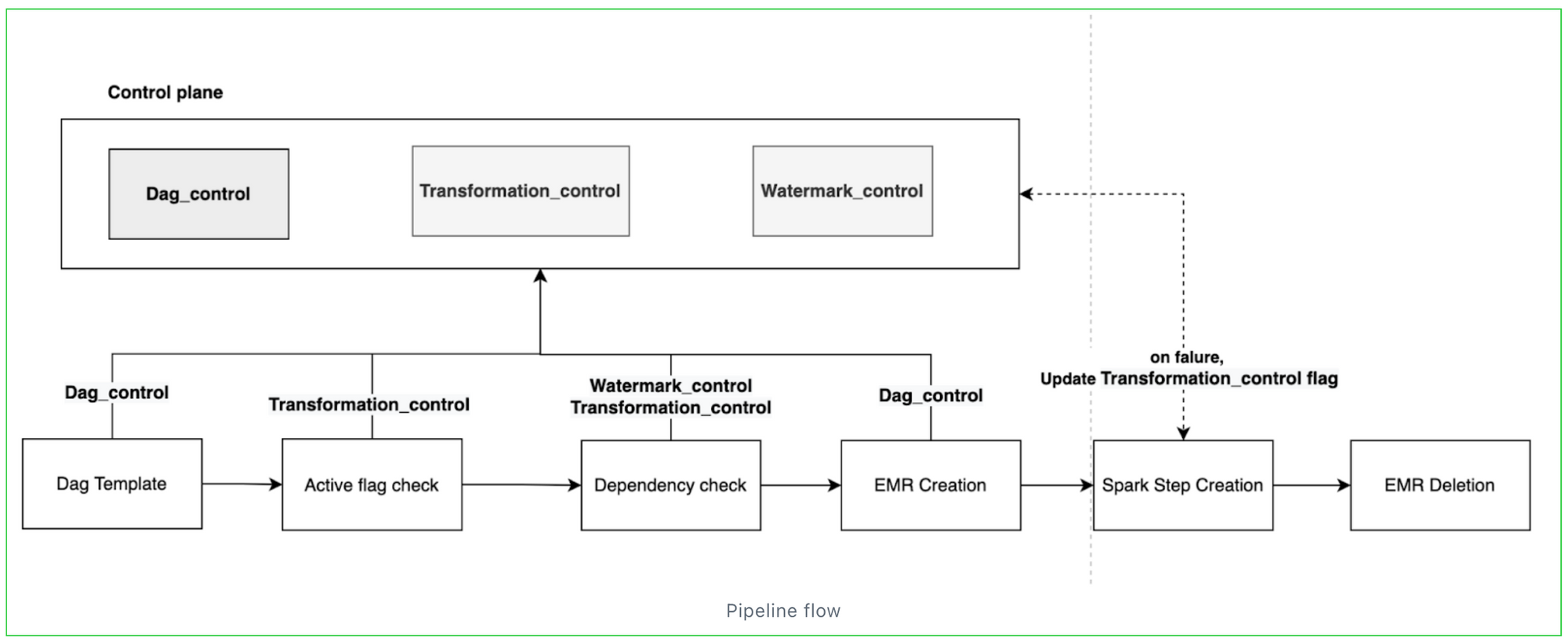
Pipeline flow:
A quick look at our pipeline flow, as you can see in every task the framework utilizes the data present in the control table for creation and execution.
Other Key benefits:
- The Dag control table provides one place to stop and start the dag without getting into the console.
- The transformation control table provides an active flag check ensuring the SQL logic or the incoming data is aligned with the target table. For example, syntactical or column data type mismatch active flag gets flagged and sends the alert to the respective channel.
- The Water-mark table helps in alerting if any of the source or target tables didn’t receive increments within the stipulated time.
- Some of the errors are categorised into the soft bucket, ensuring the active flag check is set to “Yes” to have an auto heal mechanism for our pipelines.
- Collectively these control tables are providing Data Lineage to some extent since we maintain the source, target, and column list.
Summary:
In this blog, we shared how we adopted a metadata-driven framework to build the DWH/reporting layer pipelines and it can be extended to deliver data to any Target system. We keep improving our framework model, aligning with industry best practices and will continue to share our knowledge and learnings in future blogs.
Join us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek and many more. We recently closed our Series C round and In total have raised around USD$180 million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


