Kubernetes Optimization using In-Place Pod Resizing and Zone-Aware Routing
At Halodoc, we operate a large multi-AZ Kubernetes cluster that powers hundreds of microservices that drive our healthcare platform. As our traffic patterns evolved and our infrastructure expanded, two long-standing infrastructure challenges became key opportunities for optimization.
First, pod resources remained static throughout the day
Even when production traffic dropped significantly during non-business hours, our services continued running with the same CPU and memory allocations they required during peak periods. While HPA helped scale replica counts, it could not adjust the resource footprint of individual pods. This led to consistent overprovisioning and unnecessary compute spend, with no practical way to right-size resources without recreating workloads.
Second, cross-AZ traffic was quietly adding cost and latency
By default, Kubernetes routes service-to-service calls without considering cloud network boundaries. As our microservice graph grew, a meaningful portion of internal traffic began flowing across AWS Availability Zones. These inter-AZ hops not only introduced avoidable latency but also contributed to steadily increasing data-transfer costs that started becoming visible at scale.
Importantly, these weren’t misconfigurations or bugs. They were natural outcomes of how Kubernetes handled pod resources and request routing.
Recently, with the stabilization of two key Kubernetes capabilities, we finally gained the mechanisms needed to address these gaps:
- In-Place Pod Resizing
- Zone-Aware Request Routing using Kubernetes attribute
(trafficDistribution: PreferClose)
Together, they unlocked meaningful cost savings and improved the overall efficiency of our internal infrastructure - without adding operational complexity.
This blog walks through the problems we faced, how we leveraged these capabilities and the impact we observed.
The Non-Business Hours Under-Utilization Problem
Every microservice at Halodoc runs with fixed CPU/memory resource configuration. While HPA efficiently adjusts replica count, but the size of each pod stays the same.
This behavior is ideal during peak hours, when traffic is high and workloads require consistent performance. However, during non-business hours, many of the services enter low throughput windows - yet their pods continue running with the same, fully provisioned resources.
The problem?
Pods continued consuming full CPU/memory even when underutilized.
Before in-place pod resize introduction, reducing resources dynamically meant restarting the pods as resources field in pod specification was immutable.
- Several of our workloads - especially JVM-based and script-heavy services need more CPU during startup than during normal operation.
- When these pods restarted with reduced resource, they struggled to initialize.
- This frequently caused startup-probe failures, because the application didn’t come up within the expected time.
- Failed probes led to CrashLoopBackOff or repeated restarts, affecting service stability.
This made automated night-time resource shrinkage unsafe.
Enter In-Place Pod Resizing: Right-Sizing Without Restart
Kubernetes v1.33 introduction of in-place pod resizing (beta graduation), allowed us to update CPU/memory on a running container without recreating the pod.
This was a game-changer as it allows live resizing possible through a new /resize subresource and container-level resizePolicy options that tell Kubernetes whether a restart is required or not.
How In-Place Resize Works
When Kubernetes Receives a Resize Request:
- API server validates the new resources.
- Pod enters
ResizePendingstate. - Kubelet reconciles the new resources at the node level.
- If container specifies
restartPolicy: NotRequired, it performs a live update. - Pod transitions to
ResizeInProgress, then to normal running state.
How we used it
We analyzed traffic patterns for services to determine predictable low-traffic windows (for example, 11 PM to 5 AM).
Then we built a lightweight custom scheduler that:
- runs every N minutes,
- picks deployments labeled for auto-resizing,
- and patches their running pods to use lower CPU/memory.
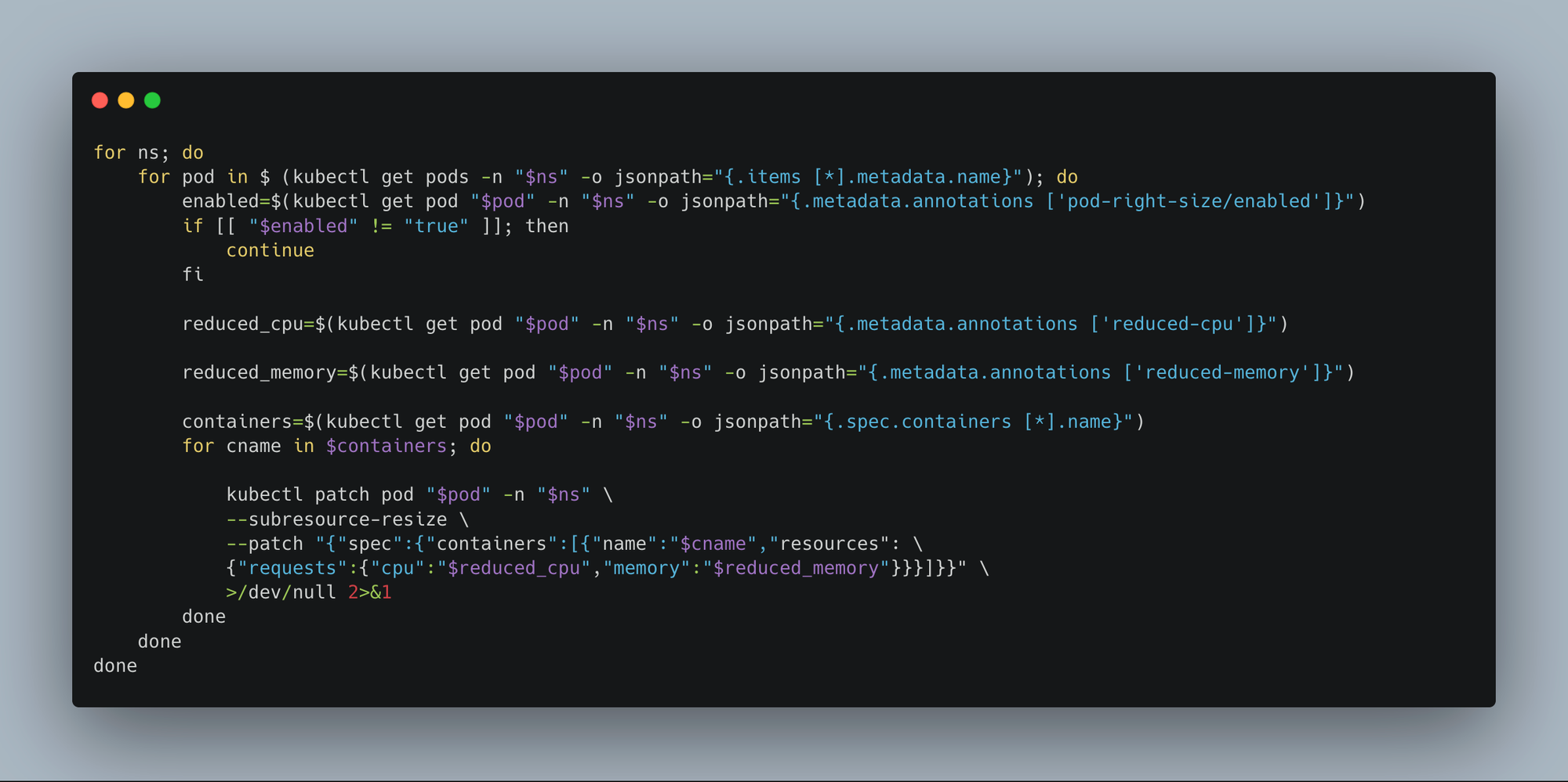
Why periodic patching using the scheduler ?
If a pod gets rescheduled in a different node or a new replica comes up due to HPA, the scheduler picks it up during the next run and right-sizes it automatically.
Why this works well
- No restart or downtime due to in-place pod resize.
- HPA continues to handle sudden traffic spikes via replica count.
- Periodic patching maintains resource uniformity even when new pods appear.
- When business hours begin, pods will automatically fall back to their baseline resource configuration using a rollout restart strategy.
In practice, this reduced pod's resource usage during non-business across number of internal services.
The Cross-AZ Traffic Problem
Our EKS cluster spans across two availability zones.
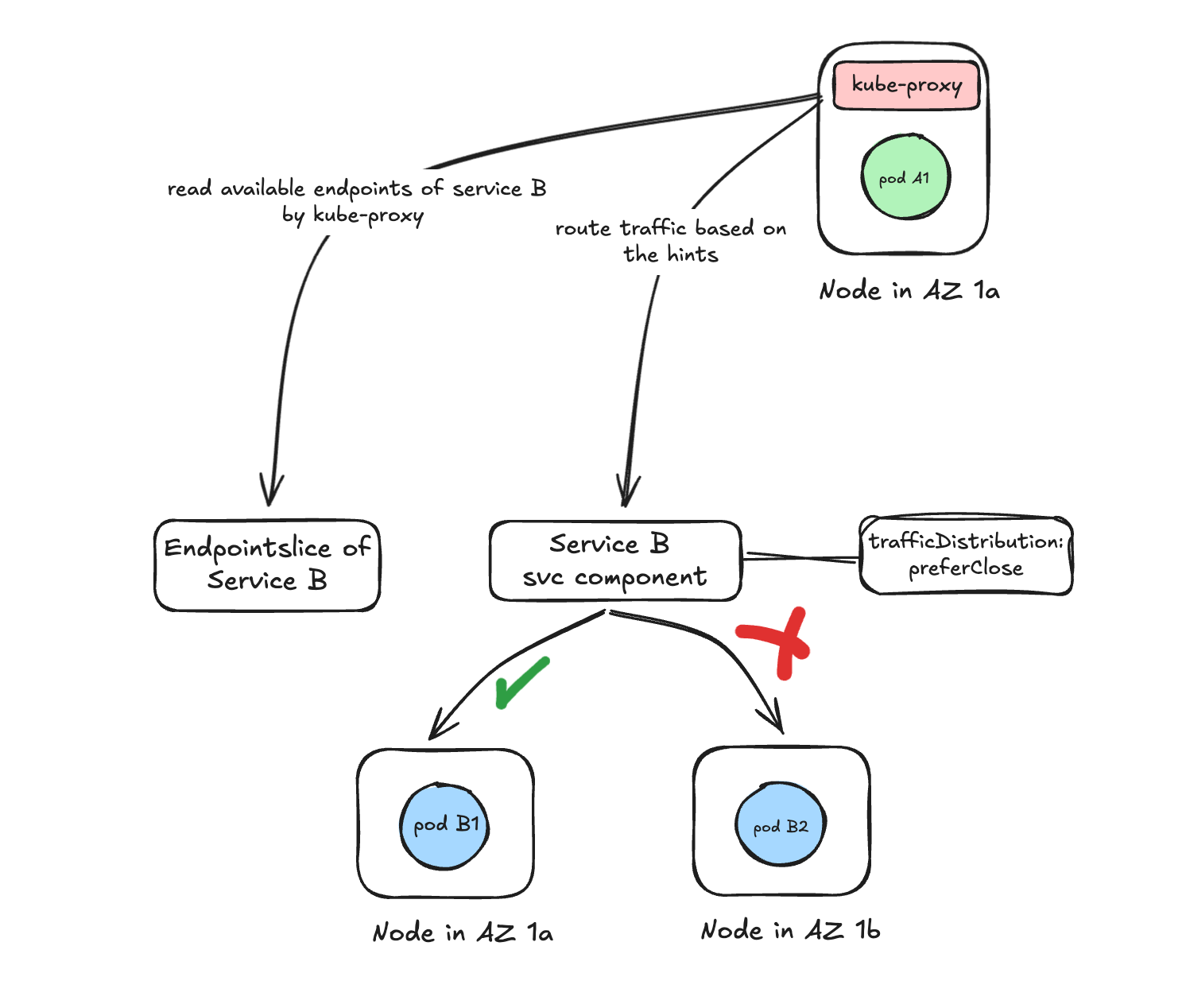
However, Kubernetes routing doesn’t consider AZ locality by default, instead kube-proxy balances requests randomly across all ready pods - regardless of which zone they’re in.
In our measurements:
- large portion of internal traffic between microservices was crossing AZs.
- AWS charges $0.01 per GB in + $0.01 per GB out, effectively costing $0.02 per GB of cross-AZ hop.
- Each hop introduces additional latency because packets traverse longer physical paths.
When millions of such requests happen every day, the resulting cost becomes non-trivial.
Zone-Aware Routing: Traffic Within the Zone
Before enabling zone-aware routing, we first needed to make sure traffic wouldn’t get unintentionally skewed. In a multi-AZ setup, a large share of requests for a service may originate from a single zone. If backend pods are not placed evenly across AZs, same-zone routing can overload the few pods available in that zone.
To reduce the impact of this, we added topology spread constraint rule on zone that ensures pods are distributed evenly across availability zones. With maxSkew: 1, Kubernetes keeps the difference in pod count between zones to at most one, giving both AZs sufficient capacity to handle their local traffic.
trafficDistribution: PreferClose , this single field addition in kubernetes service allows you to express routing preferences and it triggers a set of internal changes that fundamentally shifts how traffic should be routed to pods of a service.
How Kubernetes Routing Works with trafficDistribution :
When trafficDistribution is enabled on a service, kubernetes modifies the routing behavior.
1. EndpointSlice controller adds zone hints
For every backend pod of the service, the endpointSlice controller annotates the endpoint with a hint indicating which availability zone it belongs to.
These hints act as lightweight routing signals for the node handling the request.
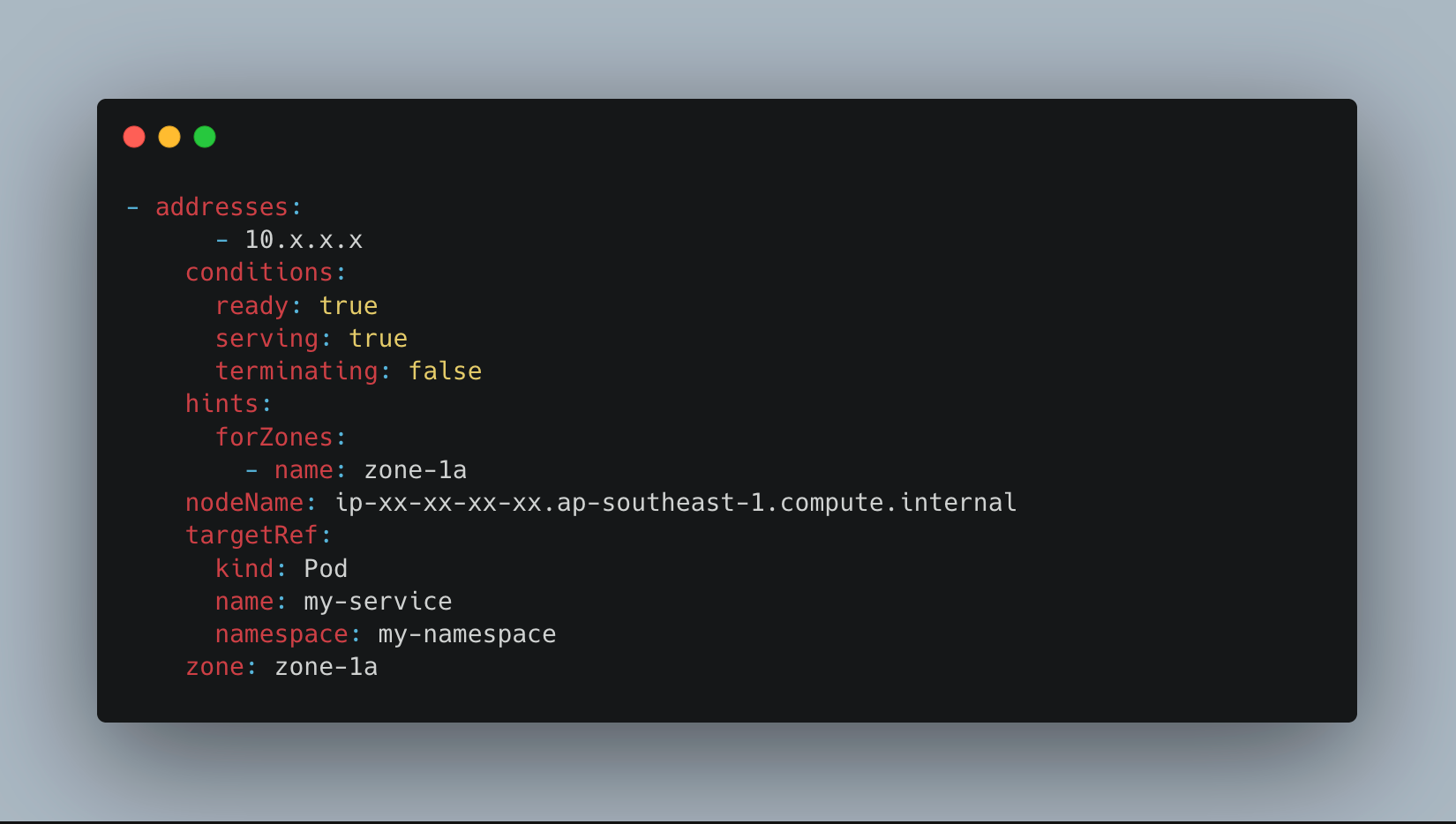
2. kube-proxy uses those hints to prefer same-zone pods
When a client pod makes a request, kube-proxy on that node:
- Looks for endpoints (pods) in the same AZ.
- Routes traffic to pod in the same AZ as client if available.
- Falls back to cross-AZ routing only if no local pod exists.
Impact and Results
Resource Efficiency Gains with In-Place Pod Resizing
By right-sizing pod resources during non-business hours, we observed:
- ~15% average CPU reduction
- ~10% average memory reduction
across many of our internal microservices—resulting in approximately 10% lower EC2 usage during non-business hours compared to baseline business-hour capacity.
Cost & Latency Improvements with Zone-Aware Routing
- Significant reduction in cross-AZ data transfer, lowering AWS network costs. (~25% reduction in cross-AZ data transfer spend)
- Slight improvement in API latency (~5% reduction in average response time), thanks to fewer cross-zone hops.
Conclusion
With just a lightweight scheduler and a few declarative settings, we were able to address two long-standing inefficiencies at scale - all without touching application code or adding new operational burden. These changes now run quietly in the background, helping our multi-AZ Kubernetes environment operate more efficiently every day.
What made this journey impactful was not just the features themselves, but how naturally they fit into our existing platform. In-place pod resizing helped us reclaim compute during low-traffic hours without restarts, while zone-aware routing ensured that service-to-service calls stayed inside the zone, reducing both cost and latency.
References
https://kubernetes.io/blog/2025/05/16/kubernetes-v1-33-in-place-pod-resize-beta/
https://kubernetes.io/docs/reference/networking/virtual-ips/#traffic-distribution
Join us
Scalability, reliability, and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels, and if solving hard problems with challenging requirements is your forte, please reach out to us with your resume at careers.india@halodoc.com.
About Halodoc
Halodoc is the number one all-around healthcare application in Indonesia. Our mission is to simplify and deliver quality healthcare across Indonesia, from Sabang to Merauke.
Since 2016, Halodoc has been improving health literacy in Indonesia by providing user-friendly healthcare communication, education, and information (KIE). In parallel, our ecosystem has expanded to offer a range of services that facilitate convenient access to healthcare, starting with Homecare by Halodoc as a preventive care feature that allows users to conduct health tests privately and securely from the comfort of their homes; My Insurance, which allows users to access the benefits of cashless outpatient services in a more seamless way; Chat with Doctor, which allows users to consult with over 20,000 licensed physicians via chat, video or voice call; and Health Store features that allow users to purchase medicines, supplements and various health products from our network of over 4,900 trusted partner pharmacies. To deliver holistic health solutions in a fully digital way, Halodoc offers Digital Clinic services including Haloskin, a trusted dermatology care platform guided by experienced dermatologists.
We are proud to be trusted by global and regional investors, including the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. With over USD 100 million raised to date, including our recent Series D, our team is committed to building the best personalized healthcare solutions — and we remain steadfast in our journey to simplify healthcare for all Indonesians.