

Enhancing Uptime and Performance with Node.js Clustering using PM2
Managing uptime and handling traffic efficiently is crucial for any public-facing website. Here at Halodoc, our Node.js servers are containerized within Kubernetes pods that scale automatically based on traffic demands. However, even with Kubernetes scaling, we encountered challenges related to downtime during pod restarts caused by runtime errors. To address this, we leveraged PM2 to implement Node.js clustering within each pod. This approach helped us reduce downtime, improve response times, and further optimize traffic handling per pod. In this blog, I’ll share how clustering enhanced the resilience and efficiency of our pods.
NOTE: In this blog, the terms process and instance will be used interchangeably. Both refer to the application server running within the pod.
The Challenge: Handling Traffic on a Single-Core Node.js Server
Since a Node.js instance runs on a single thread, it can not take advantage of multi-core systems properly. It has to process all the incoming requests on a single thread. This setup presented some challenges:
- High Traffic Delays: During peak periods, response times could slow down as requests piled up in the queue, waiting to be processed.
- Single Point of Failure in a Pod: If the process within a pod crashes, the entire pod goes down. This can lead to service disruptions if the remaining pods are unable to handle the sudden increase in traffic load.
- Challenges with Horizontal Scaling: High traffic or DDoS attacks often triggered frequent pod restarts, affecting overall uptime and stability as with Kubernetes usually it takes around 2 minutes to restart the pod.
What is Node.js Clustering?
Node.js clustering allows us to spawn multiple instances of an application, each running on a different CPU core, while sharing a single port. This enables traffic to be distributed across instances, enhancing our server’s ability to handle requests more effectively.
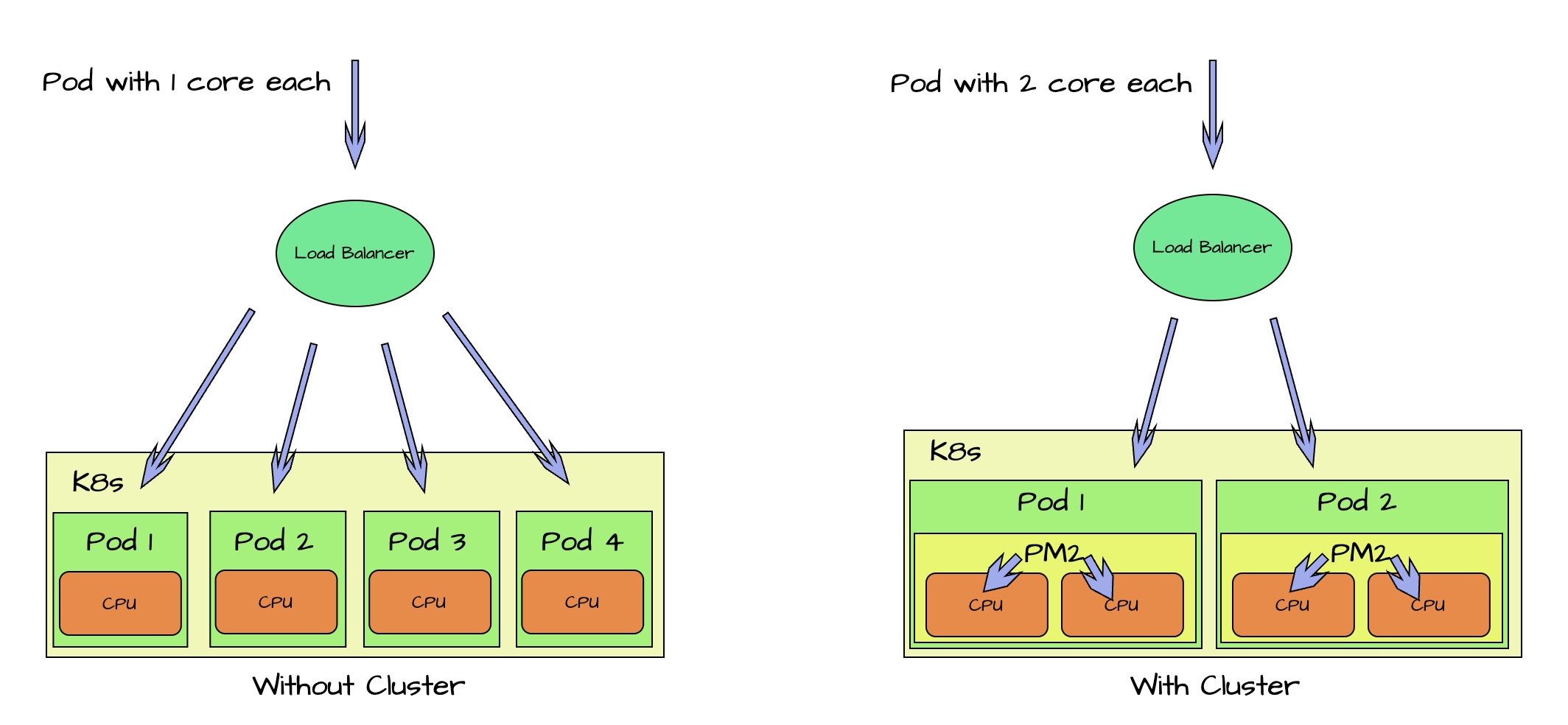
Why Clustering?
In the past few months, we observed multiple restarts of the node server due to some run time errors, happening on a particular page. These restarts often led to increase in the response time and some downtime as it took about 2 minutes to spin up a new pod.
Node.js clustering allows the application to run on multiple CPU cores. So by clustering, the idea was to:
- Reduce downtime by enabling zero downtime instance restart for the process that crashes within the pod.
- Improve response time by efficiently utilizing multi-core CPUs.
- Increase traffic capacity per pod, reducing pod restarts probability and improving fault tolerance.
So with clustering, now each pod will have multiple instances running within it. So if any of the instance crashes, it will auto restart within a second. So overall it will increase the availability of pod.
Why PM2 for Clustering?
When we go for clustered servers in production, there are many features that are asked for like process monitoring, automatic restarts, load balancing etc. Considering all those, we evaluated multiple open source libraries including the built-in Node.js cluster module. Among those PM2 seemed most promising as a comprehensive and well-maintained process manager with extensive features for clustering, making it a preferred choice for managing Node.js applications in both development and production environments.
PM2 is a powerful and easy-to-use process manager for Node.js. It doesn't require any change in the source code, which actually simplifies the process of setting up clustering.
Key benefits:
- Automatic Load Balancing: PM2 distributes traffic evenly among workers.
- Process Management: Easy to start, stop, and restart processes.
- Monitoring: Track CPU and memory usage of each process.
- Zero Downtime Instance Restarts: PM2 handles rolling restarts with no downtime.
PM2 Integration
To integrate PM2, it only requires a configuration set up. It doesn't require any code level change.
PM2 configuration to manage clustering:
module.exports = {
apps: [
{
name: 'halodoc',
script: 'main.js',
instances: 0,
exec_mode: 'cluster',
watch: false,
env: {
NODE_ENV: 'prod',
},
appendEnvToName: true,
autorestart: true,
min_uptime: '1m',
listen_timeout: 5000,
max_restarts: 3,
restart_delay: 0
}
],
};
Here script is the script path to start the server and instances refers to the number of application instance that we want to run per pod. If it's set to 0, the PM2 will launch the maximum processes possible according to the numbers of CPUs (cluster mode).
For more details about the configuration, please refer to this PM2 documentation
Deployment Changes:
To start the application in cluster mode using PM2, either it can added as a dependency to the project or it can be installed globally in the machine.
npm install -g pm2
To start the server use this
pm2 start ecosystem.config.jswhere ecosystem.config.js is the PM2 config file.
If you are using docker, you can use
pm2-runtime start ecosystem.config.jsFor more details about docker integration, please refer to this PM2 documentation
Performance Analysis: Clustering vs Non-clustering
This analysis compares the performance of clustered and non-clustered setups based on critical parameters, with testing performed using Artillery, a tool for load testing and performance benchmarking.
Parameters Assessed:
- Fault Tolerance: Evaluates how well the server can recover from failures or crashes without downtime.
- Handling Sudden Request Load: Measures the server's ability to adapt to unexpected traffic spikes.
- Error Rate: Tracks the frequency of errors occurring during the test.
- Response Time: Assesses the average response time under varying loads.
- Auto-Scaling and Restarts: Determines the system’s capability to scale up or restart processes automatically to maintain stability.
Tool used:
Artillery: Used to simulate user traffic and analyze system performance under load.
Test Configuration:
To compare the cluster and non-cluster setups, we tested with 3 instances per pod, and equivalent resources were allocated in both the scenarios.

The test was conducted over a duration of 3 minutes, with traffic gradually increasing throughout the test to emulate a real-world traffic scenario effectively.
config:
target: 'https://www.halodoc.com'
phases:
- duration: 30
arrivalRate: 50
- duration: 60
arrivalRate: 75
- duration: 90
arrivalRate: 100
scenarios:
- flow:
- get:
url: '/'where duration is duration of the test in seconds & arrivalRate is the number of users to spawn per second. So the overall test duration was 3 minutes.
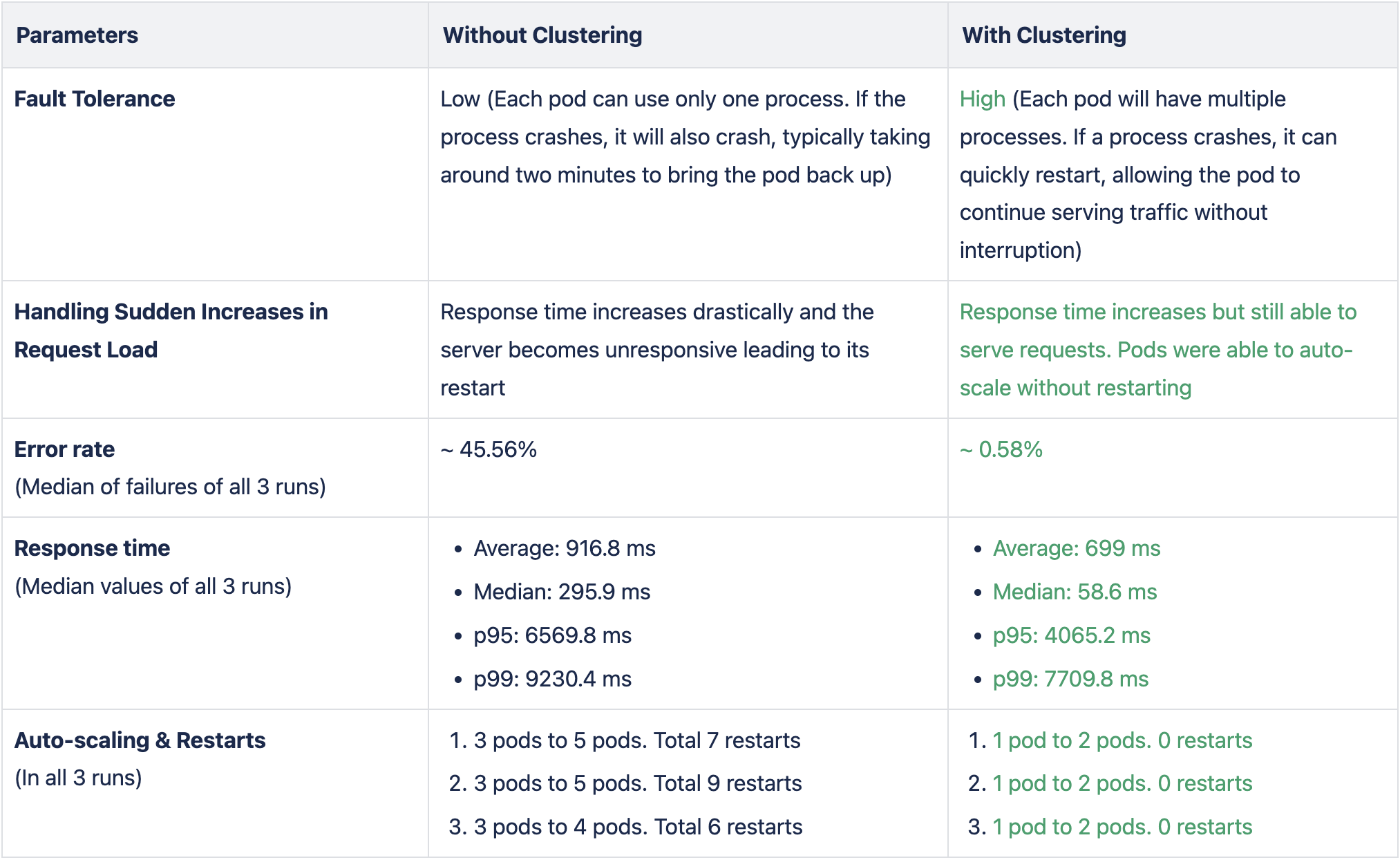
Observations
Best Practices for Clustering using PM2
PM2 provides a variety of features that can significantly enhance the stability of our servers. To fully leverage its capabilities, it’s crucial to configure it appropriately. Below are some key considerations when using PM2:
- Utilize All Available CPU Cores: For optimal performance, the number of instances should not exceed the number of CPU cores available on the machine.
- Leverage Auto-Restarts: Enable
autorestart: trueto ensure workers automatically restart if they crash or consume excessive resources. - Memory Management: Configure
max_memory_restartto prevent memory leaks from causing system crashes. - Centralized Monitoring: Since each pod may run multiple instances, it is essential to monitor the health of these individual instances. Use PM2’s built-in monitoring tools or integrate with external tools like Datadog or New Relic.
- Environment-Specific Configurations: Set up environment-specific configurations. Use PM2’s environment variables to define distinct settings for development, staging, and production environments.
Conclusion
Implementing clustering using PM2 for our Node.js application has led to a much more robust, fault-tolerant, and scalable system. It allowed us to handle high loads with lower error rates, reduced restart times for run time application failures, and improved performance. With three instances per pod, our pods were able to handle around 3x traffic and the response time improved by around 20%. Clustering has proven to be an invaluable tool in scaling up our web server for better performance and reliability.
References


Join Us
Scalability, reliability, and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resume at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. We recently closed our Series D round and In total have raised around USD$100+ million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


