

What is event-driven architecture? How Halodoc is building event-centric systems using Kafka
Introduction to event-driven architecture
What is an event? An event is the trigger or the cause that starts an activity or a set of activities. An event is a change of state of some key business system. For instance, somebody buys a product, someone else checks in for a flight, or a bus is arriving late somewhere.
The real world around us is the quintessential example of an event-driven system. We wake up when the day breaks. We change our driving routes when there is congestion ahead. We eat when we are hungry. Similarly, in business workflows, events drive the actions and hence event-driven architecture is a natural choice.
With the advent of Big-Data over the past few years, there’s been a movement from focusing on data at rest, to focusing on events (event-driven architecture).
The shift to event-driven architecture means moving from a data-centric model (focusing on collection and storage of data around which to build applications) to an event-centric model (focusing on processing data-in-flight and responding to events) which also enables fault-tolerant asynchronous communication between sub-systems (various micro-services) using events instead of commands (REST, RPC etc).
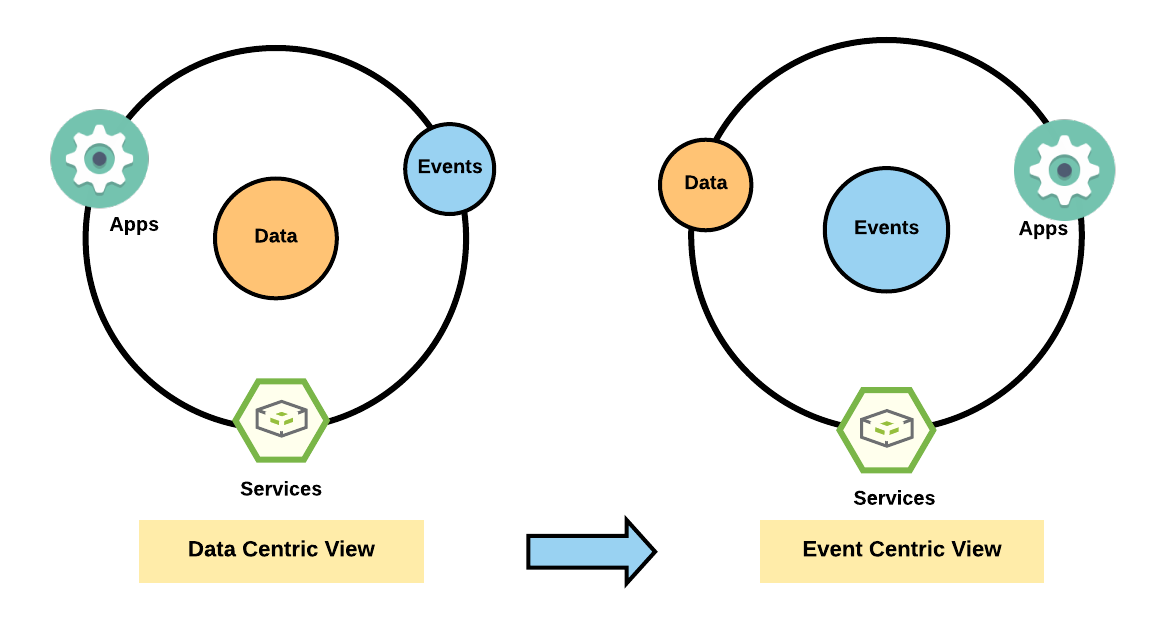
So, how does Halodoc utilise event-driven systems?
Event-driven architecture at Halodoc - Where and Why?
Backend systems at Halodoc have been architected on the micro-services model. And communication between these micro-services in a scalable and fault-tolerant way is extremely essential. This is achieved through systems that need to be highly available (99.99% SLA), highly scalable (serve more than 1 million events per day), performant, secure and fault-tolerant.
The where
Halodoc applications have multiple use cases that can be driven by events (changes in state machine). Some examples of events at Halodoc can be :
Server Events | Client Events |
|---|---|
Pharmacy order state change (created/confirmed/delivered/cancelled) | User logged out |
Insurance Policy change (linked/unlinked) | User added items to cart |
Consultation changes (created/confirmed/started/completed/closed) |
The why
Halodoc designs and implements event-driven systems in order to :
- Enable micro-services to share data without dependencies on downstream/upstream systems
- Enable time-series like event stream to analyse lifecycle/actions taken
- Long term archiving of system events - logs, metrics, changes, etc.
- Internal asynchronous communication
But, how to accomplish all these goals?
How is Halodoc building and evolving its eventing platform?
With a prolific and robust micro-services architecture involving multiple state machines and usecases, we wanted to build an inter-services communication platform that was highly available and fault-tolerant.
Since we had that goal in mind, Halodoc’s journey towards an eventing platform started with AWS SNS as the underlying messaging channel that supported publish-subscribe model.
Why did we choose AWS SNS?
- To enable a publish-subscribe model for processing state changes (events) with the ability to add/remove subscribers at runtime
- To enable easy behavioral analytics using Mixpanel or other tools
- Using SNS was economical, easy to integrate with and offered high availability and scalability as in-built features
How does it work?
We created an extendable SDK that supported multiple pluggable channels (SNS, Kafka etc.) to generate events. Each application/service generates events to an SNS topic which in turn triggers a lambda function to process the event. The lambdas could interact with other managed, internal or external services.
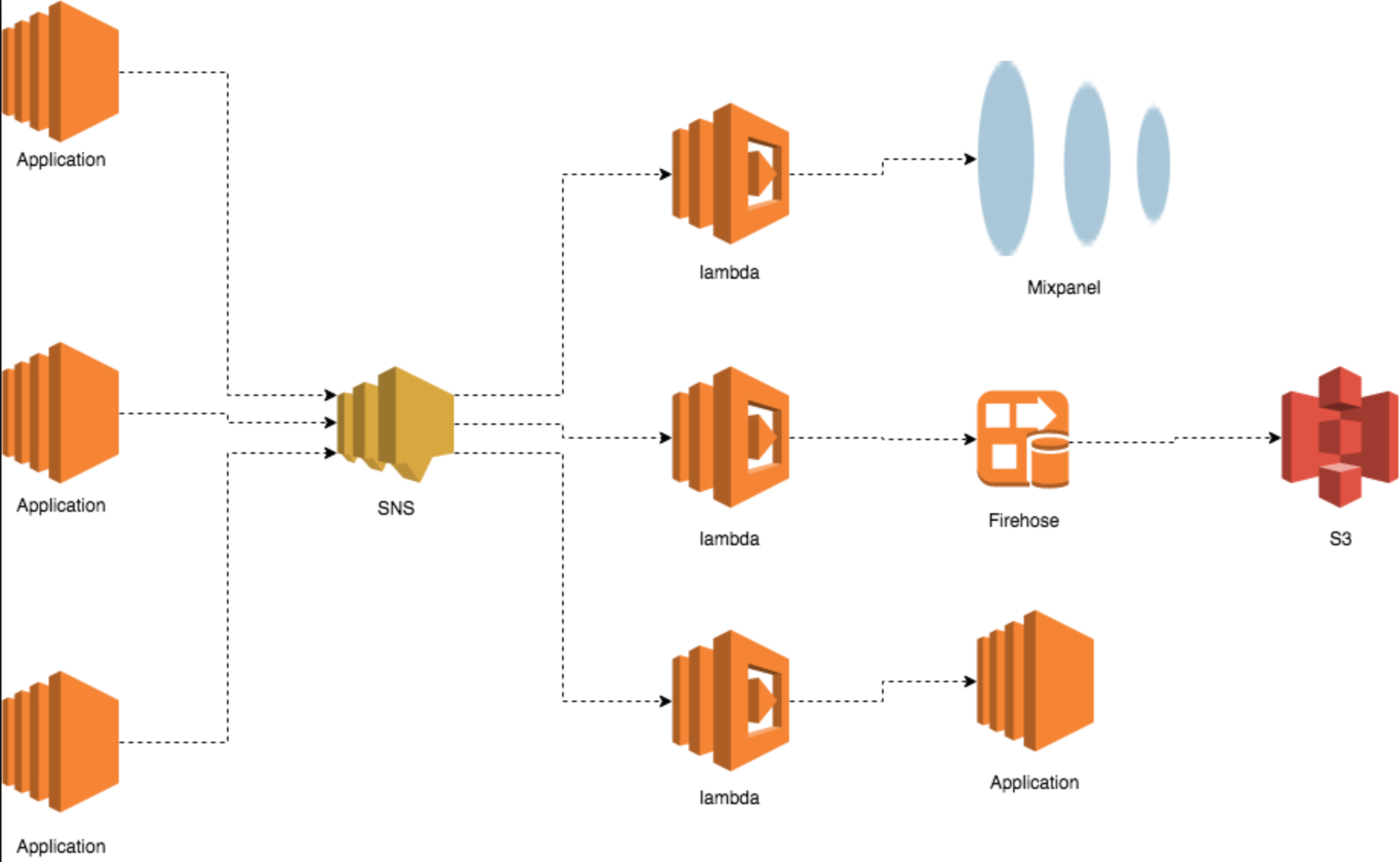
But, this design came with its own challenges.
Evolving problems and loopholes
As we scaled up, the loopholes in the platform started to show and we decided to evolve too!
- Message ordering : SNS doesn’t guarantee ordering of messages. With growing use-cases and chained events, this becomes crucial
- Message delivery guarantee : SNS messages could get lost with network or other issues
- Maintainability : The need to create manual configurations across various AWS services (SNS, DynamoDB, Lambda) to store producer and consumer configurations and destinations creates a maintenance problem
- Contract between producer and consumer : The existing eventing framework makes the contract between producer and consumer very generic with a single event object to cater multiple services
Because of these crucial requirements, we decided to move away from SNS based systems.
What is Kafka and why use it?
Apache Kafka, essentially, is an event streaming platform and more. Technically speaking, event streaming is the practice of capturing data in real-time from event sources like databases, connected devices (IoT) and software applications in the form of streams of events; storing these event streams durably for later retrieval; manipulating and processing.
Kafka can be used not only for event-streaming but also as a :
- Messaging System: a highly scalable, fault-tolerant and distributed Publish/Subscribe messaging system.
- Storage System: a fault-tolerant, durable and replicated storage system.
Kafka combines three key capabilities to design and implement various usecases for event-driven systems with a single battle-tested solution:
- To publish (write) and subscribe to (read) streams of events
- To store streams of events durably and reliably for as long as you want
- To process streams of events as they occur or retrospectively
Kafka does all this in a distributed, highly scalable, fault-tolerant, and secure manner. And therefore, as a messaging system, Kafka became an obvious choice for us to build our event-driven platform to communicate between various sub-systems.
Way ahead
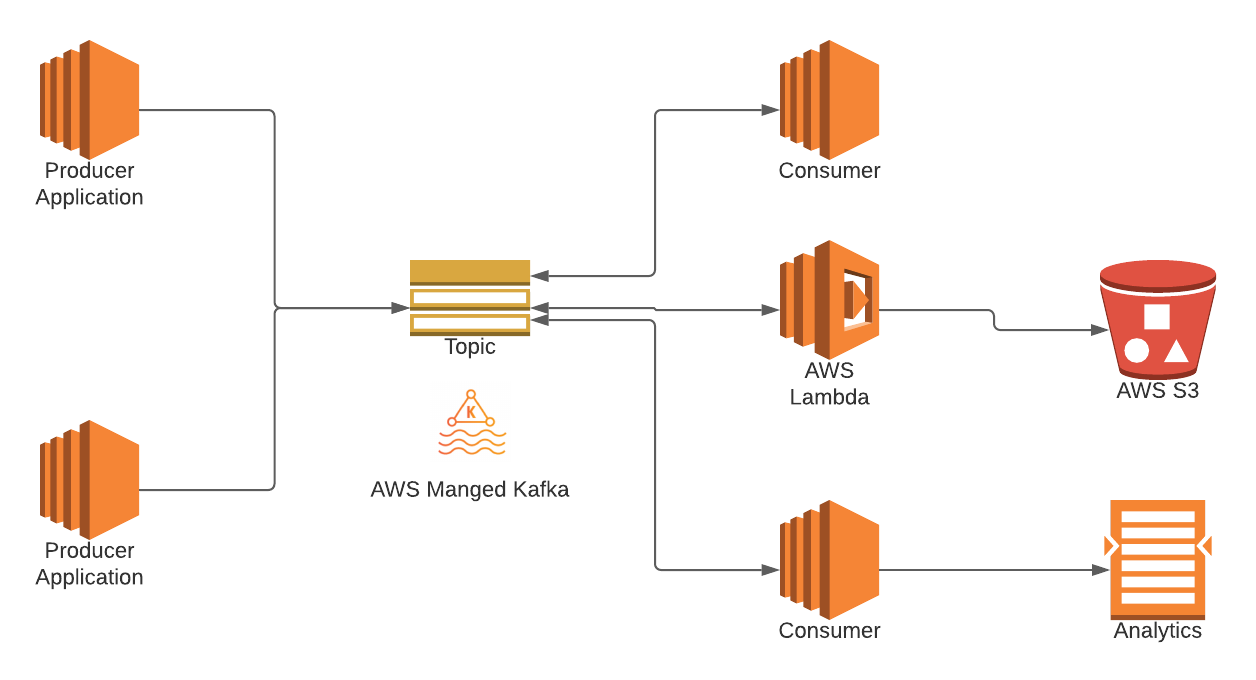
As we grow as a company and as our systems evolve, we are moving to an eventing platform that is more choreographed than orchestrated. And Kafka offered us just that :
Support for messaging requirements :
- Message ordering with partitions
- Queuing & Pub-sub use cases
- Various message delivery guarantees (at most once, at least once and exactly once)
- Highly Scalable & Available : AWS MSK (Managed Service for Kafka) provides this as an inbuilt feature
- Message structuring & versioning using Protobuf & Schema registry instead of generic messages
Additionally, Kafka is open-sourced & hence cloud agnostic and it also simplified our configuration - Kafka topic creation, Producer & Consumer configurations in a decoupled configuration service (updated at runtime).
Conclusion
Clearly, the new platform based on Kafka is the solution that fits Halodoc’s ultimate goal of simplifying healthcare and therefore, we are continuously evolving our architecture. As the problems in health sector and the needs of our customers evolve, our journey to build perfect solutions that scale continues.
Join Us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for backend engineers/architects and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke.
We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 1500+ pharmacies in 50 cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allows patients to book a doctor appointment inside our application.
We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates foundation, Singtel, UOB Ventures, Allianz, Gojek and many more. We recently closed our Series B round and In total have raised USD$100million for our mission.
Our team work tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


