Beyond Optimisation: Dynamic Right-Sizing for Apache Spark Jobs
Optimizing Apache Spark workloads has always been a challenge. In our previous blog on Apache Spark Performance Optimization, we focused on collecting and analyzing execution metrics to identify inefficiencies. However, this process required manual intervention to adjust configurations after performance issues were detected. Spark jobs typically run with the same configurations, regardless of data volume or time of week, leading to inefficient resource utilization, over-provisioning during low demand, causing unnecessary costs, and under-provisioning during peak times, resulting in performance bottlenecks.
In this blog, we'll walk you through the journey we took at Halodoc to implement predictive right-sizing, a novel approach that addresses these issues by proactively anticipating resource needs. Imagine the resources automatically reducing during weekends when workloads are lighter, or scaling up during peak demand times, all without manual intervention. By continuously analyzing Spark metrics in real time, it forecasts workload demands and dynamically provisions EMR on EKS pods just before execution. This data-driven approach ensures jobs run efficiently, optimizing both performance and costs. It moves away from reactive tuning, providing an intelligent, automated solution that ensures optimal resource allocation at all times.
Early Explorations Using ML for Right-Sizing
We explored machine learning methods to assess their viability for right-sizing Apache Spark workloads. We hypothesized that ML models could adaptively learn workload patterns and adjust resources automatically, reducing manual tuning, handling workload variability, and improving cost efficiency. To test this, we implemented two ML-based strategies: reinforcement learning with Q-learning and time-series forecasting using the ARIMA model.
Q-Learning for Resource Allocation
- Experiment Setup: We treated resource allocation as an RL problem, where a Q-learning agent explored different Spark configurations (executor count, memory, cores) and received rewards based on cost efficiency and job performance.
- Findings: The agent gradually identified better configurations, but learning was slow, requiring 100 iterations, 1000 episodes, and significant historical data. Workload variability also led to unstable policies, making it difficult to generalize across Spark jobs.
- Challenges: The approach lacked interpretability, making debugging and fine-tuning difficult. Additionally, the slow convergence of Q-learning made it impractical for rapidly changing workloads.
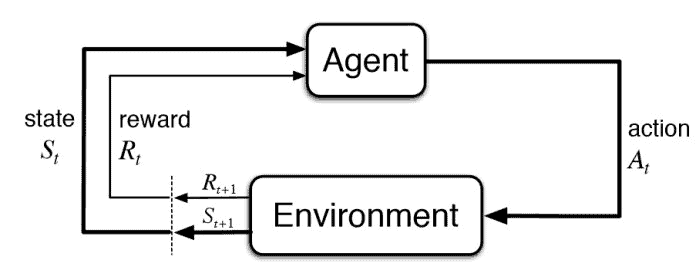
ARIMA Model for Time-Series Prediction
- Experiment Setup: We trained ARIMA models on historical Apache Spark job execution metrics to predict resource needs before execution.
- Findings: ARIMA worked well for stable workloads but struggled with non-linear patterns and sudden workload changes.
- Challenges: Frequent manual tuning was needed, and the model was more reactive than adaptive, making it less effective for dynamic cloud environments. It also required continuous retraining to remain relevant, increasing operational overhead.
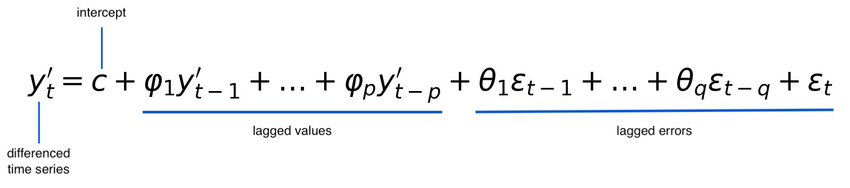
Why Machine Learning Wasn't Ideal for Our Right-Sizing Strategy
- Given the dynamic nature of data workloads and concept drift, AI models must constantly adapt to changing conditions.
- Many AI models require substantial computational power, reducing efficiency, and their complexity makes it hard for administrators to trust allocation decisions.
- Additionally, optimizing multiple objectives like performance, cost, and energy efficiency remains an ongoing challenge.
After evaluating ML-based approaches, we found that their complexity, high maintenance costs, and inconsistent prediction accuracy outweighed the benefits. This led us to choose heuristics and statistical methods, which provided more reliable predictions with lower operational overhead.
Efficient Right-Sizing with Heuristics and Statistics
Our right-sizing logic is built on Apache Spark's historical performance data and real-time execution metrics, ensuring precise resource allocation while maintaining stability. It follows a simple yet effective approach:
- Analyzing JVM utilization and Garbage Collection (GC) behaviour provides a stable representation of resource consumption, which directly influences Apache Spark executor efficiency. Unlike other metrics like CPU usage, task counts, and memory consumption, which fluctuate due to cluster contention and varying parallelism, JVM and GC metrics remain more consistent and reliable. These observations were confirmed through Exploratory Data Analysis (EDA) on Apache Spark metrics, which revealed a strong correlation between resource consumption and execution time, particularly with peak JVM utilization and GC time.
- Incorporating input size as factor for Right Sizing ensures that right-sizing remains stable even under sudden workload changes by accounting for variations in input size. A dampened factor of input size was used with the Peak JVM to handle such situations.
To calculate the adjusted ratio, we combine two key factors: the utilization ratio and the file size impact. The utilization ratio helps us understand trends in resource usage over time, while the file size ratio ensures adaptability to sudden changes in data volume, allowing for responsive scaling.

We compute the memory utilization ratio by dividing the peak JVM memory usage by the maximum allocated memory, based on historical data from the last N Spark runs. This ratio is multiplied by Weight 1 (W1) to control its influence on the overall adjustment.For file size impact, we normalize the logarithm of the current input data size against the historical minimum and maximum sizes over a 14-day period. This normalized ratio is clamped between 0 and 1 and then factored by Weight 2 (W2) to control its effect on the adjustment.
The final adjusted ratio, combining both weighted values, is used to decide whether to scale down resources or leave the configuration unchanged. The weights allow us to balance memory usage and file size impact based on workload characteristics.
Finally, we add both these weighted values together to get the adjusted ratio. This adjusted ratio is what we’ll use to decide whether to scale down resources (if the ratio is below a certain threshold) or leave the current configuration unchanged. This process lets us fine-tune how we allocate resources, taking into account both how much memory is being used and how the input data size might have changed. The weights give us the flexibility to adjust the balance between these two factors based on the nature of the workload.
Architecture and Flow to Automate Dynamic Right-Sizing
Our architecture integrates Apache Airflow, AWS EMR on EKS, and statistical analysis to automate predictive right-sizing.
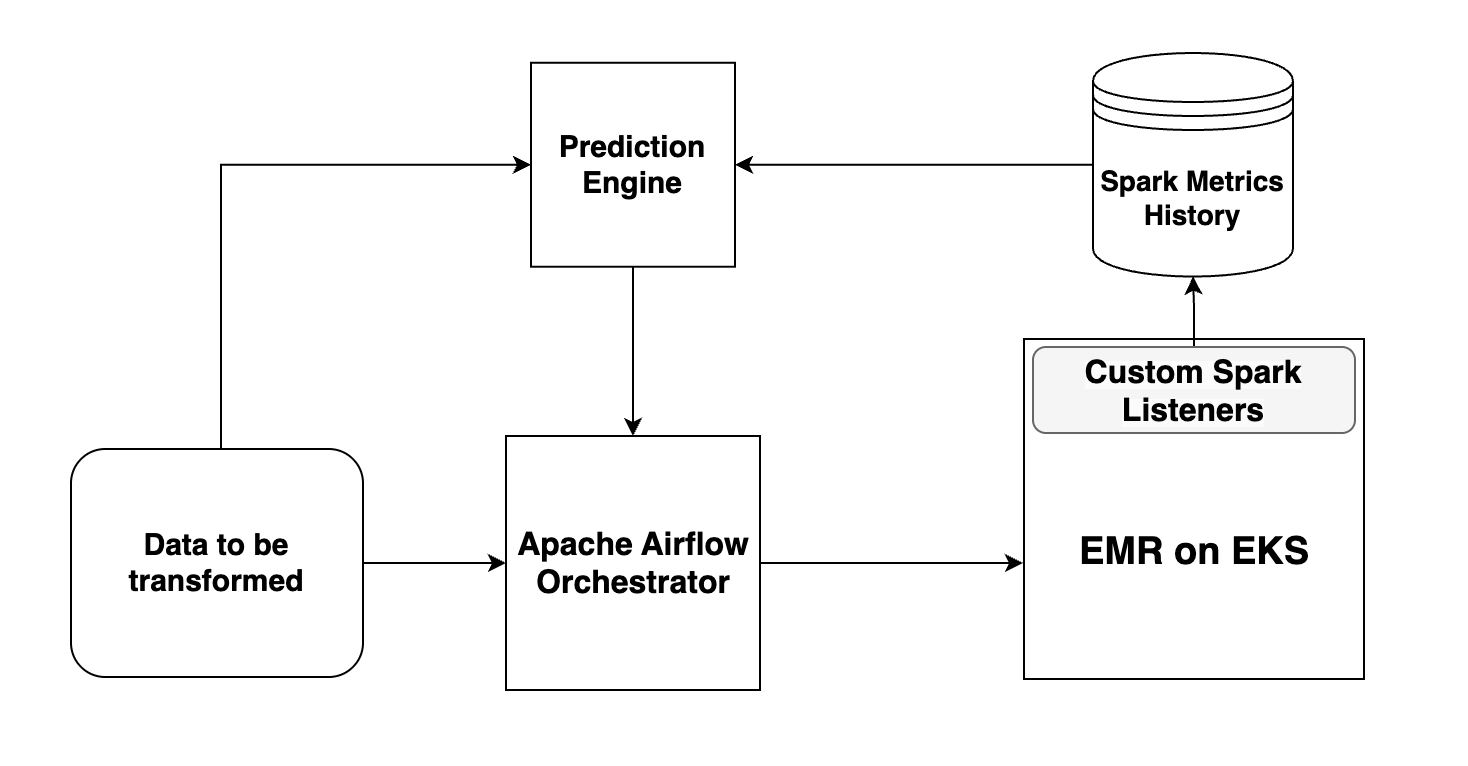
The process from Prediction to Execution
Step 1: Collecting Apache Spark Metrics
Custom Spark Listeners capture real-time execution data, including CPU and memory usage, task execution times, and shuffle operations. This data is stored in a database and serves as input for the prediction engine.
Step 2: Prediction Engine Estimates Resource Needs in Airflow
Before starting the job, Apache Airflow runs the embedded prediction engine, analyzing historical job executions to determine the optimal number of executors, memory, and CPU required. The engine leverages historical data trends and workload analysis to improve accuracy over time.
Step 3: Airflow Triggers EMR on EKS Pod Creation
Once the predictions are generated, Apache Airflow automates the deployment by fetching job execution metadata, retrieving the predicted configuration, and triggering an EMR on EKS job with the recommended settings. The recommended settings apply only to the current run; new configurations will be fetched for the next run. Airflow monitors execution in real-time and updates historical metrics for continuous learning.
Step 4: Adaptive Learning and Continuous Optimization
As jobs execute, new performance metrics are captured, allowing the prediction engine to refine future predictions. Over time, the system improves accuracy, achieving a balance between cost efficiency and optimal performance.
Challenges and Considerations
While predictive right-sizing offers substantial benefits, there are challenges to address:
- Cold Start Problem: We solved this by keeping look-back runs, and right-sizing is only triggered once enough historical data is available.
- Data Drift: We mitigate this by incorporating both input size variations and historical trends, ensuring that sudden changes in workload patterns do not negatively impact predictions.
- Complex Transformation Logic: If a job has a very complex transformation logic, right-sizing can be disabled for that specific job to ensure stability.
- Upscaling Challenges: Predicting resource needs for upscaling is complex and risky. To avoid instability, we focus more on downscaling and over-provisioning resources by default for stable performance.
Continuous refinement, hybrid rule-based scaling for new workloads, and pre-warmed EMR pods help mitigate these challenges, ensuring reliable performance.
Real-World Benefits of Predictive Right-Sizing
By implementing predictive right-sizing, organizations can achieve:
- Cost Reduction: Resource wastage is minimized, leading to significant cost savings. In our production environment, we saw a 40% reduction in EC2 costs and a 35% reduction in EMR costs.
- Improved Performance: Jobs are allocated just the right amount of resources, ensuring they run efficiently without overloading the system or causing delays.
- Minimal Manual Intervention: With dynamic resource allocation, system administrators spend less time tuning configurations and more time focusing on business-critical tasks.
The Future of Apache Spark Performance Optimization
Predictive right-sizing is an exciting step forward in the optimization of Apache Spark workloads. By leveraging historical metrics and statistical analysis, we can now predict resource needs before they arise, ensuring that Spark clusters are always operating at peak efficiency. As this approach continues to mature, we expect to see even more advanced techniques, such as integrating additional Spark metrics to get better Spark configs, further improving overall performance. In the end, predictive right-sizing enables Spark jobs to run smarter, faster, and more cost-effectively, reducing manual intervention while optimizing performance.
References
- https://netflixtechblog.com/evolving-from-rule-based-classifier-machine-learning-powered-auto-remediation-in-netflix-data-039d5efd115b
- https://www.researchgate.net/publication/383935397_Efficient_resource_allocation_in_cloud_computing_environments_using_AI-driven_predictive_analytics
Join us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number one all-around healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off, we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. We recently closed our Series D round and in total have raised around USD 100+ million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.