

Automating MR Reviews: How Halodoc Reduced SQL Review Time Using AI
Merge Request Reviews are an integral component of engineering workflows. They support code quality, maintain consistency and help prevent errors from being introduced into production systems. However as our team strength and number of release cycle increase, manual MR reviews take up significant portion of our time.
Each review requires verifying correctness, assessing performance, and ensuring adherence to standards. When repeated multiple times per week, this can consume several hours of engineering time, representing a substantial time commitment. Frequent context switching between development and review tasks can also reduce focus on complex work for reviewer. From a developer’s perspective there’s often a lot of back-and-forth involved in getting the MR corrected.
Within our organisation, we observed this challenge while working with the Data Analysis and Business Intelligence teams. Valuable dashboards and reports were being produced, but without an automated SQL validation process, syntax errors, missing columns or inefficient queries were often caught only during manual reviews.
To address this, We at Halodoc's Data Platform Team piloted an automated MR review framework, starting with the SQL's. This allowed us to test and refine the approach in a controlled environment. After a successful implementation, we plan to extend this framework to other teams, improving review efficiency and freeing up engineering time for development work.
Background
At Halodoc, Data Engineers review all reporting SQL queries written by Data and Business Analysts. While checklists, linters and AI code editors are available, they cannot fully verify syntax or detect missing columns, making manual review necessary before deployment. Additionally, SQL optimisation is more effective when analysing both the SQL and its explain plan, rather than the SQL alone.
To solve this, we started building a system that reviewers can fully trust to merge requests safely. In a sense, it’s similar to Test-Driven Development (TDD), but here the “tests” can also run outside the system to validate the SQL’s impact on data pipelines, ensuring changes behave as expected in real environments.
The First Attempt: Let AI Handle Everything
The initial approach explored was to let AI takeover complete process. A system was developed to read SQL files, understand their context and provide comprehensive feedback using advanced LLMs.
While promising in theory, the approach presented several challenges in practice. The LLM often generated numerous comments on a single file with outputs that varied each time the same code was analysed. Some feedback was useful, while other suggestions were minor or contradictory. This variability highlighted a key limitation: while AI excels at content generation, it may not provide the consistency required for effective code reviews.
The lesson learned was clear: code reviews require consistent feedback. The same code should produce the same guidance, which is critical for maintaining quality and developer trust.
Stepping Back: What Are We Actually Trying to Solve?
We regrouped and asked ourselves: what takes up most of the review time?
The answer wasn't complex optimisation or architectural decisions. It was the routine, repetitive part of the process.
- Syntax errors: Code that wouldn't even run in database.
- Common mistakes: Things like
SELECT *(selecting all columns) that hurt performance, and also a bad practice. - Missing standards: Forgetting to include tracking columns that our systems need for data lineage.
- Style issues: Using shortcuts that make code harder to read
These checks were:
- Objective (either the syntax is correct or it isn't)
- Repetitive (we were catching the same issues over and over)
- Automatable (a computer could do this faster and more consistently)
What about the creative, judgmental parts of review things like "is this the right approach?" or "could this be optimised?" those should stay optional suggestions, not blockers.
Our Solution: A Hybrid Approach
We built a system with three layers, each handling a different type of feedback:
Layer 1: The Syntax Police
First things first, does the code even work? We validate every SQL query against our actual Amazon Redshift database. Not by running the whole query (that could be dangerous), but by asking the database to EXPLAIN what it would do.
Think of it like a spell-checker, but for database queries. If there is a typo or the syntax is wrong, we catch it immediately and tell the developer exactly what's broken and where.
Example: If someone writes SELCT instead of SELECT, or references a table that doesn't exist, the system flags it instantly with the line number and error message.
This is a hard stop. If the query has syntax errors, it won't even be reviewed by humans.
Layer 2: The Rule Enforcer
Next, we check for common anti-patterns and violations of our coding standards. These are the issues that don't break the code but make it harder to maintain or slower to run.
Some of these checks include:
- SELECT * usage: Selecting all columns when you only need a few, wastes resources and makes code brittle
- Numeric GROUP BY: Writing
GROUP BY 1, 2, 3instead of actual column names makes code unreadable - Missing data lineage: Every query needs to track where its data comes from for our governance system.
These generate warnings. They should be fixed, but they won't block the merge if there's a good reason to ignore them.
Layer 3: The AI Advisor
Finally, and only after the basic checks pass, we use AI (AWS Bedrock with Nova Pro) to suggest optimisations. These are helpful hints, not requirements.
The AI might suggest things like:
- "This JOIN could be rewritten to improve performance"
- "Consider adding an index on this column"
- "This subquery could be simplified"
- "Grain mismatch detected here, clarify the intended granularity"
These are marked as informational comments. Developers can choose to implement them or ignore them based on their judgment.
The Architecture: How It All Fits Together
Let me walk you through how the system actually works when you push code:
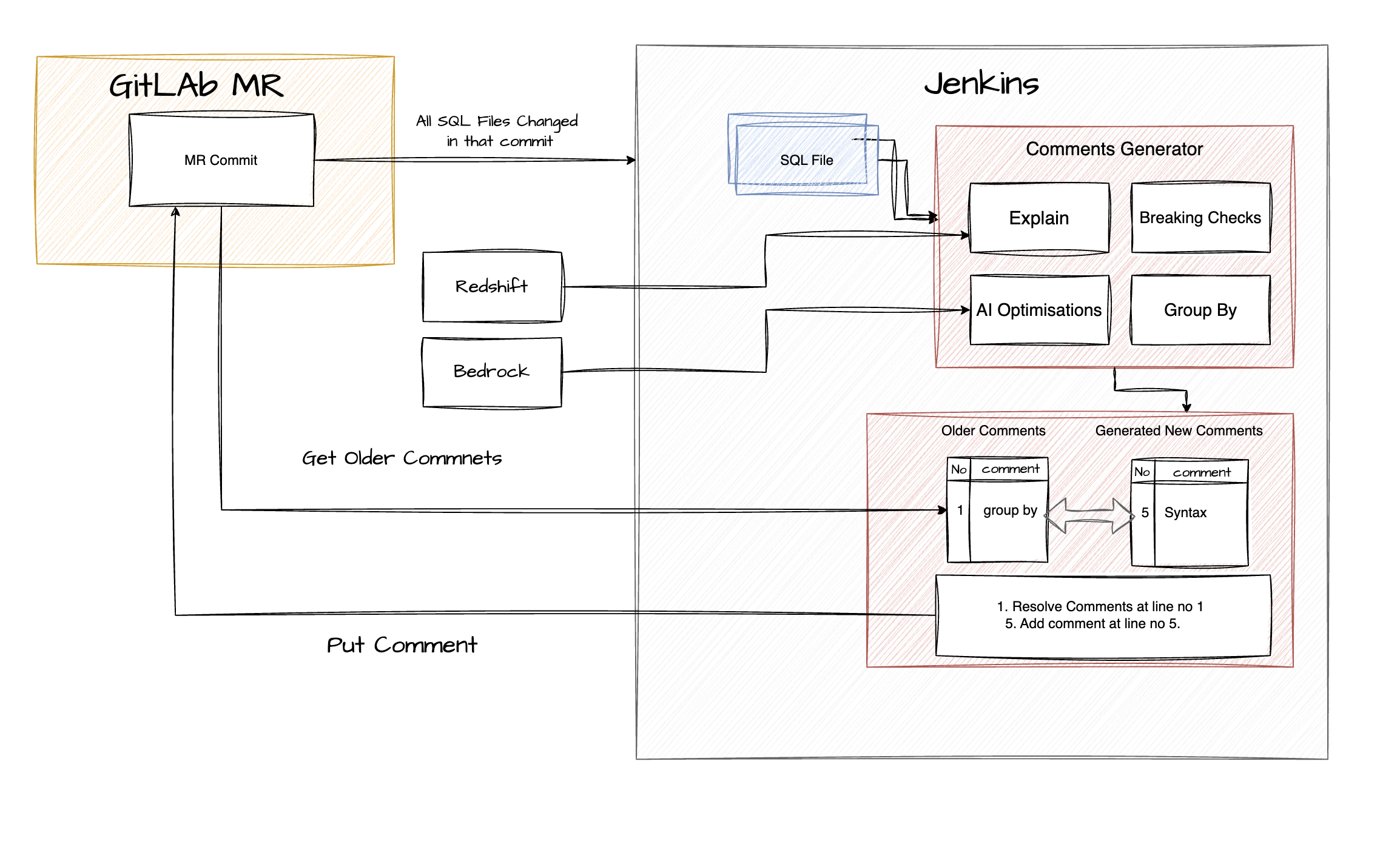
The entire process takes seconds to run, and developers get instant feedback.
Step 1: The Trigger: When you commit your code to GitLab, it automatically triggers our Jenkins pipeline. Jenkins, a CI/CD tool, executes the MR review script. The pipeline runs only for those commits that are attached to a Merge Request, not for standalone commits, since commenting is a feature of GitLab MRs.
Step 2: File Collection: Jenkins grabs all the SQL files in the commit using GitLab API. We only look at files in specific folders (like presentations/) to avoid checking generated code or configuration files.
Step 3: The Checking Phase: This is where the magic happens. Each SQL file goes through multiple validators running in parallel:
- Redshift Validator: Connects to our actual database and asks, "Would this query work?" It uses a special database feature called
EXPLAINthat checks syntax without running the query. - Breaking Checks Module: Looks for critical issues like syntax errors that would prevent the code from working at all.
- Code Quality Checks: Scans for patterns like
SELECT *or numericGROUP BYstatements. - AI Optimiser (Bedrock): Sends the query to AWS Bedrock's LLM and asks, "How could this be better?" This only happens after the basic checks pass.
Step 4: Comment Generation All the findings from these checks get collected and formatted into human-readable comments, each tagged with:
- The severity (Error 🚨, Warning ⚠️, or Info ℹ️)
- The exact file and line number
- A clear explanation of the issue
- Sometimes, a suggestion for how to fix it
- Using above info a comment will be created in the MR using GitLab API.
Step 5: The Smart Part - Comment Management Here's where the system gets clever. The system doesn't just dump comments onto the merge request. It gathers required metadata from GitLab. After the data collection it does a conversation with itself:
- "What comments already exist on this MR?"
- "What new issues did I just find?"
- "Which old comments are now irrelevant?"
Then it makes intelligent decisions about what to do.
The Magic: Smart Comment Management
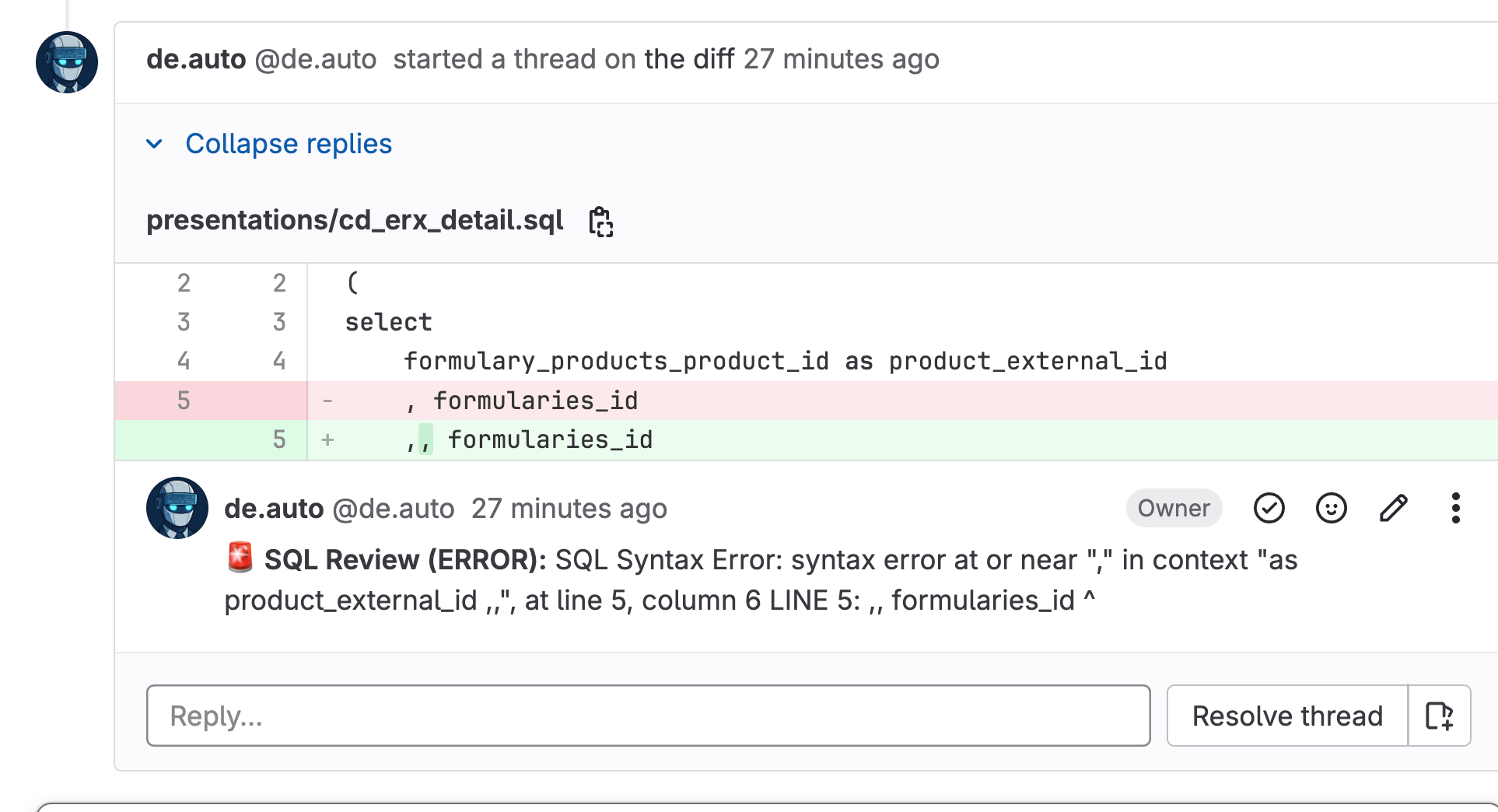
Imagine a developer submits a code with an error. Our system adds a comment: "Syntax error on line 42." You fix it and push a new commit. What happens?
It would either:
- Add a new comment about the same issue (creating spam)
- Leave the old comment hanging (causing confusion)
This system does neither. It recognises that the issue is fixed and automatically marks the comment as resolved.
The Custom Comment Key
The System creates a unique identifier for each potential comment:
key = f"{file_path}:{line_number}:{comment_content}"
The key is a fingerprint to uniquely identify each specific issue. Every time the checker runs, it builds two maps:
Older Map: All existing comments currently on the merge request before the current commit.
file1.sql:10:Obsolete issue✓ existsfile2.sql:20:Still valid comment✓ exists
Newer Map: All issues found in the current code check.
file2.sql:20:Still valid comment✓ should existfile3.sql:30:Brand new issue✓ should exist
Then it compares them:
| Older Map | Newer Map | Scenario | Action |
|---|---|---|---|
| ✓ | ✗ | Issue Fixed | RESOLVE - The issue is gone, mark the comment as resolved |
| ✓ | ✓ | Same Issue Still Exists | KEEP - Don't create a duplicate, leave it alone |
| ✗ | ✓ | New Issue Found | ADD - Create a new comment for this issue |
| "Changed wording" | "Updated wording" | Wording Changed | RESOLVE + ADD - Close old, add updated comment |
| line 50 | line 55 | Line Moved | RESOLVE + ADD - The same issue moved to a different line |
Why This Matters
In code reviews, repetitive comments for the same issue can be distracting and slow down development. Consider how different systems handle the same problem:
Bad System: "You have a syntax error on line 42" appears 10 times because you pushed 10 commits trying to fix other issues.
Our System: "You have a syntax error on line 42" appears once. When you fix it, that comment automatically resolves. If you accidentally reintroduce the same error later, a new comment appears.
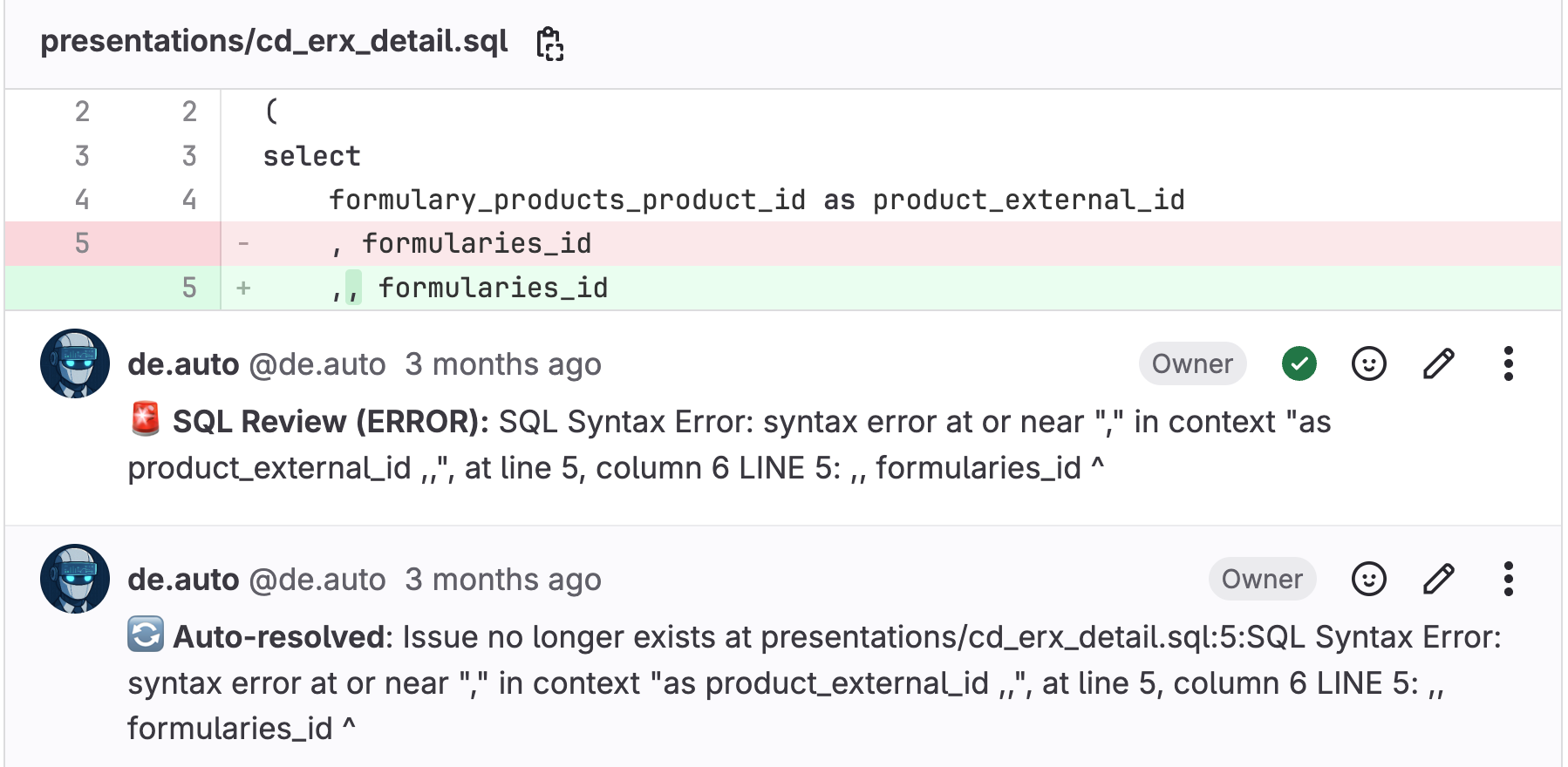
This makes the system idempotent, meaning it's safe to run multiple times without creating chaos. Whether the checker runs once or a hundred times on the same code, we'll see the same comments. No more, no less.
Impact and Results
After 2 months of using the system:
- Review time: Dropped from 30-60 minutes to 5 minutes
- Context switching: Data engineers review only the relevant parts.
- Consistency: Same code always gets same feedback
- Cost: AI optimisation suggestions cost us only $2-7 per week
- Developer satisfaction: BI team can self-serve basic validations
- Self service: Reduction in DE dependency, hence more MR's merged.
The 5 minutes of review time is now spent on the things that actually require human judgment architecture decisions, business logic verification.
Lessons Learned
Don't Let AI Run Wild: Our first attempt failed because we gave AI too much control. The successful version uses AI only for non-critical suggestions, with clear labelling that these are optional.
Consistency Beats Intelligence: A system that catches 80% of issues consistently is more valuable than one that catches 100% of issues inconsistently.
Developer Experience Matters: We spent significant time on the comment management system because nothing frustrates developers more than being spammed with duplicate or outdated comments.
Know Your Bottlenecks: We didn't need a general-purpose code reviewer. We needed something that caught the specific, repetitive issues our team dealt with daily.
Fail Fast on Blockers, Suggest Gently on Improvements: Syntax errors block the merge. Optimisation suggestions are clearly marked as optional. This respects developer agency while maintaining code quality.
What's Next?
We're not done improving. Our roadmap includes:
Smarter AI Memory: Right now, the AI generates suggestions fresh each time. We're building a system to remember past suggestions and learn from which ones get accepted vs. ignored.
Auto-Fix Capability: For simple issues like SELECT * or positional GROUP BY, we're experimenting with having the system automatically suggest code fixes that developers can accept with one click.
Custom Rules Engine: Teams could define their own validation rules without writing Python code, using a simple configuration format.
Lineage & Business Logic Awareness: While standalone SQL reviews solve most issues, deeper validation will eventually require analysing upstream and downstream tables to ensure the business logic is correctly modelled. This will be supported by building a shared knowledge base.
Conclusion
Automation isn't about replacing humans it's about freeing them from repetitive work so they can focus on tasks that create more value. Our SQL reviewer doesn't replace human reviews, It handles the tedious, objective checks that don't require human judgment, and flags the genuinely interesting issues for human review.
The result? Data engineers spend their time on architecture, mentoring, and solving hard problems. Our BI team gets faster feedback. And our codebase is more consistent and maintainable than ever. If you're drowning in code reviews, ask yourself: what percentage of your review time is spent catching the same issues over and over? That's your automation opportunity.
Sometimes the best solution isn't the most sophisticated one. It's the one that solves the actual problem.
Join us
Scalability, reliability, and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels, and if solving hard problems with challenging requirements is your forte, please reach out to us with your resume at careers.india@halodoc.com.
About Halodoc
Halodoc is the number one all-around healthcare application in Indonesia. Our mission is to simplify and deliver quality healthcare across Indonesia, from Sabang to Merauke.
Since 2016, Halodoc has been improving health literacy in Indonesia by providing user-friendly healthcare communication, education, and information (KIE). In parallel, our ecosystem has expanded to offer a range of services that facilitate convenient access to healthcare, starting with Homecare by Halodoc as a preventive care feature that allows users to conduct health tests privately and securely from the comfort of their homes; My Insurance, which allows users to access the benefits of cashless outpatient services in a more seamless way; Chat with Doctor, which allows users to consult with over 20,000 licensed physicians via chat, video or voice call; and Health Store features that allow users to purchase medicines, supplements and various health products from our network of over 4,900 trusted partner pharmacies. To deliver holistic health solutions in a fully digital way, Halodoc offers Digital Clinic services including Haloskin, a trusted dermatology care platform guided by experienced dermatologists.
We are proud to be trusted by global and regional investors, including the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. With over USD 100 million raised to date, including our recent Series D, our team is committed to building the best personalized healthcare solutions — and we remain steadfast in our journey to simplify healthcare for all Indonesians.


