

Optimising Database Performance with Efficient Transaction Management
Introduction:
Maintaining the integrity of data, especially during system failures and concurrent modifications, is a significant challenge. A reliable data store should gracefully handle faults and ensure data consistency. Many potential issues can disrupt a data system, such as hardware failures, software failures, concurrent writes, network problems during replication, and partial data updates. In this blog, we will explore transaction management, different levels of isolation and their impact on performance and some best practices for designing transactions.
Why Application Developers Must Grasp Database Transaction Safety?
Transaction management in various databases is not always well understood because databases handle many error scenarios and concurrency issues, alleviating the burden from application developers. However, it is essential for application developers to comprehend the safety guarantees provided by transactions for several reasons:
Vendor Variability: Not all database vendors offer the same safety guarantees. ACID (Atomicity, Consistency, Isolation, Durability) guarantees can vary from one vendor to another, so blind acceptance is not advisable.
Decision Making: Application developers need to make critical decisions when a database aborts a transaction. This can occur due to transient errors (where retrying makes sense) or integrity violations (where undoing changes is necessary).
Data Consistency: Even with ACID safety guarantees, it remains the application's responsibility to maintain data consistency. While a database can prevent foreign key or unique constraint violations, it cannot prevent the application from writing flawed data. The application defines what is considered valid or invalid data.
Need for Transaction management:
Efficient transaction management is crucial for maintaining database performance and ensuring the integrity of data. Here are key reasons why efficient transaction management is essential:
Data Consistency: Transactions help maintain the consistency of data in a database. They ensure that operations either succeed completely (commit) or fail completely (rollback). This prevents data from being left in an inconsistent or partially updated state, which could lead to errors or corruption.
Concurrency Control: In multi-user environments, multiple transactions can be executed concurrently. Efficient transaction management ensures that conflicts are resolved effectively to avoid data contention and maintain data integrity.
Isolation: Transaction isolation levels (e.g., READ COMMITTED, SERIALIZABLE) control how transactions interact with each other. Proper isolation levels prevent issues like dirty reads, non-repeatable reads, and phantom reads. Efficient transaction management ensures the right level of isolation is chosen for each scenario, balancing performance and data consistency.
Performance Optimization: Efficient transaction management involves optimising transaction design, reducing transaction nesting, and minimizing the time a transaction holds locks. This contributes to improved database performance and reduces contention among concurrent transactions.
Error Recovery: In the event of system failures or unexpected errors, efficient transaction management allows for recovery and restoration of data to a consistent state using techniques like transaction logs and checkpoints.
Transaction Isolation:
Now let’s discuss one of the most important topics in this blog which is Isolation levels. If two transactions don’t touch the same data, they can safely be run in parallel, because neither depends on the other. But Concurrency issues (race conditions) only come into play when one transaction reads data that is concurrently modified by another transaction, or when two transactions try to simultaneously modify the same data.
Concurrency bugs are hard to find by testing because such bugs are only triggered when you get unlucky with the timing. Such timing issues might occur very rarely and are usually difficult to reproduce. Concurrency bugs are generally caused by weak isolation levels of transactions.
ACID-compliant databases need to make sure that each transaction is carried out in isolation. This means that the results of the transaction is only visible after a commit to the database happens. Other processes should not be aware of what’s going on with the records while the transaction is carried out.
What happens when a transaction tries to read a row updated by another transaction?
It depends on what isolation level the database is operating on w.r.t. that particular transaction. Let’s explore the problems that can occur.
Problems when transaction isolation is not done:
Dirty Read — Let’s take a situation where one transaction updates a row or a table but does not commit the changes. If the database lets another transaction read those changes (before it’s committed) then it’s called a dirty read. Why? Let’s say the first transaction rolls back its changes. The other transaction which read the row/table has stale data. This happens in concurrent systems where multiple transactions are going on in parallel. But this can be prevented by the database and we will explore how later.
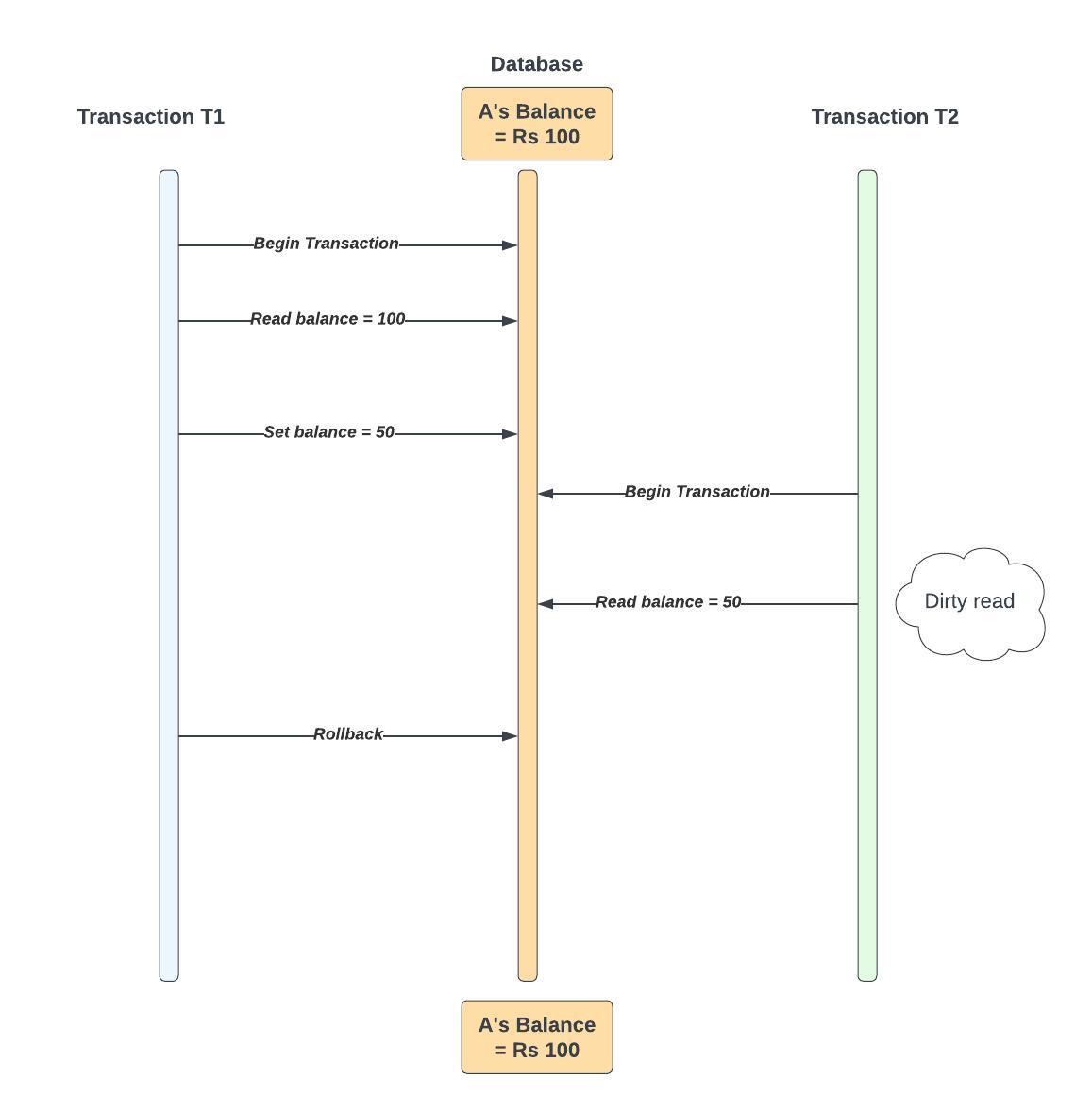
E.g.
A’s Balance before any Transaction = Rs. 100.
Transaction T1 Begins
T1 Reads A’s Balance = Rs. 100
T1 Sets A’s Balance = Rs. 50 (e.g., for a transfer to B or another operation)
Transaction T2 Begins
T2 Reads A’s Balance = Rs. 50 [DIRTY READ] (T2 reads the uncommitted change made by T1)
T1 Rollback (T1's changes are undone)
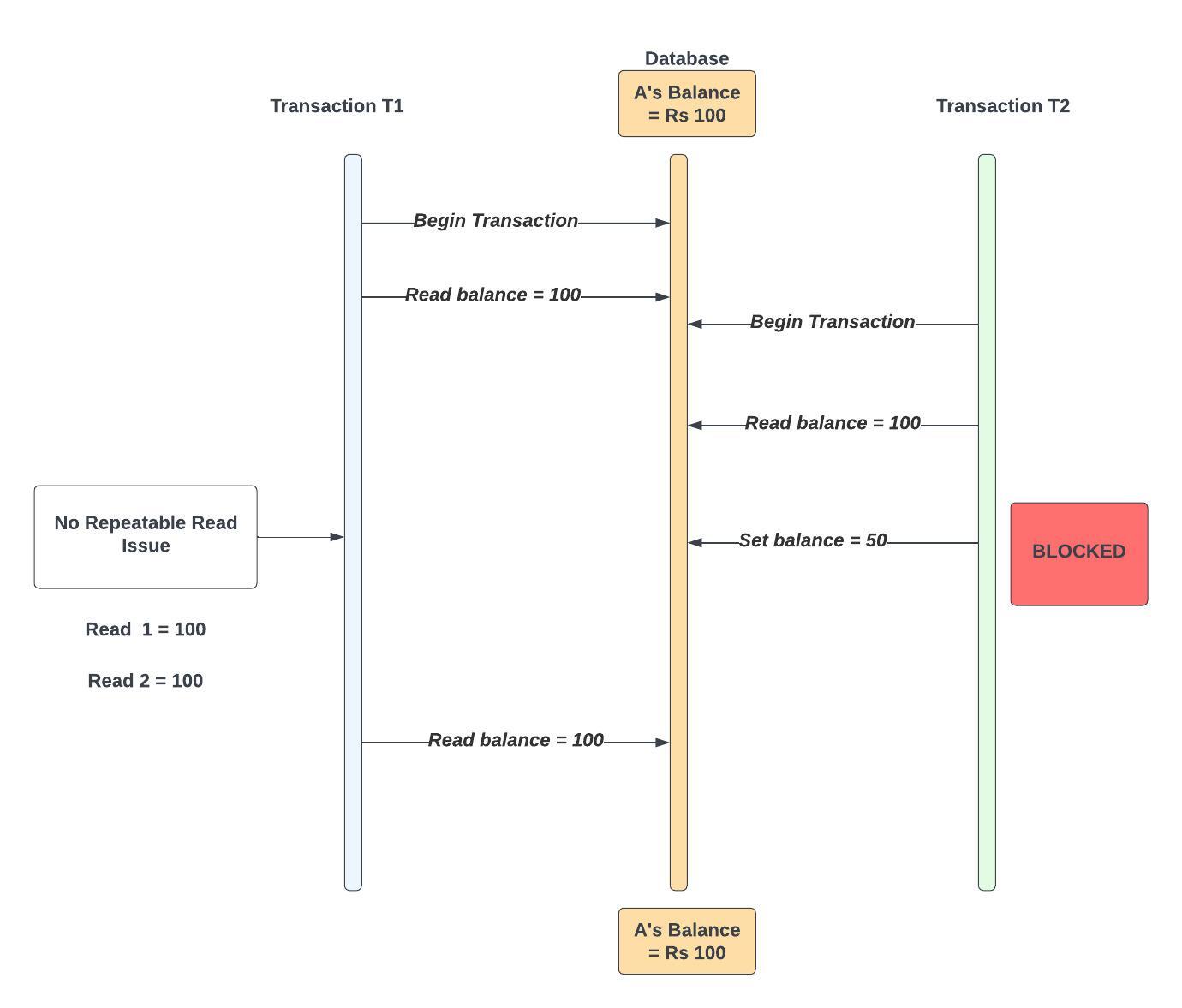
Non-repeatable read — Another side effect of concurrent execution of transactions is that consecutive reads can retrieve different results if you allow another transaction to do updates in between. So, if a transaction is querying a row twice, but between the reads, there is another transaction updating the same row, the reads will give different results.
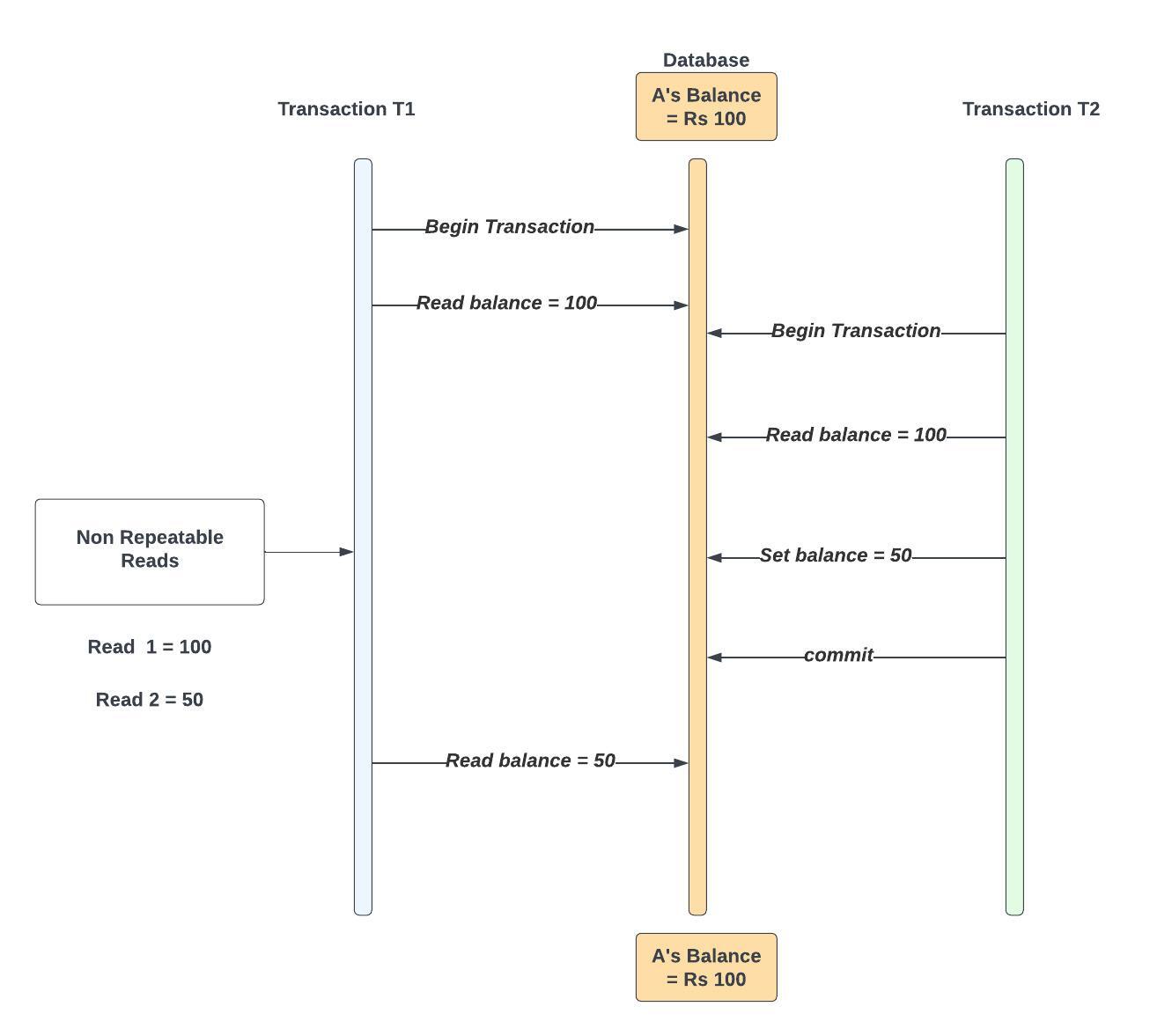
Consider an example:
Transaction T1 Begins
T1 Reads A's Balance = Rs. 100 [Read 1]
Transaction T2 Begins
T2 Reads A's Balance = Rs. 100
T2 Writes A's Balance = Rs. 50 (e.g., transferring Rs. 500 from A to B)
T2 Commits
T1 Reads A's Balance = Rs. 50 [Read 2] — Issue
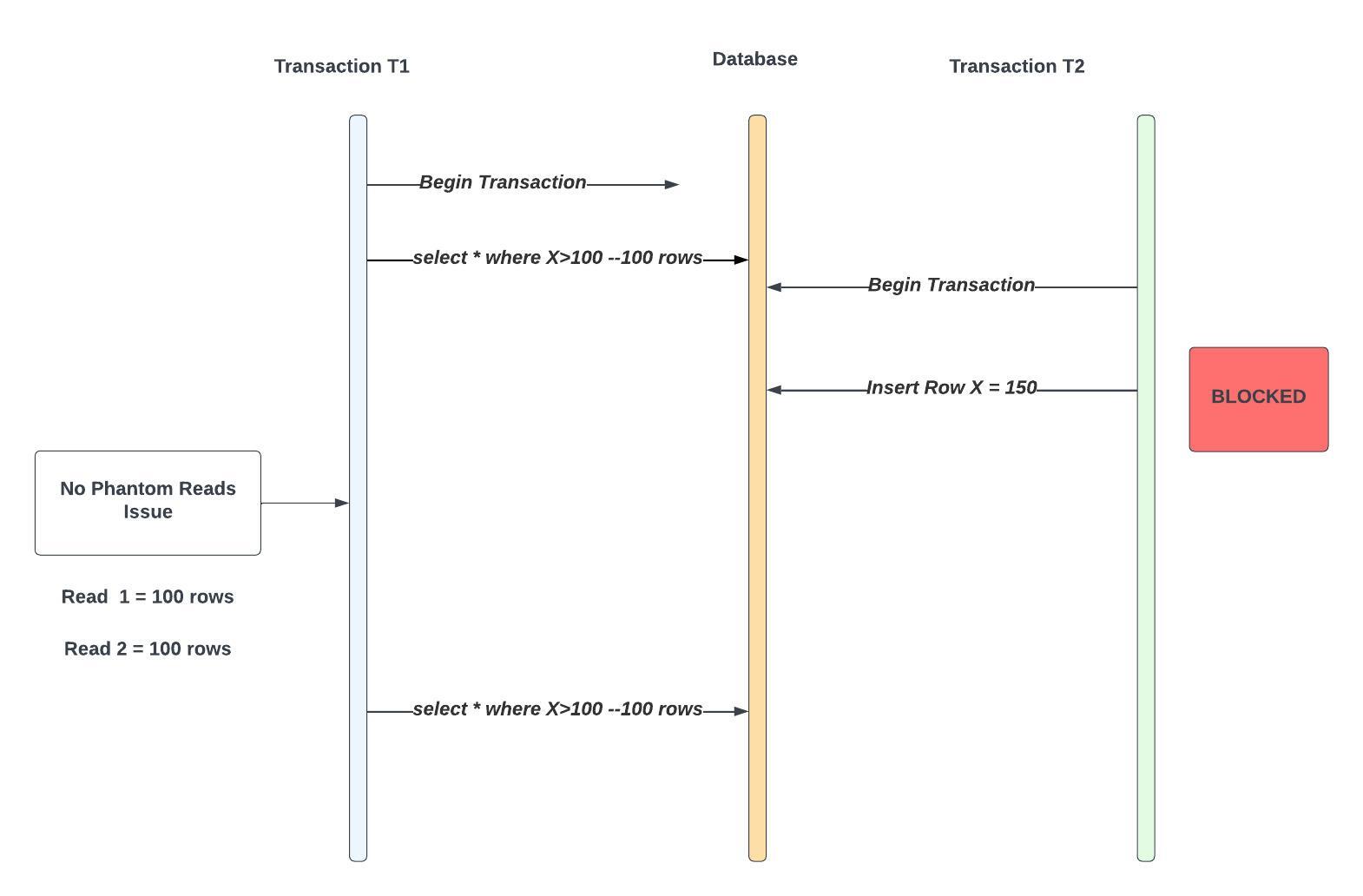
Phantom read — In a similar situation as above, if one transaction does two reads of the same query, but another transaction inserts or deletes new rows leading to a change in the number of rows retrieved by the first transaction in its second read, it’s called a Phantom read. This is similar to a non-repeatable read. The only difference is that while in a non-repeatable read, there will be inconsistency in the values of a row, in phantom reads, the number of rows retrieved by the queries will be different.
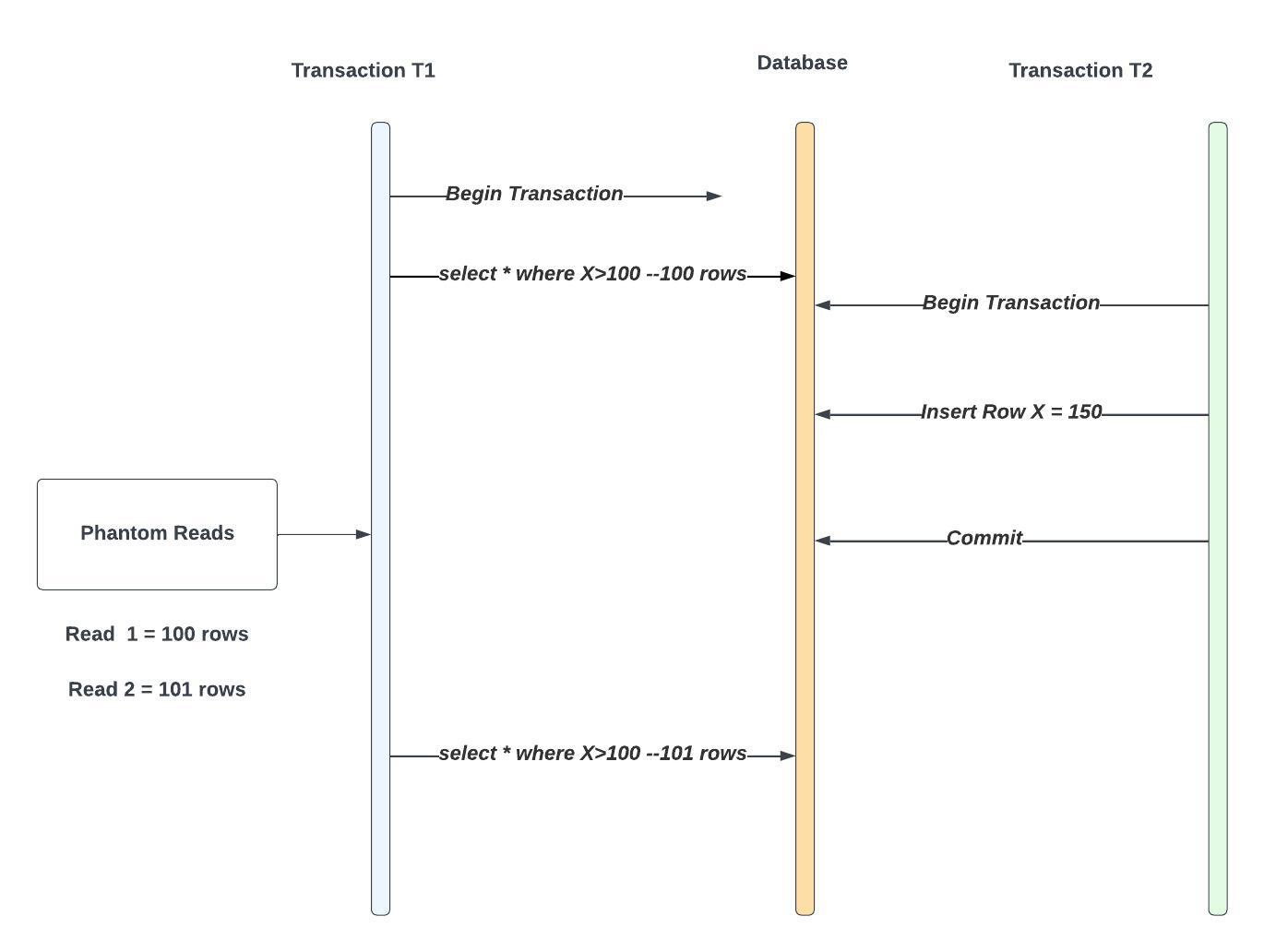
E.g.
Transaction T1 Begins
T1 Queries: SELECT * FROM Table WHERE X > 100 (Initially returns 100 rows)
Transaction T2 Begins
T2 Inserts a Row with X = 150
T1 Repeats the Same Query (SELECT * FROM Table WHERE X > 100) and Now Gets 101 Rows
How do databases deal with this?
They implement levels of isolation to avoid such problems.
Before going into isolation levels, let’s understand locks on Databases.
- Read (Shared) Lock:
- When Transaction T1 holds a read lock on a specific row, other transactions, like Transaction T2, can still read that same row concurrently.
- This means that multiple transactions can share a read lock on the same row without blocking each other.
- Importantly, readers holding read locks do not block writers, so Transaction T2 could also update the row while T1 has a read lock on it.
2. Write (Exclusive) Lock:
- When Transaction T1 holds a write lock on a specific row, it prevents other transactions (T2 and others) from both reading and writing to that row simultaneously.
- Writers with exclusive locks block both readers and writers from accessing the locked row.
- Write locks are used to ensure data consistency and prevent conflicts when data is being modified.
3. Range Lock :
A Range lock is a database locking mechanism that allows you to lock a range of data within a database table, as opposed to just a single row or a single item. This type of lock can be useful in situations where you need to ensure the consistency of multiple rows or items within a specific range of data.
While locks were supposed to be used for complete isolation of transactions, if they are going to limit other transactions from doing anything while the resource is locked then lock contentions might create a problem.
The solution to this is having different levels of isolation. Let’s discuss the most common ones. These are mentioned in increasing order of isolation levels.
Levels of Isolation:
Read uncommitted - This level of isolation lets other transactions read data that was not committed to the database by other transactions. There is no isolation happening here. So, if transaction 1 performs an update and before it’s able to commit, if transaction 2 tries to access the updated data, it will see the new data. This does not solve any issues mentioned above.
Read committed - This, as the name suggests, lets other transactions only read data that is committed to the database. While this looks like an ideal level of isolation, it only solves the dirty read problem mentioned above. If a transaction is updating a row, and another transaction tries to access it, it won’t be able to. But this can still cause non-repeatable and phantom reads because this applies only to updates and not read queries.
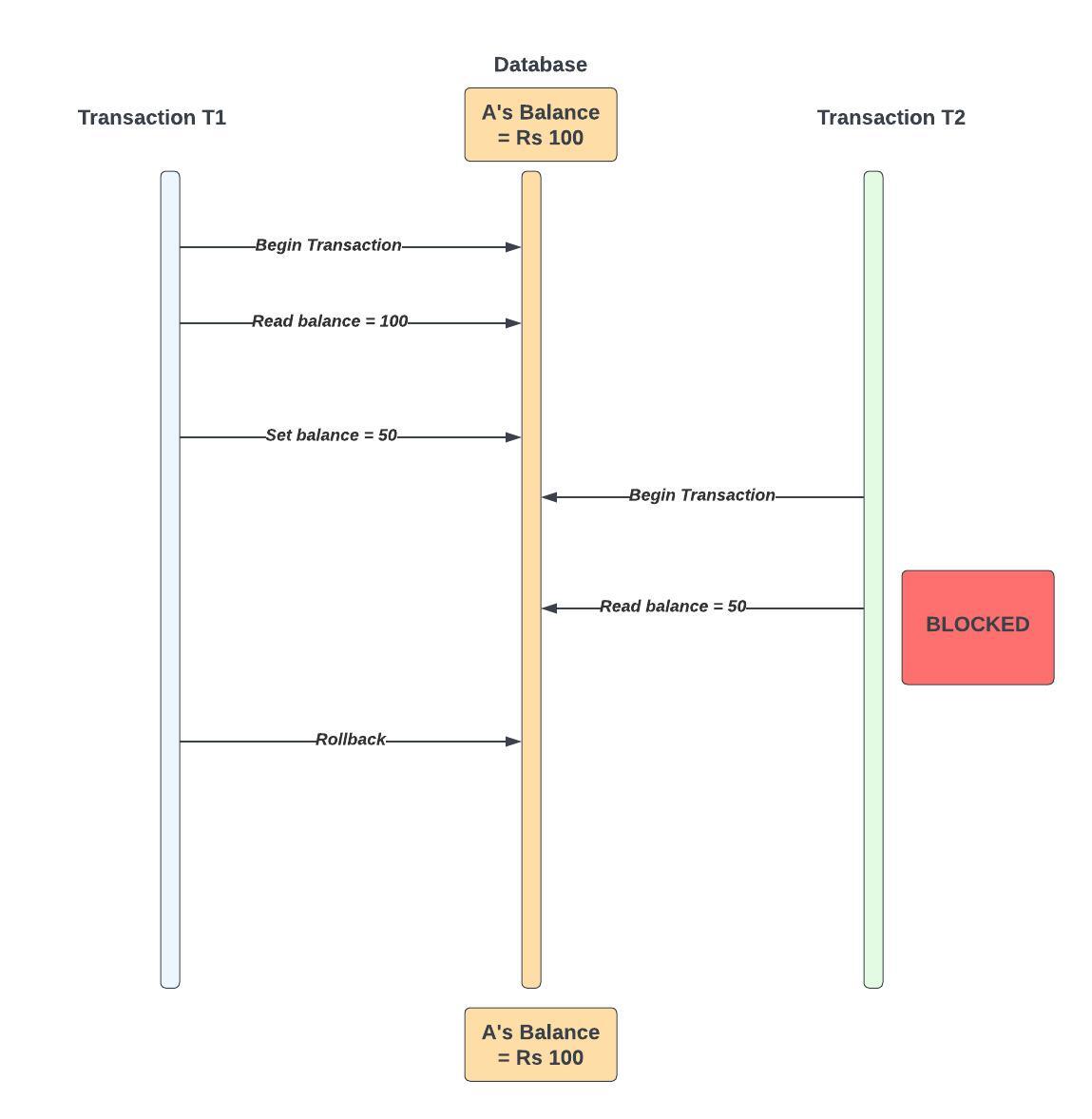
E.g.
Transaction T1 Begins
T1 Reads A's Balance = Rs. 1000
T1 Sets A's Balance = Rs. 500 (e.g., to send it to B or for some other purpose)
Transaction T2 Begins
T2 Attempts to Read A's Balance but is Blocked (Will not execute until T1 completes)
Implementing Read Committed
Databases prevent dirty writes & dirty reads by using row-level locks. When a transaction wants to modify a particular row or document, it must first acquire a lock on that object (row or document). It must then hold that lock until the transaction is committed or aborted.
Only one transaction can hold the lock for any given row or document.
However, the approach of requiring read locks does not work well in practice, because one long-running write transaction can force many read-only transactions to wait until the long-running transaction has completed.
This harms the response time of read-only transactions as a slowdown in one part of an application can have a knock-on effect in a completely different part of the application, due to waiting for locks.
Snapshot Isolation or Repeatable Read - To counter the transactions from getting inconsistent data, we need a higher level of isolation and that is offered by repeatable read. In this, the resource is locked throughout the transaction. So, if the transaction contains two select queries and in between, if another transaction tries to update the same rows, it would be blocked from doing so. This isolation level is not immune to phantom reads though it helps against non-repeatable reads. This is the default level of isolation in many databases. Snapshot isolation is a boon for long-running, read-only queries such as backups and analytics. It’s better than Read Committed Isolation level in terms of avoiding concurrency issues.
Transaction T1 Begins
T1 Reads A's Balance = Rs. 1000 [Read-1] (R Lock held on this row)
Transaction T2 Begins
T2 Reads A's Balance = Rs. 1000 (Read Lock held; multiple reads allowed)
T2 Attempts to Update A's Balance = Rs. 500 [BLOCKED] (Waiting for a Lock)
T1 Reads A's Balance Again = Rs. 1000 [Read-2] (Same Result).
Implementing snapshot isolation
The database has to keep several different committed versions of objects (row, or tables, or documents), because various in-progress transactions may need to see the state of the database at different points in time. Because it maintains several versions of an object (row, or tables, or documents) side by side, this technique is known as Multi-Version Concurrency Control (MVCC).
The key principle of snapshot isolation is Readers never block Writers, and Writers never block Readers. This allows a database to handle long-running read queries on a consistent snapshot at the same time as processing writes normally, without any lock contention between the two.
Serializable - This is the highest level of isolation. In this, all concurrent transactions “appear” to be executed serially. But it’s not truly serially or sequentially executed. This level works against phantom reads as well.
Transaction T1 Begins
T1 Queries: SELECT * FROM table WHERE X > 100 → Returns 100 rows (Range Lock held on 100 rows)
Transaction T2 Begins
T2 Attempts to Insert 1 Additional Row with X = 150 [Blocked]
T1 Repeats the Same Query: SELECT * FROM table WHERE X > 100 → Returns 100 rows [Same result]
Quick Summary:

While these isolation levels are standard, different database vendors may provide variations or extensions beyond these four basic levels. Furthermore, the way database systems handle locking and concurrency control mechanisms under these isolation levels can vary significantly. The specific behavior and performance characteristics may be vendor-specific.
Best practices for designing and implementing transactions:
Designing and implementing transactions effectively is crucial for maintaining data integrity and application reliability. Here are best practices for designing and implementing transactions:
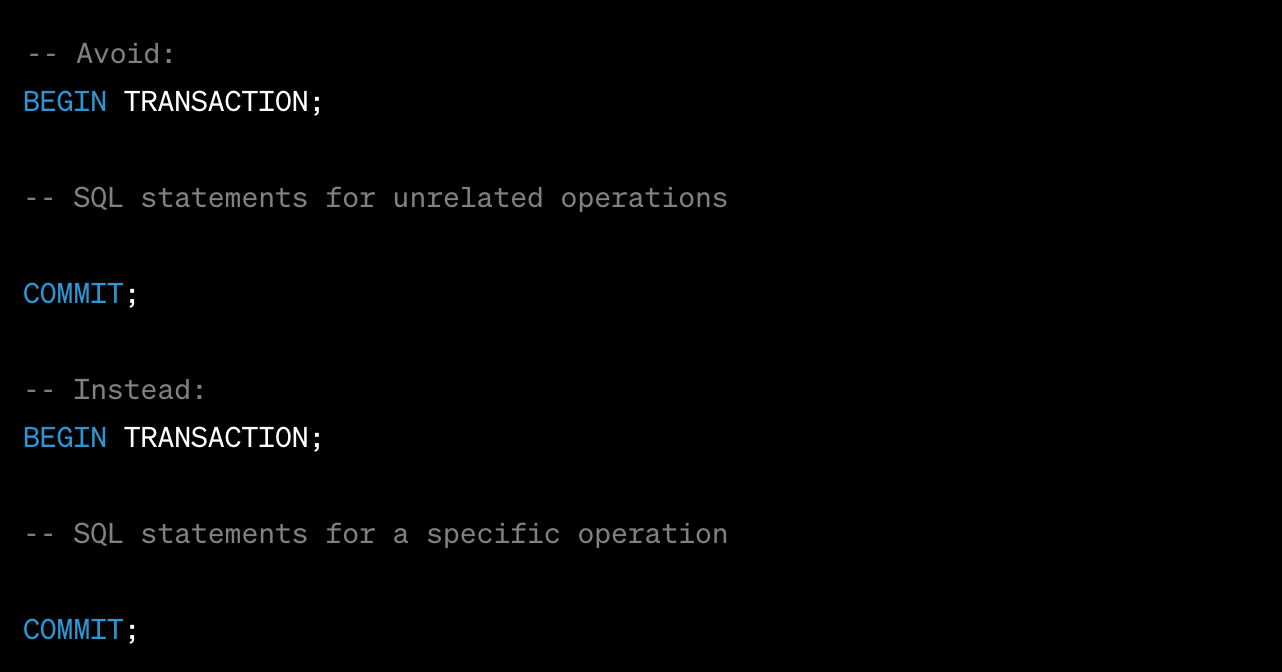
Keep Transactions Short and Focused:
Aim for short and focused transactions that perform a single logical unit of work.Avoid long-running transactions that hold locks for extended periods, as they can lead to contention and performance issues. Avoid including unrelated operations within a single transaction.
Choose the Right Isolation Level:
Understand the isolation levels (e.g., READ COMMITTED, SERIALIZABLE) and choose the appropriate level for each transaction.Use the least strict isolation level that satisfies your data consistency requirements to improve concurrency.
The choice of isolation level depends on your application's requirements. Use a less strict level for scenarios where high concurrency is more important, and use a more strict level when data consistency is critical, even if it means sacrificing some concurrency. Consider the trade-offs carefully in your specific use case.
Minimize Transaction Nesting:
Limit the nesting of transactions. Nested transactions can complicate error handling and lead to unpredictable behaviour.
Prefer a flat transaction structure whenever possible.
Suppose you have a database with two tables: Customers and Orders, and you want to update the customer's information and the order total amount within a single transaction. Instead of nesting transactions, you can perform the two updates in a single transaction block:
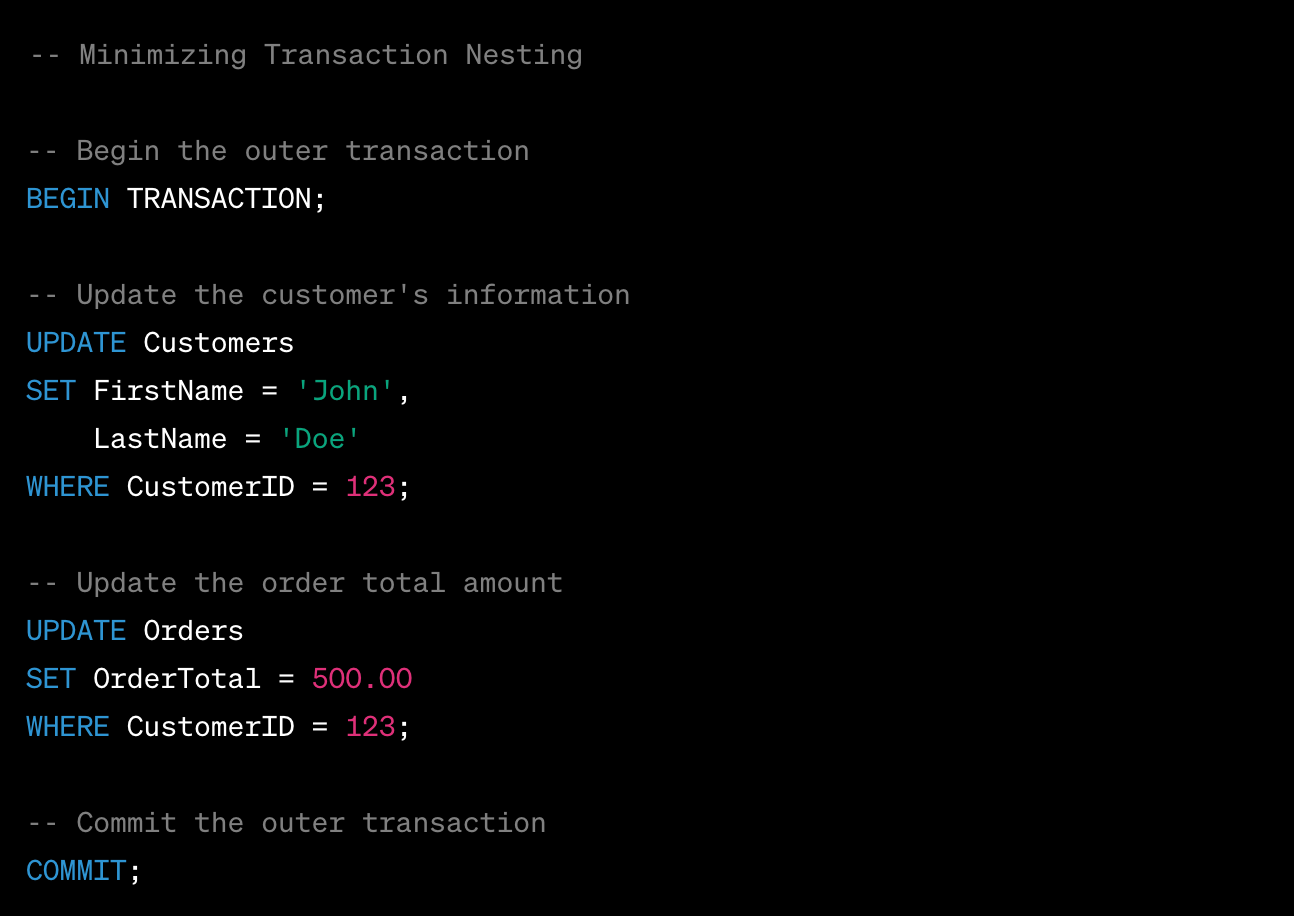
In this example, we have a single transaction that encompasses both updates. This minimises the nesting of transactions and reduces the complexity of the code.
Now, let's compare this approach to a nested transaction:
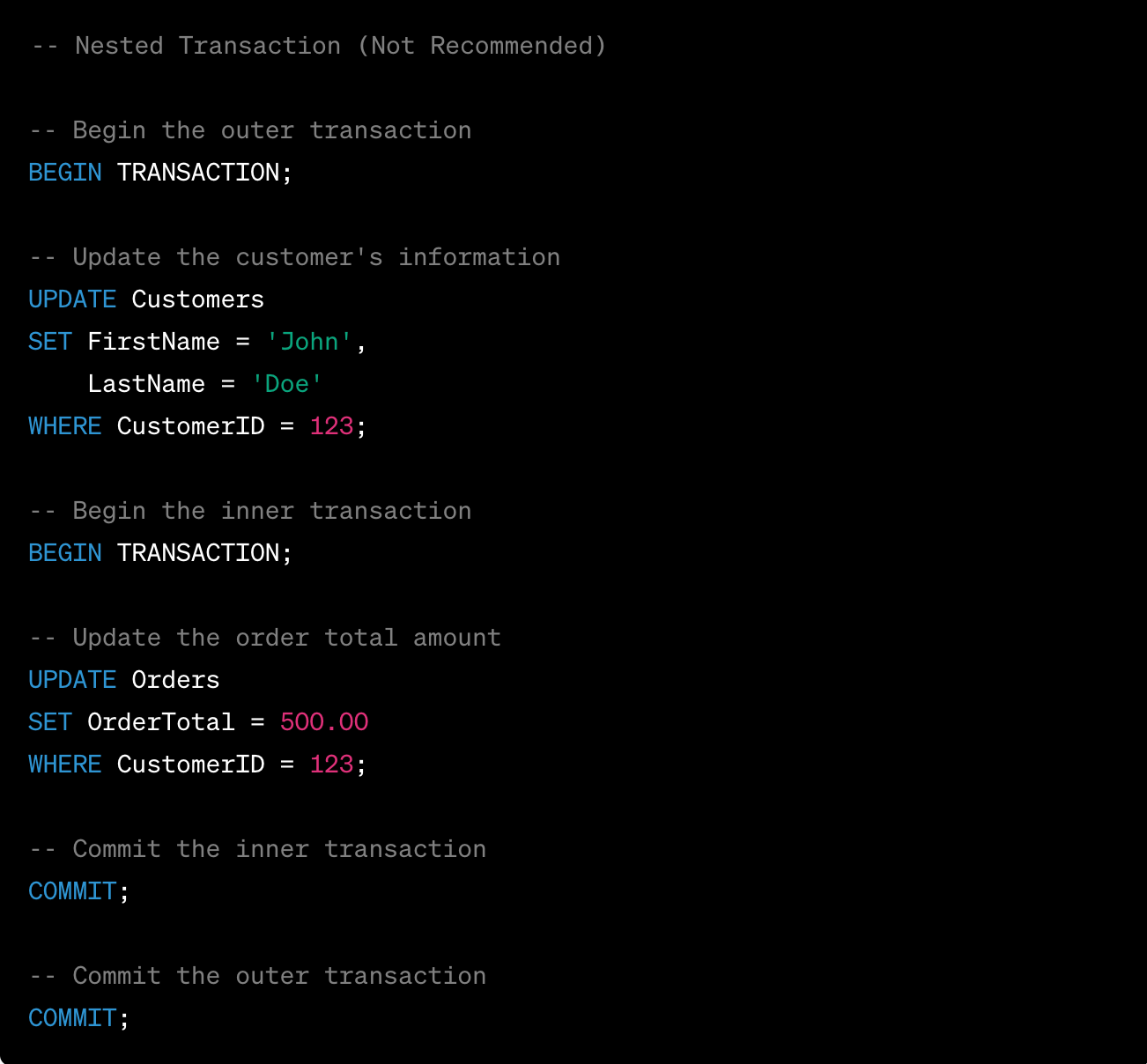
While this code works, it involves nesting transactions, which can lead to increased complexity and potential issues. For instance, if the inner transaction fails and is rolled back, the outer transaction remains open, which might lead to unexpected behavior. It's better to use a single transaction for this scenario to maintain simplicity and avoid potential complications.
Optimistic Concurrency Control:
Implement optimistic concurrency control techniques when multiple users may access and modify the same data concurrently.
Use version numbers or timestamps to detect conflicts.
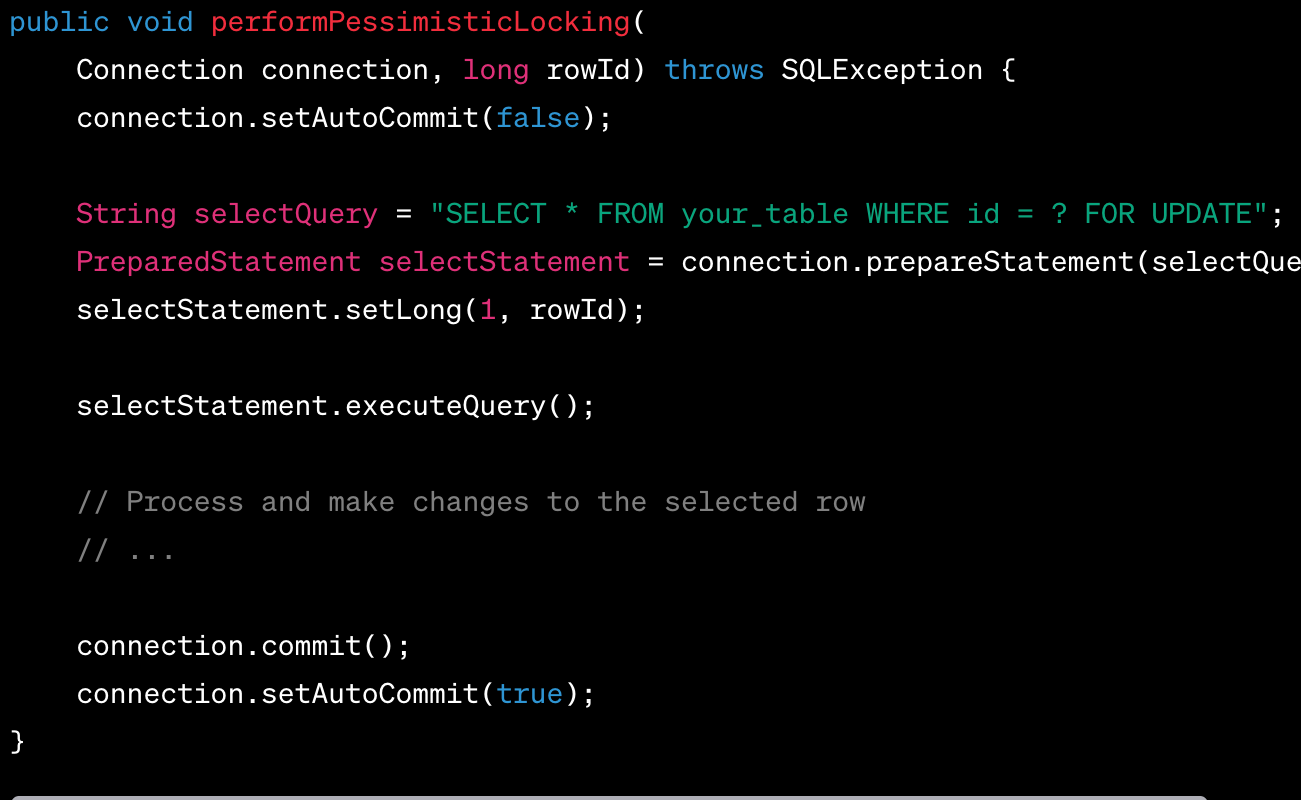
By default, rely on a pessimistic locking strategy
Lock rows that you SELECT if the results of the SELECT statement affect DML executed later in the transaction. Pessimistic locking is easy to implement and is a robust solution. However, issue SELECTs with FOR UPDATE as late in the transaction as possible to minimise duration of locks.
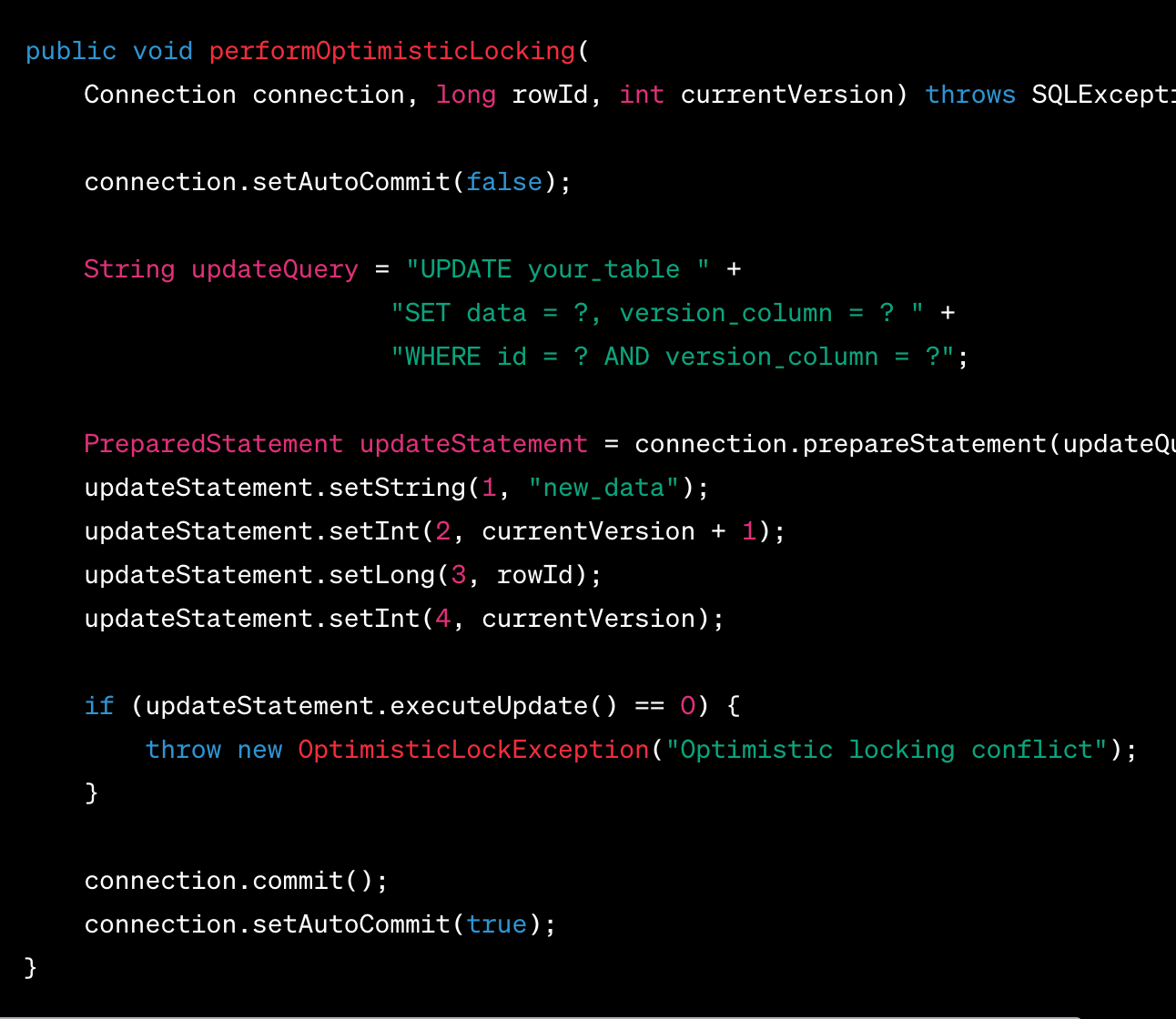
Consider optimistic locking for throughput-critical transactions
Optimistic locking requires more coding (to handle failed transactions) and may lead to user frustration if the optimism is misplaced. However, optimistic locking can reduce lock duration and thereby increase throughput for high-volume transactions. Optimistic locking is typically implemented using a version or timestamp column in your database table.
Batch Processing and Bulk Operations:
For bulk data operations, consider using batch processing techniques to minimize transaction overhead.
Use bulk insert/update/delete statements for efficient bulk data modifications. Group related operations into a single transaction to reduce the number of commits.

Performance & Scalability:
Transactions let you group sql statements into an atomic unit. It doesn't mean your code should be written that way with multiple sql statements going back and forth to the database. This will kill your performance. Do the extra work to instead organise your code to construct a block of statements that you send to the db to execute in a transaction. If not your scalability will take a major hit as you'll be holding on to locks too long and your performance will be impacted due to too many round-trips to the db.
Conclusion
In essence, efficient transaction management serves as the bedrock of data integrity, concurrent access support, error resilience, and optimized database performance. By adhering to these best practices, developers can architect transactions that are stalwarts of consistency, reliability, and efficiency, ensuring the smooth and dependable operation of data-driven systems. It enables applications to work with databases in a way that balances consistency and performance, ensuring the reliable and efficient operation of data-driven systems.
References
http://dataintensive.net/
https://martin.kleppmann.com/2017/03/27/designing-data-intensive-applications.html
https://martin.kleppmann.com/2015/09/26/transactions-at-strange-loop.html
Join Us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resume at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. We recently closed our Series D round and in total have raised around USD$100+ million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


