
How to migrate your Kubernetes workloads into AWS Graviton2
At Halodoc, we are relentless in our pursuit to enhance the efficiency and reduce the costs of our compute infrastructure. We've been hearing a lot about AWS's custom-built ARM64 processors named "Graviton2". Numerous online reviews indicate that Graviton2-based instances deliver a 40% performance improvement while being 20% more cost-effective than their Intel/AMD counterparts.
This article delves into the process of transitioning Kubernetes workloads from AMD64 nodes to Graviton2 nodes. The insights from our migration experience can help others plan more effectively and expedite their own successful transitions.
Previously, our compute nodes were reliant on Intel/AMD architectures, with a significant number being utilized within our Kubernetes clusters (EKS). Thus, our initial goal was to transition AMD64-based workloads to Graviton2 nodes.
Within our Kubernetes cluster, we host a diverse range of applications, including Dropwizard, NodeJS, Tomcat, and GO. We prioritized migrating Dropwizard applications first, given that they constitute the majority of our applications.
Initial Investigation:
We initially believed that simply creating ARM64-based images would pave the way for our migration to Graviton2. However, when we attempted to build GO applications for Graviton2, we encountered challenges. These build issues stemmed from the absence of compatible libraries.
Moreover, while we tried constructing Dropwizard applications using "docker buildx", we were unable to get the applications running on Graviton2 due to architectural incompatibilities.
Another observation was that the auto-scaling for Graviton2 nodes did not function according to resource needs. Additionally, with our existing NewRelic infra-agent for Kubernetes, we couldn't access container metrics.
Challenges faced to start the migration journey:
- From our preliminary assessment, we believed that by creating a multi-arch image using "docker buildx," we could facilitate a smooth migration without needing any adjustments in our CI/CD process. It's worth noting that our CI/CD pipeline integrates tools like Gitlab, Jenkins, Ansible, helm-charts, and Kubernetes.
In practice, we discovered that images built on the AMD64 architecture are not compatible with Graviton2 nodes.
Our evaluation:
We evaluated two options:
a. Using AWS CodePipeline to build Graviton2 based images and push to ECR (Elastic Container Registry)
b. Create a Graviton2 Jenkins slave.
We decided to go with Graviton2 Jenkins slave option since it requires minimal changes in our CI/CD process.
2. Second challenge faced was that we use vault-k8s agent as Init Container for managing the secrets. We could not find ARM64 based image for vault-k8s agent. Before vault integration, we used shell script for this purpose. No intention to go back to old-school.
We solved the issue using Vault 1.6.2 version which is multi-arch based and with an annotation.
- Created base image for vault init agent for arm64: vault V1.6.2
- Used vault agent proxy annotation in our helm charts.
vault.hashicorp.com/agent-image:XXX.YYY.ap-southeast-1.amazonaws.com/vault:1.6.2
3. Third challenge we faced was that we use NewRelic for our APM. Unfortunately, no ARM64 supported NewRelic agent available . If we move our workloads into Graviton2, we will not get any APM metrics, which will impact our Monitoring and Alerting system.
Initially we used, newrelic-infra agent installed as Linux process in EKS worker nodes to provide container related metrics. But no luck. It does not capture the container metrics. Only node infra metrics are available.
Luckily, we got a beta image for ARM64. This solved our monitoring and alerting issues. We maintained two daemonsets i.e. one for AMD64 and one for ARM64 nodes.
https://hub.docker.com/r/newrelic/infrastructure-k8s
Our Kubernetes cluster is running with version 1.16 before migration. We upgraded to version 1.17. During the process, we upgraded ALB ingress controller, Metrics server and Cluster auto-scaler to much higher level to support multi-arch nodes. Otherwise, these component upgrades are not mandatory.
Migration process:
We tested the waters in stage first. Once validated, we migrated the workloads into Prod. We used self-managed node groups in our EKS cluster. Created a new Auto Scaling Group for Graviton2 nodes with different node label to facilitate easy migration.
Our Java apps are Dropwizard based. We created base images for ARM64. An application pod contains these containers.
2. Updation of helm charts.
We updated the images according to ARM64 architecture. We added annotation and vault proxy in our helm charts


Updated node Selector to force the new deployment placed on Graviton2 nodes.

We used fluent-bit for log collection.

3. Restricting Graviton2 based Jenkins jobs to run on Graviton2 node only.

4. We observed test case failures in a few applications mainly for missing compatible libraries. We took developers help to find alternate libraries to fix those issues.
Validation of Stage migration:
Our approach was to validate the applications in stage before migrating to production since we wanted to avoid any surprises in production. Our testers performed through testing of the application before providing sign-off. We withheld some application migrations due to test case failures ( we use Sonarqube and JaCoCo for test coverage). We worked with developers and testers to find alternate libraries to get through the quality gates.
Observations:
During application migrations, we found that CPU requirements are little higher compared to AMD64 based worker nodes while starting the application. We increased the CPU "limit" around 10% where app container continuously restarts for CPU crunch. Over a period of time, CPU utilisation reduces.
We observed deployment failures because of running wrong Jenkins jobs and scheduling of ARM64 based applications on AMD64 nodes.
To avoid hurdles in developer velocity, we followed an approach that, the minute an application is migrated successfully in stage, we focussed on migrating that application to production rather than focusing on other applications in stage.
Positive Impacts:
We have seen good performance improvements after moving into Graviton2. Here are a few examples:
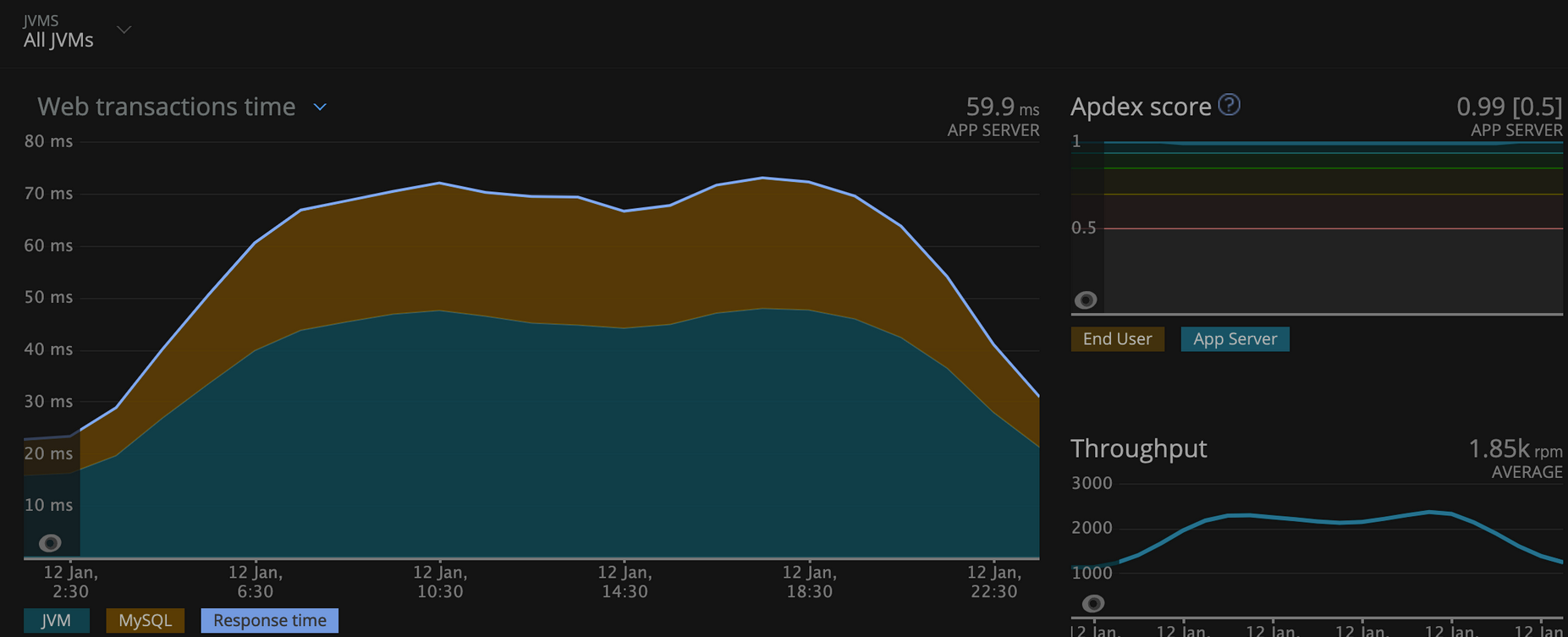
1.On AMD64 worker nodes:
On Gravtion2 worker nodes:
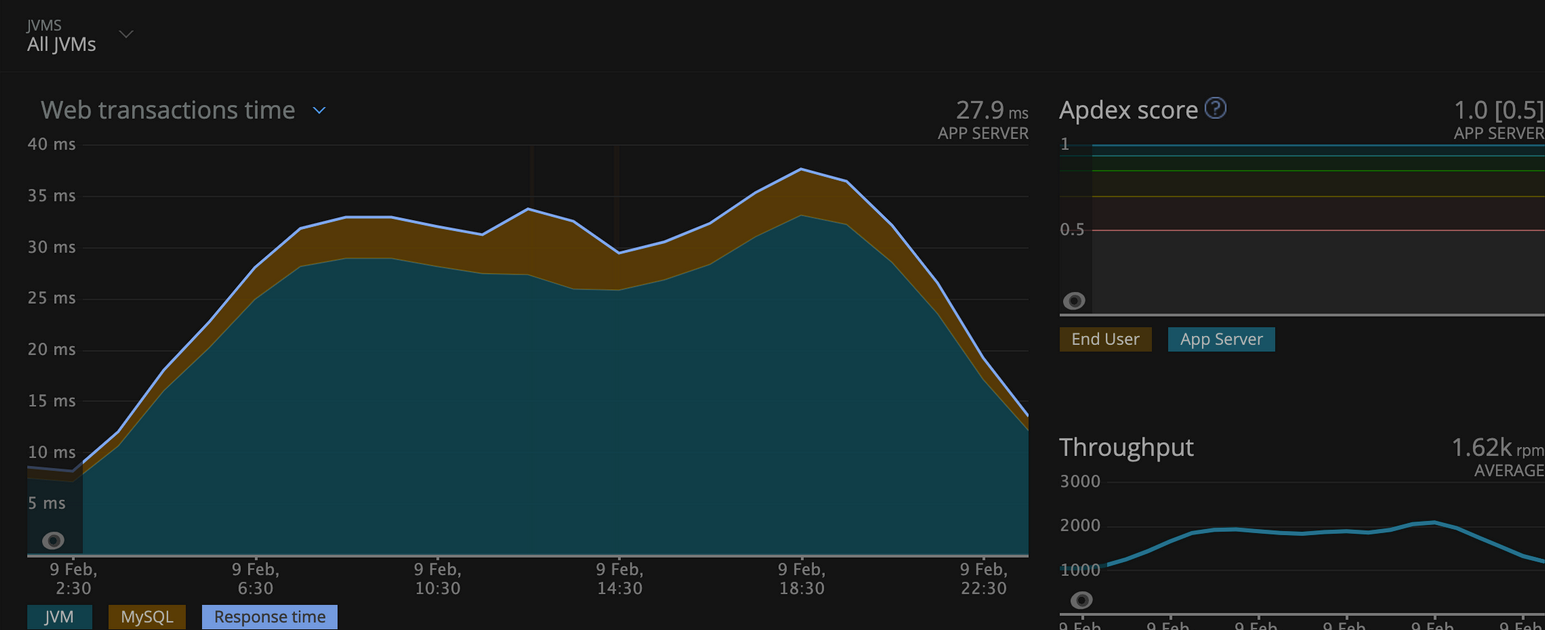
Observation: There is performance improvement in the service when moved to Gravtion2. The average web transaction time has been decreased by 46%.
2. On AMD64 worker nodes:
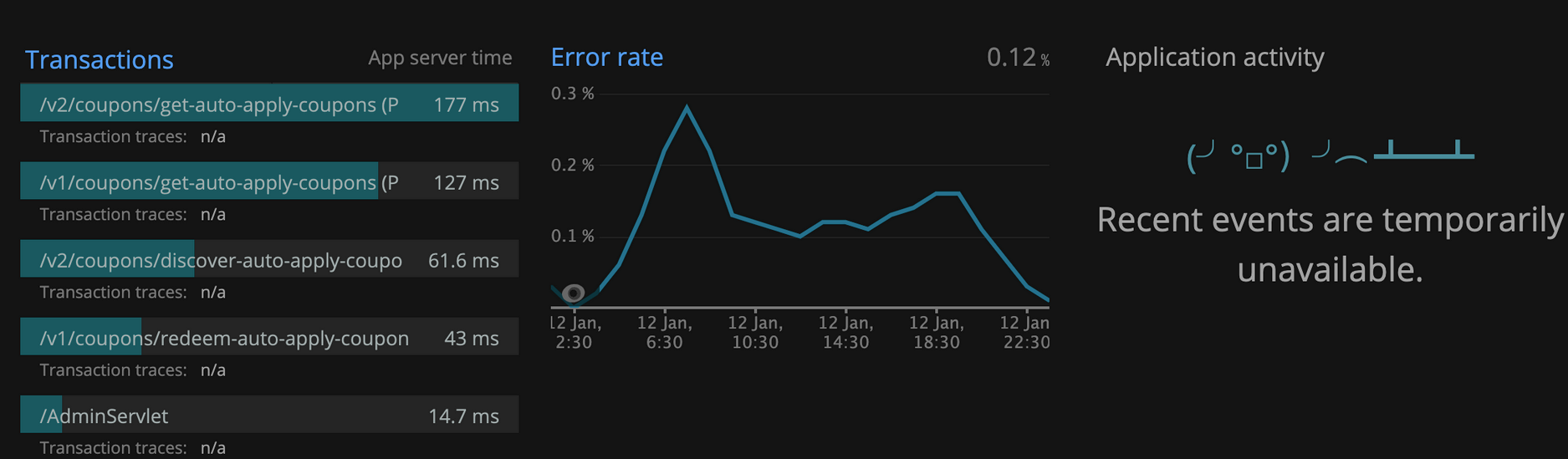
On Gravtion2 worker nodes:
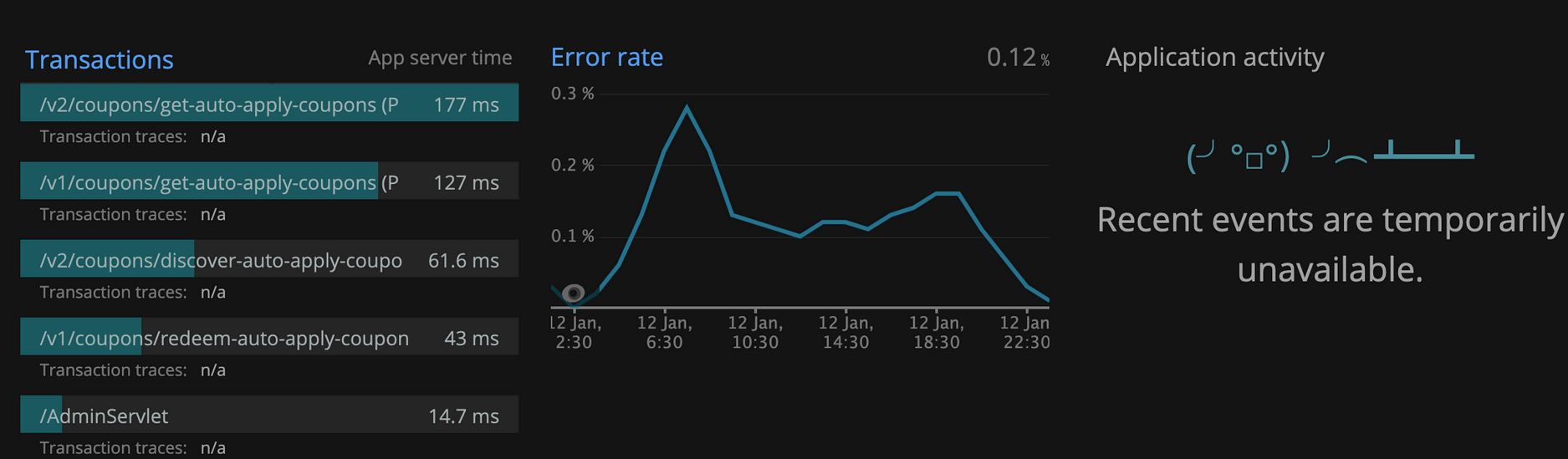
Observation: Graph shows performance improvement by moving into Gravtion2. /v2/coupons api response improve by 48%, /v1/coupons api response time improved by 56%.
3.On AMD64 worker nodes:
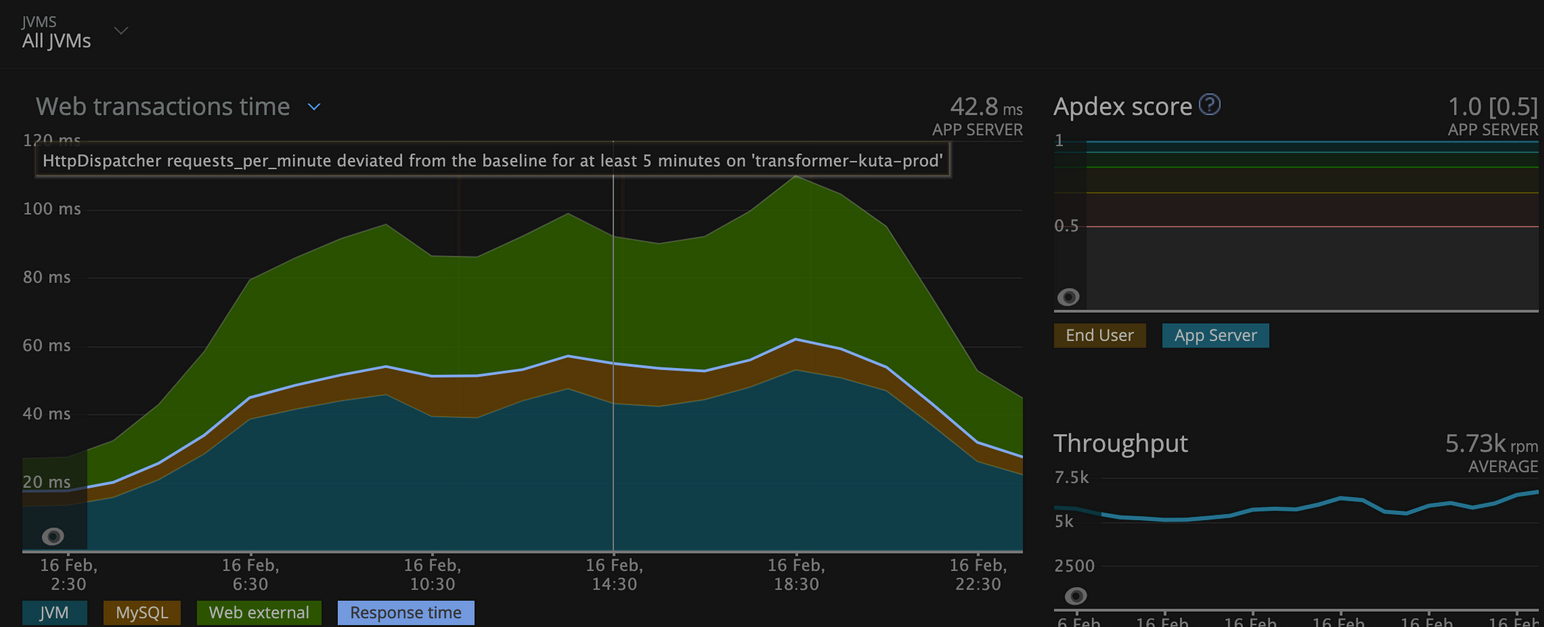
On Gravtion2 worker nodes:
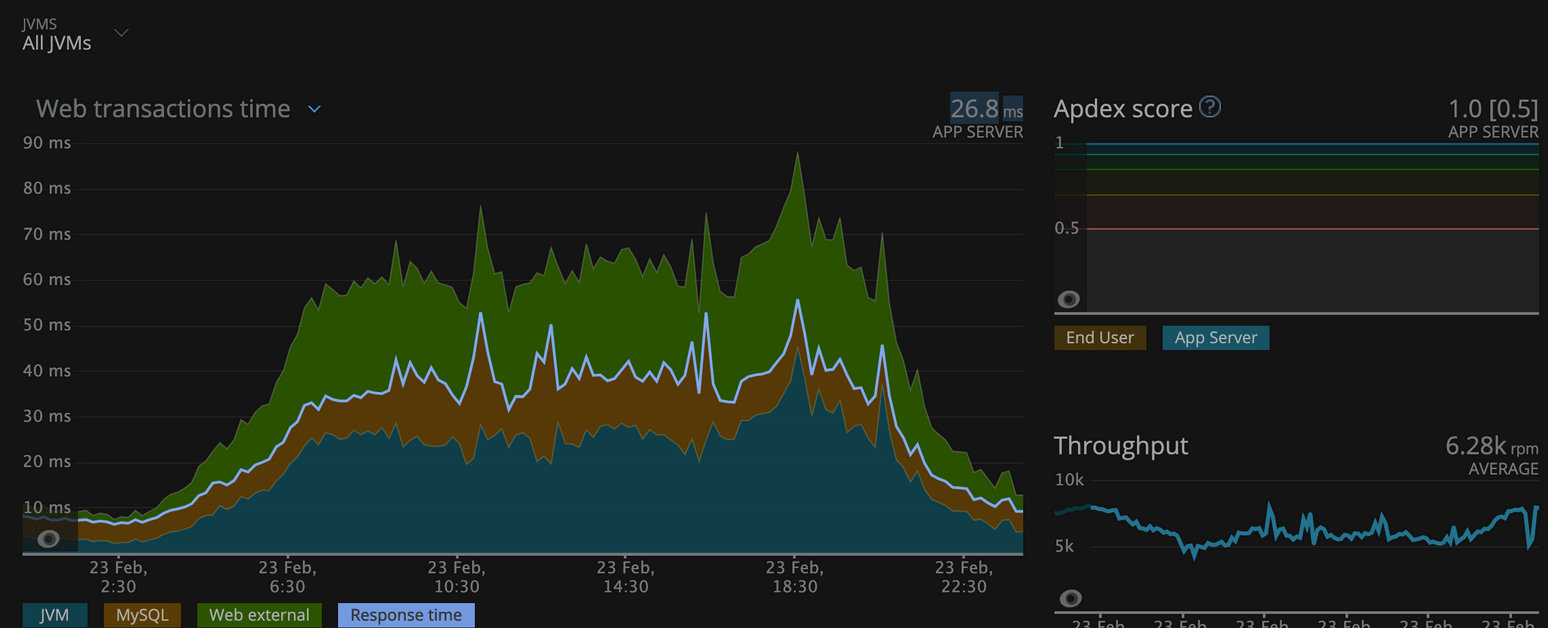
Observation: The average web transaction time has been decreased by 48%
Conclusion:
In this article, we have explained how we migrated workloads from AMD64 based to Graviton2 based nodes. That enabled better price-to-performance.
References:
https://github.com/aws/aws-graviton-getting-started/blob/main/containers.md
Join us
We are always looking out for top engineering talent across all roles for our tech team. If challenging problems that drive big impact enthral you, do reach out to us at careers.india@halodoc.com
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek and many more. We recently closed our Series B round and In total have raised USD$100million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


