

End-to-end data pipeline to query Clevertap events data using Athena/Redshift Spectrum
Data has always been a pivotal aspect of Halodoc's decision making. As the number of services on our platform grows, mapping a user's journey across the platform has become one of our most critical initiatives in the Data Engineering space. We started with understanding the user's buying behaviour and then bucketing them into cohorts. The next step, however, was to gain a better idea of the behavioural aspects of their sessions.
At Halodoc, we use Clevertap to retain user engagement in our platform. To get insights on the user's journey in its entirety, we need to merge Clevertap events data with our backend transactional data. Currently, all our transactional data relies on Redshift consolidating data from different micro services (TeleConsultation, Pharmacy Delivery, Appointments, Insurance, and so on).
Clevertap captures and stores the clickstream data, producing huge volumes of data on a daily basis. Loading this data directly to our Redshift cluster was very expensive as it needed the significant scaling of our existing Redshift cluster to accommodate it. So, instead, we planed to build a data lake where Clevertap events data can be stored in S3 and we leverage the features of Redshift Spectrum or Amazon Athena to query this data. Having Redshift Spectrum in place removed the need to have to load the data in Redshift while also be able to join the S3 data with other transactional data relying on Redshift.
How did we start to build a scalable end-to-end pipeline
We did a PoC on what data formats would be best suited for efficient processing and cost-saving in terms of storage. We decided to have parquet file format with some partitioning based on date (i.e year or month) for an efficient read while accessing the data. The reason for choosing parquet format was:
- Columnar storage brought efficiency in accessing the data compared to row-based storage like CSV or JSON.
- Supported flexible compression and efficient encoding schemes.
- Cost-saving as Athena/Spectrum charged based on the volume of data scanned.
Architecture
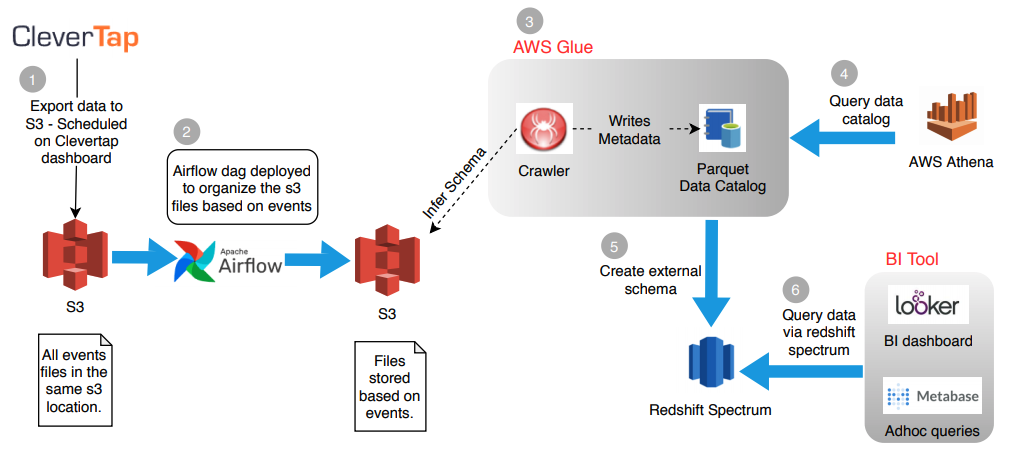
The above architecture depicts the end-to-end pipeline for exporting Clevertap data to S3 and making it queryable via Athena/Redshift Spectrum.
The high-level task includes:
- Scheduled data export from the Clevertap dashboard to S3.
- Airflow dag deployed to organise the files in the destination bucket.
- Created AWS Glue crawler to infer the schema that creates/updates the data catalog.
- Query data using either Athena/Redshift Spectrum.
The components involved are:
1. CleverTap
CleverTap enables you to integrate app analytics and marketing to increase user engagement.
Clevertap provides a feature to export the data directly to S3. The detailed documentation can be available here - Clevertap Data Export to S3.
2. Airflow DAG
Airflow is a platform to programmatically author, schedule and monitor workflows.
All events files were exported to an S3 folder for connecting to the Clevertap dashboard. It is not possible to crawl the data using AWS Glue if different schemas of files are present in the same S3 folder.
So we decided to write an Airflow DAG that could copy these files and organise in a manner that can easily be crawled and create a data catalog in AWS Glue. Since we need to deal with multiple projects in Clevertap comprising 100’s of events, we wrote a custom Airflow plugin that can organise the files based on event name when passed as a parameter in the Airflow custom operator.
The structure we followed is:
bucket_name/clevertap/project_name/event_name/year/month/yyyy-mm-dd.parquet
The steps involved:
- We fetched the S3 object for the particular event file.
- Once we get an S3 object, next step would be to pick the particular S3 file (organized by event_name for DAG run-day) and organize in the destination bucket.
- We provided a check and logged info to deal with DAG file load failures.
- Once source S3 key is identified, final step was to load the file to destination bucket.
3. AWS Glue
AWS Glue is a fully managed ETL (extract, transform, and load) service that makes it simple and cost-effective to categorize your data, clean it, enrich it, and move it reliably between various data stores and data streams.
Once files are structured in S3, we need to schedule a crawler that can infer the schema on a periodic basis and writes/updates the metadata to the data catalog.
- Crawler
Crawler infers the schema of the S3 data and writes the metadata to the data catalog, everytime new files are dropped in the corresponding S3 bucket. To control the data scanned, we started to create the data catalog based on request for the events by the end user. - Data Catalog
Data catalog stores the metadata and the schema details of S3 files. It provides the flexibility to edit the existing schema created by the crawler.
4. Athena
Athena is an interactive query service that makes it easy to analyse data directly in Amazon S3 using standard SQL.
AWS Athena was mostly used by our product and data teams for deriving data insights. In our case, since we have already created a data catalog for Clevertap events, we needn't have to manually create the table schema in the Athena console. One can directly connect to AWS Glue data catalog and can query the tables being listed in catalog.
Some of the features that attract us to use AWS Athena were:
- Easy to connect to the AWS Glue data catalog.
- Athena allows running
select * statement. It helps our product & data analysts to visualize the columns in the table easily. - Easy to query complex data type compared to Redshift Spectrum (i.e nested data, arrays, struct, map and so)
5. Redshift Spectrum
Redshift Spectrum is useful when you are already running the Redshift cluster in production. Since we rely heavily on Redshift to create dashboards and reports (on Looker or Metabase), it became so convenient to leverage the features of Redshift spectrum. With Redshift spectrum actually we have achieved separation of the storage(S3) and compute layers (Redshift engine), which enables us to scale both these tiers independently.Though we use Spectrum we encountered some challenges while querying S3 data.
- Redshift Spectrum doesn't allow to execute
select * statement. We need to specify the column_name in the select statement. - Redshift Spectrum has certain rules to execute complex data types - detailed here
We created an external schema on our Redshift cluster and provide select only access to the end-user.
create external schema schema_name
from data catalog
database 'database_name'
iam_role 'iam_role_to_access_glue_from_redshift'
create external database if not exists;
By executing the above statement, we can see the schema and tables in the Redshift though it's an external schema that actually connects to Glue data catalog.
6. BI Tool
At Halodoc, we have Looker and Metabase to create dashboards and reports for business stakeholders. Accessing S3 data using Looker was pretty easy as Looker already supports Redshift as a datasource. The advantage of the Redshift Spectrum over Athena for the BI team as they don't have to get the AWS console access.
Summary
In this blog, we provided insights on why and how we built an end-to-end data pipeline to query S3 data via Spectrum/Athena. We talked about AWS Glue and how one can create the crawler and data catalog on it. We deep dive into some of the challenges encountered during the pipeline set-up and how we resolved all.
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke.
We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 2500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allows patients to book a doctor appointment inside our application.
We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates foundation, Singtel, UOB Ventures, Allianz, Gojek and many more. We recently closed our Series B round and In total have raised USD$100million for our mission.
Our team work tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


