

Data Model Adoption at Halodoc
At Halodoc, we are always committed to simplifying the healthcare services for our end-users and the primary goal is to become a data driven organisation. In our previous blog we focused on bringing our data from various sources into the Data Lake as the first phase.In this blog we will go over some of the conceptual challenges for adopting a data model. Before deep diving into the details, we would like to explain the current nature of data that we get from the source
- We get multiple changes for a given transaction on a given day. For example, in payment transactions, we do receive multiple states for a single transaction.
- We receive lots of semi-structured data example columns in a nested format with key dimension attributes..
- We don’t have historical reference from the source for the catalogue/master tables example products, product group.
- We receive some descriptive information like speciality name and type in the transaction table and master catalogue table.
A look back at our previous Data warehouse:
With our previous platform, we faced a lot of challenges without adhering to any data model principles like
- Redundancy in the data marts, code base, multiple versions were created for the same business use cases by various operations.
- Increase the storage and compute, since every time a new table is created for every use case.
- There is no single place of truth, which is hard to govern.
Options:
As we started exploring multiple ways to organise the data in the MPP or distributed columnar database like Redshift, some of the options we had like
- Data Vault:
It requires more time to understand and implement, since the nature of the data model is complex, and the type of business operation requires data to be immediately available, which is not possible with this approach. - Flat or Denormalised structure:
From the previous experience we are sure not adopting the denormalised structure completely, but considering the nature of data and columnar storage, we decided to utilise it wisely for few business use cases like near real time reports. - Dimension Modelling
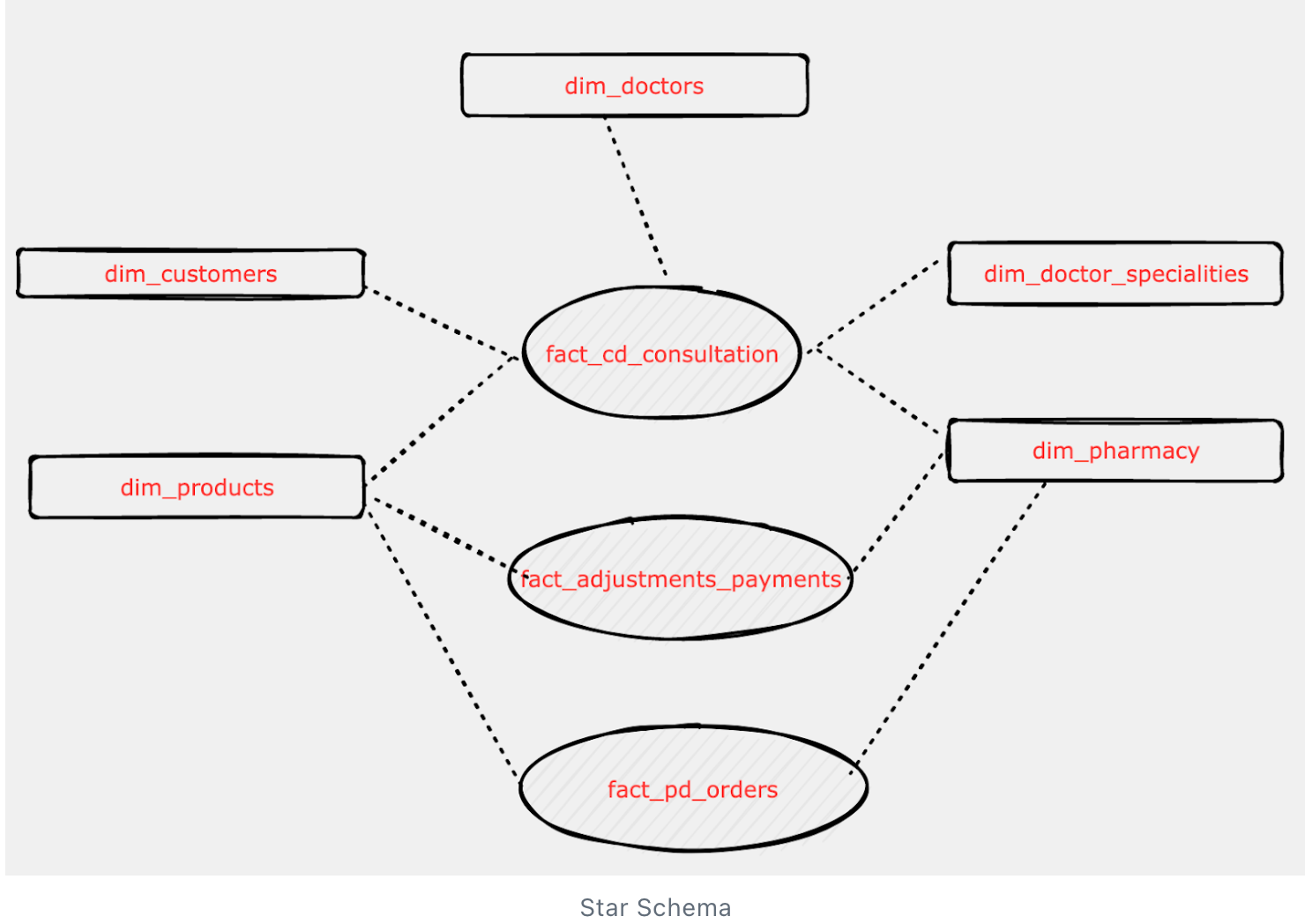
Star Schema
SnowFlake schema
We choose dimension modelling as fundamental layer for our data warehouse because,
* To provide database architecture that is easy for end clients to understand and write queries.
* To maximise the efficiency of queries. It achieves these goals by minimising the number of tables and the relationships between them.
* To have better visualisation and maintainability like slowly changing dimension (SCD’s).
* To provide better governance and maintain a single place of truth, like having those conformed dimensions.
* To provide pre-aggregated measures in the form of summary table, star schema gives a good shape to the data.
* Redshift provides Materialised view, which is incremental in nature and reduces the need for maintaining scheduler.
* To organise our dimension and fact table with proper distribution key and sort key, the queries required to create the star schema model becomes more efficient in redshift.
Trade off:
We went with a Hybrid Data model with a combination of Dimensions, Facts and denormalised structure. In order to achieve this, we need to compromise on some of the features of the dimensional modelling techniques specifically the star schema model, due to the nature of the data and utilise the advantages of columnar database like
- We are not generating any surrogate keys as our natural keys are numeric/hexadecimal from the source.
- Maintain some dimensional attributes in the fact table as we receive some attributes at the transaction level. This would avoid the need for surrogate keys in the fact tables.
- We are not having any descriptive value like Email id as the natural key, instead our source system is providing the hexadecimal keys.
- We are not implementing late arriving dimensions as we refer to transactions and catalogues to build the dimensions. Assign to unknown if incase we receive orphan transactions.
Example :
Doctor Id and speciality creates composite keys and provides a unique dimension attribute for a given fact transaction. Ideally composite keys are helping us to maintain our star schema.
Data Model Use case:
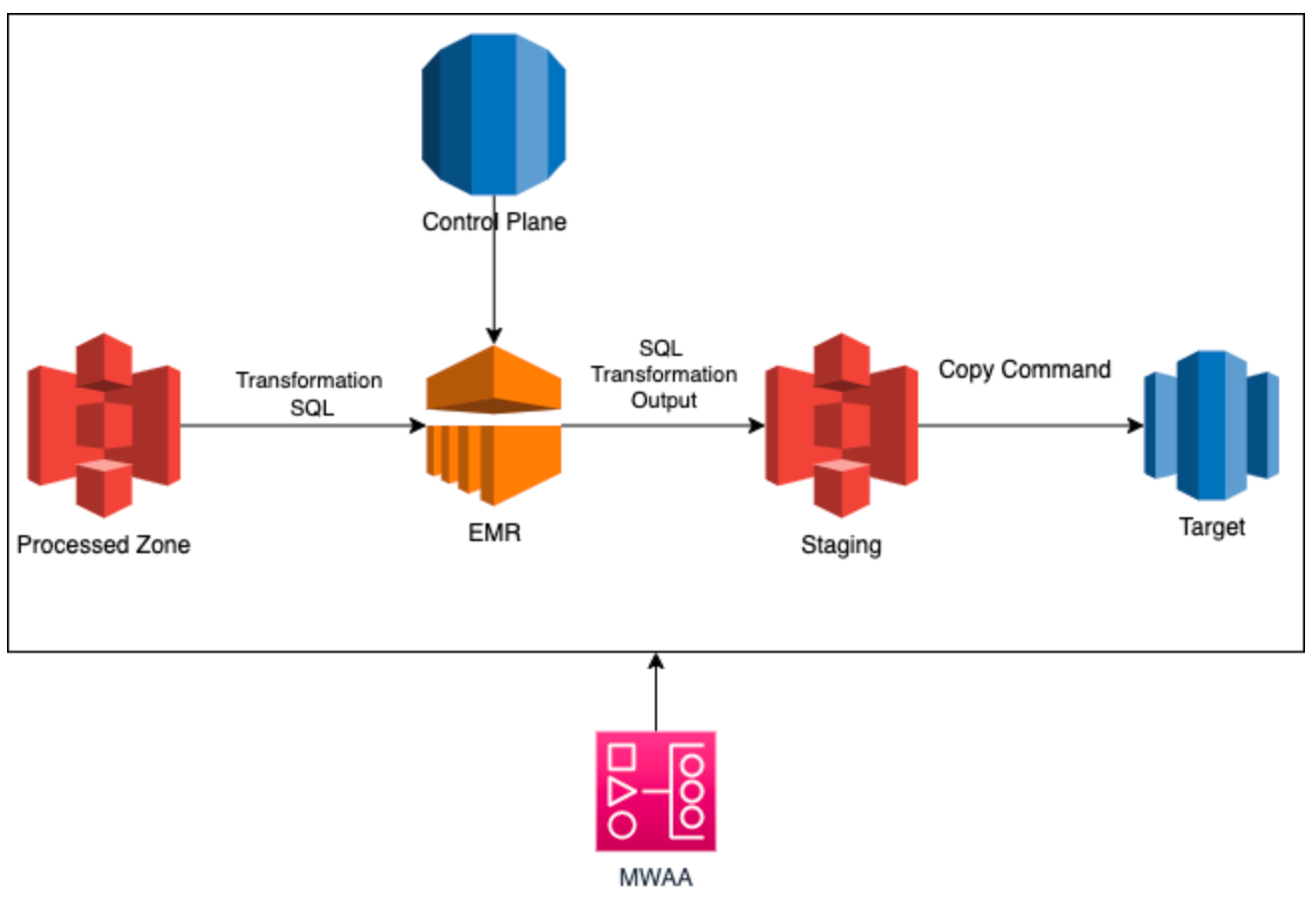
Current stack :
We have introduced several components and features to build the data warehouse with conscious effort to separate the compute and storage.
- AWS Elastic Map Reduce (EMR)
To perform transformation using spark SQL - AWS S3
To store result of transformation process - AWS Redshift
Target result of dimension and fact table - AWS Managed Workflow for Apache Airflow (MWAA)
To orchestrate the pipeline
What’s next:
In the upcoming blogs, we will be discussing on building a data democratised self-service platform to onboard the new data assets. Some of the challenges faced while implementing the framework driven architecture to onboard various layers of our Data warehouse, such as Dimensions, Facts, Summary and the control planes for ETL operations
Summary :
In this blog, we have shared how we adopted a Hybrid data model based on the nature of data. However there is no best fit data model, and it varies depending on the nature of data and the business problem we are trying to solve. Hence this would be evolving along with new features as the data grows.
Join us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek and many more. We recently closed our Series C round and In total have raised around USD$180 million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


