Reducing Amazon EKS Compute Costs by 35%: Migrating Production Workloads from Graviton3 to Graviton4
At Halodoc, compute efficiency is driven first by performance at scale. As a platform serving millions of healthcare interactions, our priority is to deliver consistently low latency and stable service behavior under highly variable traffic patterns.
As part of our natural infrastructure upgrade cycle, we evaluated opportunities to improve performance and efficiency without compromising reliability. This assessment led us to upgrade our Amazon EKS worker nodes from AWS Graviton3 (Gv3) to AWS Graviton4 (Gv4).
This blog walks through why we did the migration, how we validated it using real production signals, and what tangible outcomes were observed across performance, resource efficiency, and cost.
Why Look Beyond Graviton3?
Graviton3 has been a strong foundation for us, delivering reliable price-performance improvements over earlier generations and establishing a stable baseline for our Kubernetes workloads at scale.
AWS positions Graviton4 as a significant generational upgrade in ARM-based compute, with improvements across CPU efficiency, memory bandwidth, I/O performance, and platform-level security.
Rather than evaluating these improvements in isolation, our focus at Halodoc was to understand whether Graviton4 could help us serve more requests per unit of compute, maintain predictable latency during traffic spikes, and unlock efficiency gains that translate into tangible platform-level impact.
Our Evaluation Approach
Rather than relying solely on vendor benchmarks, we independently validated Graviton4 under our own workloads using a two-phase evaluation model to build confidence before production adoption.
- Hardware-level benchmarking
Validating raw CPU, memory, and disk I/O gains in a controlled environment - Application-level benchmarking
Measuring how real services behave under production-like traffic, using identical resource constraints.
We moved toward production only after both phases consistently demonstrated measurable and repeatable improvements.
Phase 1: Hardware Benchmarking using Sysbench
To establish a baseline for raw hardware capabilities, we began with Sysbench, a widely used, open-source benchmarking tool designed to evaluate CPU, memory, and disk I/O performance in a controlled and repeatable manner.
Result Analysis
- CPU throughput improved by ~28%, increasing from ~403k events/sec (Graviton3) to ~516k events/sec (Graviton4), reflecting higher core density and more efficient compute pipelines.

- Memory bandwidth increased by ~64%, improving from ~212 GB/s (Graviton3) to ~348 GB/s (Graviton4), indicating substantially better performance for memory-intensive workloads.

- Disk I/O throughput improved by ~60% for reads and ~63% for writes, rising from ~128 → ~205 MB/s (read) and ~84 → ~137 MB/s (write), highlighting gains in storage and I/O efficiency.

These results demonstrated that Graviton4’s architectural enhancements consistently delivered measurable hardware-level gains, establishing a reliable baseline for application-level validation.
Phase 2: Application-Level Benchmarking using JMeter
Hardware gains only matter if applications can convert them into real outcomes.
In this phase, we benchmarked a service running in a stage environment using two long-running APIs under controlled throughput, with identical traffic profiles and a gradual load increase from 1k to 10k TPS to observe steady-state behavior.
What changed?
At 1,000 TPS, Graviton4 immediately demonstrated higher efficiency:
- API latency improved from ~150 ms (Gv3) to ~84 ms (Gv4)
- CPU utilization reduced from ~50% to ~30%
- Memory utilization reduced from ~28% to ~23%
- Zero errors and no pod restarts on both platforms
As load increased beyond 4,000 TPS, the difference became more pronounced:
- Graviton3 began to saturate, showing memory exhaustion, rising error rates, and pod restarts under sustained pressure
- Graviton4 maintained stability longer, with lower resource utilization, fewer errors at equivalent load, and no pod restarts
Comparison Chart
| Metric | Graviton3 | Graviton4 |
|---|---|---|
| Tested Throughput | 1k – 10k TPS | 1k – 10k TPS |
| Peak CPU Utilization | ~82% | ~76% |
| Peak Memory Utilization | ~100% | ~52% |
| Error Rate at High Load | Up to ~72% | Up to ~54% |
| Simple Test API 1 p99 (High load) | ~70 s | ~30 s |
| I/O Intensive Test API 2 p99 (High load) | ~95 s | ~65 s |
| Pod Restarts | 3 restarts observed beyond 4k TPS | 0 restarts across all tested loads |
Key Observations
- Graviton4 consistently processed the same traffic with lower CPU and memory utilization
- Error rates and pod restarts appeared later and at higher throughput levels on Graviton4 compared to Graviton3.
- Long-running APIs showed more predictable latency behavior under sustained load
The Bigger Win: Resource Right-Sizing
The most compelling insight didn’t come from raw performance, but from efficiency tuning. Once we observed the performance headroom provided by Graviton4, we shifted focus from "how fast can it go" to "how efficiently can it run at steady state".
Benchmarking CPU and Memory Reductions on Graviton4
To validate safe resource reductions on Graviton4, we ran additional benchmarks by systematically adjusting pod-level CPU and memory limits while keeping traffic patterns constant.
Each configuration was tested under sustained load on like-for-like instance sizes (c7g.4xlarge vs c8g.4xlarge), and evaluated across key production signals including API latency (p95), error rates, and resource utilization.
| Reduction Band | Observed Behavior |
|---|---|
| −10% CPU / −10% memory | Identical throughput and latency with healthy resource headroom |
| −15% CPU / −10% memory | Stable throughput and latency under sustained load, no error amplification, and sufficient headroom |
| −15% CPU / −15% memory | Stable at moderate load, early saturation signals under sustained peak |
| −20% CPU / −20% memory | Elevated latency and error rates under high throughput |
Based on these results, we observed a 15% CPU and 10% memory reduction offered the optimal balance between efficiency and stability.
Strategic Adoption & Cost Analysis
Our evaluation identified two distinct strategies for adopting Graviton4:
- Performance-first: These workloads keep resource allocations constant, accept the marginal cost increase, and gain the benefit of lower latency and better burst handling.
- Cost Impact: ~10% increase in compute cost.
- Cost-efficiency-first: These workloads reduce CPU and memory allocations based on the right-sizing data, maintain their existing performance, and achieve measurable cost savings.
- Cost Impact: ~15% reduction in compute costs with unchanged performance
Most of our workloads naturally fall into Cost-efficiency-first category, making Graviton4 a compelling default choice for EKS-based microservices.
This analysis confirms that combining the move to Graviton4 with systematic resource right-sizing is the key to achieving a net reduction in compute spend while simultaneously improving performance and reliability characteristics.
How We Rolled Out Graviton4 in EKS (Zero-Downtime Migration)
We migrated to Graviton4 by evolving our existing EKS node pools, rather than introducing parallel or shadow pools. This approach kept the rollout simple, low-risk, and fully aligned with our existing autoscaling and scheduling model.
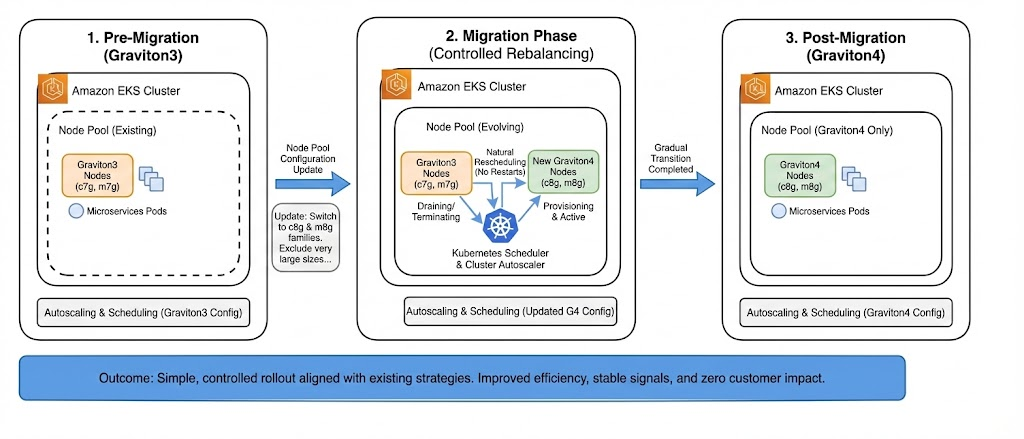
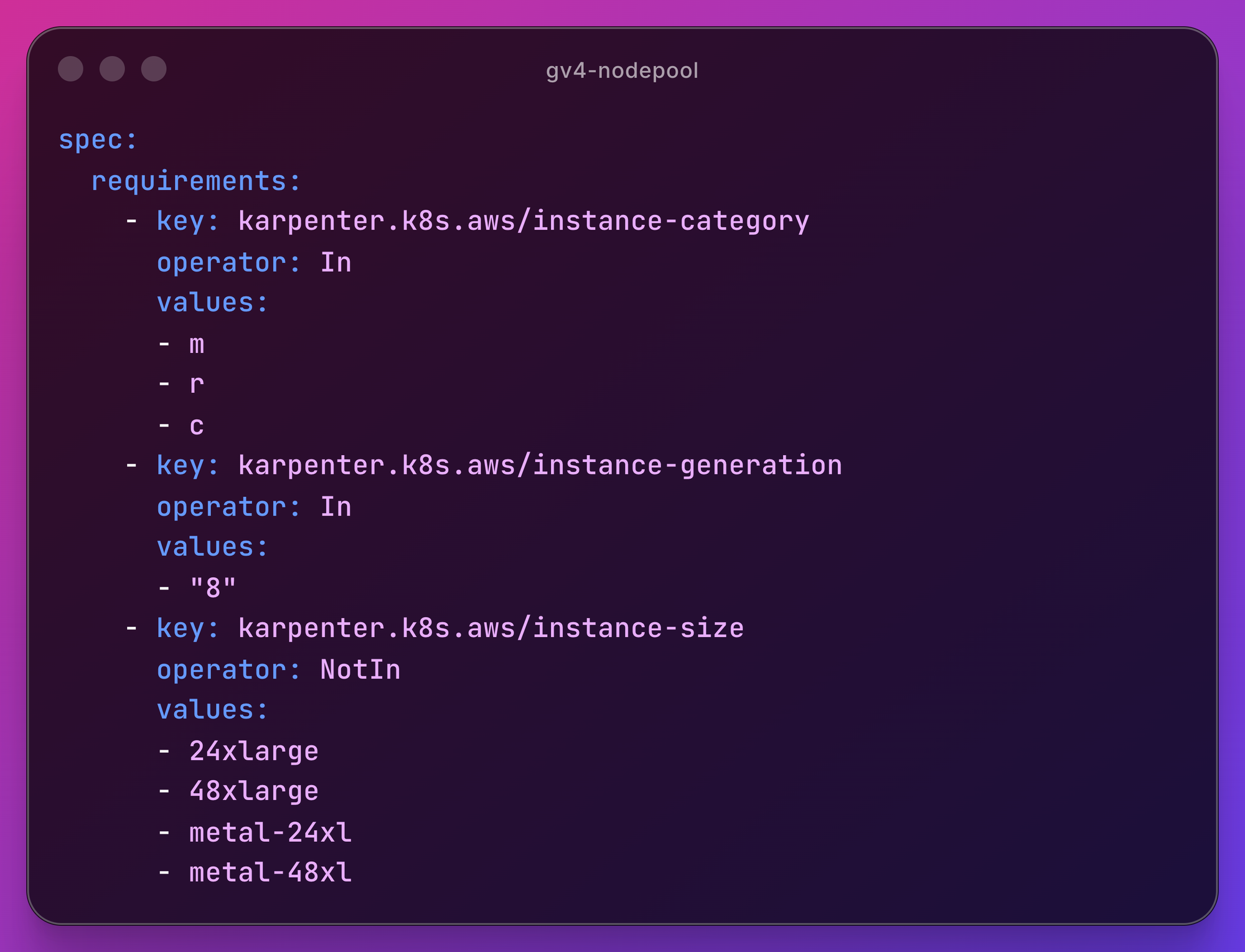
NodePool Updates
We updated the existing node pool configuration to move from Graviton3 to Graviton4 instance families.
To improve efficiency, we intentionally excluded very large instance types (e.g., 24xlarge, 48xlarge), which helped us avoid underutilization caused by oversized nodes and enabled more predictable autoscaling and faster scale-downs.
Controlled Rebalancing
Once the node pool definitions were updated:
- New capacity was provisioned using Graviton4 instances
- Existing Graviton3 nodes were gradually drained as part of normal scaling activity
- Workloads naturally rescheduled onto Graviton4 nodes without application-level changes
This enabled a zero-downtime migration with no service restarts or customer impact.
Post-Migration Validation and Resource Optimization
After updating the instance family in the existing node pools, we deliberately paused any resource changes for one week. This allowed workloads to fully stabilize on Graviton4 and ensured that baseline performance, error rates, and saturation metrics were well understood under real production traffic.
Only after this observation window did we proceed with CPU and memory right-sizing, driven directly by benchmarking results and live production signals. Resource reductions were applied incrementally, validated against latency, throughput, error rates, and autoscaling behavior to ensure there was no regression in service quality.
This phased approach helped us decouple infrastructure change from application tuning, reducing risk while maximizing the efficiency gains unlocked by Graviton4.
Cost Impact
As a direct outcome of this phased optimization, we achieved ~35% cost savings without sacrificing performance or reliability.
Resource right-sizing combined with node consolidation reduced overall fleet capacity, resulting in a ~40% reduction in EKS node count. This consolidation directly drove a ~32% reduction in aggregate CPU capacity and a ~30% reduction in memory footprint, while also delivering ~20% lower EBS costs due to the reduced number of nodes.
Importantly, these savings were achieved only after services demonstrated sustained stability under real production traffic, ensuring cost optimization never came at the expense of user experience.
Closing Thoughts
This migration wasn’t about chasing newer hardware; it was about making data-backed infrastructure decisions.
By grounding our approach in real benchmarks and production-like traffic, we ensured that performance improvements translated into meaningful platform-level efficiency and long-term sustainability. For services that retained their existing resource allocations, Graviton4 delivered clear gains in performance and stability, with a modest increase in cost. For services that adopted resource right-sizing, the same performance levels were preserved while unlocking tangible and sustainable cost savings.
For teams running Kubernetes at scale, Graviton4 is no longer an experiment it’s a strategic lever.
Join us
Scalability, reliability, and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels, and if solving hard problems with challenging requirements is your forte, please reach out to us with your resume at careers.india@halodoc.com.
About Halodoc
Halodoc is the number one all-around healthcare application in Indonesia. Our mission is to simplify and deliver quality healthcare across Indonesia, from Sabang to Merauke.
Since 2016, Halodoc has been improving health literacy in Indonesia by providing user-friendly healthcare communication, education, and information (KIE). In parallel, our ecosystem has expanded to offer a range of services that facilitate convenient access to healthcare, starting with Homecare by Halodoc as a preventive care feature that allows users to conduct health tests privately and securely from the comfort of their homes; My Insurance, which allows users to access the benefits of cashless outpatient services in a more seamless way; Chat with Doctor, which allows users to consult with over 20,000 licensed physicians via chat, video or voice call; and Health Store features that allow users to purchase medicines, supplements and various health products from our network of over 4,900 trusted partner pharmacies. To deliver holistic health solutions in a fully digital way, Halodoc offers Digital Clinic services including Haloskin, a trusted dermatology care platform guided by experienced dermatologists.
We are proud to be trusted by global and regional investors, including the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. With over USD 100 million raised to date, including our recent Series D, our team is committed to building the best personalized healthcare solutions and we remain steadfast in our journey to simplify healthcare for all Indonesians.