Transitioning from Elasticsearch to AWS OpenSearch
Overview
Elasticsearch is a highly scalable analytics and full-text search engine. It allows for the quick and nearly instantaneous searching, storing and analysis of large volumes of data.
At Halodoc, Elasticsearch was primarily used for serving better search results related to doctors, medicines, hospitals, etc. to the end-user via the powerful search capabilities of the cluster. This blog will provide insights about the migration from AWS Elasticsearch cluster version 6.4 to AWS OpenSearch version 2.9.
Motivated by a hunger for technological advancement
As pioneers in the healthcare industry, our aim is to adopt cutting-edge technologies that offer superior performance benefits while keeping our tech stack modernised.
Our Elasticsearch cluster was a managed service using AMD based compute and running version 6.4 with one year reserved instance (RI). This version did not support Graviton-based instances. In order to capitalise on the cost and performance advantages of the latest generation of Graviton instances, which offer larger cache sizes and up to 20% lower costs compared to previous versions, we've decided to upgrade our cluster to a version greater than 7.x, as our current version lacks support for Graviton-based instances. Currently, over 90% of our workload runs on Graviton instances, which provide up to 40% better price performance compared to older instances.
We had to migrate or upgrade the Elasticsearch cluster before the RI expiry to avoid paying more for the non-graviton instances or buying new RI for the existing non-graviton instance cluster, which would make us wait for another year for the upgrade since the minimum period for RI is one year, non-cancellable.
Why OpenSearch instead of Elasticsearch?
Elasticsearch has modified its licensing, and the upgraded version is not available as an AWS managed service. The Licensing changes restrict AWS from reselling Elasticsearch as a managed service. Hence, AWS forked the project and started developing their own version of it called OpenSearch. AWS OpenSearch will be a fully open-source project that is licensed under the Apache v2.0 license.
To transition to a higher version of Elasticsearch, we must migrate from our current AWS cloud-managed service to a Elasticsearch SaaS sloution via AWS Market place or to a self-hosted solution. Additionally, Elasticsearch is more expensive than OpenSearch as a managed service.
More details about the Elasticsearch managed version and pricing can be found here.
The primary motivation to run our workload as a managed service is to do away with the overhead of security patches, monitoring aspects, and the effort required for maintaining a self-hosted cluster so the team can concentrate on other business needs. Considering the benifits of managed service and the cost for SaaS solution, the plan to go with a self managed version and SaaS of Elasticsearch was dropped. Hence, we decided to go with AWS OpenSearch(v2.9) as a managed service on reserved graviton2 instances (RI).
Decoding the OpenSearch Migration Journey: Triumphs and Trials
Java is a major tech stack that we use in our organisation. Both Elasticsearch and AWS OpenSearch support integration with Java based applications with the help of clients.
Instead of using HTTP methods and raw JSON to communicate with clusters, we can use Java methods and data structures with the OpenSearch Java client SDK. Using the built-in methods of the client, we can use objects to make requests to our cluster in order to add data to documents, build indexes, or do other operations.
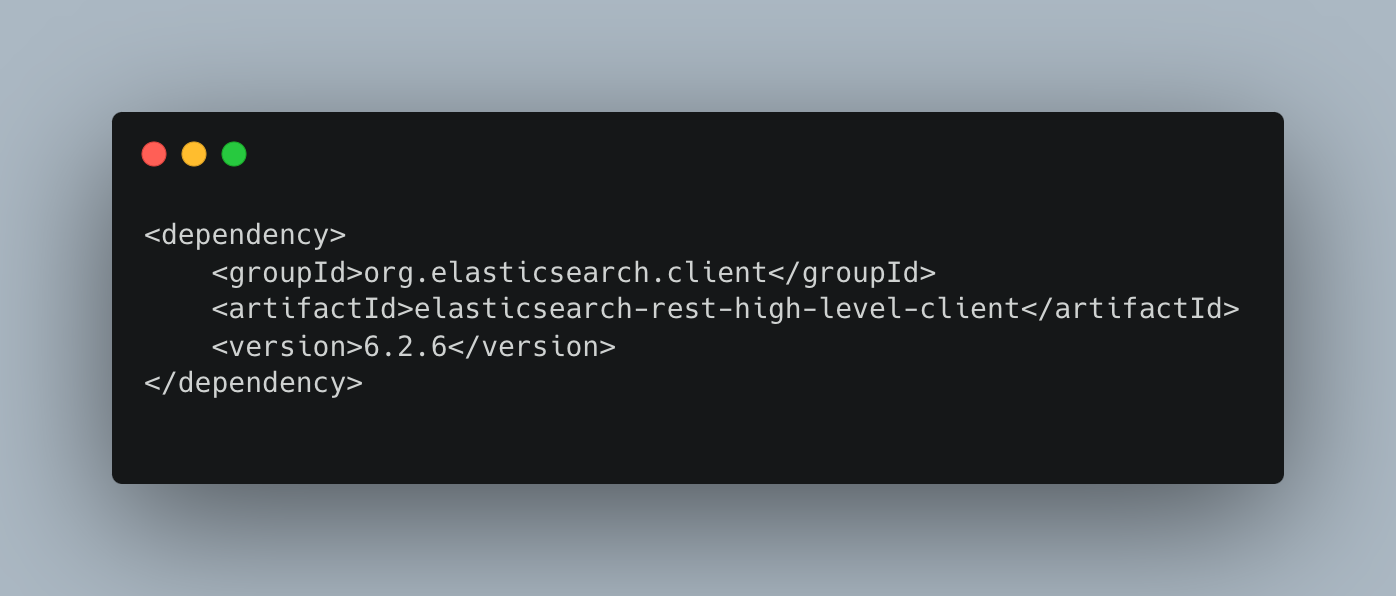
The illustration below displays the dependency we were utilising while we were running the Elasticsearch cluster.
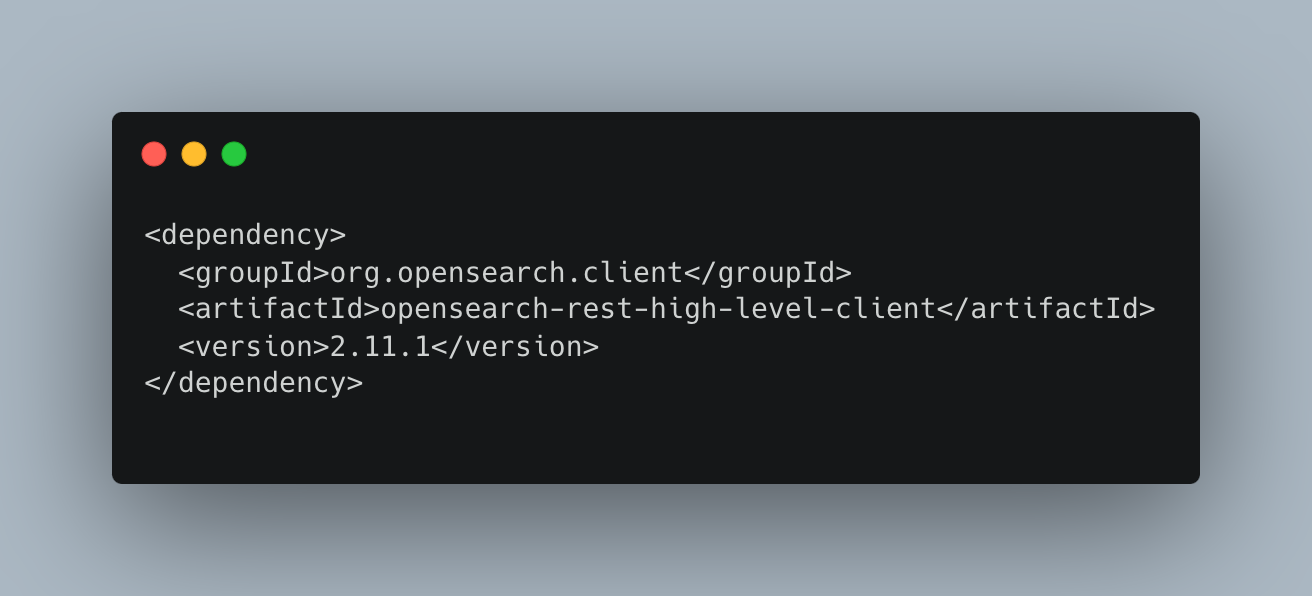
AWS OpenSearch provides high-level rest client dependencies through which we can easily migrate to the OpenSearch cluster with minimal code changes, and major changes are only in the import section of the class.
However, this dependency will be deprecated in a higher version, as mentioned in the official documentation, so we decided not to go with it.
AWS provides 3 sets of transport clients for Java through which we can establish connection to OpenSearch.
- RestClient Transport
- Apache HttpClient5 Transport
- AWS SDK2 Transport
RestClient Transport: This will be deprecated in upcoming versions of OpenSearch (v3.0.0) and thus we decided not to opt for this dependency.
Apache HttpClient5 Transport: With required code changes we went with this option. We observed that with this particular client the memory utilisation of applications was going higher. We found that org.opensearch.client.transport.httpclient5.internal.HeapBufferedAsyncResponseConsumer this particular class was retaining more memory.
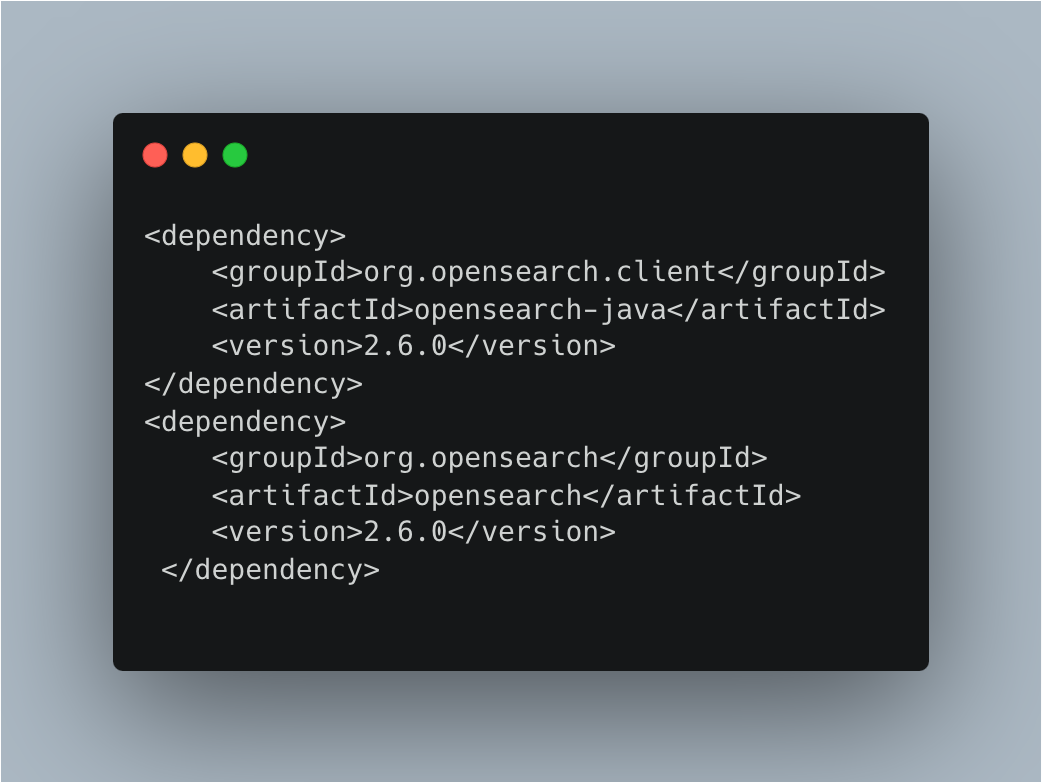
After this evaluation, we tried using AWS SDK2 Transport for communicating with OpenSearch, which worked very well for our use case where it reduced the response time very much than the older approach and kept memory utilisation under control. The illustration below displays the library dependency we were utilising in pom.xml
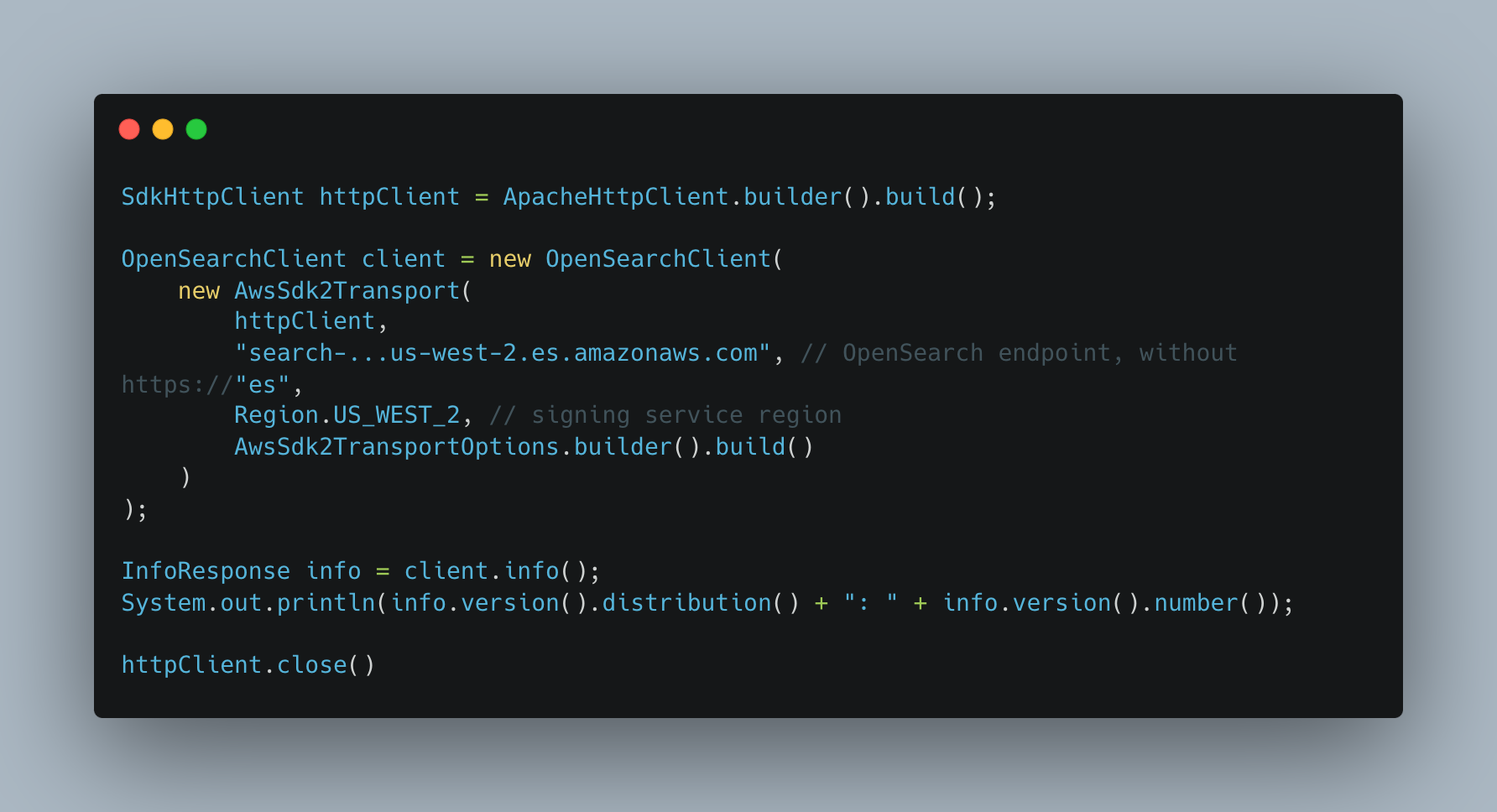
Sample code block to connect with AWS OpenSearch cluster is shown as below.
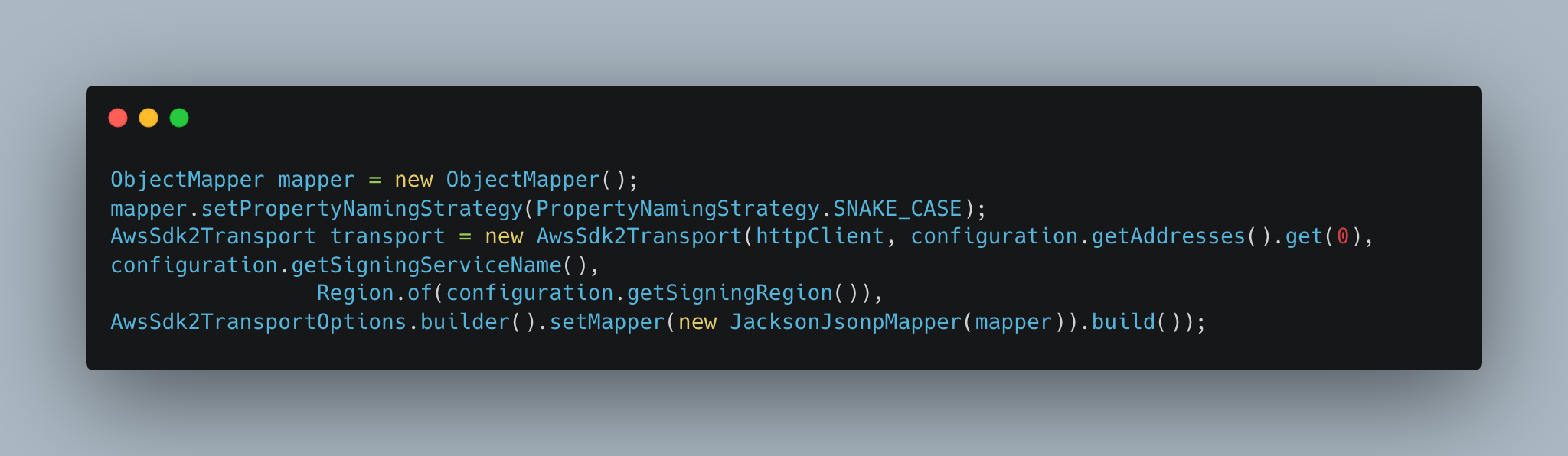
To have a uniform naming convention for all the fields of the document we use a custom mapper while building the transport client as illustrated below.
More details about creating the index and other operation is available in AWS OpenSearch official documentation
Things to consider while updating from an older version of Elasticsearch to a more recent version of Opensearch
-
The configuration of the default mapping feature is removed from higher versions of Elasticsearch and OpenSearch, which were present until Elasticsearch v7.0 and below. More details on it can be found here
-
Total hits defaulted to 10000:
OpenSearch will not show the hit count more than 10000 to gain more performance benefit whenever we have a large set of documents which is part of the query response. OpenSearch can now skip calculating scores for records that are identified at an early stage as records that will not be ranked at the top of the result set.
This feature was also introduced in Elasticsearch version 7.0. -
In older versions of Elasticsearch we can use matchphrase query against keyword type as well, but in OpenSearch versions, we can’t use matchphrase query against the keyword type as it throws an error if we go with it. matchphrase query can be used only with text fields in OpenSearch.
-
The mmapfs directory is one of the store types in Elasticsearch. It is used to store the shard data. It uses mmapfs to map files into memory, which allows Elasticsearch to access data within the files as if they were in memory.
In OpenSearch, the equivalent of the mmapfs directory type is the hybridfs directory type, which is the default directory type. It uses a hybrid of mmapfs and niofs to store the shard data. -
Elasticsearch's high level rest client was returning an empty list if the search query is not able to retrieve any documents, in newer versions of OpenSearch it throws error status code 404 instead of returning empty list. We need to be careful about these small changes while migrating to a new client.
Along with these we need to change the code to communicate with OpenSearch a lot to be compatible with the cluster as we are moving to a totally new client and we need to be careful about the new API’s which is part of the OpenSearch SDK.
For production deployment, we went with a canary approach for rolling out the changes to avoid issues that cause business impact.
What other steps we took to enhance the performance?
We evaluated the count of our index shard before migrating to the OpenSearch cluster, to optimise cluster performance.
We were running with the default 5 shard per index in our previous Elasticsearch cluster.
Shards can’t be reduced once the index is created. If we want to change the shard count of an index, we need to create a new index. This can be achieved by using the clone API of the cluster.
When index data size is less and expected to have more reads as compared to writes it is better to go with fewer shards and more replicas count as compared to having more primary shards.
The overall goal of choosing a number of shards is to distribute an index evenly across all data nodes in the cluster. However, these shards shouldn't be too large or too numerous.
For workloads where search latency is a critical performance goal, a common rule of thumb is to aim for shard sizes between 10–30 GiB, and between 30 and 50 GiB for workloads that need a lot of writing, such log analytics. Additionally, for a given node, limit the number of shards per GiB of Java heap to 25.
Conclusion
The decision to upgrade from Elasticsearch cluster version 6.4 to AWS OpenSearch version 2.9 was driven by our goal to keep up with technological advancements.
We encountered some challenges, notably with the new Java client for OpenSearch, which required adjustments due to behavioural changes.
Additionally, optimising cluster shards and integrating Graviton2 instances helped improve performance. Overall, this move resulted in a significant decrease (36%) in expenses compared to our previous Elasticsearch setup.
In essence, it highlights the importance of considering newer software versions for improved performance and cost savings.
References
OpenSearch github PR for RestClientTransport deprecation
Elasticsearch 7.0.0 release notes
Join us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the pioneer of a digital health ecosystem with a mission to simplify healthcare access by addressing users’ pain points through accessible, reliable, and quality services. The company’s commitment to promoting wellness is reflected in the comprehensive range of health solutions, covering preventive to curative approaches, all within a single application.Since 2016, Halodoc has been enhancing health literacy in Indonesia through user-friendly healthcare Communication, Education, and Information (KIE). Our expanding ecosystem offers a range of convenient healthcare services, including Home Lab for home care health test; My Insurance for seamless access to cashless outpatient service benefits; Chat with Doctor teleconsultation with 20,000+ licensed doctors and health workers; as well as Health Store for access to purchase medicines, supplements, and various health products from 4,900+ trusted partner pharmacies. Halodoc has been recognized as one of a telehealth platform making a positive impact on the healthcare sector and received the “supervised” status in the Regulatory Sandbox program by the Ministry of Health of the Republic of Indonesia. It reflects a strong commitment and partnership between Halodoc and the MoH, ensuring participatory supervision to safeguard Digital Health Innovation (IDK) organizers, consumers and healthcare workers as the partner of digital innovations. The platform has also received a string of prestigious awards, including being featured on CB Insights’ Digital Health 150 list in 2019–2020 and receiving the Indonesian government’s 2023 PPKM Award.Download Halodoc app via iOS and Android.