

Slow Changing Dimension Type 2 for Hybrid Model of Dimensional Modelling
Here in Halodoc we always pursue better insights to improve our end users’ experience through data-driven analysis.
As explained in our previous blog on our data model, we have adopted a Hybrid Model of dimensional modelling for our data warehouse layer. This model consists of Dimension, Fact, and denormalized tables to allow flexibility in handling our raw data's natural behaviour and our business use cases. In this blog, we will show how this model allows the operation and business team to benefit from the flexibility of this model to obtain snapshot data through Slowly Changing Dimensions Type 2 (SCD2).
What is an SCD2 Table?
SCD2 is a dimension that stores changes in the data over time. Some of its features are as follows:
- Every version of data is stored in a single row, recording all versions of the data.
- Each row can also be accompanied by a timestamp that reflects when the pipeline captures the change and if another change occurred, the time of the next change could be captured as well.
- The latest version of the data can be indicated by a binary label e.g. current ‘Y’, past versions ’N’.
- Depending on the business use case, not all attributes of the data must be used to trigger the creation of a new record; instead, a few attributes of interest can be chosen so that new rows are only created when there is any change in any of them.
- Some use cases are:
- Tracking the changes in the product price for analysis
- Tracking the changes in doctors’ or medical tests’ availability to track the availability based on specialties or other categories.
- Improve analyses on users’ points usage behaviour.
How SCD2 Works
(A)
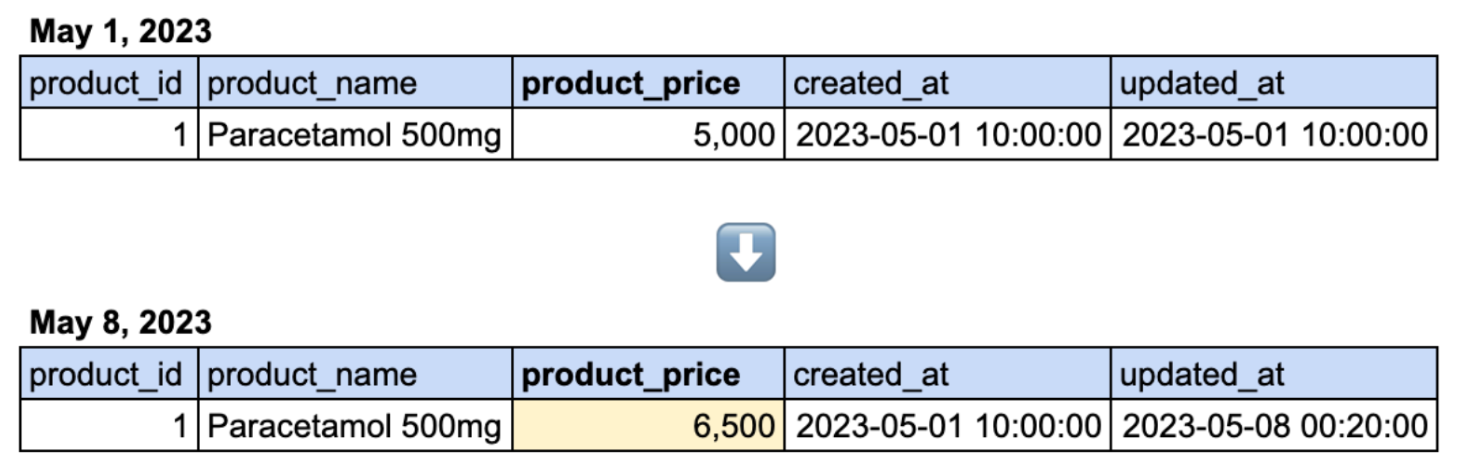
(B)
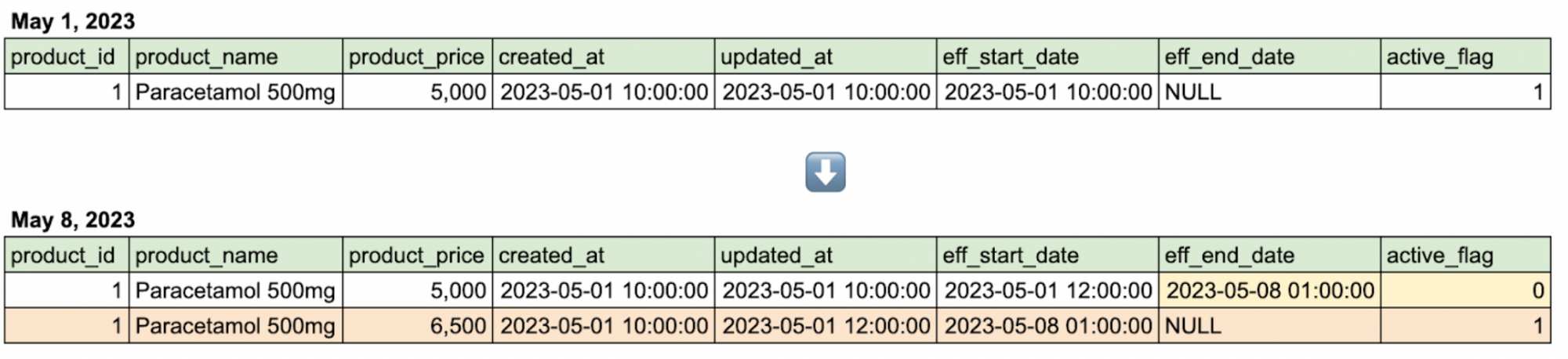
Figure 1. A. A change in the data of a product in the source table. B. How the data change in the source table is captured by the SCD2 table.
This is an outline of the processes that happen in SCD2 when capturing a data change:
- Here, we have a sample table for products. The product_price column is the column of interest which changes are going to be captured. Figure 1.A. shows that a change occurred in this column.
- Figure 1.B shows how an SCD2 will capture the change. It has columns that are unique to this type of table: eff_start_date indicates when the data is inserted into the table, eff_end_date indicates when the next version of data is inserted, and active_flag indicates whether the row is the latest version of the data.
- The first version of the data is captured on May 1, 2023. When it first enters the table, the time when the data is inserted is captured in eff_start_date, active_flag has the value of 1 and eff_end_date is null to indicate that it is the latest version of the data.
- When the value in product_price changes, a new column is created and the eff_end_date of the previous row (containing the old value) is filled with the time when the new data is inserted. The eff_start_date of the new table is also the time when the new data is inserted, and the new row has a null eff_end_date and active_flag now has the value of 1.
How do we build SCD2 Tables?
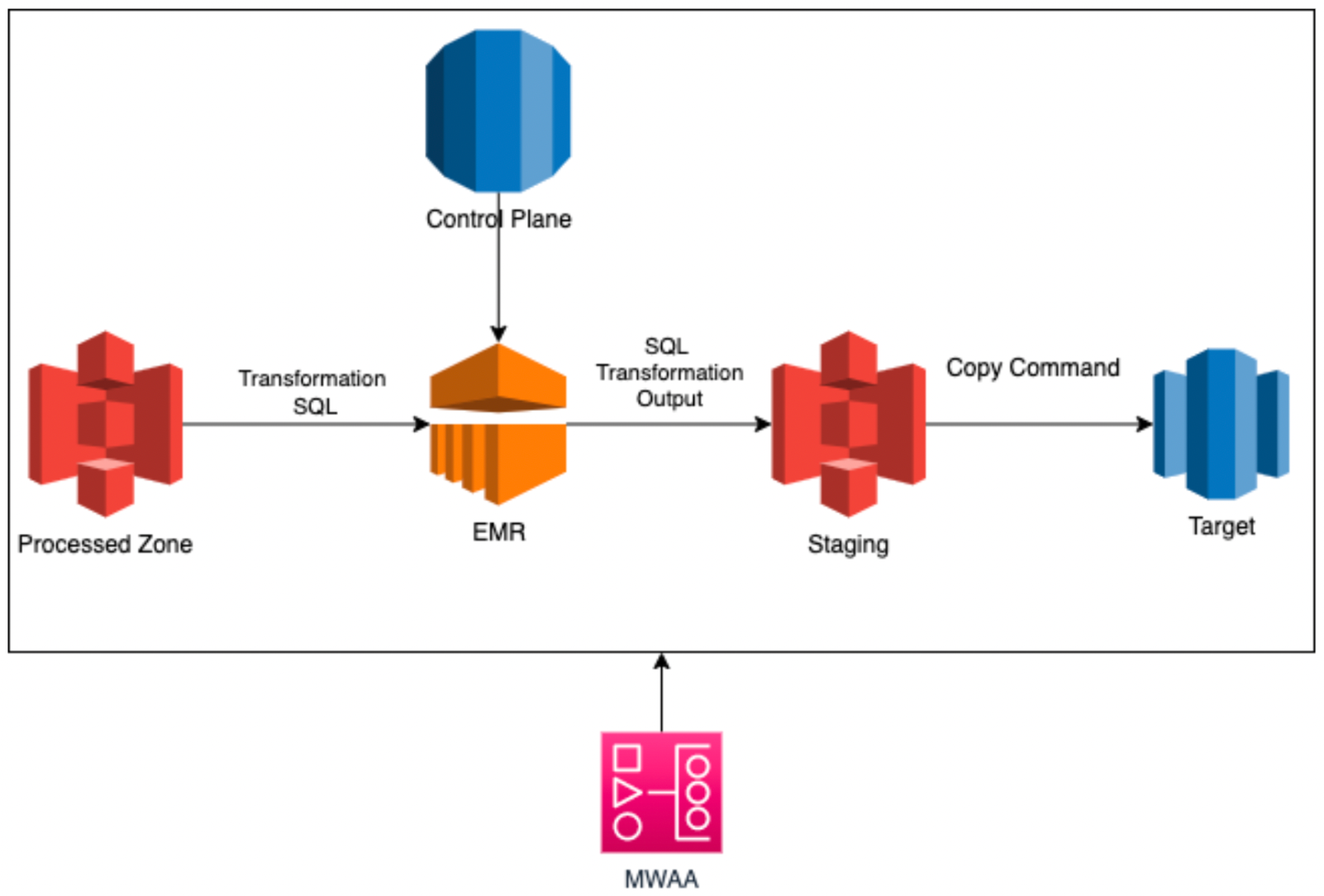
Figure 2. The framework of Halodoc’s data warehouse.
These are Halodoc’s data warehouse components (Figure 2):
- Control Plane: Control Plane tables store the configurations of SCD2 tables and other tables in the processed and target (data warehouse) zones. This includes
- SCD2 columns, the column(s) in which changes are tracked and will trigger the creation of a new record in the table.
- The time when the latest schedule runs and the latest time in the table and the source tables. This allows the table to be loaded incrementally.
2. AWS MWAA: An AWS-managed Apache Airflow used to coordinate the data pipelines.
3. AWS Elastic Map Reduce (EMR): A virtual cluster where the SQL transformation is performed using Spark SQL.
- The data used in this process comes from the data lake, which captures the data and changes from the source.
- The SQL transformation query is stored in S3.
4. Stage and Target (S3 and Redshift): These two stages involve both S3 and Redshift for SCD2.
- EMR uses Spark SQL to create and store the stage table in S3.
- EMR establishes a connection to Redshift and using the copy command, the stage table is inserted into the stage schema in Redshift.
- This stage table is then processed using a template SQL script and captures the changes by comparing the most updated version of the data in production to the latest data stored in the Stage schema of Redshift.
SCD2 Transformation Using SQL Scripts
These are some sample queries that we use to transform tables into SCD2. The table from Figure 1 is used as a reference. Templates are used to create these sample queries below and they are executed in this following sequence.
1. Creation of the staging table
The staging table contains all the data based on the incremental filter of the SQL transformation query of the table.
2. Update existing row (if necessary)
The query uses the UPDATE statement to replace the value of the SCD2 columns (active_flag, eff_end_date) of existing rows if they have different values in the staging table (containing the latest data).
Because there can be more than one SCD column, this query concatenates all the values of the SCD2 column(s) and uses the MD5 statement to convert the long string to a binary string of 32 hex digits, which improves the performance of the query. In this example, the SCD2 columns are product_name and product_price.

3. Update the values of other columns when there is no change in the values of the SCD columns
When the previous step has been completed and the changes have been captured (mainly active_flag = 0 for those rows), this query is run. It updates the values of the other columns besides the SCD2 columns in an existing row (i.e. where active_flag = 1).

4. Inserting a new row in an SCD2
This is the last step of the chain of queries. This query checks if the current row exists in the target SCD2 and will only insert if it does. This is done by comparing the business key, the column that determines the granularity of the table. In this example, the column is product_id.

Improvement Areas
This is the first pipeline for SCD2 tables in Halodoc, so there are improvements that can be done.
- We use Redshift to process the data and transform it into an SCD2. This results in a higher load on Redshift’s CPU and memory usage that might be unsustainable as our data grows, especially as it stores and computes our dimensions, facts, presentation tables, and materialized views.
- The SCD2 column has no unique key or surrogate key that other tables can join on, even though there are cases where this feature is required. For example, some businesses have discount rules that might be updated over time. However, there is a need to observe whether the correct discount had been applied according to the current rule. This comparison will require joining the transaction fact table and the discount rule SCD2 by date and that leads to a higher load on Redshift.
- The Redshift load can be reallocated to EMR where a very similar process will run with Apache Hudi using Apache Spark. The upsert operation enables Spark clients to update dimension records without any additional cost. This might increase the cost of EMR, but at the same time, it will reduce the load on our Redshift and therefore, give more Redshift’s resources to reporting.
Pros and Cons
Pros: SCD2 allows business users to track the changes of the data. In Halodoc, this is especially helpful for user behaviour analysis and operational data analysis when backend does not provide snapshot data.
Cons: In our case, the pipeline required to build SCD2 increases the load to Redshift and will require additional technical effort to streamline.
Conclusion
SCD2 is a useful feature for operational and analysis use cases that gives our users the ability to capture all the different versions of a data point. Even though there are still improvements to make, our current version of SCD2 is able to provide flexibility in choosing which columns should be tracked. We hope to improve this process further, by streamlining our process in EMR, for example.
Join us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek and many more. We recently closed our Series C round and In total have raised around USD$180 million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


