

Airflow automation for finance reconciliation
Finance reconciliation is an accounting process that compares two sets of financial records or account balances to check for margin and amount consistency, accuracy, and correctness and to ensure if this is in agreement with the balance.
Being a fast-paced, rapidly evolving start-up, our organisation is continuously emerging, dealing with a lot of financial transactions day by day.
Finance reconciliation involves comparison of data between the report derived from live transactions and the transformed source data as per the business logic to fetch the right balance.
The source DB that serves as the base for financial reconciliation is distributed among different AWS Relational Database(RDS) coming from various microservices.
This is a combination of static and transactional data increasing the complexity of transactional logic for reconciliation which needs to be done both internally and with our partners like pharmacies, hospitals, insurance providers, and so on.
With discrepancies such as double payments, partial refunds, reallocations in source transactional data, reconciliation gets more challenging and this has to be tackled at the source before the data extraction into the middleware system where it is transformed as per the financial business needs.
Middleware is the database where transformations for finance closing are carried out on the data extracted from source database. Data post the transformations get migrated to Oracle DB for the creation of journals and general ledgers.
In this blog, we have outlined the finance reconciliation process and why we chose Apache Airflow as the workflow management tool. The issues faced by the existing tool used and how Airflow was successful in overcoming these with a plenitude of beneficial features and operators.
Tools considered
Among many ETL tools that facilitated data movement and job scheduling, Synchro Indonesia was the chosen candidate. It was initially used for scheduling and triggering jobs which loaded data from the source DB to middleware and executed update scripts on this data.
Findings from the trials (and short-comings)
- The Synchro software posed serious issues with regular task failures, which required manual intervention for script execution and data modification which put data accuracy and integrity at risk.
- Update scripts scheduled to be executed after data load often failed, resulting in a repeated manual effort.
- Also, it lacked automatic data sharing capability.
- Above inefficiencies led us to explore other workflow orchestrators that could support effective data loading, scheduled post-load script execution, and data sharing all within a single automated pipeline without compromising data accuracy or needing manual intervention.
Why Airflow?

- Apache Airflow solved all the problems listed above that its predecessor could not solve for us.
- It is a popular platform to programmatically create workflows and an excellent tool to organize, execute, and monitor workflows so that they work seamlessly. It is widely used as a workflow orchestration solution for ETL & Data Science.
- At Halodoc, we have numerous data sources which are daily queried through specific workflows to feed and augment the analytical databases with information related to the daily transactions of our business, such as medicine delivery orders, insurance, tele consultations, doctor appointments, laboratory data, and so on.
- Since Airflow was already the chosen workflow management tool for batch processing data from Relational Data Store (RDS) to Data Warehouse (DWH) (by the Data team) at Halodoc, adopting the same for finance closing/reconciliation was an obvious choice.
- Airflow helped improve data quality, data consistency and integrity by completely eliminating the need for human interference, thereby ensuring error-free data.
- The workflows are designed in such a way that the failure information in case of any task failure is sent to a dedicated private Slack channel, Slack being the major alerting and communication platform at Halodoc.
- This alerts the team of any failure at the task level and helps in rectifying the error and restarting the failed task without disrupting the job it is a part of.
- Its DAG (directed acyclic graphs) based definition style is practical and easy to implement and maintain. A sequence of operations can be set up that can be individually retried on failure and restarted where the operation failed. DAGs provide a nice abstraction to a series of operations.
- Airflow also offers a very powerful and well-equipped UI that makes tracking jobs, rerunning them, and configuring the platform an effortless task.
- It provides a fair dashboard to monitor and view job runs and statuses. It is possible to have a quick overview of the status of the different tasks, as well as have the possibility to trigger and clear tasks or DAGs runs.
- With an efficient retry strategy and a Highly Available cluster, Airflow is stable, reliable, and consistent doing away with the task failures owing mainly to the high CPU usage of the DB server faced earlier.
- It is a very flexible tool that gives more control over the transformations while also letting the user build their framework on top of the existing operators. It offers the flexibility to write and assemble our evolving data pipeline.
- Code flexibility and visibility play a key role in financial data transformation, and these encouraged us to introduce additional scripts on data validation and self-checks both at the source before extraction and during the transformation.
- Keeping errors in check at the source has helped greatly in better customer experience along with smoother financial reconciliation.
- Source data error reduction and data accuracy and consistency have let us focus on larger problems also eliminating toil from various teams in gathering error information.
Features that proved extremely beneficial
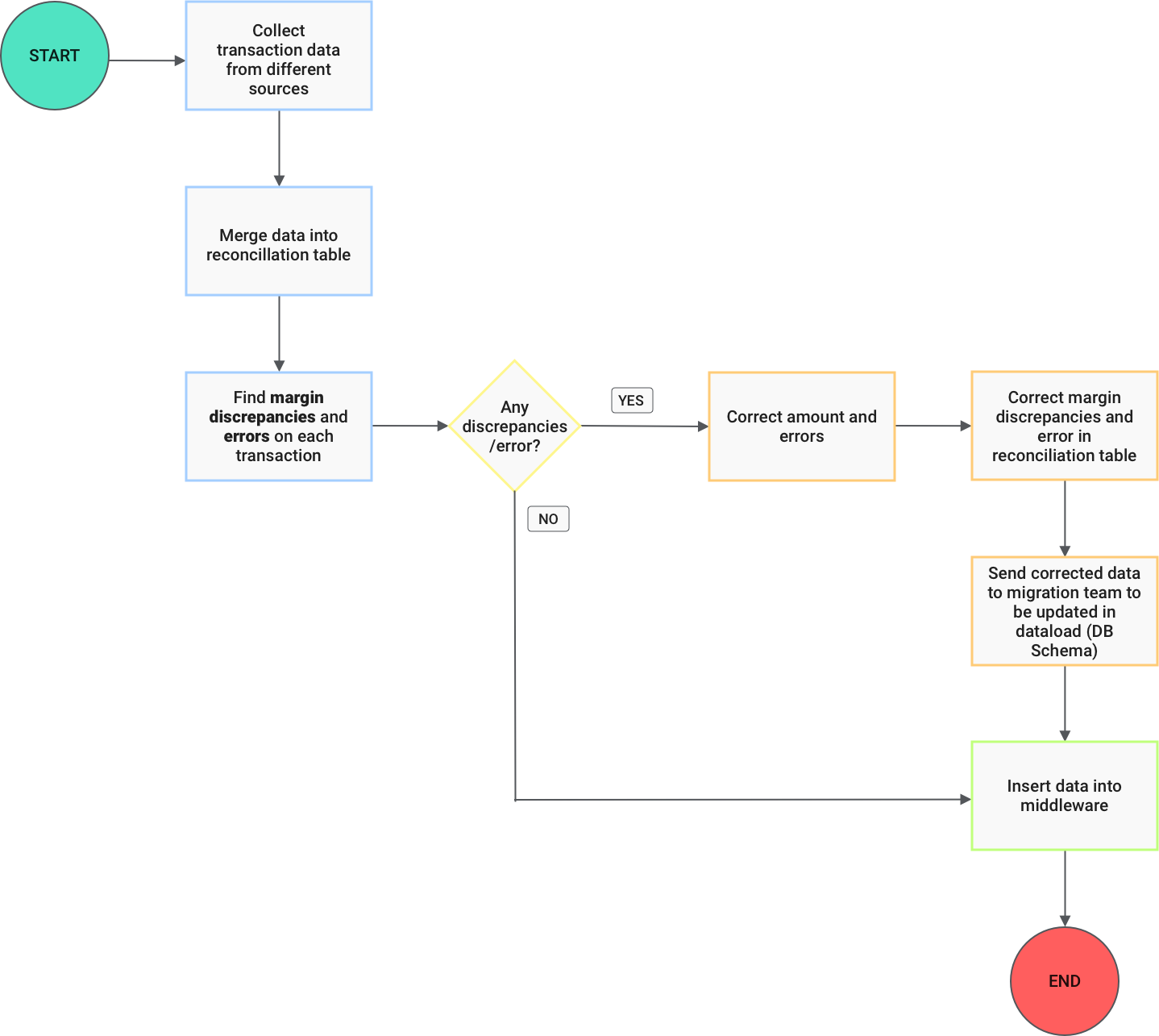
Data transformed for financial reconciliation involves complex logic for the creation of Journals and General Ledgers and data comparison against the BI report generated from real-time transactions.
This demands decision-making among various branches in the transformation and execution of a task based on a given specific condition.
Airflow handles task dependency concepts such as branching, and it is capable of controlling complex relationships between tasks. Synchro lacked this functionality making human decision-making inevitable.
The below features were highly helpful to achieve the desired transformation for finance reconciliation.
- BranchPythonOperator: BranchPythonOperator is a powerful tool in Airflow that is used for branching. This allows following a specific path according to a condition. BranchPythonOperator executes a Python function returning the task id of the next task to execute. It is similar to the PythonOperator in that it takes a Python function as input but returns a task id (or a list of task_ids) to decide which part of the graph to go down.
This can be used to iterate down certain paths in a DAG-based on the result of a function.
This was advantageous for data flow for finance closing in the right decision making for data update post data insertion into the middleware. - Trigger rule: Airflow allows for more complex dependency settings, though the normal workflow behaviour is to trigger tasks when all their directly upstream tasks have succeeded.
The trigger rule argument defines the rule by which the generated task gets triggered.
The trigger rule along with BranchPythonOperator has been hugely useful to execute only a branch of operations depending on the result of the preceding task, skip a set of operations and continue with the remaining tasks without breaking the flow.
Not setting trigger rules in conjunction with BranchPythonOperator would result in skipping all the tasks following a branch since the default value is ‘all_success' which executes a set of operations only if all the preceding upstream operations are successful.
Custom operators built on top the existing framework
As mentioned earlier, Airflow is a very flexible tool that gives more control over the transformations, to design workflows of any complexity level, while also letting the user build their framework on top of the existing operators.
With this basic framework in place, building new DAGs becomes effortless.
This helped us in building tailor-made operators for purposes such as:
- RedshiftToDataloadOperator: To insert the extracted data from the source DB (Redshift) to the target DB (Postgres).
Below is the list of tasks that gets executed when this operator is called:
- Data from the source DB gets extracted.
- Extracted data gets loaded into the staging table in the target DB.
- Data in the staging table is compared against the target table using the primary key combination.
- Records are updated if the primary key combination is present in the target table, inserted if not found considering them new.This brings in an intermediate layer that acts as a staging area where data is validated and cleaned before transforming into target tables.
- Also prevents the same data from entering more than once due to accidental multiple job triggers. This keeps data duplication in check thereby enhancing data consistency, integrity, and robustness.
- DataloadToS3Operator: To upload and send the transformed data file export links from target DB to a private Slack channel.
- After running a series of update statements on the inserted data in the target table, data is exported to a file whose type can be specified as a parameter of this class.
- File is then compressed depending on whether or not compression is required.
- Exported file is uploaded to AWS S3 bucket whose name is to be mentioned in the configuration file.
- Downloadable links of uploaded files are shared on the dedicated Slack channel which is the majorly used communication and alerting platform at Halodoc.
- Finance team uses these links to download the files for daily, weekly, and monthly finance reconciliation.
Summary
With a multitude of favorable features and operators, Apache Airflow has ensured smooth data transition right from source data extraction, to necessary updates on data inserted and finally sharing transformed error-free data file links with the finance team for reconciliation.
The error rate has exponentially dropped with the introduction of Airflow single automated pipeline for hassle-free sensitive financial data movement and reconciliation.
Additional self-checks and data validations included as part of the workflow before extraction and during transformation have facilitated data stability, uniformity, and authenticity.
Data exported is meticulous, complete, timely, and consistent assuring high data quality and integrity in the days to come.
Interested in exploring with us?
We are always looking out for top engineering talent across all roles for our tech team. If challenging problems that drive big impact enthrall you, do reach out to us at careers.india@halodoc.com
About Halodoc
Halodoc is the number 1 all-around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 2500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allows patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, Gojek, and many more. We recently closed our Series B round and In total have raised $100million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalized for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


