

Scaling the Reconciliation system using eventing based architecture
This is in continuation of my last blog where I explained about Reconciliation using eventing based system and how we built reconciliation using Kafka based architecture. In this blog I will explain about the challenges we faced under heavy load and how we scaled up using Kafka based eventing system.
Problem
Being a rapidly growing fast-paced start-up, Halodoc is continuously evolving & handling large amounts of financial transactions every single day. As number of transactions are increasing by the day, we need to find a way to reconcile all the orders at the earliest. As the reconciliation system is based on event processing, handling very high number of transactions require parallel processing of events.
Resolution
- We need to enable parallel processing so that processing time is reduced significantly.
Solving the Problem through parallel processing
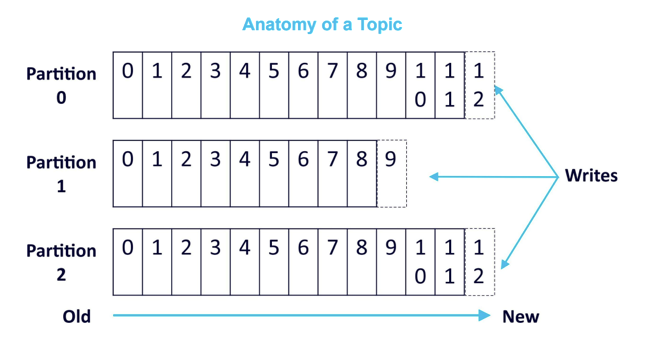
We can scale up event processing in Kafka by increasing topic partitions. Kafka topics can be divided into a number of partitions. While a topic is a logical concept, a partition is the smallest unit of storage that holds a subset of messages in a topic. Each partition is a log segment to which messages are written in an append-only fashion. By increasing topic partitions and spinning up multiple consumers, we can achieve parallelism in event processing.
./kafka-topics.sh --zookeeper localhost:2181 --create --topic reconciliation --replication-factor 3 --partitions 11
But parallel processing alone isn't enough. Let me walk you through one of the problems we faced during parallel processing, and how we handled it.
We discovered a new problem with increased partition count. We discovered that ordering of the events matter, and Kafka guarantees ordering of messages only within a partition.
Let's consider a scenario where one order generates multiple events, say, order_confirmed, order_payment_success, order_shipped and order_cancelled. If not controlled, these events can end up in different partitions, and consumers of the topic may see these events in random sequence. If order_cancelled event gets processed by the consumer before order_confirmed, the actual state of order will be recorded incorrectly.

Solving the problem of out of order event processing
One way to solve this problem is by writing events generated by an order in the same topic partition in Kafka. Since Kafka guarantees message sequence within a partition, a consumer registered to this topic partition is ensured to receive these events in the same sequence that it was produced.
For this, we wrote a custom Partitioner called ReconSystemPartitioner.

In this example, we pass in order_id as 'key' to the customer Partitioner which uses it as the partition key in determining the partition that the events will be written to. This way, the custom partitioner helps us get better control over the destination of events produced in a topic.

To get full parallelism of kafka partition we need to make sure each partition will have its own consumer group . If there are three partitions and one consumer group in that case it will be the same as sequential processing . Let me explain this with an example .
What is consumer group ?
In simple terms , consumer group is a multi-threaded or multi-machine consumption from Kafka topics.
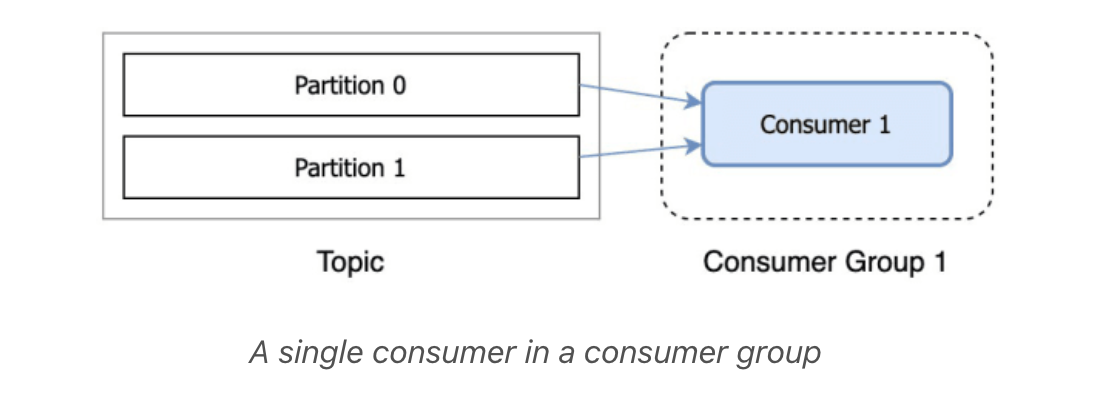
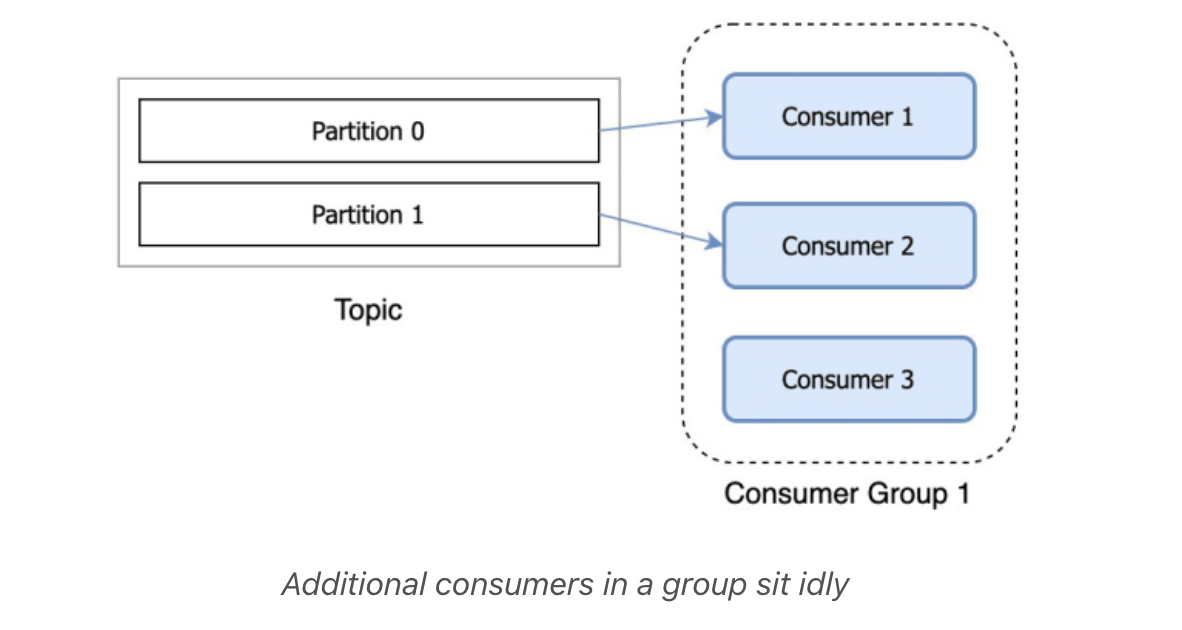
If you have a topic with two partitions and only one consumer in a group, that consumer would consume records from both partitions.
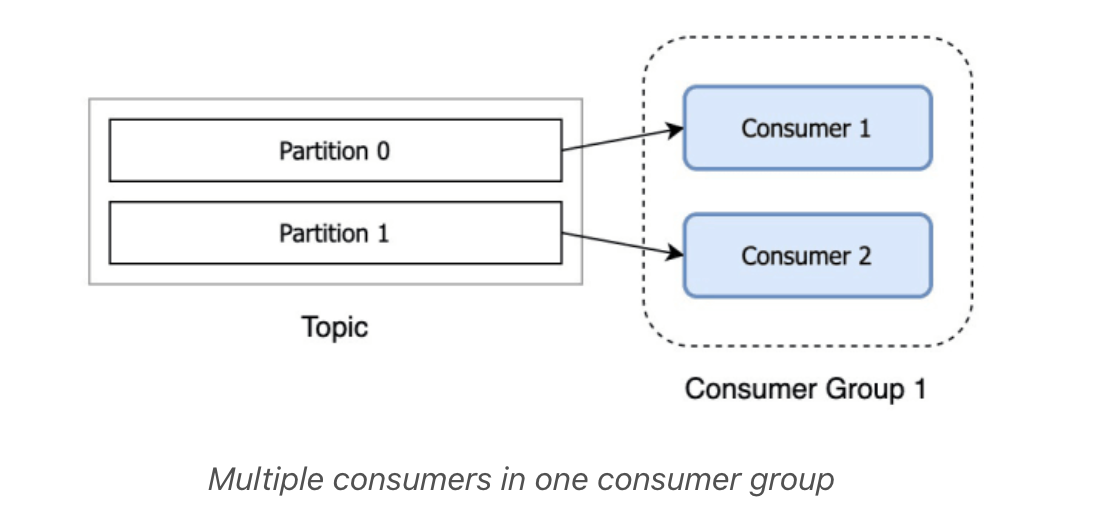
After another consumer joins the same group, each consumer would continue consuming only one partition.
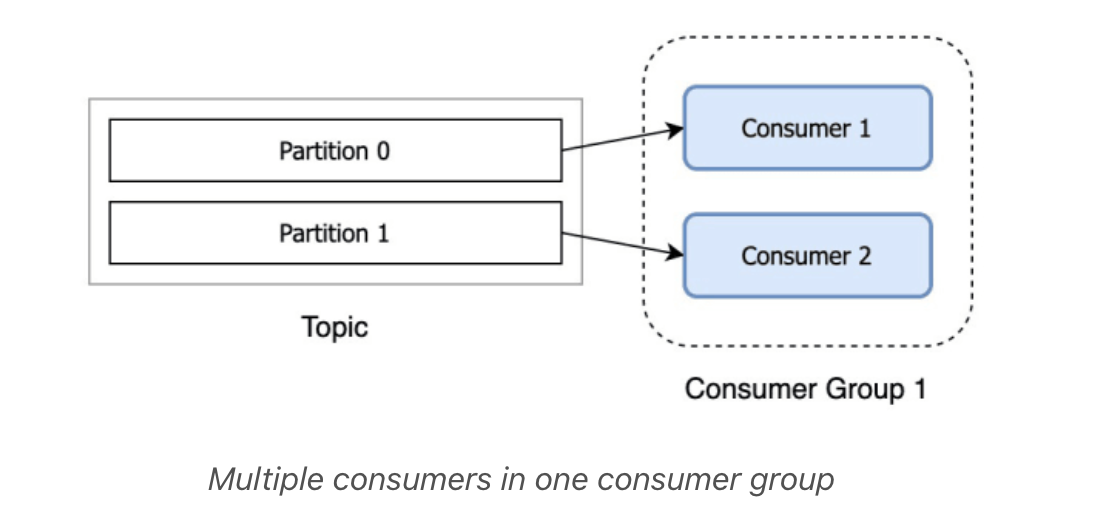
If you have more consumers in a group than you have partitions, extra consumers will sit idle, since all the partitions are taken.
So when we need to create topic we need to take account on topic-partition , partition-key and consumer group . By appropriating choosing this configuration , it will increase the performance of kafka event processing drastically .
Conclusion
In short, increasing topic partitions, spinning up multiple consumers in a consumer-group proportionate to the number of partitions and defining a custom Partitioner lets us achieve significantly improved performance and maintain data correctness and integrity.
Join Us
We are always looking out for top engineering talent across all roles for our tech team. If challenging problems like this, that drive big impact, enthrall you, do reach out to us at careers.india@halodoc.com
About Halodoc
Halodoc is the number 1 all-around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, and many more. We recently closed our Series B round and In total have raised USD 100million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalized for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


