

Automatic ICD-10 code assignment to Consultations using Deep Learning
We at Halodoc, ensure the patient gets the services covered under their insurance policies. Adjudication of healthcare claims is the key activity that actually delivers the insurance benefits to the Patient. The process is just and ensures that the claims are rightly addressed. Patients can utilize their insurance for doing a teleconsultation and then purchase medicines prescribed to them at Halodoc and for a smooth user experience and faster claims adjudication we wanted to explore AI-based solutions to make the process smooth and involve less human intervention.
Clinical notes are free text narratives generated by doctors after each patient consultations. They are typically accompanied by a set of metadata codes from the International Classification of Diseases (ICD), which present a standardized way of indicating diagnoses and procedures that were performed during the consultation. ICD-10 codes have a variety of uses, ranging from Billing, Insurance claims to predictive modeling of patient’s conditions.
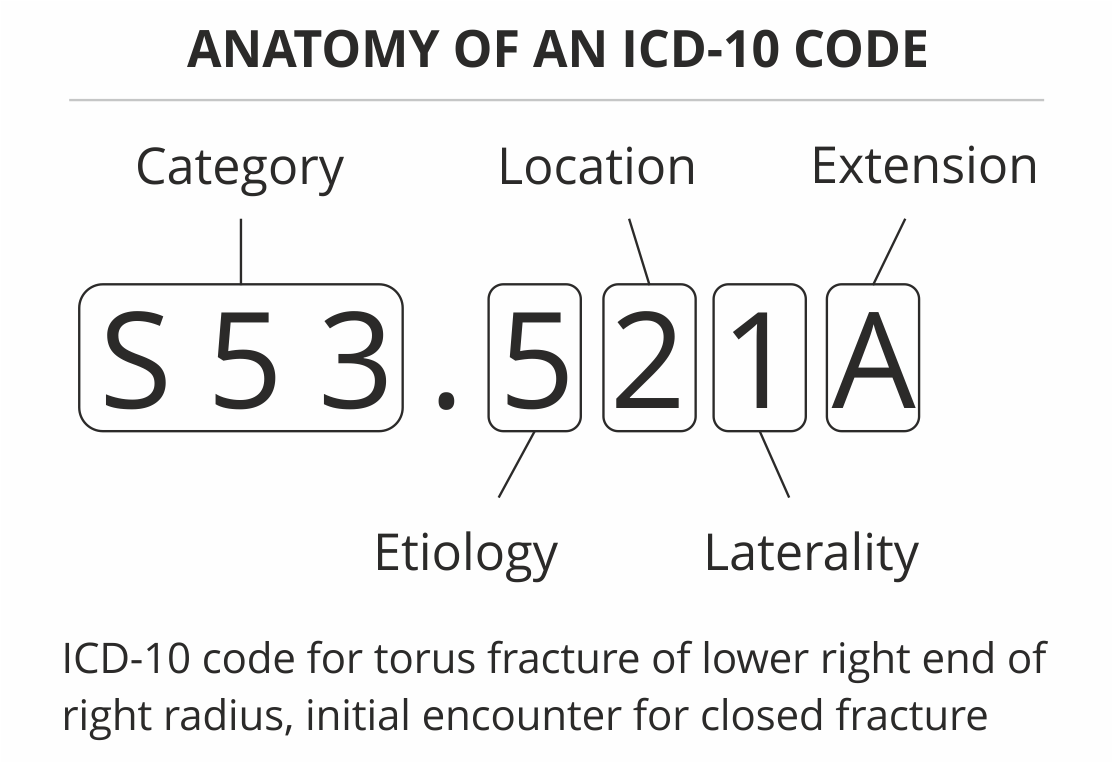
We use ICD-10 codes primarily in Insurance Claims Adjudication along with various other usages in post-consultation analytical use-cases. Because manual coding is time-consuming and error-prone, automatic coding has been explored. The task is difficult for two main reasons. First, the label space is very high-dimensional, with over 140,000 codes combined in the ICD-10-CM and ICD-10-PCS taxonomies. Second, the clinical text includes irrelevant information, misspellings, and non-standard abbreviations, and large medical vocabulary. These intricacies combine to make the prediction of ICD codes from clinical notes an especially difficult task, for computers and human coders alike. In the past, this assignment of ICD-10 codes had been done manually where intern doctors and claim analysts go through the entire chat interaction between the doctors and the patients and the SAP notes given by a doctor to identify key problems the patient is facing and assign appropriate ICD-10 codes to the consultations.
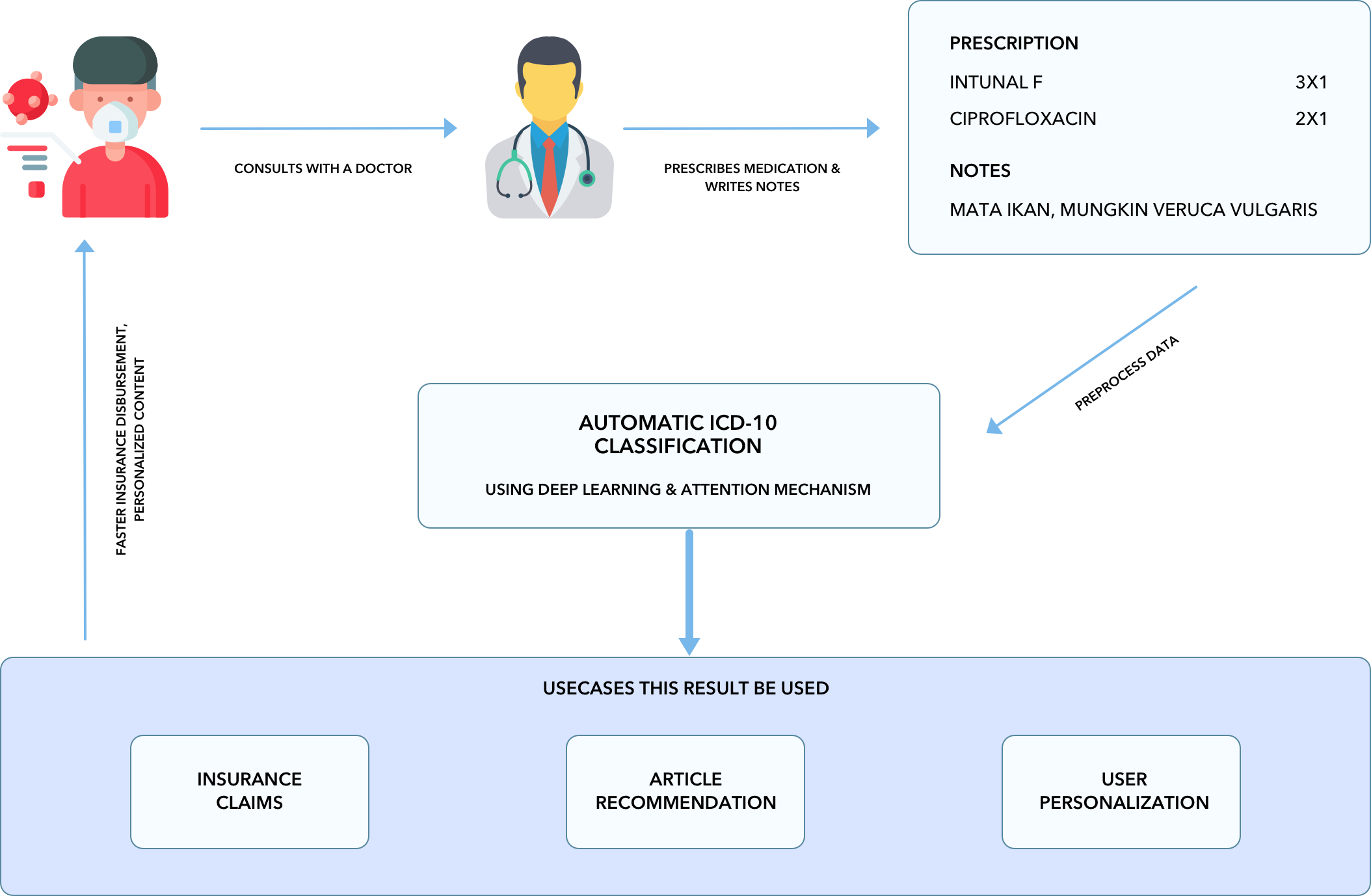
Today, as we move towards User Personalization & Automatic Claim Adjudication, there is a need for automating this step and process huge volumes of consultation data in real-time. Therefore we began exploring AI-based approaches to solve the problem and make our systems robust to process these data for User personalization and faster claim adjudication.
DATA
To start building a robust pipeline, we began digging into our data and began compiling it to a standard format, the very first challenge we faced was to extract the SAPE (Subjective, Objective, Assessment, Plan) attributes from the consultations and use the Assessment from each of the consultations to assign an ICD-10 Code, the process of SAPE classification is discussed separately in this blog. Now that we have the Assessment from the Consultations, we also gathered ICD-10 codes and their descriptions in Bahasa since we operate majorly in Indonesia and our consultations also happen in the native Bahasa.
The Solution :
We started working on a Deep Learning -based method for automatic ICD-10 code assignment based on consultation notes. Since we have multiple codes to assign, we employ a label attention mechanism, which allows our model to learn distinct document representations for each code. Attention mechanisms provide explainable attention distributions that can help to interpret predictions. We have formulated the problem into a Multi-label Text Classification, where we generate a probability for each of the ICD-10 codes and try to answer the question: "if this code can be assigned?" .
We wanted to design our model taking the fact that important information correlated with a code’s presence may be contained in short snippets of text which could be anywhere in the note, and that these snippets will likely differ for different labels.
We treat ICD-10 code prediction as a Binary Classification problem. Let ℒ represent the set of ICD-10 codes; the labeling problem, for consultation, i is to determine,
$$y_{i,l} ~~ \epsilon ~~ {{ 0,1 }} $$
We train a neural network that passes text through a recurrent layer to compute a base representation of the text of each document and makes |ℒ | binary classification decisions. we then apply an attention mechanism to select the parts of the document that are most relevant for each possible code. These attention weights are then applied to the base representation, and the result is passed through an output layer, using a sigmoid transformation to compute the likelihood of each code.
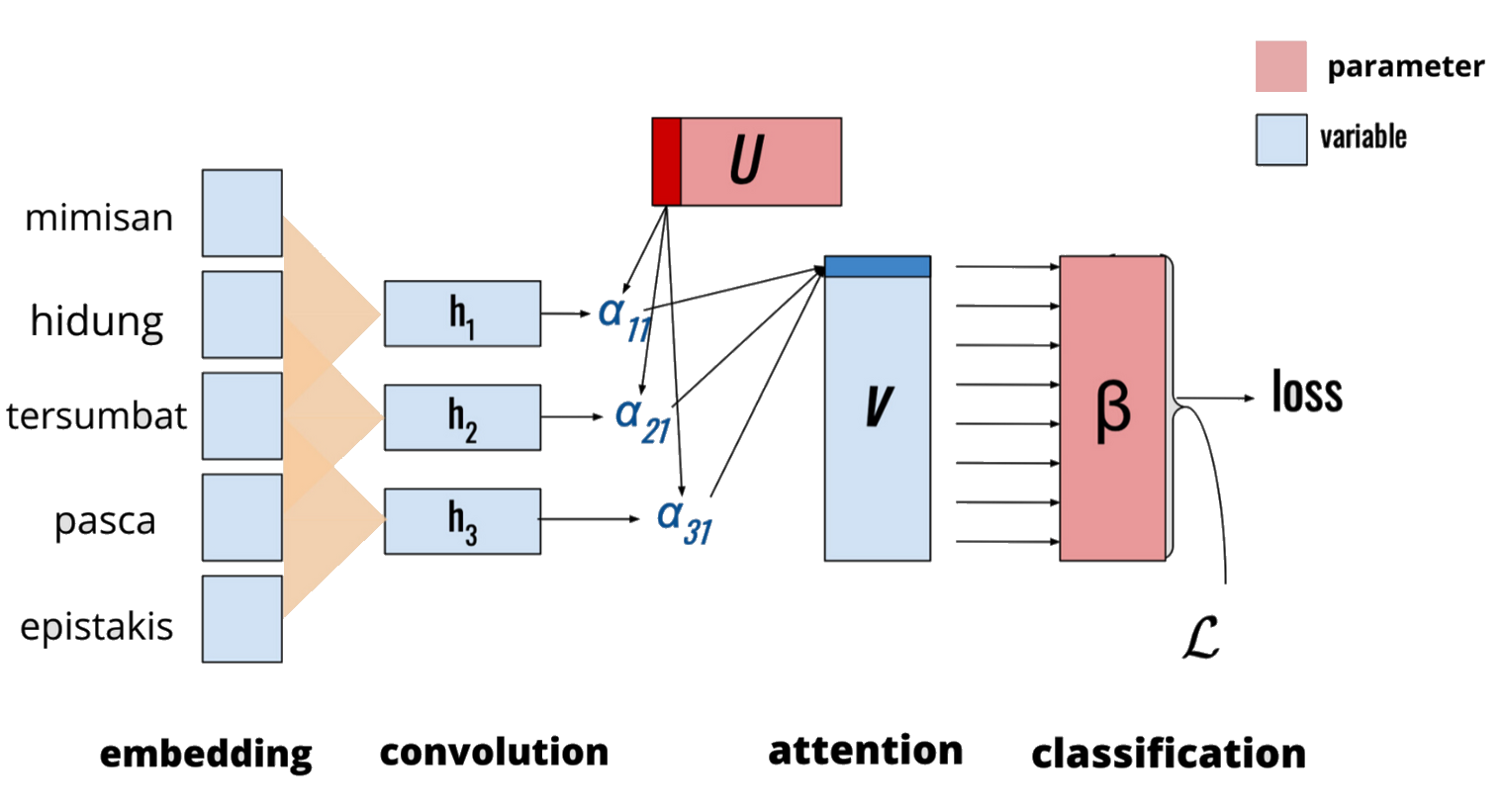
Embedding Layer
To begin with, we create a Vocabulary of words from our corpus, here we use the notes for each consultation to create a vocabulary. The vocabulary is a holding area for the processed text before it is transformed into some representation for the impending task, be it classification, or language modeling, or something else.
The vocabulary serves a few primary purposes:
- help in the preprocessing of the corpus text,
- serve as a storage location in memory for processed text corpus,
- collect and store metadata about the corpus and
- allow for pre-task munging, exploration, and experimentation.
Before the Word2Vec training process starts, we pre-process the text we’re training the model against. In this step, we determine the size of our vocabulary (vocab_size) and which words belong to it.
After the vocabulary is created, we train a Word2Vec model to get a pre-trained word embedding model which can be used in the convolution layer. This also helps us in training the model faster as we can save time for training the embedding model for each training experiment and also as this is a separate module, we can replace this with more sophisticated modeling techniques and improve our overall accuracy.
Convolutional Architecture
At the base layer of the model, we have de-dimensional pre-trained embeddings for each word in the document, which is horizontally concatenated into the matrix, X=[x1,x2,x3,…………xN], where N is the length of the document. Adjacent word embeddings are combined using a convolutional filter. we use a combination of embedding layer, convolution layers, and recurrent Layers.
Attention Mechanism
After convolution, the document is represented by the matrix H, we apply a per-label attention mechanism. As the clinical documents have different lengths and each document has multi-labels, our goal is to transform H into label-specific vectors. We achieve that goal by proposing a label attention mechanism. Our label attention mechanism takes H as the input and output |L| label-specific vectors representing the input doctor notes.
Initial Results and Improvements:
We trained the initial version of the model and achieved 64% Test and Validation Accuracy.
A drawback of this work is that it can only capture the local context within the width of the convolution while long-term dependencies in the text can often be informative.
Transformers are built upon a mechanism they proposed called self-attention which allows each word to simultaneously attend to all other words in a sequence. Transformers has been shown to be much better at capturing long term relationships in text than CNNs and LSTMs. In addition to this, the attention mechanism makes it more interpretable than CNNs and LSTMs. The transformer's ability to capture long term dependencies in the text will enable it to outperform the previous approach.
The original transformer encoder outputs a representation for each word in the input sequence and we would need to aggregate these inputs in order to make the classification decision. The transformer encoder is a stacked model composed of B-identical blocks where each block has its own set of parameters.
These blocks are composed of two primary components, a self-attention layer and a feed-forward layer with one hidden state.
Keeping the architecture intact, we experimented with replacing LSTM or GRU layers with the Encoder layer from Transformers.
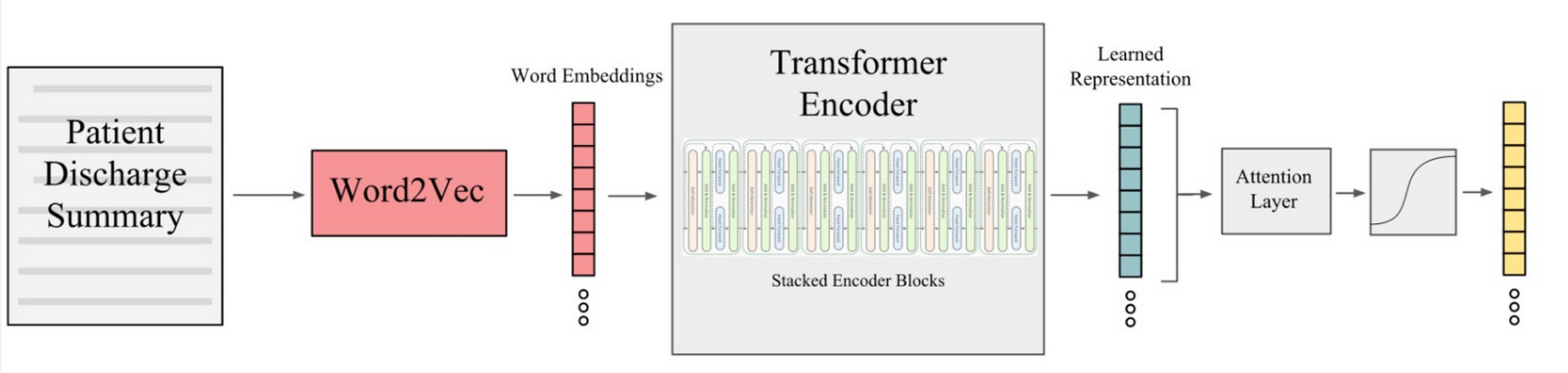
For comparison with prior work and train and evaluate on a label set consisting of the N- most frequent labels. In this setting, we filter each dataset down to the instances that have at least one of the top K most frequent codes. We selected consultations that cover the top-N ICD-10 codes and trained the model with this data. We achieved greater accuracy as compared to the previous model.
| accuracy | precision | recall | |
|---|---|---|---|
| Training | 0.93 | 0.93 | 0.87 |
| Validation | 0.96 | 0.96 | 0.93 |
Model Deployment :
For Training the model we used Amazon Sagemaker. Amazon SageMaker is a cloud service providing the ability to build, train, and deploy Machine Learning models. It aims to simplify the way developers and data scientists use Machine Learning by covering the entire workflow from creation to deployment, including tuning and optimization.
There are basically four “classical” steps: model creation, data gathering, training, and deployment.
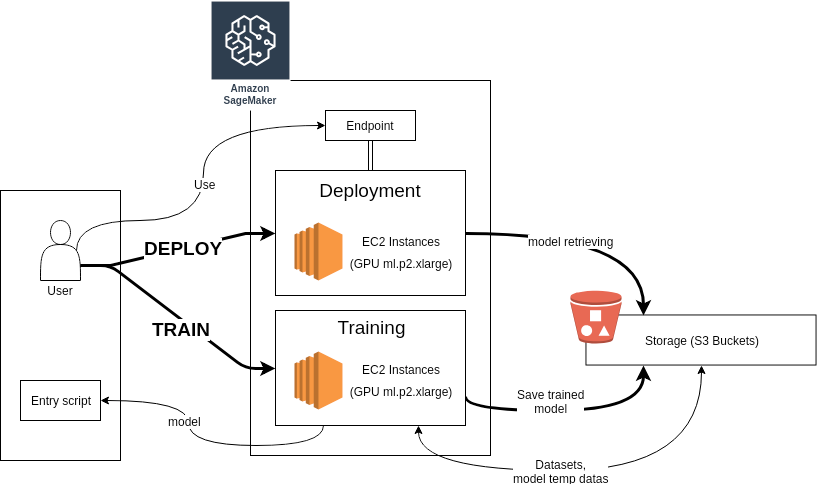
We used Sagemaker's “Notebook Instances” which basically are Jupyter Notebooks to train the model and use Amason S3 for storage. Amazon S3 is a storage service which will store data concerning model and datasets. Once, the model is trained, we create a Sagemaker Endpoint and initialize a predictor object which is able to access the model estimator and serve the requests. Amazon advises using the client’s SDK (in Javascript, Python, …) because it makes things really easier when it comes to send and receive data from endpoints. When the endpoint is not needed anymore, it can be removed manually using SageMaker’s web interface (e.g. clicking on buttons), or with Python by using the method “delete_endpoint” with the endpoint in the argument.
Conclusion
At Production, we observed the model to perform at par with the claim analysts and giving consistent results at 91% Accuracy. While the model is performing as expected, are now looking at ways we tune the model further and achieve performance close to 100% accuracy. At the current stage, we can use this solution to solve various pain points and make patients' experiences at Halodoc smooth.
Join us
We are looking for experienced Data Scientists, NLP Engineers to come and help us in our mission to simplify healthcare. If you are looking to work on challenging data science problems and problems that drive big impact enthral you, do reach out to us at careers.india@halodoc.com
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 1500+ pharmacies in 50 cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allows patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, Gojek, and many more. We recently closed our Series B round and In total have raised USD$100million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalized for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


