

Elevating Online Consultation Quality with Generative AI
At Halodoc, we believe that the quality of telehealth goes beyond clinical accuracy. It also depends on empathy, clarity, professionalism, and trust. Until recently, these dimensions were difficult to measure at scale. Patient feedback was sparse, manual reviews covered only a small fraction of consultations, and many issues surfaced only after patients escalated complaints.
This has now changed. By transforming patient feedback into measurable quality metrics, we are able to evaluate every online consultation with the help of AI. Using Amazon Bedrock (Nova Pro) batch inference, we process tens of thousands of consultations asynchronously, feed the results into our analytics layer, and deliver clear, actionable insights to doctors. The result is fewer escalations, faster resolution, and a more consistent consultation experience for patients, while equipping doctors to continuously improve their communication and uphold the highest professional standards.
Why is Telehealth Quality Hard to Measure
At Halodoc, we historically relied on a mix of RED scores, post-consultation feedback, and manual random sampling to gauge quality:
- Only ~28% of patients submitted feedback.
- Operations teams could review only 200–300 consultations per week manually.
- Complaints were escalated reactively, often too late.
With ~70,000 consultations weekly, we needed a way to monitor 100% of interactions proactively and surface actionable feedback to doctors in near real time.
From detractor feedback (NPS), we saw recurring themes:
- Delayed or no response from the doctor.
- Unanswered questions or no clear next step provided.
- Unfriendly or rushed tone, with some sessions ending prematurely.
- Concerns with prescriptions or referrals, such as unclear instructions or incomplete guidance.
The core question: How do we translate this feedback into a scalable, objective quality system that helps doctors continuously improve?
Turning Patient Complaints into Actionable Quality Signals
We operationalised a structured set of parameters that cover both communication quality and compliance behaviours. At a high level, this framework evaluates how clearly doctors explain medical information, how respectfully they interact with patients, and how consistently they adhere to platform guidelines that maintain trust and confidentiality. This ensures that evaluations balance empathy and clarity with professionalism, ethics, and trust.
How the Quality System Works
- Playground: We first test the proposed parameters on sample consultations to verify detection quality, with internal doctors involved in reviewing and validating the results before promoting them to production.
- Scoring at scale: Each consultation receives a structured quality score per parameter. Unlike subjective ratings, these are consistent, with rules that account for edge cases (e.g., patient not responding), ensuring doctors are not unfairly penalised.
- Schema-bound outputs: AI outputs are generated in a strict JSON schema with mandatory explanations, ensuring consistency across tens of thousands of records and enabling automated analytics.
- Dashboards: QA teams can filter results by doctor, speciality, or timeframe, view parameter-level scores, see AI explanations for each rating, and use scores for rapid triage.
What This Means for Doctors
- Actionable, timely feedback focused on specific skills (such as answering follow-up questions, simplifying jargon, or adjusting tone).
- Transparent benchmarks over time.
- Targeted coaching sessions based on parameter trends rather than generic training.
What This Unlocks for Halodoc
- Fewer escalations: Issues such as empathy gaps, delayed responses, or prescription concerns are flagged early, reducing patient complaints before they escalate.
- Doctor development: Targeted, fair feedback helps doctors improve specific skills quickly, enabling more effective coaching and faster growth.
- Operational efficiency: Quality teams spend less time on manual reviews and more time interpreting insights, driving meaningful improvements across the platform.
- Patient trust and platform integrity: Continuous monitoring ensures consultations remain empathetic, professional, and compliant, strengthening patient confidence and protecting brand trust.
- Sustained improvement: A feedback loop from Playground to Production continuously refines parameters, ensuring quality standards evolve alongside patient needs.
How We Built It: Technical Architecture with Amazon Bedrock (Nova Pro)
Overview
We use Amazon Bedrock Batch Inference with the Amazon Nova Pro foundation model to analyse consultations at scale. This enables submission of large JSONL datasets from Amazon S3, asynchronous processing, and retrieval of results back into S3 for downstream workflows. We initially started with synchronous calls, but later shifted to Batch Inference, which reduced costs by 50% while still meeting our operational needs.
This approach is best suited for workloads where:
- Data arrives in large, scheduled cohorts (for example, daily or weekly consultation logs).
- Throughput and cost efficiency are more important than single-digit latency.
- Token usage must be tracked closely for operational and financial governance.
Each job runs fully managed within Bedrock, so there is no need to provision servers or manage inference clusters. We orchestrate daily and weekly jobs, and then push structured scores into our analytics store and dashboards.
Batch Inference Workflow
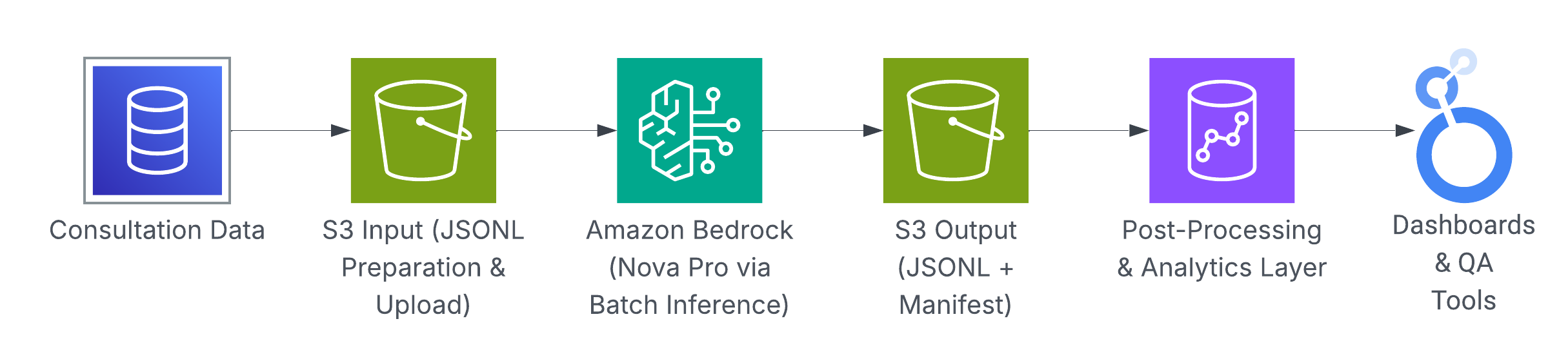
- Consultation Data – Raw consultation data is gathered from source systems.
- S3 Input – The data is transformed into JSONL format, and uploaded to Amazon S3 as the batch job input.
- Amazon Bedrock – Bedrock executes batch inference asynchronously across all JSONL records using the Amazon Nova Pro foundation model.
- S3 Output – Bedrock writes per-record outputs as JSONL files and generates a manifest in the specified S3 location.
- Post-Processing & Analytics Layer – The outputs are parsed, validated, and converted into structured scores and aggregated insights ready for downstream consumption.
- Dashboards & QA Tools – The processed results are presented through analytics dashboards and quality assurance tools, enabling operational teams to monitor trends and act on insights.
Data Format
Amazon Bedrock batch inference uses the JSON Lines (JSONL) format, where each line is a standalone JSON object. This format is optimised for parallel processing and scales efficiently to large datasets. All files must be UTF-8 encoded without BOM.
- Input JSONL – Each line contains a unique
recordIdand amodelInputpayload that follows the Nova Pro runtime request schema. If arecordIdis not provided, Bedrock automatically generates one. - Output JSONL – For every input line, Bedrock produces a corresponding output line. The order of records is preserved within each file. If a record fails, the output includes an
errorobject with details such aserrorCodeanderrorMessageinstead of a model response. - Manifest File – Alongside the output JSONL, Bedrock generates a
manifest.json.outfile containing job-level statistics: total records, counts of processed/success/error records, and aggregate token usage. This file is essential for cost tracking, monitoring throughput, and forecasting.
Example input record:
{
"recordId": "CALL000123",
"modelInput": {
"system": [
{
"text": "<system_prompt>"
}
],
"messages": [
{
"role": "user",
"content": [
{
"text": "<consultation_data>"
}
]
}
],
"inferenceConfig": {
"temperature": <temperature>
}
}
}Example output record (simplified):
{
"recordId": "CALL000123",
"modelInput": { … },
"modelOutput": {
"output": {
"message": {
"content": [
{
"text": "<consultation_scores>"
}
],
"role": "assistant"
}
},
"stopReason": "end_turn",
"usage": {
"inputTokens": 900,
"outputTokens": 100,
"totalTokens": 1000,
"cacheReadInputTokenCount": 0,
"cacheWriteInputTokenCount": 0
}
}
}Example manifest:
{
"totalRecordCount": 1500,
"processedRecordCount": 1500,
"successRecordCount": 1500,
"errorRecordCount": 0,
"inputTokenCount": 4991960,
"outputTokenCount": 139137
}Creating and Monitoring Jobs
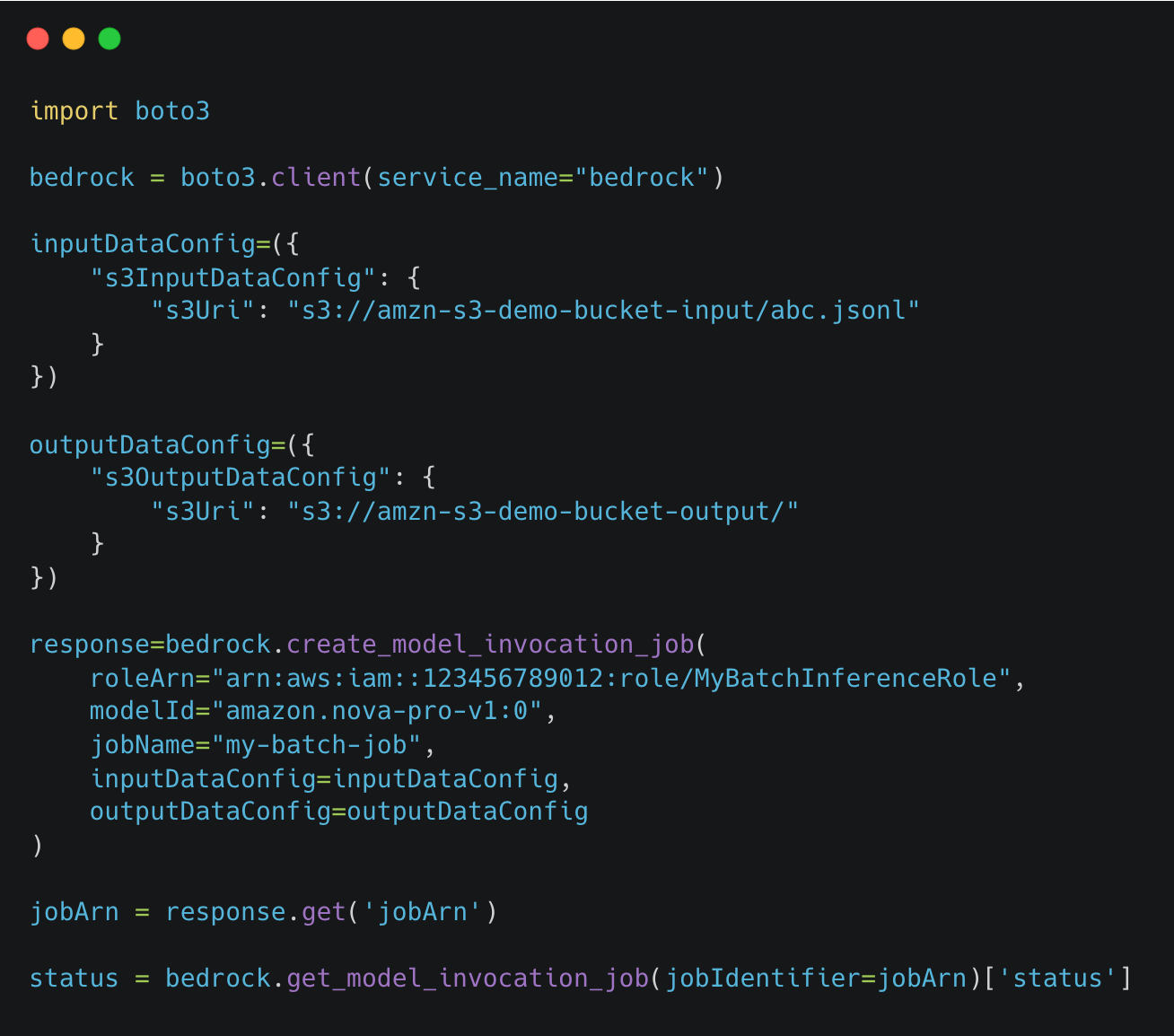
Batch jobs are created with the CreateModelInvocationJob API, which accepts S3 input and output locations, an IAM role, and optional parameters such as VPC configuration or a timeout (24–168 hours). The API call returns a jobArn that uniquely identifies the job.
Job progress can be monitored using GetModelInvocationJob, which provides the current status. The ListModelInvocationJobs API enables filtering and listing jobs by status, name, or creation time. Jobs can also be cancelled before completion with StopModelInvocationJob.
Security and Compliance
- IAM – Apply least-privilege policies to the job-submitting identity and to the Bedrock service role that reads from and writes to S3.
- Networking – Utilise VPC endpoints (PrivateLink) to ensure traffic between Bedrock and S3 remains within the AWS private network.
- Encryption – Enable server-side encryption for all S3 input and output, preferably with KMS keys for compliance.
- Auditing – Capture all submissions and state changes in AWS CloudTrail for full traceability.
Scalability Considerations
- Partition input – Split large datasets into multiple JSONL files to balance size and token load.
- Respect quotas – Apply back-pressure in scheduling to stay within Bedrock’s job size and concurrency limits.
- Track costs – Use token counts from the
manifest.json.outfor FinOps monitoring and forecasting. - Right tool for the job – Run batch inference for large cohorts; use synchronous APIs (InvokeModel or Converse) for real-time needs.
- Timeouts and retries – Jobs can run up to 7 days; resubmit failed records only if a job partially completes.
Final Takeaway
The goal isn’t to automate judgment but to strengthen it. By transforming patient complaints into structured quality signals, doctors receive fair, targeted feedback on both communication and ethical standards. This not only safeguards patient trust but also supports doctors’ growth, ensuring every consultation remains empathetic, professional, and consistently high-quality. Crucially, it allows us to proactively monitor 100% of consultations at scale, something that was impossible with manual reviews alone.
Join us
Scalability, reliability, and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels, and if solving hard problems with challenging requirements is your forte, please reach out to us with your resume at careers.india@halodoc.com.
About Halodoc
Halodoc is the number one all-around healthcare application in Indonesia. Our mission is to simplify and deliver quality healthcare across Indonesia, from Sabang to Merauke.
Since 2016, Halodoc has been improving health literacy in Indonesia by providing user-friendly healthcare communication, education, and information (KIE). In parallel, our ecosystem has expanded to offer a range of services that facilitate convenient access to healthcare, starting with Homecare by Halodoc as a preventive care feature that allows users to conduct health tests privately and securely from the comfort of their homes; My Insurance, which allows users to access the benefits of cashless outpatient services in a more seamless way; Chat with Doctor, which allows users to consult with over 20,000 licensed physicians via chat, video or voice call; and Health Store features that allow users to purchase medicines, supplements and various health products from our network of over 4,900 trusted partner pharmacies. To deliver holistic health solutions in a fully digital way, Halodoc offers Digital Clinic services including Haloskin, a trusted dermatology care platform guided by experienced dermatologists.
We are proud to be trusted by global and regional investors, including the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. With over USD 100 million raised to date, including our recent Series D, our team is committed to building the best personalized healthcare solutions — and we remain steadfast in our journey to simplify healthcare for all Indonesians.


