EMR on EKS: Mastering the Future of Data Processing
At Halodoc, we are relentlessly committed to staying at the forefront of technology, continually seeking ways to enhance our tech stack for greater efficiency and performance. In the ever-evolving landscape of data processing and analytics, staying ahead with scalable, efficient, and flexible solutions is paramount. Our journey began with Amazon EMR on EC2, a robust platform that served us well. However, as our data processing needs grew and the demand for optimization increased, we explored more advanced solutions. This exploration led us to Amazon EMR on EKS, a container-based approach that decouples analytics jobs from the underlying services and infrastructure, offering a multitude of advantages.
Containers and Kubernetes have revolutionized the tech industry by offering consistent, scalable, and efficient environments for deploying applications. Recognizing the power of this trend, Apache Spark and Amazon EMR have integrated support for Kubernetes/EKS, transforming big data processing with dynamic resource allocation and simplified infrastructure management.
In this blog, we’ll delve into why we transitioned to EMR on EKS, the setup process, and the significant improvements we’ve experienced. From enhanced resource utilization to streamlined infrastructure management, EMR on EKS has revolutionized how we handle our analytics workloads. Join us as we share our learnings, tips, and the benefits of embracing this cutting-edge solution.
Overview
- In the realm of big data management, Amazon EMR on EKS introduces a groundbreaking deployment solution, empowering users to leverage open-source big data frameworks seamlessly within the Amazon Elastic Kubernetes Service (Amazon EKS) environment.
- EMR on EKS revolutionizes the way analytics jobs are handled by introducing a container-based approach, effectively decoupling them from the underlying services and infrastructure.
- In addition to streamlining container management for open-source applications it provides a highly distributed and scalable infrastructure for EMR, allowing users to focus more on executing their analytics workloads efficiently.
- Additionally, this solution optimises resource utilisation and simplifies infrastructure management, promising a more efficient and effective data processing experience. With Amazon EMR on Amazon EKS, users can conveniently submit Apache Spark jobs on demand on Amazon Elastic Kubernetes Service (EKS) without the need for provisioning EMR clusters.
Advantages over EMR on EC2
As our data platform previously relied on EMR on EC2 for handling analytics workloads, we embarked on a journey to assess our infrastructure needs and seek opportunities for optimization.
We used MWAA and its supported operators for EMR to create EMR clusters using EC2 nodes, add steps, and migrate data to the destination.
Through this exploration and recognizing the advantages mentioned below, it became evident that transitioning to EMR on EKS proved highly beneficial in deploying and managing our workloads.
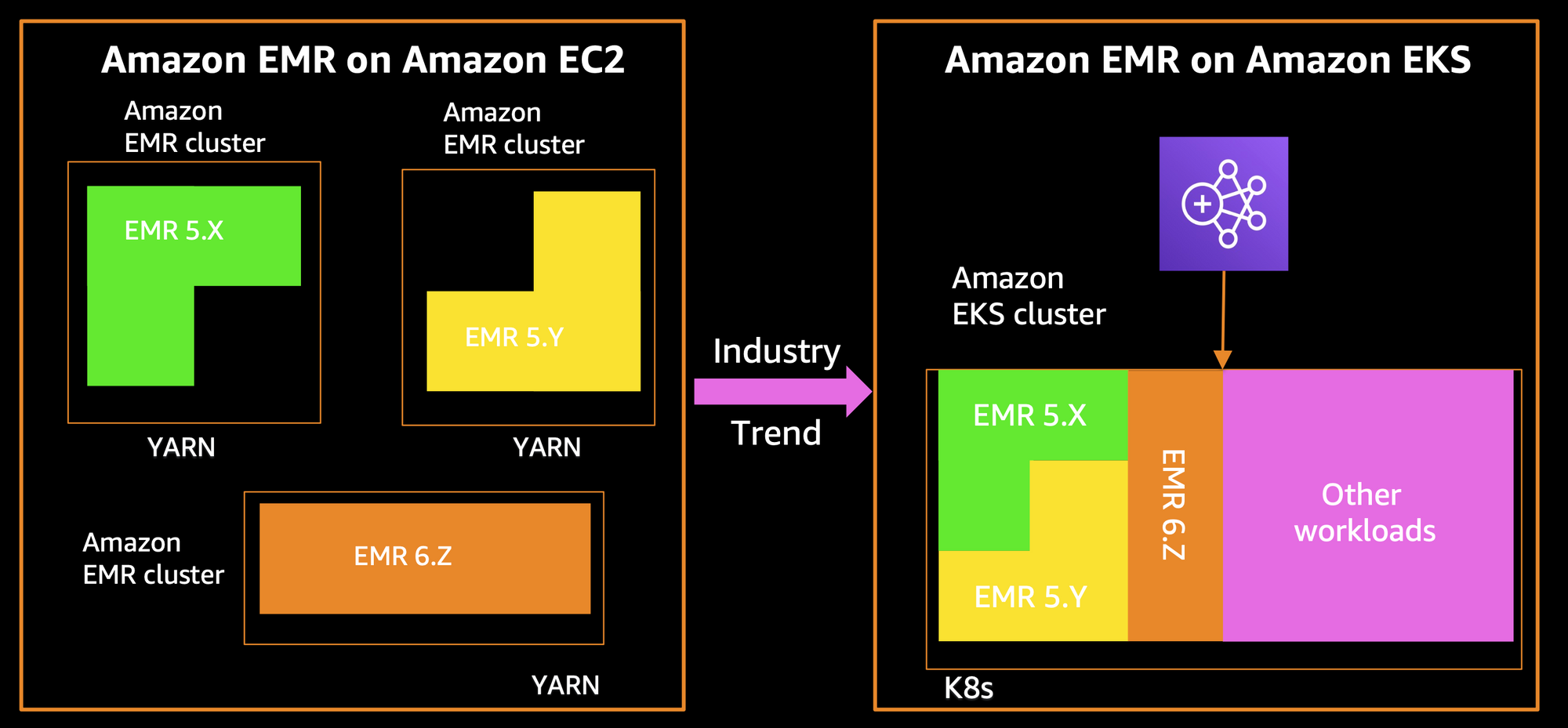
- Resource Utilisation: EMR on EKS offers improved resource utilisation by leveraging Kubernetes for container orchestration, ensuring efficient allocation of compute resources.
- Operational Simplicity: Jobs launch swiftly without cluster provisioning delays, starting instantly on EMR on EKS compared to potential 10-minute delays with Spark on Yarn.
- Flexibility and Scalability: With EKS, EMR clusters can dynamically scale based on workload demands, allowing for greater flexibility and scalability compared to EC2 instances. This lets us accommodate multiple versions of Spark on same EKS cluster and simplify Spark application upgrades.
- Cost Efficiency: EKS provides a more cost-effective solution by allowing users to optimize resource usage and scale down clusters during periods of low demand, reducing overall infrastructure costs.
- Enhanced Security: EKS offers robust security features, including native integration with AWS Identity and Access Management (IAM). The job-scoped execution role allows for fine-grained access controls, enhancing security measures.
Transforming our Data Platform with EMR on EKS
To kickstart this implementation, we needed to tackle the following basic setup:
- EMR on EKS implementation requires the creation of an EMR virtual cluster, backed by the robust EKS physical cluster infrastructure.
- Utilizing MWAA version 2.7.2 or higher is essential, as it supports the EmrContainerOperator class, enabling enhanced orchestration and management capabilities.
- Creation of IAM role named the Execution role with the required permissions to interact with EMR on EKS resources, in accordance with our data platform's security policies.
- We utilize Karpenter for streamlined node provisioning in our Kubernetes setup, dynamically allocating resources based on workload demands. This enables efficient scaling and resource management, ensuring optimal performance and cost-effectiveness.
In addition to the above fundamental set-up, we needed to configure the following features for smooth transition to EKS.
Custom image

- A custom image, varying based on the job type and containing the current EMR version and all required library installations, is built and made accessible in the Amazon Elastic Container Registry (ECR).
- The code retrieves this image from ECR and enables the utilization of all installed library functions seamlessly.
- The custom image considers factors like EMR version and other library dependencies.
- Adequate access to the designated execution role is granted to retrieve the uploaded image from ECR.
Pod Template Files
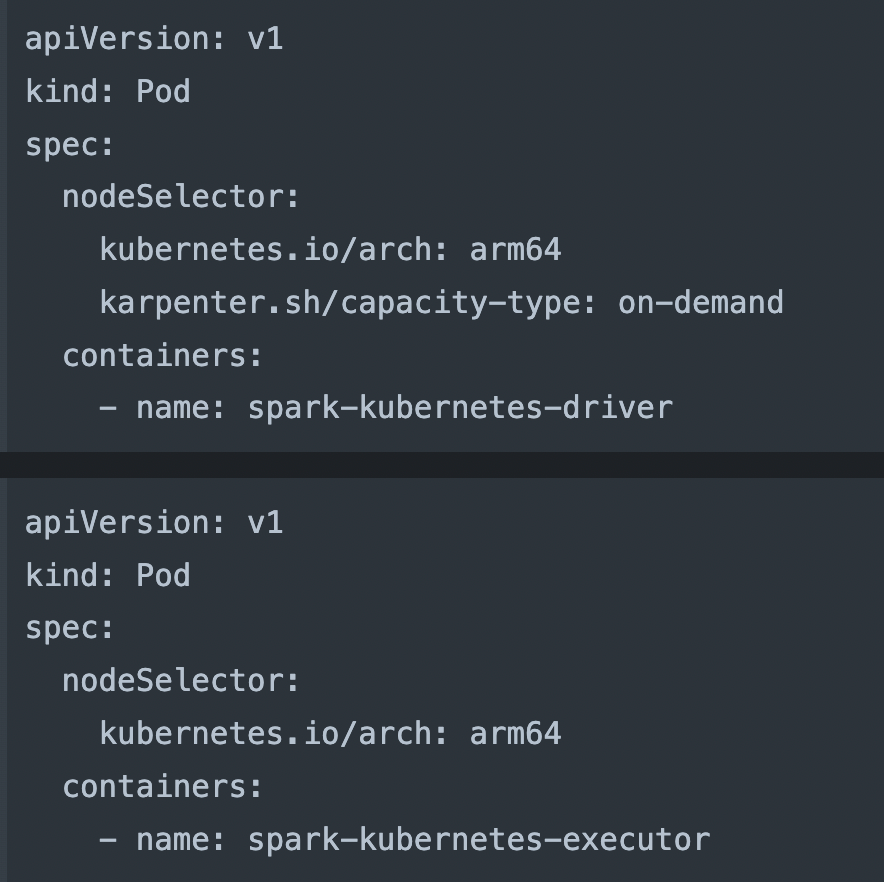
- Furthermore the code incorporates Pod template files, one for each driver and executor.
- These template files define configurations for the driver or executor pods, specifying how each pod runs.
- They contain specifications such as nodeSelector, which dictates the compatible K8 architecture for the pod instance, and containers, which specifies the container name.
- To address Spark job issues caused by randomly assigned EC2 instances, we explicitly specified the arm64 architecture in the Pod template, ensuring the creation of graviton EC2 instances.
- Additionally, we configured the driver pod to consistently run on an on-demand instance to prevent accidental job termination midway.
- Meanwhile, executor pods are set up to run on either on-demand or spot instances for flexibility.
Spark JARs

- To avoid compatibility conflicts caused from downloading jars from the open repository, we directly pull hudi-spark-bundle.jar from the local system of the custom image retrieved from ECR.
- We store other dependent jars in S3 and invoke them during job execution.
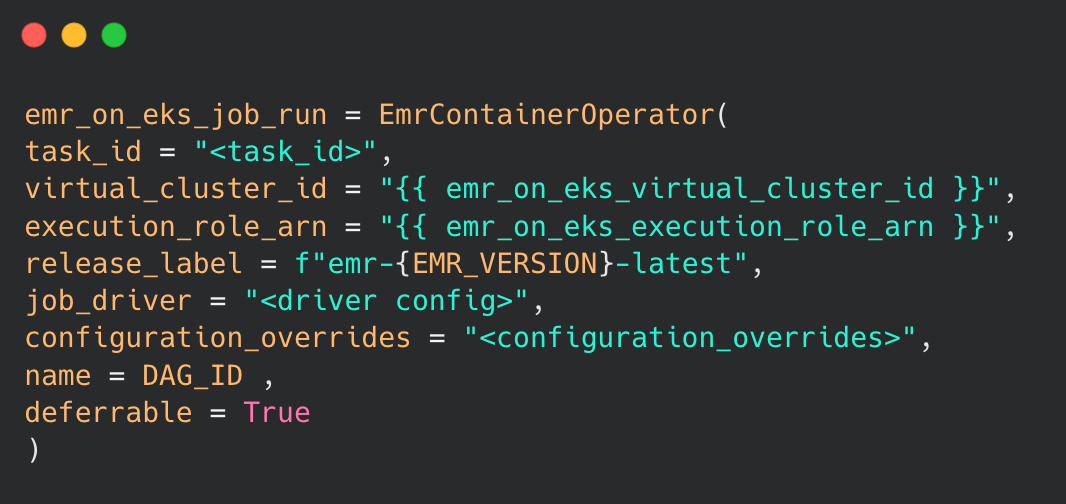
MWAA Integration
- The EmrContainerOperator in MWAA enables streamlined management of EMR on EKS jobs, offering real-time task cancellation for enhanced operational flexibility.
- This integration allows Airflow to automatically resubmit failed jobs, significantly improving job reliability.
- By leveraging EmrContainerOperator and Airflow, job management becomes more efficient and robust.
Insights Gained: Maximizing EMR on EKS
The implementation of EMR on EKS has drastically enhanced our data migration pipeline, notably cutting down job execution times and reducing costs. Furthermore, it grants granular control over spark and table-level configurations, a feature previously limited to selecting the appropriate EC2 instance. Here are key takeaways from our implementation that can guide the design of data pipelines using EMR on EKS.
- Our Karpenter's node consolidation feature is configured to terminate spot instances after a predetermined duration, a process that enhances cluster placement and optimizes resource utilization within the environment. We adjusted pipeline schedules to allow for the efficient reuse of existing operational instances, minimizing the necessity for creating multiple instances for each job and maximizing resource efficiency across the platform.
- In some cases, during migration, all available IPs in the range can be exhausted due to multiple secondary IP addresses assigned to executor instances. This situation can potentially slow down job execution. To mitigate this, we've adopted a staggered pipeline execution approach, distributing jobs across the hour to optimize IP usage and ensure smooth execution.
- With EMR on EKS providing finer control over node configurations and scaling, spark configurations such as executor instances, memory allocation, and core settings are fine-tuned based on the specific workload and complexity of each pipeline job. This optimization ensures superior performance, a significant improvement over the limited user control available with EMR on EC2, where adjustments were confined to EC2 cluster configuration rather than the spark jobs that are executed on these instances.
- Integration with MWAA's EmrContainerOperator enhances operational flexibility, allowing for seamless task cancellation on-the-go—a significant improvement compared to the termination-based approach of EMR on EC2, which lacked such real-time cancellation capabilities. Also Airflow resubmits failed jobs automatically a feature not available in EMR on EC2 due to separate submit and watch operators.
- We previously relied on an always-running EC2 based EMR cluster for high-frequency jobs, resulting in significant cost increase. By transitioning to EKS, we now use a virtual cluster and instances managed by Karpenter's node consolidation, eliminating unnecessary costs.
Outcome
- A remarkable 65% improvement in run duration has been observed, with the average time decreasing from 32 minutes to just 11 minutes across the onboarded pipelines.
- We've achieved over 25% cost savings with our migrated pipelines, and we anticipate even greater reductions as more pipelines transition to this efficient setup.
- Jobs now start promptly within 1-2 minutes, compared to the previous 15-minute average for cluster spin-up alone.
- Tasks in a DAG are submitted simultaneously, eliminating concurrency issues.
- EmrContainerOperator efficiently handles job submission and monitoring
- Tasks can be rerun individually from the DAG UI. Resource allocation is flexible, adjustable at the job level.
Conclusion
In conclusion, transitioning from EMR on EC2 to EMR on EKS has proven to be a game-changer for our data platform. With faster job start times, significant cost savings, and enhanced control over resource allocation, EMR on EKS offers a more efficient and flexible approach to managing analytics workloads. This shift not only optimizes resource utilization but also streamlines infrastructure management, paving the way for improved performance and scalability. EMR on EKS stands out as a superior solution, driving better outcomes and future-proofing our data processing capabilities.
References
Join us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. We recently closed our Series D round and In total have raised around USD$100+ million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.