Optimising EMR Cost and Simplifying Data Warehouse Transformation DAGs
Introduction
One of Halodoc's core values is that a Halosquad should always be fanatical about solving for patients, meaning that we have an obligation to the patient in solving their pain points in a way that covers all the underlying problems and helps them in the long term. As the data platform team, we have those obligations to the Business Intelligence team (BI for short).
One of the BI pain points is that as the business needs for data grow, so do the number of dimensions and fact tables. Each of the transformations to build said dimension and fact tables are handled in a single EMR (Elastic MapReduce) cluster that runs a Spark code. The Spark code orchestration and scheduling are handled in Airflow through a single DAG (Directed Acyclic Graph) for each transformation. When we first started our migration journey, this mechanism did not pose a problem. However, as more and more dimension and fact tables are built, two apparent problems started to appear:
- The cost of running EMR grows significantly through sheer volume alone. As of Q4 2022, we grew to 90 DAGs, and as it stands, EMR operation is the second largest cost component in our data lakehouse system.
- The large number of Airflow DAGs lead to complexity in DAG building and maintenance. One must build one DAG for each table built.
It became apparent then that we must proactively solve these pain points so that in the long-term, the BI team can serve the business needs without sacrificing ease of use, maintainability, and cost-effectiveness.
Current Implementation
In the current architecture, each DAG is responsible for exactly one transformation for exactly one data warehouse table, which runs on a single EMR cluster. The figure below represents how we are doing our transformation currently:
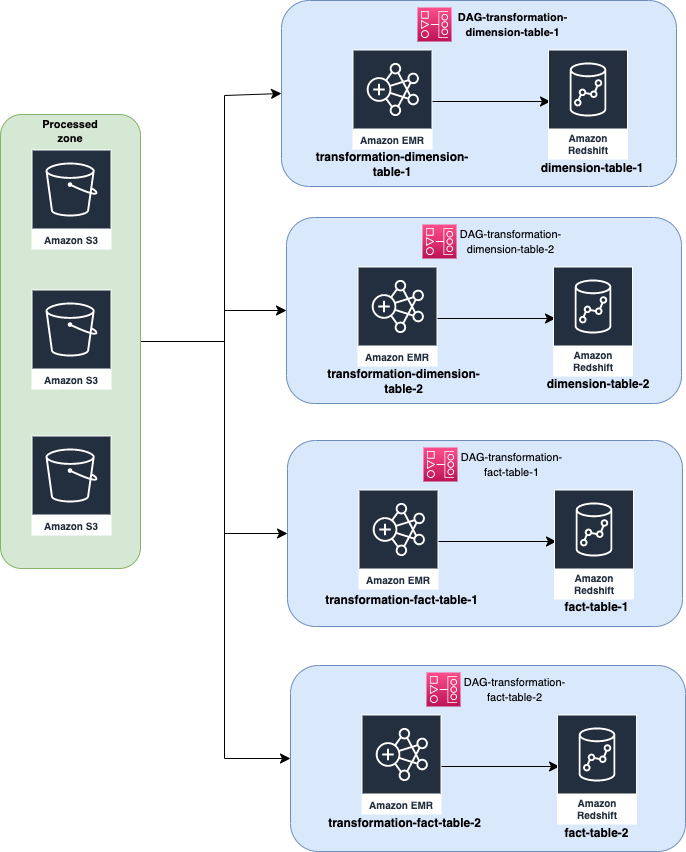
When we started designing the solution to this problem, we observed that the transformation can be clustered into three major groups: dimension transformation, fact transformation, and report transformation. The tables under these major groups can also be clustered based on the business units (e.g., pharmacy delivery, teleconsultation, appointment, etc.) We also find that the clustering can be made in a more “tech” manner i.e., clustering the DAG based on the load of each transformation as some transformations handle heavier workloads compared to other transformations. The second observation that we made is that each of the EMR clusters running the transformation doesn’t perform to its 100% capacity, meaning that we have more leeway on our existing EMR cluster configuration to add more tasks without sacrificing performance.
Apart from the observations we made above, we also need to consider three constraints to our solutions: ease-of-use, execution SLA, and cost efficiency. Ease-of-use means the new design should be:
- easy to monitor,
- easy to operate,
- easy to reason about (i.e., ideally the DAG should be able to be described by glancing at its name alone.)
The new DAG should not sacrifice execution SLA, meaning the transformation should be completed in the most efficient manner possible. There is also the EMR cost efficiency that needs to be considered, given that EMR operation cost is the second largest behind S3 API calls.
Solutioning Process
Given the observation we’ve made and the constraints that we need to consider, we come up with the following approach:
- Each transformation is grouped based on its commonality (i.e., table type and business unit.)
- Increase the concurrency level of the EMR cluster.
The commonality-based grouping strategy will reduce the cost associated with running EMR clusters by reducing the volume of EMR clusters. One does not need to create a new DAG for every table built, it is enough to only specify under which business unit the data warehouse will belong and what type of table it is. It also increases the efficiency of BI engineers when building a new table or maintaining old ones, since everything is grouped under one DAG and one EMR cluster. The drawback of this approach is that by default EMR runs each transformation on a first in first out basis i.e., one transformation must be completed before the next transformation will be executed by the EMR.
To mitigate the increasing SLA because of the way EMR executes spark-step by default, we introduce a new configuration while creating the EMR cluster, namely StepConcurrencyLevel. This configuration allows EMR to run several spark steps simultaneously, depending on the concurrency level we set on the mentioned configuration key. To achieve this concurrency, we went with the YARN CapacityScheduler capability in Hadoop because we want more control over the resource allocation so that we can tweak and customise the setting freely. CapacityScheduler is Hadoop’s scheduler that allows multiple applications to share a cluster and allocates the cluster’s resources in a timely manner under predefined allocated capacities. In our implementation, we divided the cluster into three queue groups, each having 30% of the total cluster resources, to begin with. We set aside 10% capacity for default workflows. We set the step concurrency level to 4, meaning that at any given time, the EMR cluster will execute 4 spark steps in parallel. These configurations (table type, business unit, and queue groups) can be set and modified through our metadata tables, thanks to our decision for a metadata-driven architecture. The below figure shows what the new design looks like in principle.
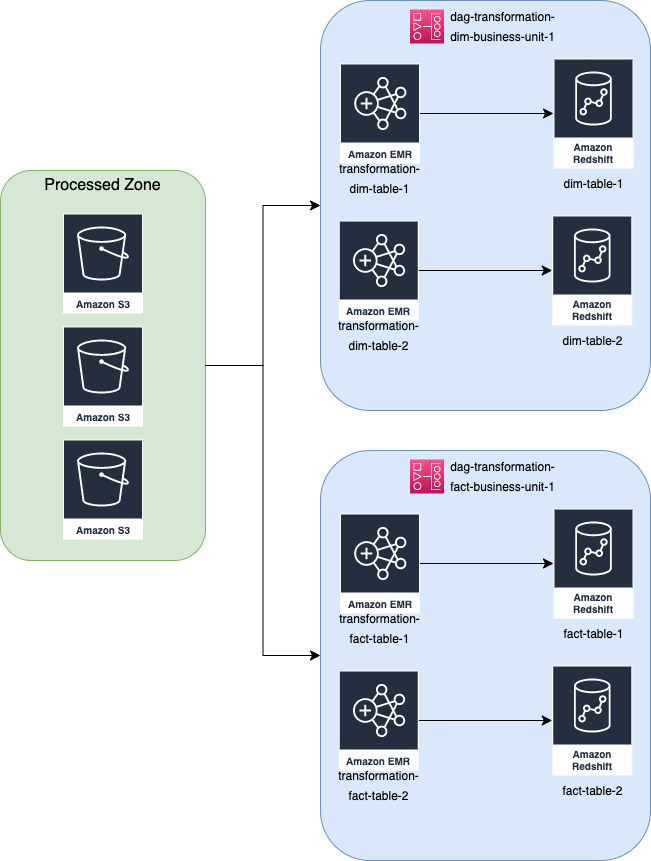
To achieve this grouping, we utilise TaskGroup functionality in Airflow. Task group allows us to dynamically add or remove transformation tasks according to the metadata recorded in the metadata table.
Limitations
However, there are limitations to this approach which directly ties to the SLA of table delivery. The DAG design can run 4 jobs in parallel, but the rest of the jobs will still need to wait in queue for these 4 jobs to be completed. If the number of transformations for a given business unit is still in the 10 – 16 range, the SLA is still acceptable, but more than that, we will compromise the convenience and cost at the expense of table delivery SLA, which we don’t want. In the current implementation, we limit the number of jobs to 16. If the BI team wants to add more transformation, then a new DAG should be created.
Results
Through these approaches of merging multiple DAGs into a single DAG and introducing concurrency to the Spark job, we’ve managed to accomplish two major things:
- We reduced the number of Airflow DAGs considerably. For transformation logic, we went from 93 DAGs to 16 DAGs (almost a 95% reduction). This reduction of DAGs and the ease of usage that comes with it allows the BI engineers to focus on building the dimension and fact tables instead of having to build and maintain Airflow DAGs.
- The cost associated with EMR operation was also slashed by 50%. This reduction strongly correlates with the number of reduced DAGs.
In addition, we also managed to preserve, and in some cases, improve the SLA of the table delivery. Previously, each transformation job took 10+ minutes to run due to the necessity of the bootstrapping process in the EMR cluster. With the introduction of the current DAG design, this bootstrapping process does not need to run each time a transformation job is run. The total time it took for a business unit’s data warehouse transformation is 15 minutes for dimension tables and 45 minutes for fact tables, and each DAG contains at most 10 transformations, so each table is completed in 2 – 5 minutes on average since the transformation job is submitted.
Possible Future Improvements
While the current design implementation offers a significant reduction in cost and operationalisation, some improvements can be implemented in the future, such as using EMR serverless instead of an on-demand cluster. This will eliminate the need to pick the appropriate cluster for transformation jobs and potentially reduce the cost of EMR even more, but further analysis on the how and what of EMR serverless needs to be conducted before we commit to using the serverless service, such as the pricing structure, the possibility to limit the resource usage, and how does it achieve concurrency.
About Halodoc
Halodoc is the number 1 all-around healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. We recently closed our Series C round and in total have raised around USD$180 million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalized for all our patient's needs and are continuously on a path to simplify healthcare for Indonesia.