

Claim Adjudication: Imbalance Dataset and tackling it using ML
Halodoc is a health-tech platform aiming to simplify access to healthcare for millions of people around Indonesia. Over the years, the Data Science has played an important role in the growth and development of Halodoc, through its application ranging from analytics, data science, machine learning, and statistics for solving real business problem. One such problem we've solved using ML is in the Insurance domain, called Claim Adjudication.
On this blog, we will talk about how we tackled the Imbalance Datasets using ML, for solving the Claim Adjudication problem.
Claim Adjudication
A claim is a request for payment that a member or healthcare provider submits to a health insurer for items and services that may be covered by the insurer. Healthcare organizations use these documents to seek reimbursement from insurance companies. The claims adjudication process checks for accuracy and relevancy, taking into account a member's benefits before deciding whether the claim will be covered by the insurer.
The claims adjudication workflow generally follows this path:
- The claim is accepted into the system and given a basic information check to ensure that it is not a duplicate, the patient's personal information is correct, and there are no omissions or errors on the claim.
- The claim then moves on to a detailed information check, which looks for diagnosis and procedure codes and verifies the patient's ID and date of birth against the insurer's records.
- Finally, a decision is made on the claim: it is either paid (full or partial), pending, or denied.
Imbalance Dataset on Claim Adjudication Data
Imbalanced data can occur in health insurance claims for a number of reasons.
- Relative frequency of different types of claims.
One reason is that some types of claims are more common than others. For example, claims for routine medical procedures may be more common than claims for rare or complex medical conditions. This can lead to an imbalance in the data, with a large number of observations for the more common claims and a smaller number of observations for the less common claims. - The likelihood that different policyholders will file claims.
Another reason for imbalanced data in health insurance claims is that some policyholders may be more likely to file claims than others. For example, policyholders with chronic medical conditions may be more likely to file claims for medical treatment than policyholders who are generally healthy. This can also lead to an imbalance in the data, with a larger number of observations for policyholders who file more claims. - Fraudulent behavior.
Imbalanced data can also occur in health insurance claims due to fraudulent behavior. In some cases, individuals may attempt to file false or exaggerated claims in order to receive payments from the insurer. This can lead to an imbalance in the data, with a small number of fraudulent claims mixed in with a larger number of legitimate claims.
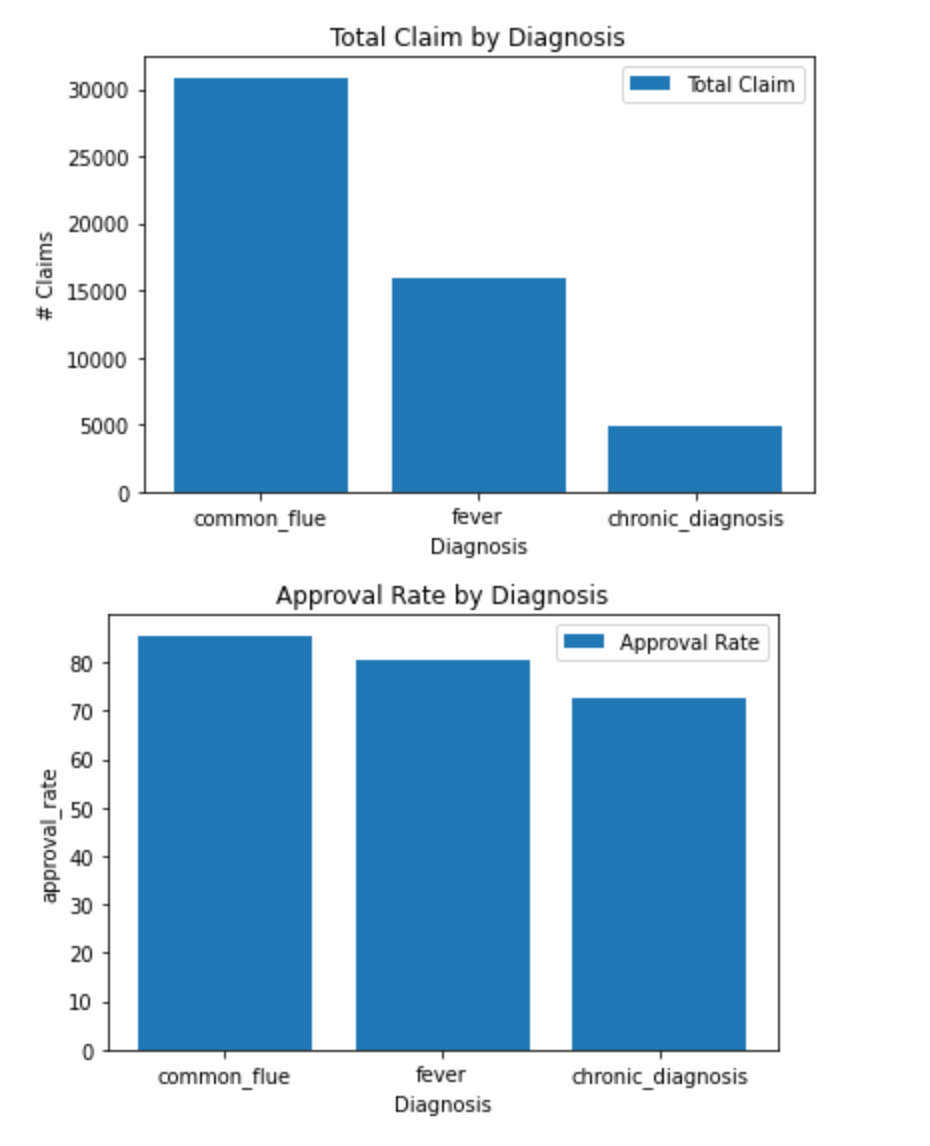
Overall, imbalanced data in health insurance claims can occur for a variety of reasons, including the relative frequency of different types of claims, the likelihood that different policyholders will file claims, and fraudulent behavior. This can make it challenging to accurately predict and classify health insurance claims using machine learning algorithms.
Tackling Imbalance Dataset
On general there are 3 approaches to tackle imbalance dataset :
1.Sampling methods
In our case, the imbalanced data set is not due to a lack of data, but rather to the distribution of the claims. As a result, we have decided not to use under-sampling or over-sampling to balance the data set.
2. Ensemble classifiers and weighting factor
We are building different (manually and automatically) models for different situations, such as separate models for common illnesses/routine medical procedures and chronic medical conditions. By using ensemble classifiers, we hope to improve the accuracy and efficiency of our claims processing.
Weighted factor is a technique used to balance imbalanced datasets by assigning higher weights to the minority class observations. This can help the model to better identify the minority class observations, as they will have a larger impact on the model's decision boundary. This can be done by specifying the class weights when training the model.
For example, to assign a weight of 2 to the minority class and a weight of 1 to the majority class, you can specify the class weights as follows:
# Train a model using class weights
class_weights = [1, 2]
model = RandomForestClassifier(class_weight=class_weights)
model.fit(X_train, y_train)You can also use the compute_class_weight function from scikit-learn to automatically compute the class weights based on the frequency of the classes in the training data:
# Compute the class weights based on the frequency of the classes in the training data
from sklearn.utils import compute_class_weight
class_weights = compute_class_weight(class_weight='balanced', classes=np.unique(y_train), y=y_train)
# Train a model using class weights
model = RandomForestClassifier(class_weight=class_weights)
model.fit(X_train, y_train)
Using a weighting factor can help to improve the model's performance on the minority class by giving more importance to these observations during training. However, it is important to carefully evaluate the performance of the model using multiple metrics to ensure that the weighting factor is appropriate for the specific dataset and use case.
3. Threshold adjustment (technical metrics)
Threshold adjustment is a technique used to improve the performance of a model on imbalanced datasets by adjusting the classification threshold. The classification threshold is the point at which a prediction is considered positive or negative. By default, most classification algorithms use a threshold of 0.5, meaning that a prediction is considered positive if the predicted probability is greater than or equal to 0.5. However, in imbalanced datasets, this default threshold may not be optimal.
There are several ways to adjust the classification threshold in order to improve the model's performance on imbalanced datasets. One approach is to use a metric-based threshold, where the threshold is selected based on a metric such as precision, recall, or F1 score. For example, to prioritize sensitivity (the ability to correctly identify positive cases) over specificity (the ability to correctly identify negative cases), the threshold can be adjusted to increase the recall.
F1 = 2 * (precision * recall) / (precision + recall)
precision = TP / (TP + FP)
recall = TP / (TP + FN)

To implement threshold adjustment in Python, you can use the scikit-learn library. Here's an example of how to adjust the classification threshold based on the recall:
# First, split the dataset into input features (X) and target labels (y)
X = df.drop('target', axis=1)
y = df['target']
# Next, split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Train a model on the training data
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Predict the probabilities of the test data
y_probs = model.predict_proba(X_test)[:,1]
# Calculate the precision and recall for various thresholds
from sklearn.metrics import precision_recall_curve
precision, recall, thresholds = precision_recall_curve(y_test, y_probs)
# Find the threshold with the highest recall
threshold_index = np.argmax(recall >= 0.75) # Set recall threshold
threshold = thresholds[threshold_index]
# Make predictions with the adjusted threshold
y_pred = y_probs >= threshold
# Calculate the accuracy
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy: ', accuracy)
Alternatively, you can manually specify the classification threshold when making predictions. For example:
# Predict the probabilities of the test data
y_probs = model.predict_proba(X_test)[:,1]
# Manually specify the classification threshold
threshold = 0.3 # Set threshold
# Make predictions with the adjusted threshold
y_pred = y_probs >= threshold
# Calculate the accuracy
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy: ', accuracy)Threshold adjustment can only be used with models that output probability estimates. It may not be suitable for all types of models.
Our Result
We want to ensure that our model is able to handle multiple loss functions effectively. To do this, we will use the F1 Score with a variety of loss functions :
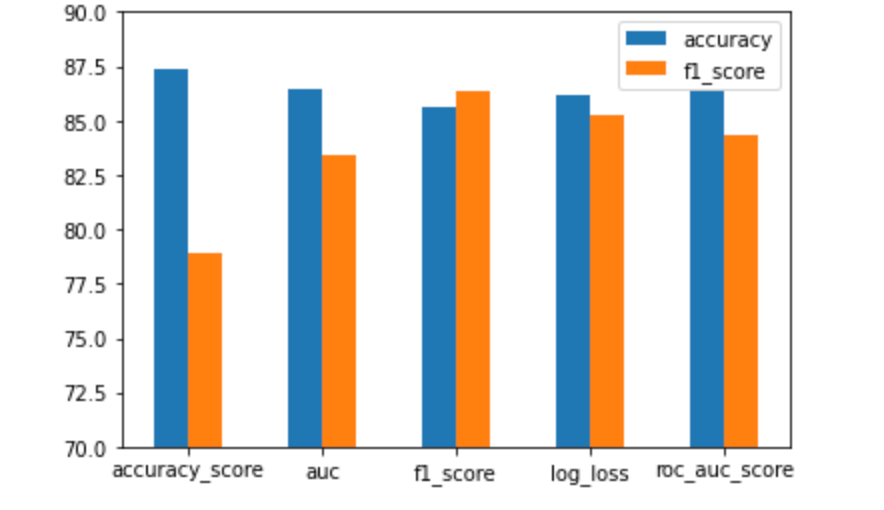
Our experiment shows that the combination of ensemble classifiers, weighting factors, and threshold adjustments result in an F1 Score and accuracy of approximately 80%-90%. The best performance was achieved with the F1 Score and Log loss/cross entropy, both of which had an F1 Score of 85% and an Accuracy of 85%.
Impact on Our Business
Claims administration and adjudication represent a significant portion of costs for healthcare providers and payers. These costs are driven largely by the complexity of the adjudication process, which varies across payers and often involves manual input and review. This can lead to significant time delays for patients and represents a large share of administrative expenses.
In order to improve the efficiency of the claims adjudication process, we are working on building a flow for system validation that will reduce the number of claims that need to be adjudicated manually. This will help the claims team to process claims more efficiently and allow the business to scale. By reducing the cost of operation, we hope to improve the overall performance of the claims adjudication process.
Summary
It is important to carefully evaluate the performance of different approaches to handling imbalanced datasets in order to choose the one that is most appropriate for the specific dataset and use case. It may be necessary to use multiple techniques in combination to achieve the best results. It is also important to use the right evaluation metrics, such as the F1 score to fully assess the model's performance.
Join us
We are looking for experienced Data Scientists and ML Engineers to come and help us in our mission to simplify healthcare. If you are looking to work on challenging data science problems and problems that drive significant impact to enthral you, check all the available data jobs on Halodoc’s Career Page here.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek and many more. We recently closed our Series C round and In total have raised around USD$180 million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


