

Harnessing the power of AI/ML through Graph based Product recommendations at Halodoc
Solving customer problems and improving customer experience at scale is always our primary goal at Halodoc. With 11k+ products in our assortment which consist of medical products, herbal products, non medicinal products such as skin care and medical devices, we strive to enable our customers make highly informed decisions to purchase products based on their underlying need.
The Data Science team at Halodoc ventured onto surfacing relevant products based on the items already on the cart to the user which will enable them to find the products they've been looking for faster. We gathered the orders data and decided to build a recommendation engine based on these products which are frequently bought together. In order to build this recommendation engine, We initially looked at the collaborative filtering that was the basis of multiple giant companies’ recommendation engines. However, we decided to take another approach by representing the products in a big graph and capturing the product interactions in the edges of the graph. In this post, we will describe the data that we used, how we built the graph, how we evaluated our system and the different cases where our engine fails and how to potentially improve it.
Building baseline for product recommendations :
In the initial version, we looked into Association Rule mining, leveraging Market basket analysis- FP growth algorithm. Association Rule Mining, as the name suggests, association rules are simple If/Then statements that help discover relationships between seemingly independent relational databases or other data repositories. Association rule mining is a procedure that aims to observe frequently occurring patterns, correlations, or associations from datasets found in various kinds of databases such as relational databases, transactional databases, and other forms of repositories.
At Halodoc, all the Pharmacy Delivery orders are present in Order Management System, and products are linked using an inventory_id. This database, can be called a “market basket” database, consists of a large number of records on past transactions. A single record lists all the items bought by a customer in one transaction. Knowing which groups are inclined towards which set of items gives us the freedom to adjust the catalog to place the optimally concerning products one another, nudge users to buy “products usually bought together” and recommend products based on orders history.
While working on the Association rule mining, the 11k SKUs in out inventory posed a challenge since only 2% of items are frequently bought together vs the rest. In order to resolve this and have a better understanding of the pharmacy products, we decided to tie all SKUs together with their ATC (Anatomical Therapeutic Chemical) codes. ATC codes - is a unique code assigned to a medicine according to the organ or system it works on and how it works, and different manufacturers can have their own product using product formula.
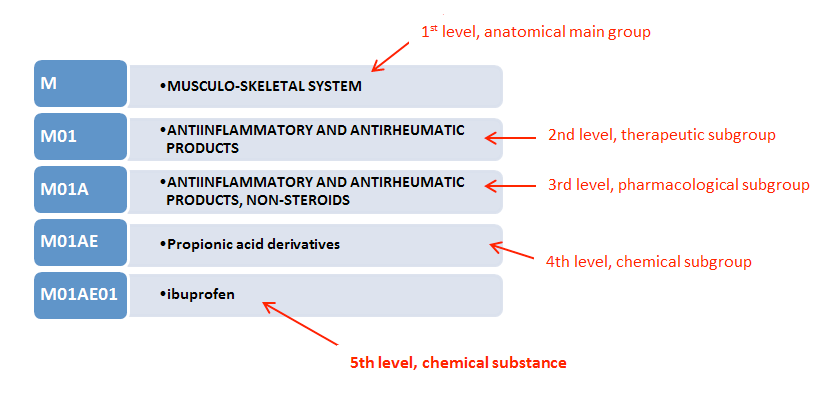
Eg: Cipla and Sun pharmaceuticals both manufacture paracetamol 650mg, but their product names are different.
By computing the association rules at ATC code level, we were able to get significant relations between Antecedents(ATC that will be recommended for ) and Consequents(Recommended ATC),But since we would need to recommend customers products, for antecedents we mapped ATC codes to their respective Products and for consequents, we retrieved top 5 sold products in terms of GMV for consequent ATC code.
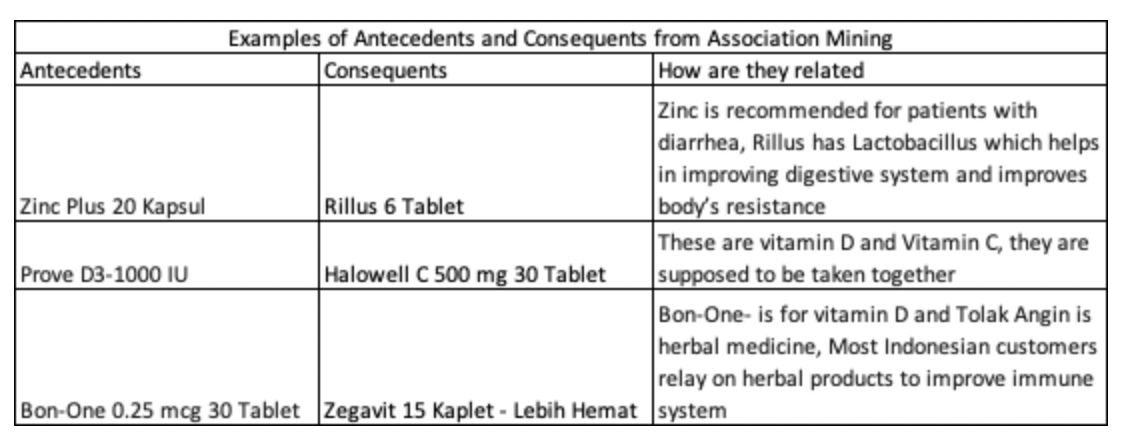
What were the limitations of Association mining ?
While the initial results were significant, and the recommendations looked good
- The coverage of SKUs is small due to sparse product distributions,
- Static product recommendations for products within same ATC, recommendations aren't customized as per manufacturer, brand or dosage etc
- Products which did not follow any hierarchy aren't included.(eg: medical devices, herbal products etc)
What's Next?
We need to increase the coverage of products including medical devices, herbal products etc and our recommendations need to be dynamic based on individual product attributes(like the manufacturer, brand, dosage etc). Recommended products should also account the intent for purchase (diagnosis, underlaying medical issue etc).
While existing recommender systems like content based filtering work on product level recommendation, they don't capture the sequence of items bought together. Since for making a purchase, a user is trying to buy for an underlying need/ problem and to surface products we need to first identify the intent based on the sequence the customer adds items into the cart and recommend accordingly.
Understanding the Intent of the User for making the purchase
To understand the intent of the purchase and relationships of the products which are bought together, we borrowed a classic NLP method, Word2Vec, we call it Product2Vec.
You shall know a word by the company it keeps" — J. R. Firth
We built out a network graph to understand how products are related to one another. Each node represents individual products and the edge weight represents the number of orders those products are bought together. From below network graph we can observe that Paracetamol tablet has Sanmol, Rhinos, Becom tablets and many other relevant products (with a direct edge) for body pains, headaches ,vitamin supplements that are usually bought when someone buys Paracetamol for fever.
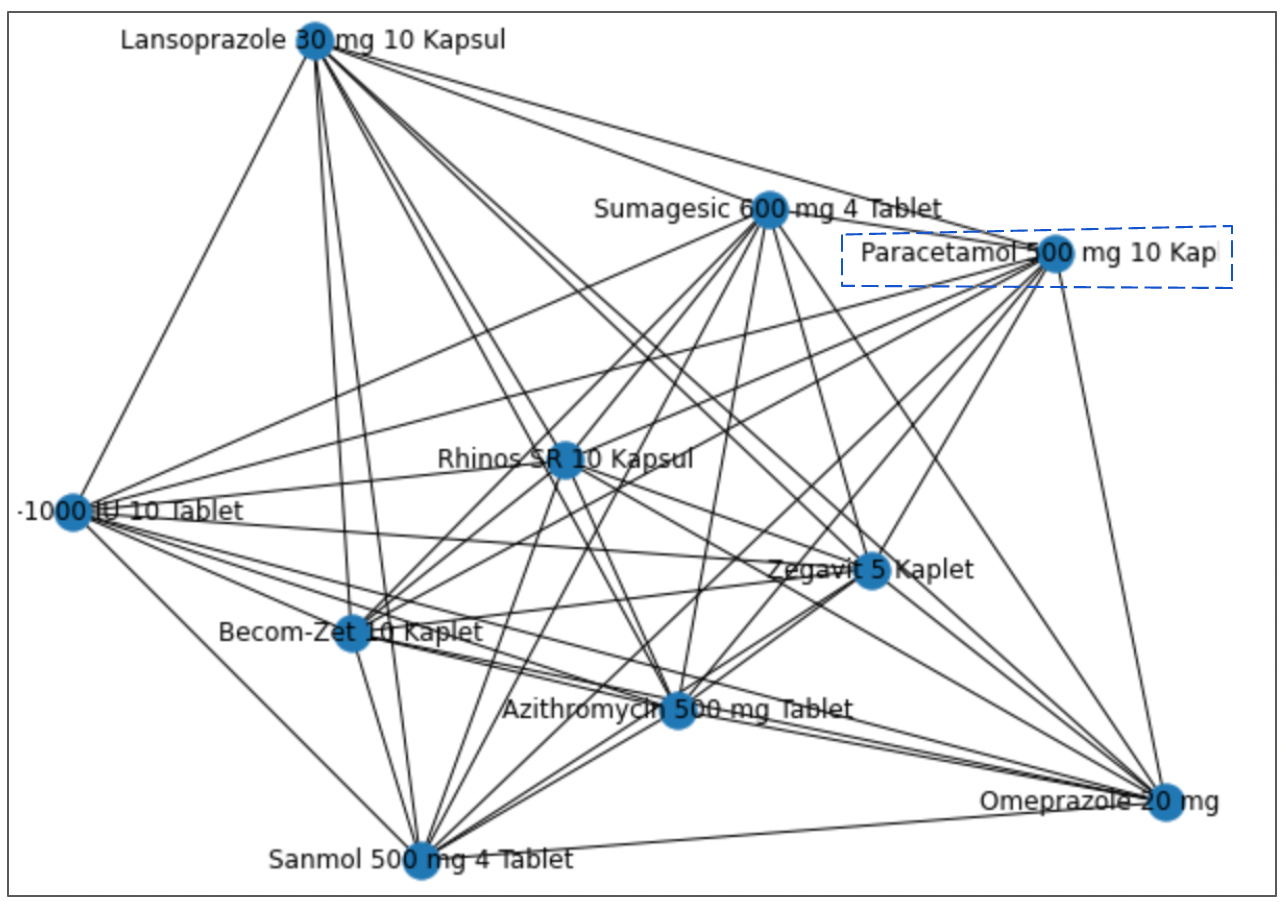
Learning relationships from the graph and enriching the recommendations :
- Based on the graph we constructed earlier, we've put threshold to edge weight to remove isolated edges so as to remove combination of items which aren't significant based on edge weight distribution.
- Generated random walk across different nodes to create sequences of products that are bought together
- Used these sequences to build skip gram word2vec model to generate product embeddings
- From the generated word2vec model, compute cosine similarity for products to identify similar products
- These similar products are the recommended products for a SKU.
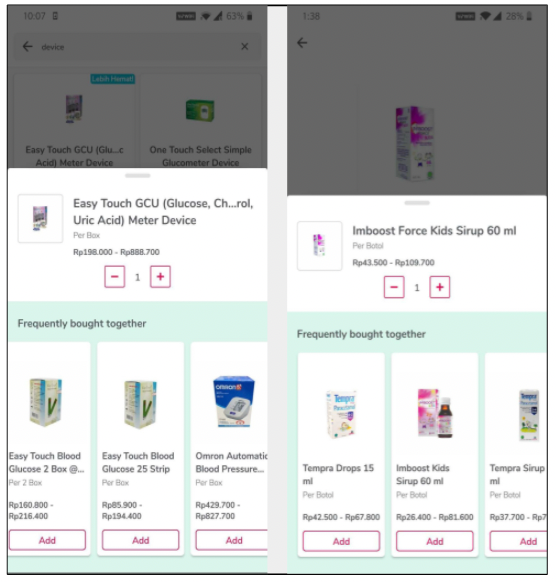
Our live Product recommendations example :
How did we scale the framework in Production?
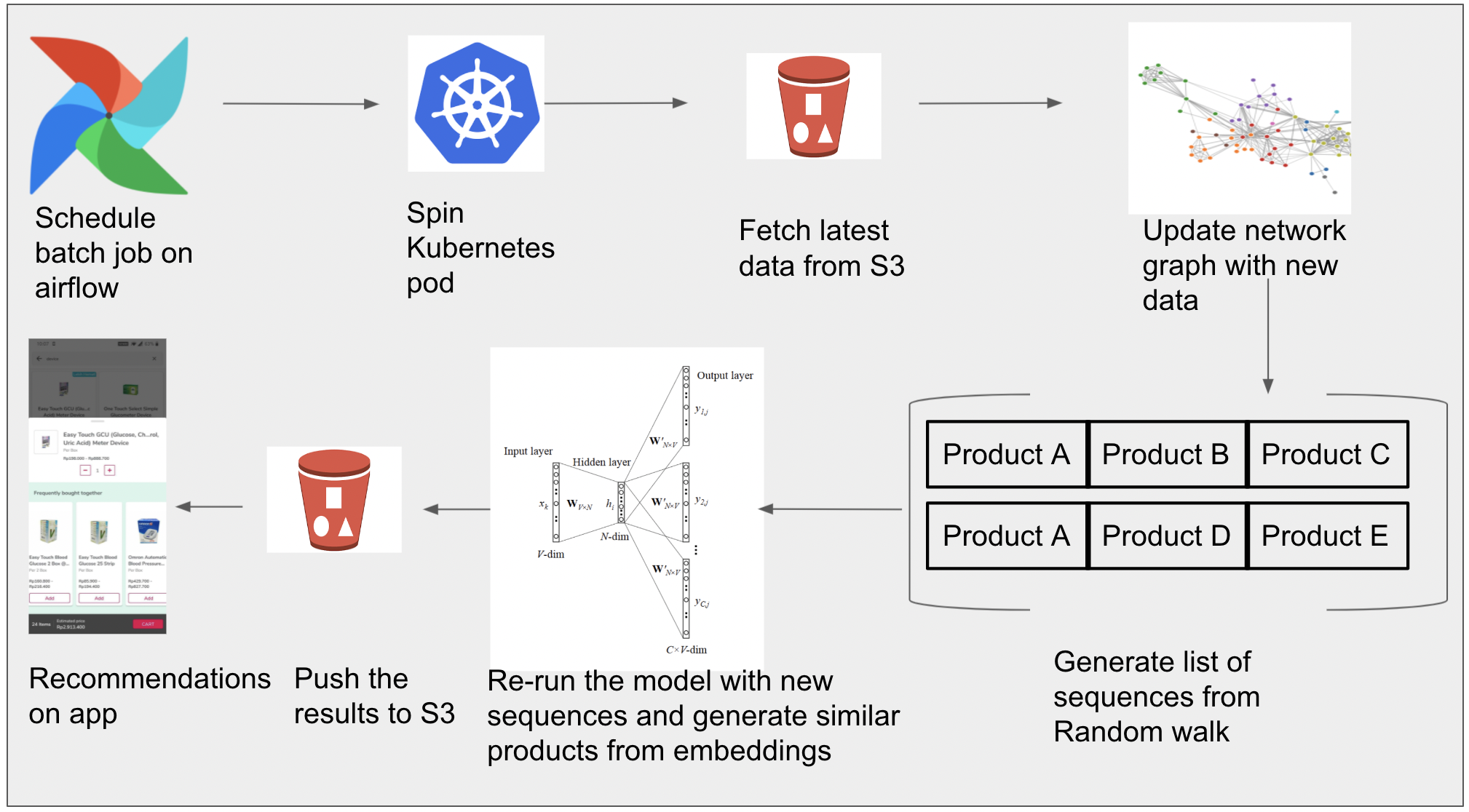
- We used airflow and kubernetes to schedule batch jobs (refer)
- Built network graph with historic data and saved the graph through networkx library
- Append the weekly data to the pre-saved network graph and generate sequences from the updated graph
- Generate similar products for the newly created word2vec model based on new generated sequences
Impact:
- We have seen 4% GMV increase due to this feature
- Our Basket value increased by 69% for orders which used this feature
- Interestingly, Cart-to-order conversion of customers who've used this feature had higher ratio as compared to non users by 54%
Further Improvements :
- Use Substitutive products(based on composition and product type) for recommendations incase of new or out of stock products thereby increasing coverage to entire inventory
- Create multivariate graphs which includes item and customer attributes that would cater recommendations at personalised level
Join Us
We are looking for experienced Data Scientists, NLP Engineers, ML Experts to come and help us in our mission to simplify healthcare. If you are looking to work on challenging data science problems and problems that drive significant impact to enthral you, reach out to us at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek and many more. We recently closed our Series C round and In total have raised around USD$180 million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalized for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


