

Feature Engineering on Demand Prediction
Demand prediction is a critical task in the pharmaceutical industry, particularly in the context of pharmacies. Pharmacies need to accurately predict the demand for drugs to ensure that they have enough inventory to meet the needs of their customers. In this blog post, we will explore how machine learning (ML) can be used to tackle demand prediction for drugs in pharmacies.
Understanding the Data
Before we dive into the ML techniques for demand prediction, let's take a look at the data. The data we will be using is the historical sales data for drugs in a pharmacy. The data includes information such as the drug name, the quantity sold, the date of sale, and the price. Our task is to predict the future demand for each drug in the pharmacy for a given period of time, based on the historical sales data.
Why is Feature Engineering Important?
Feature engineering is a critical step in building predictive models for demand forecasting. Here are some key reasons why it matters:
- Enhanced Model Performance
Well-engineered features can capture underlying patterns and relationships in the data, leading to more accurate predictions. By selecting the right features and transforming them appropriately, you can extract valuable information that might be hidden in the raw data. - Improved Interpretability
Feature engineering can make your models more interpretable. By creating meaningful features, you can gain insights into which factors are driving demand and how they impact your predictions. This knowledge is invaluable for making informed business decisions. - Handling Non-linearity
Real-world demand data is often non-linear, and feature engineering allows you to transform variables to better fit the assumptions of your chosen machine learning algorithm. This can result in better model performance.
Feature Engineering
Feature engineering is the process of selecting and transforming relevant features from the raw data to improve the performance of ML models. In demand prediction for drugs on pharmacies, some of the most important features are:
- Time-based features: These features capture trends and patterns over time. Examples include day of the week, month, year, and holidays.
- Store-based features: These features capture pharmacy-specific characteristics. Examples include the location of the pharmacy, the size of the pharmacy, and the customer demographics.
In addition to these features, external factors such as economic conditions, weather conditions, and cultural event can also be taken into account.
1. Time-based features
Time-based features are an important category of features that can be used in demand prediction for drugs on pharmacies. These features capture trends and patterns over time and can help the ML model to better understand the dynamics of the demand for drugs.
Some examples of time-based features that can be useful for demand prediction are:
- Day of the week: Many drugs have different demand patterns depending on the day of the week. For example, pain relievers may be more in demand on weekdays, while sleep aids may be more in demand on weekends.
- Month: Seasonal changes can have a significant impact on the demand for drugs. For example, allergy medications may be more in demand during the spring and summer months.
- Year: Long-term trends can also have an impact on the demand for drugs. For example, the demand for certain drugs may increase or decrease over time due to changes in demographics or health trends.
In Python we can convert the data into time-based feature, create a lag feature, and rolling window using pandas , example :
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# Load the sales data
sales_data = pd.read_csv('sales_data.csv')
# Convert the date column to a datetime object
sales_data['date'] = pd.to_datetime(sales_data['date'])
# Create time-based features
sales_data['day_of_week'] = sales_data['date'].dt.dayofweek
sales_data['day_of_month'] = sales_data['date'].dt.day
sales_data['month'] = sales_data['date'].dt.month
sales_data['quarter'] = sales_data['date'].dt.quarter
sales_data['year'] = sales_data['date'].dt.year
sales_data['day_of_year'] = sales_data['date'].dt.dayofyear
sales_data['week_of_year'] = sales_data['date'].dt.weekofyear
# Create lag features
sales_data['lag_7'] = sales_data['demand'].shift(7)
sales_data['lag_14'] = sales_data['demand'].shift(14)
sales_data['lag_21'] = sales_data['demand'].shift(21)
sales_data['lag_28'] = sales_data['demand'].shift(28)
# Create rolling window features
sales_data['rolling_mean_7'] = sales_data['demand'].rolling(window=7).mean()
sales_data['rolling_mean_14'] = sales_data['demand'].rolling(window=14).mean()
sales_data['rolling_mean_21'] = sales_data['demand'].rolling(window=21).mean()
sales_data['rolling_mean_28'] = sales_data['demand'].rolling(window=28).mean()
There are some pros and cons to using time-based features in demand prediction.
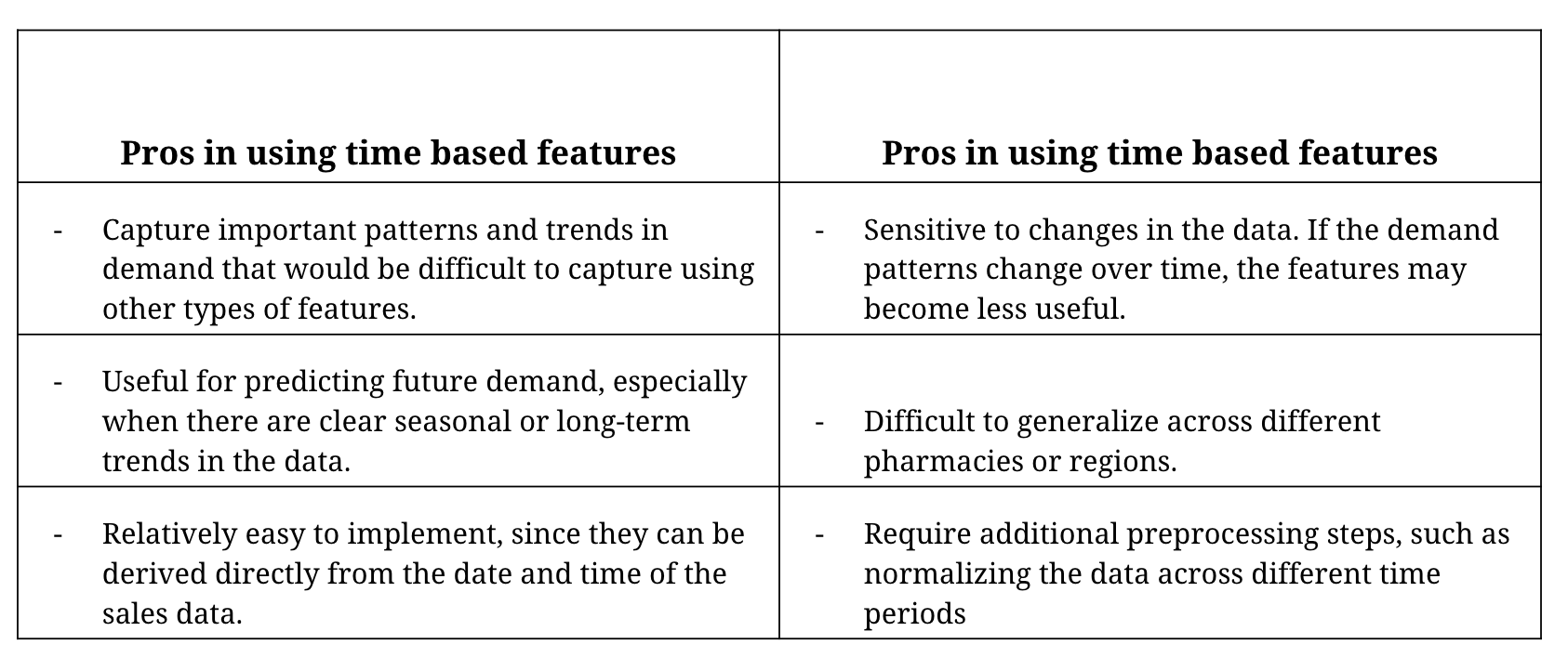
Here are some tips for incorporating time-based features in your ML model for demand prediction:
- Use a variety of time granularities: Different time granularities, such as day, week, or month, may be relevant for different drugs. Experiment with different granularities to find the most useful features.
- Use rolling windows: Instead of using static time-based features, consider using rolling windows to capture the recent trends in demand. For example, you could use the average demand over the past week as a feature.
- Consider the time horizon: The time horizon for demand prediction can vary depending on the needs of the pharmacy. For example, some pharmacies may need to predict demand on a daily basis, while others may need to predict demand on a weekly or monthly basis. Make sure that the time-based features you use are appropriate for the time horizon of the prediction.
2. Store-based features
Store or pharmacy-based features are a type of feature engineering technique used in demand prediction for drugs on pharmacies using machine learning. This technique involves adding features related to the store or pharmacy where the drugs are sold, such as location, size, and the number of employees.
Store-based features can provide valuable insights into demand patterns that are specific to a particular store or location. By understanding the unique characteristics of each store, pharmacies can better forecast demand and optimize their inventory levels.
We can use geographic coordinates to augment feature sets involves gathering latitude and longitude data for each store's location. These coordinates can be leveraged to ascertain whether a store is situated in a suburban, downtown, or urban area. To convert latitude and longitude values into categories like "suburb," "downtown," or "rural," you can use geospatial data or external APIs that provide information about the location. In Python we can use geopy library to demonstrate how to do this based on proximity to predefined locations:
from geopy.distance import great_circle
# Define coordinates for reference locations (e.g., downtown, suburb, rural)
# Example downtown,suburb,rural coordinates (latitude, longitude)
downtown_coords = (40.7128, -74.0060)
suburb_coords = (40.7459, -73.9804)
rural_coords = (40.8256, -74.2207)
# Function to categorize a given latitude and longitude
def categorize_location(latitude, longitude):
location_coords = (latitude, longitude)
# Calculate distances to reference locations
downtown_distance = great_circle(location_coords, downtown_coords).miles
suburb_distance = great_circle(location_coords, suburb_coords).miles
rural_distance = great_circle(location_coords, rural_coords).miles
# Determine the category based on distances
if downtown_distance < suburb_distance and downtown_distance < rural_distance:
return "Downtown"
elif suburb_distance < downtown_distance and suburb_distance < rural_distance:
return "Suburb"
else:
return "Rural"
# Example latitude and longitude
latitude = 40.7128 # Example latitude
longitude = -74.0060 # Example longitude
# Categorize the location
location_category = categorize_location(latitude, longitude)
print(f"The location is categorized as: {location_category}")To incorporate population data into your demand prediction model, you can obtain population data for specific locations using various data sources or APIs. We can use the U.S. Census Bureau ( censusdata Python library) as an example. Example of how to retrieve population data for a city using the censusdata Python library:
import censusdata
# Define the geographic area (in this example, we'll use New York City)
state = 'NY'
county = 'New York'
place = 'New York city'
# Define the year for the population estimate (e.g., 2020)
year = 2020
# Retrieve population data for the specified location
pop_data = censusdata.download(
'acs5', # Dataset identifier for American Community Survey 5-Year Estimates
year,
censusdata.censusgeo([('state', state), ('county', county), ('place', place)]),
['DP05_0001E'], # Population estimate variable
)
# Extract the population estimate from the DataFrame
population_estimate = pop_data.iloc[0]['DP05_0001E']
# Print the population estimate
print(f"Population estimate for {place}, {county}, {state} in {year}: {population_estimate}")As with any feature engineering technique, there are pros and cons to adding store-based features. Here are a few to consider:
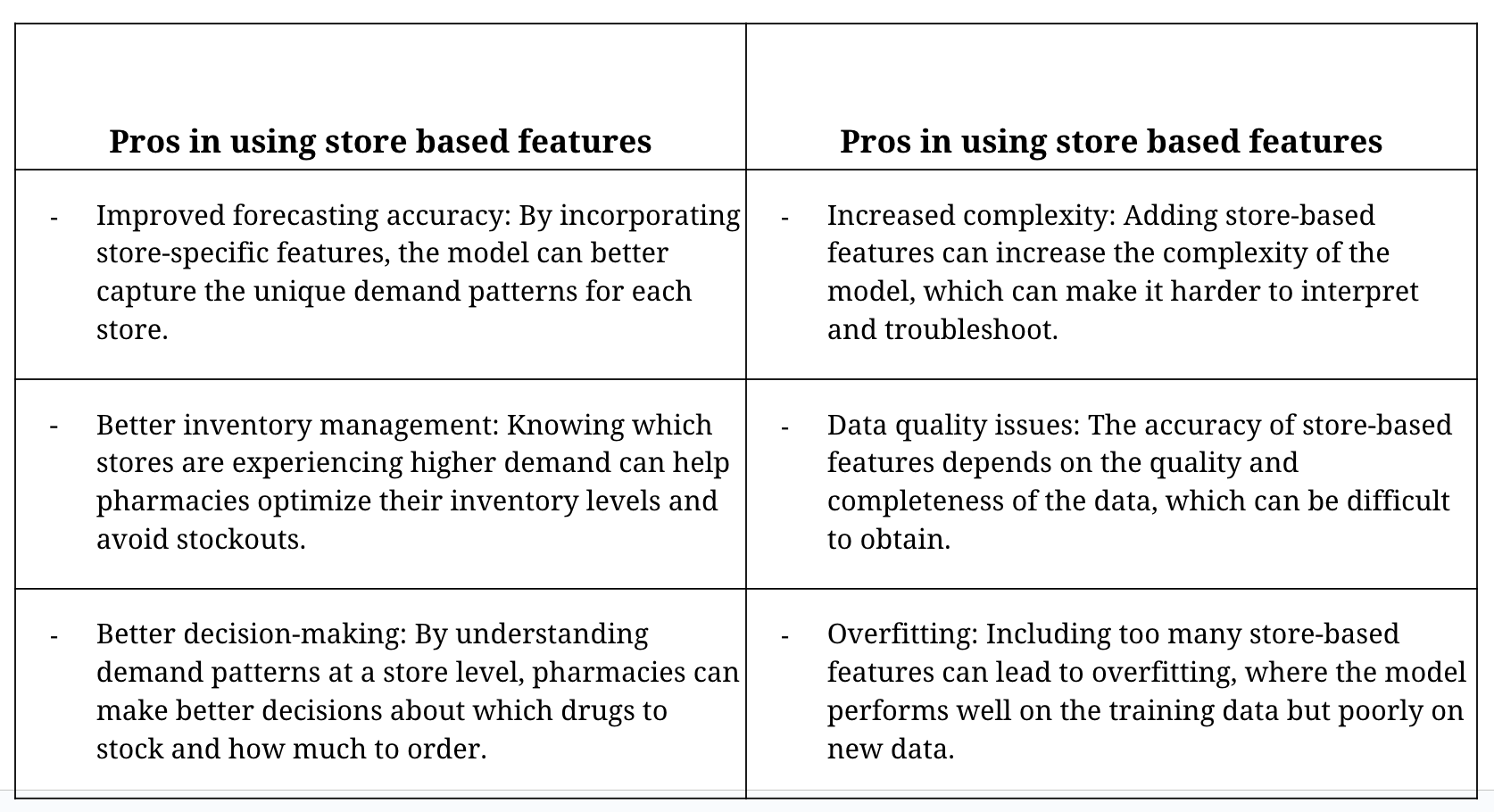
Here are some tips to consider when creating store-based features:
- Consider the granularity of the features: Store-based features can be very specific, such as the number of employees working at a particular store, or more general, such as the store's location. It's important to consider what level of granularity is appropriate for the specific problem you're trying to solve.
- Use external data sources: Additional information about the store or location, such as demographic data, foot traffic, and nearby competitors, can provide valuable insights into demand patterns.
- Be mindful of privacy concerns: When working with store-based data, it's important to be mindful of privacy concerns and to ensure that sensitive information is properly protected.
Evaluation
Once the model has been selected, it needs to be trained on the historical sales data. This involves splitting the data into training and testing sets, and using the training set to fit the model to the data. Once the model has been trained, it can be used to predict the demand for drugs in the pharmacy for a given period of time.
To evaluate the performance of the model, we can use metrics such as mean absolute percentage error (MAPE), root mean squared error (RMSE), mean absolute error (MAE), or R-squared(R²). These metrics provide a measure of how well the model is able to predict the demand for drugs in the pharmacy. To evaluate the impact of feature engineering, you should compare the performance of models with and without engineered features using the evaluation metrics mentioned earlier. In most cases, you will likely observe that models with feature engineering outperform those without. Lower MAPE, RMSE, and MAE values and higher R² values are indicative of improved predictive accuracy.
Conclusion
In the world of demand prediction, effective feature engineering is the key to building accurate and actionable predictive models. By understanding the importance of feature selection, transformation, and engineering techniques, data scientists and analysts can unlock the true potential of their data, enabling organizations to make informed decisions and stay ahead in a competitive marketplace.
To help you make the most out of your feature engineering efforts in demand prediction modeling, consider the following specific suggestions:
- Domain Knowledge: Invest time in understanding the domain you are working in. Speak with domain experts and stakeholders to identify which features are likely to have the most significant impact on demand. Their insights can guide your feature selection process.
- Exploratory Data Analysis (EDA): Conduct a thorough EDA to explore the relationships between your features and the target variable (demand). Visualizations, correlation analysis, and statistical tests can help you uncover important patterns and dependencies.
- Feature Importance: Utilize techniques like feature importance scores from tree-based models or feature selection algorithms to objectively assess the relevance of each feature. Focus on those with the highest importance scores.
- Dimensionality Reduction: If you have a large number of features, consider dimensionality reduction techniques like Principal Component Analysis (PCA) or t-Distributed Stochastic Neighbor Embedding (t-SNE) to reduce the feature space while preserving relevant information.
- Feature Engineering Experiments: Experiment with feature engineering techniques such as creating interaction features, polynomial features, or time-based aggregations. Test the impact of these engineered features on model performance.
Join us
We are looking for experienced Data Scientists and ML Engineers to come and help us in our mission to simplify healthcare. If you are looking to work on challenging data science problems and problems that drive significant impact to enthral you, check all the available data jobs on Halodoc’s Career Page here.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek and many more. We recently closed our Series C round and In total have raised around USD$180 million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


