
Migrating AWS MSK from ZooKeeper to KRaft: A Canary Approach
Introduction
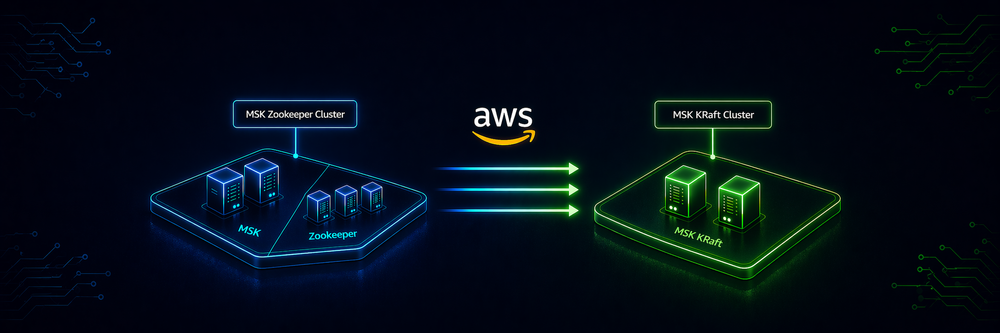
Apache Kafka has evolved significantly over the years, and one of the most consequential architectural shifts is the move from ZooKeeper-based metadata management to KRaft (Kafka Raft Metadata Mode).
For organizations running business-critical workloads on Amazon MSK, this transition is more than a version upgrade. It's a strategic modernization initiative that improves scalability, simplifies operations, and aligns with Kafka's future roadmap. Importantly, AWS has removed ZooKeeper support starting from MSK version 4.x, making KRaft the only supported metadata mode for new clusters and future upgrades.
At Halodoc, we successfully executed a canary migration of AWS MSK from ZooKeeper to KRaft across both staging and production environments with zero customer impact. This blog shares our end-to-end journey, covering POC validation, migration strategy, execution model, rollback planning, and learnings.
Why Move from ZooKeeper to KRaft?
Kafka traditionally relied on ZooKeeper for controller election, metadata storage, and broker coordination. While this architecture was stable and widely adopted, it also added operational complexity by introducing a separate system to manage, resulted in controller failover times of around 5–10 seconds, and occasionally caused latency spikes during high metadata activity.
KRaft modernizes this model by embedding the metadata quorum directly within Kafka brokers, eliminating the dependency on an external ZooKeeper cluster. This shift delivers several concrete benefits:
- Simpler architecture: KRaft integrates the metadata quorum directly into Kafka brokers, with no external ZooKeeper cluster to operate or tune.
- Faster failover: Sub-second controller recovery vs. 5–10 seconds with ZooKeeper.
- Better scalability: Handles partition-heavy and metadata-intensive workloads more efficiently.
- Lower overhead: No more ZooKeeper snapshot management, quorum health tuning, or independent scaling.
- Future-aligned: AWS has removed ZooKeeper support from MSK 4.x onward, KRaft is the only supported mode going forward.
Existing ZooKeeper clusters cannot be upgraded in-place. A new KRaft cluster must be provisioned and workloads migrated, which is exactly what we set out to do.
POC Validation: Proving Functional Parity Before Production
Before committing to production migration, we performed a comprehensive proof-of-concept using two isolated clusters with identical configurations: halodoc-poc-zookeeper (ZK-based MSK 3.7.x) and halodoc-poc-kraft (KRaft-based MSK 4.0.x). Our goal was to validate full message lifecycle behavior (produce → consume), performance benchmarks, failover improvements, and client compatibility.
Performance Benchmarks
We simulated production-scale loads (~1 million messages per minute) and measured:
Multi-Client Compatibility
We validated compatibility across the three primary language stacks used at Halodoc. The Go stack required a client library upgrade to confluent-kafka-go ≥ v2.6.1 (from v1.8.2) to ensure successful connectivity with KRaft.
POC outcome: Full functional parity and zero data integrity issues across all load tiers. Go services needed confluent-kafka-go ≥ v2.6.1. Once resolved, no remaining blockers for production migration.
Why Standard Upgrades Don't Apply
Unlike standard version upgrades, migrating from ZooKeeper to KRaft on AWS MSK requires:
- Provisioning a brand-new KRaft-based MSK cluster
- Migrating all producers and consumers with configuration changes
- Migrating Schema Registry dependencies (Avro/Protobuf subjects and versions)
- Preserving message flow continuity without message loss or duplication
- Avoiding downtime for business-critical services
- Managing dual-bootstrap configurations during the transition window
This demanded a migration model with strong rollback safety, progressive traffic shifting, and production-grade validation at every step.
Our Migration Strategy: Canary Deployment
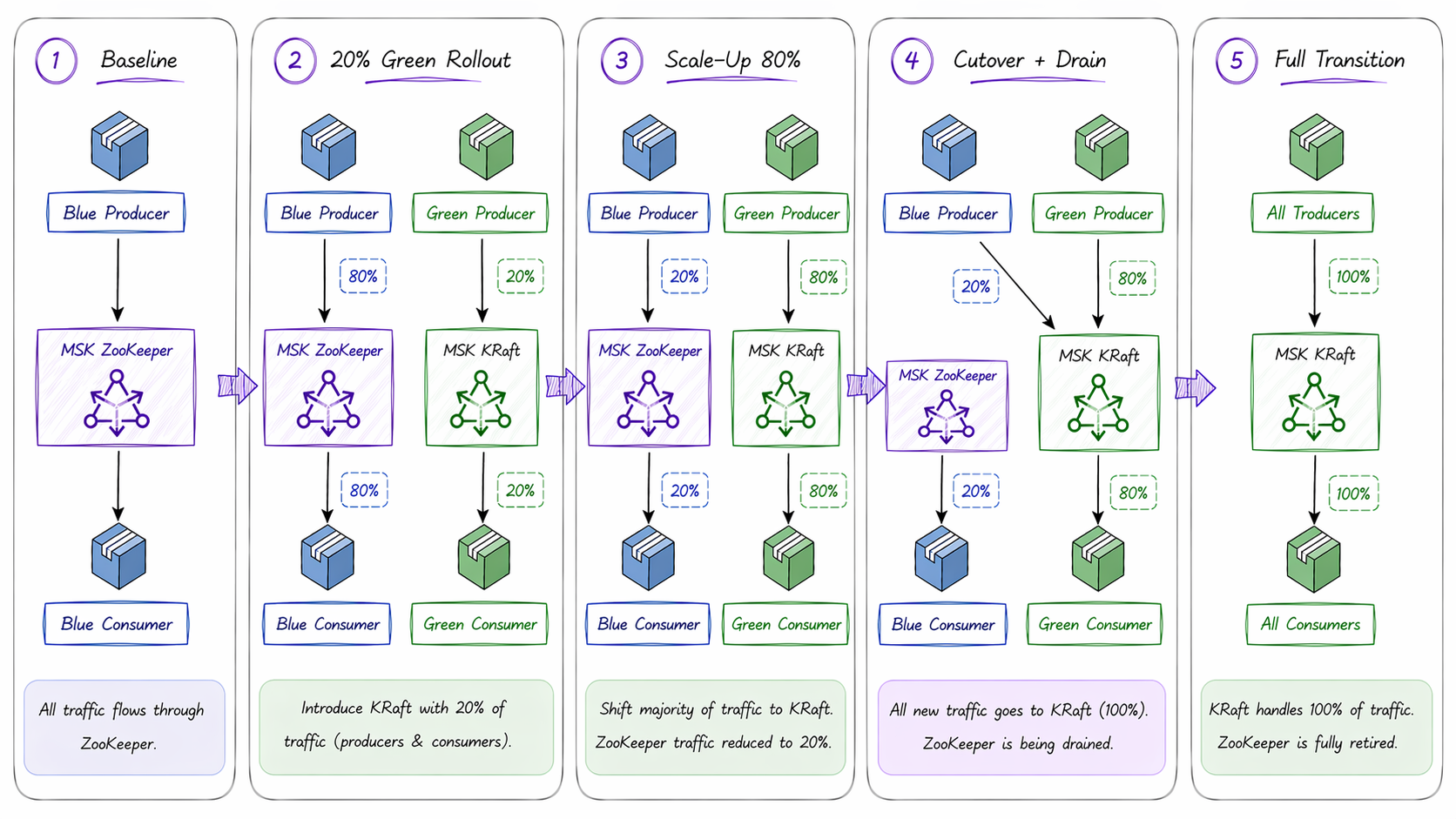
We adopted a canary deployment strategy, gradually shifting a small percentage of traffic across every service in the fleet from the existing ZooKeeper cluster (environments named Blue) to the new KRaft cluster (environments named Green), and monitoring stability at each stage before increasing the load. Unlike a full Blue-Green cutover that switches 100% of traffic at once, the canary approach let us validate KRaft behavior under real production load incrementally, with a fast rollback path at every step.
Environment Setup
- Blue (ZooKeeper): Existing production Amazon MSK cluster running Kafka 3.7.x with 6 brokers and a replication factor of 3.
- Green (KRaft): Newly provisioned Amazon MSK cluster running Kafka 4.0.x with 6 brokers and a replication factor of 3, configured with the same network setup (VPC, subnets, and security groups) and SASL/SCRAM authentication using the existing secrets.
Traffic Migration Phases
- Phase 1: Blue services produce and consume on ZooKeeper. Green services independently produce and consume on KRaft, validating end-to-end flow on the new cluster with real traffic.
- Phase 2: Workloads gradually moved to KRaft (20% → 50% → 80%) and validated at each stage.
- Phase 3: 100% traffic on KRaft; ZooKeeper cluster decommissioned.
Code Changes
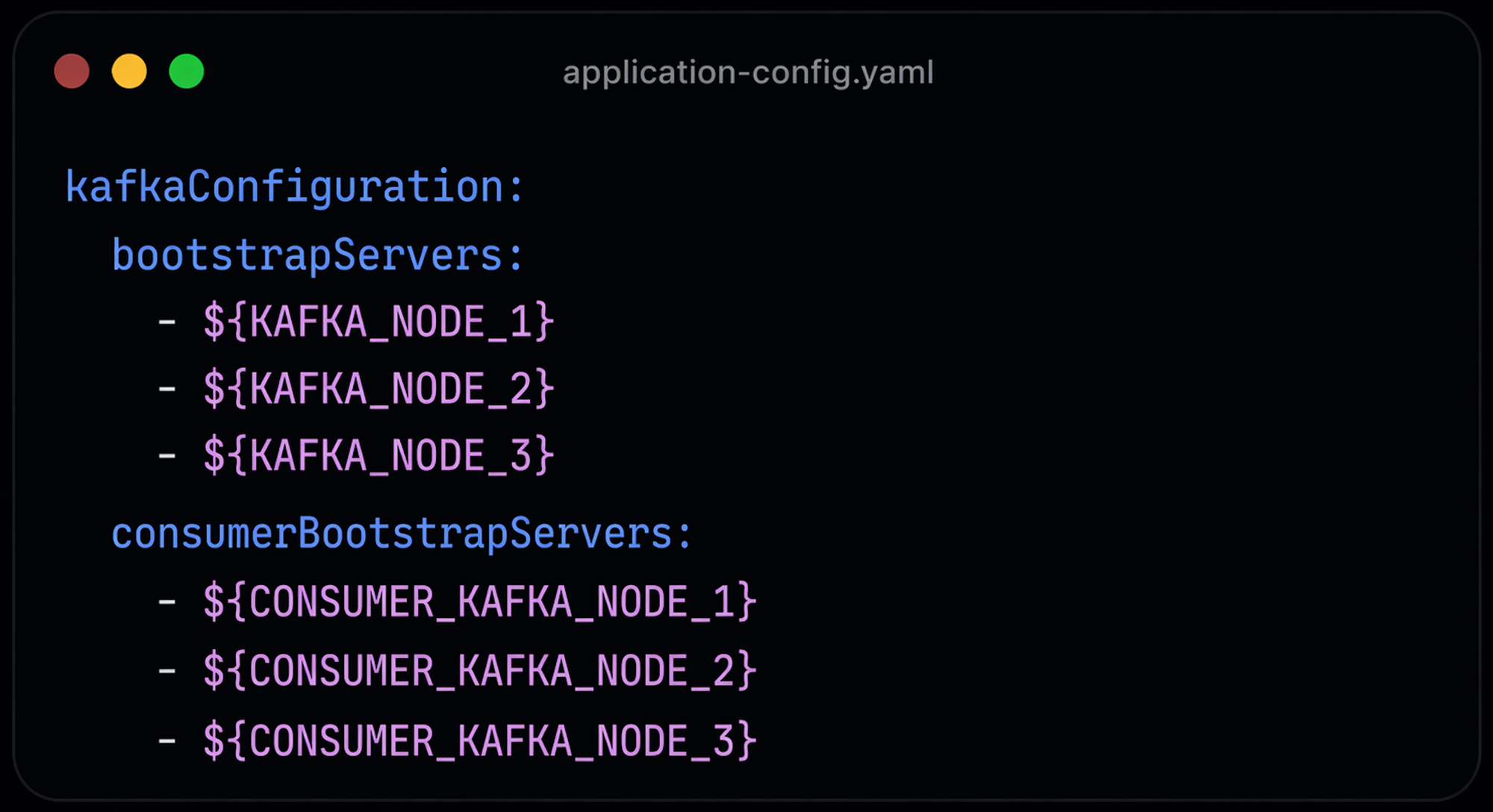
The migration required minimal but precise code changes. We introduced a dedicated consumerBootstrap parameter alongside the existing configuration, enabling independent routing of producer and consumer traffic. For consumer-only services, bootstrap URLs were updated directly. Code changes were confined to configuration and publisher/consumer initialization. No business logic modifications were needed.
Pre-Migration Readiness Checklist
Infrastructure & Platform Setup
- KRaft MSK Cluster Provisioned: Kafka 4.0.x, same broker specs, VPC/subnet/security group parity, SASL/SCRAM authentication configured and validated
- Topic Recreation: All topics exported from ZooKeeper cluster and recreated on KRaft with matching partition counts, replication factors, and retention settings
- Lambda Trigger Configuration: Parallel Lambda event source mappings created for KRaft cluster (topic name, consumer group, batch size, SASL authentication) while ZooKeeper triggers remain active
- Grafana Monitoring Setup: Dedicated KRaft dashboards configured and validated before any traffic shift (broker health, consumer lag, throughput, error rates, application failures)
- Consumer Lag Baseline: All consumer groups validated at near-zero lag on ZooKeeper cluster. Snapshot recorded for reference.
- Client Compatibility Audit: All services verified to use modern Kafka clients with bootstrap.servers. Go services upgraded from confluent-kafka-go v1.8.2 to v2.6.1 to resolve KRaft connectivity issues.
Schema Registry Prerequisite
Schema Registry migration was a critical prerequisite. We performed:
- Subject export from the ZooKeeper cluster registry
- Import into the new KRaft cluster registry
- Schema count and subjects list validation via Schema Registry API
- Version parity and compatibility checks
- Producer lookup validation to confirm runtime serialization correctness
Production Migration Execution
With infrastructure ready and monitoring in place, we executed service migration in controlled stages:
- Step 1 — Baseline Confirmation: All services on Blue (ZooKeeper). Consumer lag at near-zero and Green environment configured to route both producer and consumer endpoints to KRaft brokers.
- Step 2 — 20% Green Rollout: 20% workload deployed to Green. Monitored consumer lag, error rates, and processing health across both environments.
- Step 3 — Scale-Up (20% → 50% → 80%): Traffic was incrementally increased across all services. Each rollout stage was gated on sustained performance validation, followed by a 15–20 minute stabilization window before proceeding to the next percentage.
- Step 4 — Producer Cutover on Blue: All Blue producers switched to publish exclusively to KRaft, initiating intentional drain of ZooKeeper cluster.
- Step 5 — Drain Validation: ZooKeeper consumer lag monitored until trending to zero, confirming effective traffic cessation.
- Step 6 — Full Transition (100%): 100% workload on Green. KRaft established as the sole active Kafka control plane.
Monitoring During Migration
We maintained continuous observability across four dimensions:
- Kafka Metrics: Bytes in/out, active connections, request latency, partition health
- Consumer Metrics: Group lag, rebalance events, processing delays
- Application Metrics: Error rates, retries, latency spikes, pod restart counts, idempotency behavior
- Infrastructure Signals: Broker CPU, memory, network throughput, disk usage
Any anomaly immediately paused the rollout. Rollback decision paths were pre-defined before migration began.
Rollback Plan
We defined three explicit rollback scenarios:
| Scenario | Condition | Rollback Action |
|---|---|---|
| Early Canary Issues | Issues detected at 20% Green rollout | Reduce Green traffic back to 0%, immediately returning all traffic to the ZooKeeper cluster. |
| Producer Rollback Post-Blue Cutover | After Blue producers switched to publish exclusively to KRaft | Revert producer endpoints on Blue to ZooKeeper. Restores original topology and stops KRaft ingress during investigation. |
| Cluster Instability | KRaft cluster-level issues observed | Stop all KRaft producers, revert all services to ZooKeeper, and investigate cluster-level issues. |
Key Learnings
- Migration Is an Application Exercise, Not Just Infra Work: Kafka clusters may move cleanly, but true success depends on application-level validation. Every service team needs to be engaged.
- Schema Registry Demands Equal Priority: Many production failures happen at the serialization/deserialization layer. Schema migration must be treated as a first-class concern.
- Client Library Versions Are Critical: The Go stack experienced KRaft connectivity issues on confluent-kafka-go v1.8.2 and required an upgrade to ≥ v2.6.1. Validate and audit all Kafka client versions early in the migration lifecycle to proactively mitigate compatibility risks.
- Progressive Rollout Reduces Blast Radius: Moving traffic in stages (20% → 50% → 80% → 100%) with stabilization windows provides confidence and limits failure impact.
- Clear Ownership Accelerates Recovery: Having service owners actively validate their flows in real time dramatically improves execution speed and incident response.
- Observability Is Non-Negotiable: Pre-configured dashboards and log baselines are essential. Build your monitoring before Day 1.
Conclusion
Kafka's future is KRaft. For teams running AWS MSK on ZooKeeper, the move is no longer optional. AWS has deprecated ZooKeeper support from MSK 4.x onward. The question is not whether to migrate, but how to do it without disruption.
With a rigorous POC validating real-world performance and client compatibility, a canary deployment strategy preserving rollback safety at every stage, and a clear operational runbook spanning cluster provisioning through decommission, organizations can modernize their streaming platform safely and confidently.
For Halodoc, this migration was more than a cluster replacement. It was a strategic platform modernization that upgraded our Kafka control plane to a more scalable architecture, delivered measurable performance gains, and positioned our data infrastructure for the next phase of scale.
Join us
Scalability, reliability, and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels, and if solving hard problems with challenging requirements is your forte, please reach out to us with your resume at careers.india@halodoc.com.
About Halodoc
Halodoc is the number one all-around healthcare application in Indonesia. Our mission is to simplify and deliver quality healthcare across Indonesia, from Sabang to Merauke. Since 2016, Halodoc has been improving health literacy in Indonesia by providing user-friendly healthcare communication, education, and information (KIE). In parallel, our ecosystem has expanded to offer a range of services that facilitate convenient access to healthcare, starting with Homecare by Halodoc as a preventive care feature that allows users to conduct health tests privately and securely from the comfort of their homes; My Insurance, which allows users to access the benefits of cashless outpatient services in a more seamless way; Chat with Doctor, which allows users to consult with over 20,000 licensed physicians via chat, video or voice call; and Health Store features that allow users to purchase medicines, supplements and various health products from our network of over 4,900 trusted partner pharmacies. To deliver holistic health solutions in a fully digital way, Halodoc offers Digital Clinic services including Haloskin, a trusted dermatology care platform guided by experienced dermatologists. We are proud to be trusted by global and regional investors, including the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. With over USD 100 million raised to date, including our recent Series D, our team is committed to building the best personalized healthcare solutions and we remain steadfast in our journey to simplify healthcare for all Indonesians.


