

Optimizing our Datalake's Raw Data Layer by Smart Storage
At Halodoc, as our data platform continues to scale to handle millions of healthcare interactions across Indonesia, efficient data management has become not just a technical necessity but a critical business priority. Every byte stored, every S3 request made, and every transformation executed carries real cost and performance implications.
In our journey towards maintaining a robust data infrastructure, we encountered a challenge that many data-intensive organizations face: the small file problem. This blog post outlines how we addressed storage inefficiencies in our raw data layer, resulting in a 40% reduction in storage size and a 76% decrease in object count, while also significantly reducing storage costs by more than 20%.
Background: The Growing Pains of Scale
Our data platform ingests data from multiple sources, including application databases, external APIs, third-party providers, and internal services like our reporting system (Toba). As our business grew, so did our data footprint. However, this growth came with hidden inefficiencies that were silently increasing our infrastructure costs.
One of the most significant issues was the small-file problem. Many upstream systems, especially our transaction tables, produced very small files, often only a few kilobytes each. These accumulated into millions of objects in S3. Although the total data volume was manageable, the way the data was stored created operational challenges. Distributed compute engines like Spark and Athena run far less efficiently when the data is split into too many small files.
For example, processing five files totaling 1 GB is significantly faster and more efficient than processing 100 files totaling the same 1 GB, because fewer files mean fewer metadata lookups, fewer S3 API calls, and larger, more parallelizable partitions.
The symptoms were clear:
- About 48% of unused and backup data was stored without proper lifecycle management
- Millions of small files with an average size of just 41 KB
- Increasing storage costs with an overlooked optimization strategy in place
Our Objective
Our main objective for this initiative was to create a more optimized and cost-efficient raw data layer through better file organization and lifecycle management. While the raw layer was already scalable, it needed stronger optimization to reduce operational overhead, improve performance, and control long-term storage costs.
To achieve this, we focused on two key strategies:
- Compression & Compaction
- Merge small files into large, optimized Parquet files.
- Automate compression with PySpark and Athena workflows.
- Lifecycle Optimization
- Implement S3 Intelligent Tiering
- Automate transitions via S3 Lifecycle Policies.
By combining these strategies, we improved the structure and efficiency of the raw data layer, reduced object counts, and achieved more sustainable long-term storage management.
Compression
In our environment, millions of small, uncompressed files were driving up storage expenses, slowing down queries, and adding operational overhead. Each additional gigabyte stored translates to recurring monthly costs, while every extra object increases S3 API activity and metadata management load. Moreover, having too many small files also raises the cost of S3 lifecycle transitions, since transitions are charged per object. By consolidating these small files into larger, compressed ones, we not only reduce storage footprint and API overhead but also make our class transition process significantly more cost-efficient.
Choosing the Right Compression Strategy
We evaluated three popular compression codecs: Snappy, ZSTD, and GZIP. We used our old monthly data from 5 different tables to do the benchmark. Each offered different trade-offs between compression ratio, speed, and CPU usage.
Our testing revealed interesting performance characteristics across the three codecs:
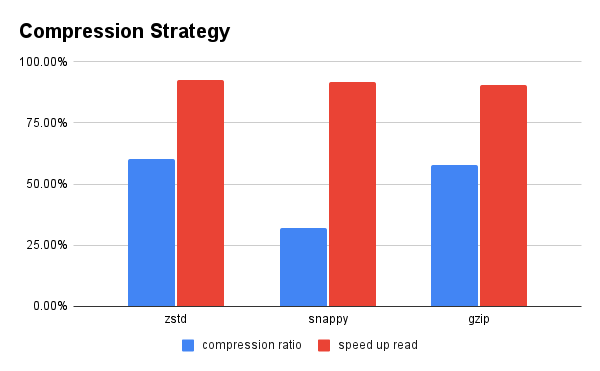
Key Findings:
- Compression Ratio: ZSTD and GZIP both achieved approximately 60% compression ratios, significantly outperforming Snappy at only 30%
- Read Performance: All three codecs delivered comparable read speeds, with slight variations around 90-95% efficiency
- The Snappy Trade-off: While Snappy is known for its fast compression speed, its lower compression ratio meant we'd store nearly twice as much data compared to ZSTD or GZIP
While both ZSTD and GZIP showed similar initial performance (~60% compression ratio and ~90% read speeds), we needed to understand whether ZSTD's tunable compression levels could provide additional advantages. We conducted a comprehensive benchmark comparing ZSTD across all its compression levels (1-22) against GZIP as our baseline.
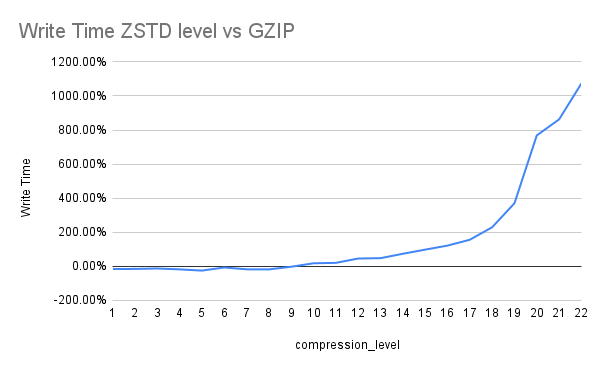
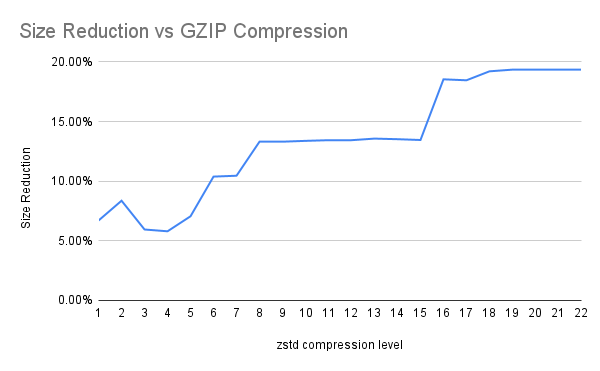
We used GZIP as our benchmark (represented as 0% baseline in both charts) and measured:
- Write Time: How much longer ZSTD take to compress compared to GZIP
- Size Reduction: How much additional compression ZSTD achieves beyond GZIP
The chart clearly shows that after level 8, write times increase exponentially while compression gains plateau
- Level 8: similar compression time, 13% better compression
- Level 16: 200% more time, only 19% better compression (diminishing returns)
While higher compression levels (16-22) offer slightly better compression ratios (~19% vs 13%), the exponential increase in write time makes them impractical for production use. Level 8 delivers most of the compression benefits without the dramatic performance penalty. Based on extensive testing, ZSTD compression level 8 became our default standard for the raw data layer, outperforming GZIP in compression ratio while remaining operationally viable at scale.
The Tools: Spark vs. Athena
We evaluated two primary approaches for implementing our compression pipeline: Apache Spark on EMR and Amazon Athena.
Spark (EMR) Approach
Pros:
- Scales effectively for large datasets and multi-bucket workflows
- Supports comprehensive codec options (Snappy, ZSTD, GZIP, LZO)
- Handles complex schema evolution and custom transformation logic
- Full programmatic control over the compression process
Cons:
- Requires EMR cluster management with associated operational overhead
- Incurs cluster costs even during idle periods
- Higher S3 API costs due to LIST and GET operations
Key Learning: During our initial Spark implementation, we saw a significant spike in S3 API Tier 1 costs. In one day, our API calls increased 7 times in our daily operations when compressing 6 million files. We discovered that even if we specify the exact key path during Spark read, Spark still performs LIST API operations behind the scenes.
Athena Approach
Pros:
- Serverless architecture eliminates cluster management
- Tight S3 integration with cost based on scanned data size (cheaper for our use case)
- Ideal for one-off jobs, ad-hoc compression, or smaller datasets
- Minimal operational overhead
Cons:
- Limited to specific compression formats (Snappy, ZSTD, GZIP)
- Less flexible for complex schema transformations
- More challenging to orchestrate multi-step workflows
Spark vs Athena Cost Comparison
Based on the metrics below from the testing environment, Athena shows stronger efficiency in terms of S3 API calls. Its job generated significantly fewer LIST and GET operations, resulting in lower API overhead.
In addition, Athena’s serverless pricing model ($5 per TB scanned) keeps total compute costs minimal — the workload processed here was less than 163 GB, far below a single terabyte.
| Engine | File Count | File Size | S3 LIST Calls | S3 GET Calls |
|---|---|---|---|---|
| EMR Spark | 3.8 M | 68 GB | 5.3 M | 15.6 M |
| Athena | 3.3 M | 163 GB | 315 K | 6.5 M |
Our Strategy: We adopted a hybrid approach, using Athena for most compression jobs, and Spark for complex transformations that require custom logic or handling edge cases.
Lifecycle Optimization
While compression reduced the size of our data, lifecycle optimization ensured we weren't paying premium prices for data that didn't require high-performance storage. Rather than managing complex lifecycle rules manually, we leveraged S3 Intelligent Tiering to automatically optimize storage costs.
Why S3 Intelligent Tiering?
S3 Intelligent Tiering eliminates the operational overhead of managing lifecycle policies by automatically moving objects between access tiers based on actual usage patterns:
- Automatic Cost Optimization: Objects are automatically transitioned to lower-cost access tiers when not accessed for 30 days ~ Infrequent Access (IA) and 90 days ~ Archive Instant Access (AIA)
- Zero Operational Overhead: No need to analyze access patterns or configure complex lifecycle rules
Results: The Impact of Optimization
Our optimization efforts delivered substantial improvements across multiple dimensions:
Storage Efficiency
- Raw bucket size reduced by 40%
- Object count decreased by 76% reduction
- Average object size increased from 204 KB to 869 KB (325% increase)
Cost Savings
- 43% data migrated from Standard to Intelligent Tiering
- Automatic transition to IA after 30 days, saving approximately 20% cost reduction
- Automatic transition to Archive Instant Access after 90 days, saving approximately 35% cost reduction
Break-even Analysis - The initial investment in compute and API costs for compression was recovered in approximately 50 days, after which we began realizing net savings.
Conclusion
Optimizing our raw data layer delivered significant benefits across storage efficiency, cost reduction, and query performance. By addressing the small file problem through automated compression and implementing intelligent lifecycle policies, we reduced our raw storage footprint by 40% while cutting long-term storage costs substantially.
This initiative reinforces an important lesson: data platform efficiency isn't just about processing speed or feature richness—it's also about managing the fundamentals well. Small files might seem like a minor nuisance, but at scale, they represent a significant operational and financial burden, which should be addressed by robust automation and well-designed data management practices. In addition, this work offers a chance to explain a well-known challenge in the data engineering world—the small-file problem, where countless tiny files strain storage systems and slow down processing.
References
Join us
Scalability, reliability, and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number one all-around healthcare application in Indonesia. Our mission is to simplify and deliver quality healthcare across Indonesia, from Sabang to Merauke.
Since 2016, Halodoc has been improving health literacy in Indonesia by providing user-friendly healthcare communication, education, and information (KIE). In parallel, our ecosystem has expanded to offer a range of services that facilitate convenient access to healthcare, starting with Homecare by Halodoc as a preventive care feature that allows users to conduct health tests privately and securely from the comfort of their homes; My Insurance, which allows users to access the benefits of cashless outpatient services in a more seamless way; Chat with Doctor, which allows users to consult with over 20,000 licensed physicians via chat, video or voice call; and Health Store features that allow users to purchase medicines, supplements and various health products from our network of over 4,900 trusted partner pharmacies. To deliver holistic health solutions in a fully digital way, Halodoc offers Digital Clinic services including Haloskin, a trusted dermatology care platform guided by experienced dermatologists.
We are proud to be trusted by global and regional investors, including the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. With over USD 100 million raised to date, including our recent Series D, our team is committed to building the best personalized healthcare solutions — and we remain steadfast in our journey to simplify healthcare for all Indonesians.
