

How we optimized the read operations using MongoDB at Halodoc
Halodoc is a giant in Indonesia's healthcare ecosystem. We serve millions of users everyday in form of Pharmacy Delivery, Tele consultation, Appointments and Lab services. Our main objective has always been to enhance health care facilities in Indonesia.
To provide a good experience to the users, we aim to solve our use cases by identifying and using proper tech stack that help us making our backend systems more scalable and resilient to sudden spikes. For example, our backend layer consists of multiple Java and Golang applications. Most of these services are user facing and serve our transactional use cases. Many steps were taken in our journey of improving user experience. We have experimented with Algolia/ES for making our search operations faster and user friendly, event based pipelines using Kafka/SNS for asynchronous operations and MongoDB to provide updated information to users in real time.
One of the most used services on our platform is Pharmacy Delivery. With this platform, we find the pharmacy(s) which have the cheapest price for the medicines in user's cart and upon successful payment, we deliver them via our delivery partners.
Challenges we faced
We have onboarded ~3500 pharmacies across Indonesia on our platform, which selling close to 42,000 unique products. We maintain around 5.5Million mapping of these distinct products across these pharmacies with prices and inventory being updated every 15mins to 1hour according to the configured data pipelines.
The challenge here is providing user with the best price while discovering products, so that user knows what is the final amount that they would have to pay if they choose to purchase the product from our platform.
Our Catalog system is backed by a MySQL Database which is an RDBMS. With operations team onboarding considerable amount of pharmacy partners everyday, we were facing scaling issues like
- RDS's CPU utilisation maxing out.
- Connection Timeouts because of slow queries.
- Database connection pool getting corrupted because of slow queries.
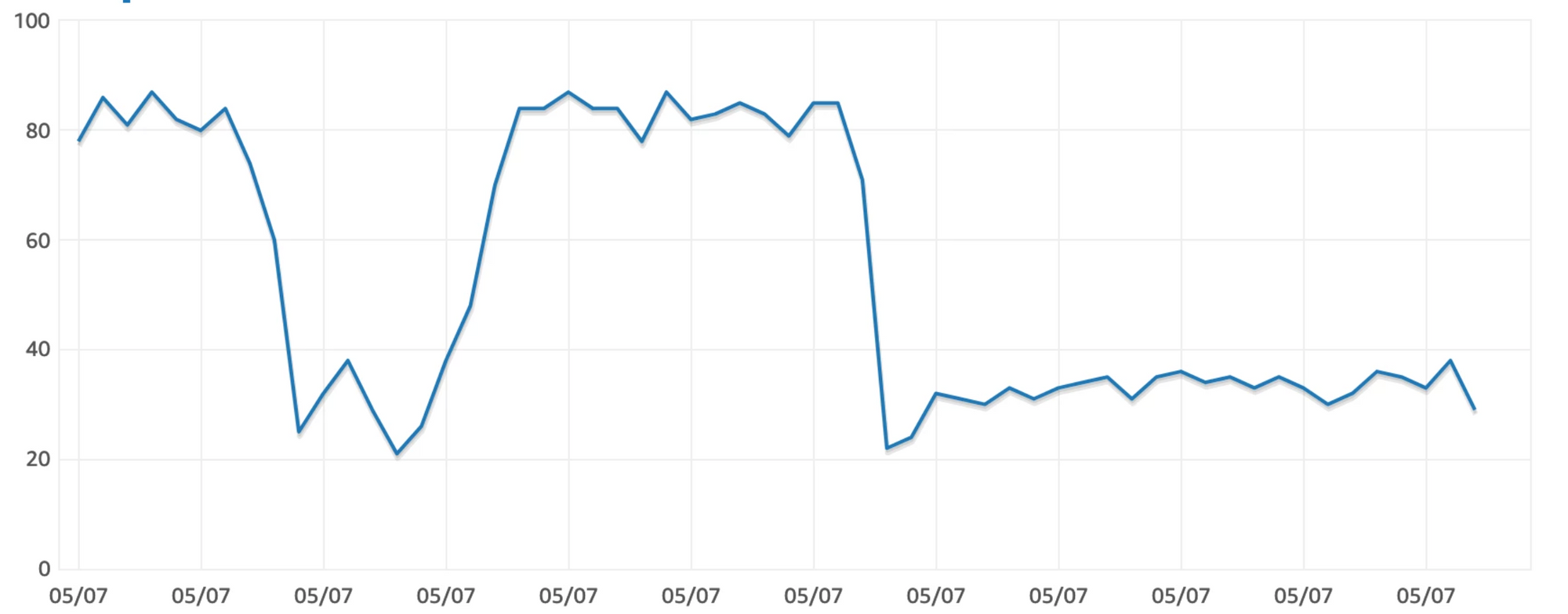
We figured out that the main cause of the problem was the query which runs frequently whenever data is ingested in our catalog. Example of one such query is :
SELECT max(item.selling_price) FROM items item JOIN item_attributes item_attribute ON item.id = item_attribute.item_id WHERE item_attribute.attribute_key = 'acceptable_sources' AND item_attribute.attribute_value LIKE '%business_app%'
Such queries served business critical functionality and even a minor increase in execution time could have major business impact for us, as it would directly affect the discovery of our catalog. Furthermore, indexing could not address this specific problem as we did not want to do a prefix match based query approach. Both these constraints made it extremely challenging for us to deprecate OR rather reduce dependency of these queries.
How did we try to solve ?
Vertical Scaling
We tried scaling up our limited db instances causing the price to go high. This was the easiest way to solve the problem that we were facing and honestly, it did solve our problem, only in the short-term.
In Memory Approach
Since we had already figured out which database operation was increasing load on RDS, we decided to move the computation logic to our application. As a result, the load on our database had reduced to less than half, but application was suffering with high response times.
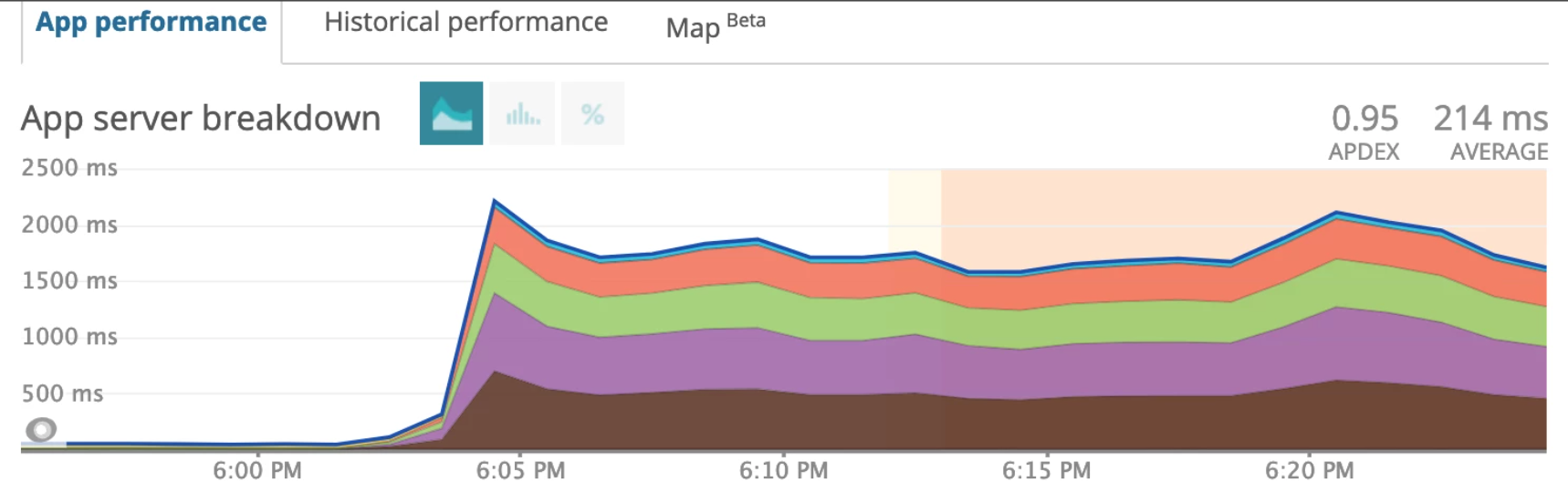
Evidently, we were able to reduce the load on RDS, but at the cost of having multiple over provisioned application instances with high response times and low user satisfaction rating. Lesser devil of the two, but still an incompetent solution.
Horizontal Scaling (and moving to NoSQL)
We decided to move towards NoSQL technologies, because they provide some powerful secondary indexing capabilities that are unavailable in RDBMS. We evaluated DynamoDB and MongoDB at the time. Since we wanted to be cloud agnostic and have optimised costs too, we decided to use MongoDB.
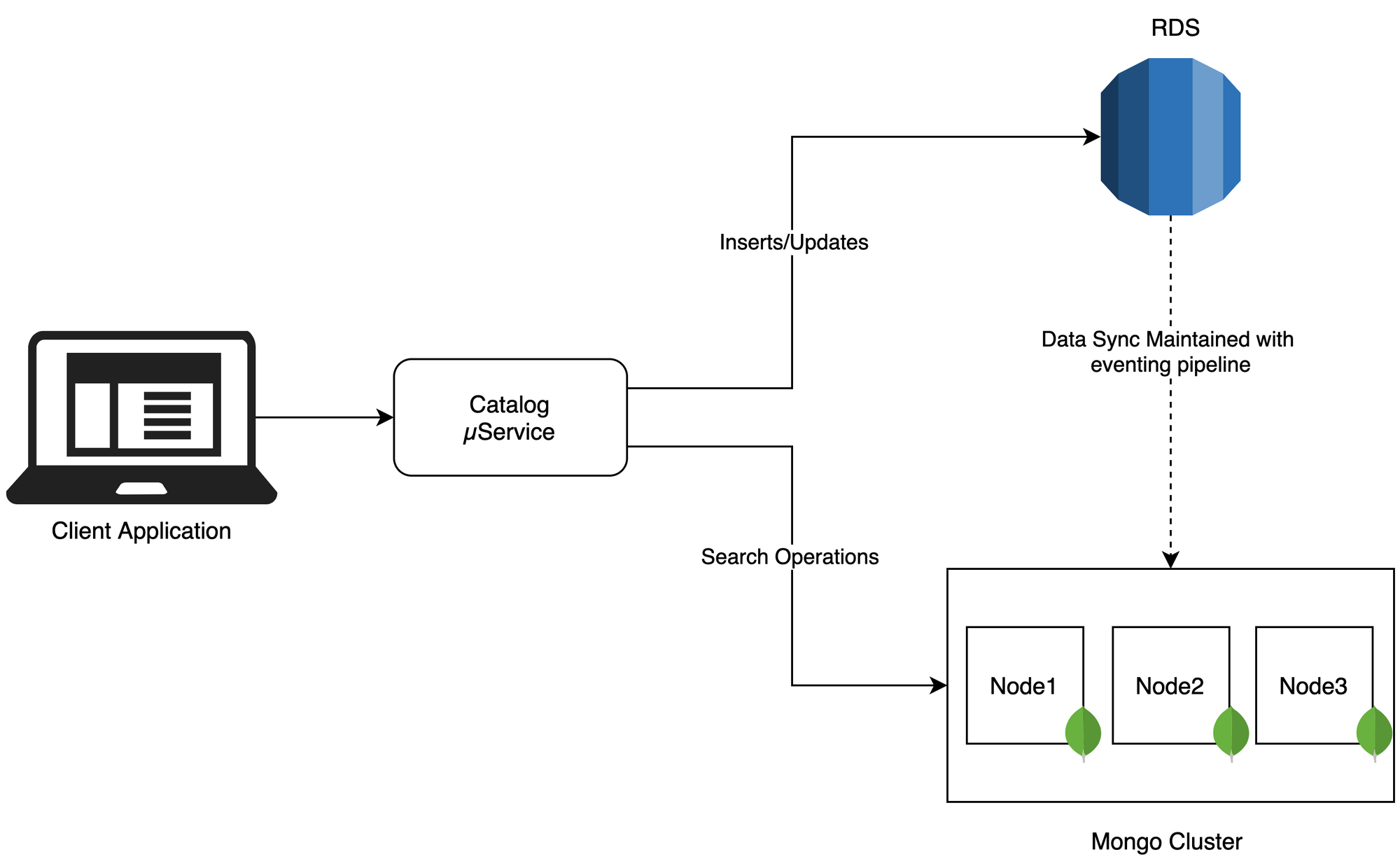
Steps taken
- Infra Setup - To start with, we had setup a 3 node cluster on t3.medium EC2 machines with 2 vCPU and 4GB memory.
- Data Modelling - Next big question was, how do we want to store data in MongoDB? The domain model we had in place was very specific to the RDBMS use cases, but to optimise the read operations, we wrote a mapper between the existing data model to the new de-normalised document structure.
- Data Consistency - Since we have to maintain 2 data sources now, it is necessary to talk about how we maintain consistency across all the data sources.
We use our eventing pipelineEragonfor this. Lets take a simple example to understand this -
- Update/Create request comes into system.
- The record is updated/created in primary data source i.e. MySQL, an event (item_updated or item_created) is published.
- This event is consumed by catalog service and the new record is indexed in secondary database i.e. MongoDB.
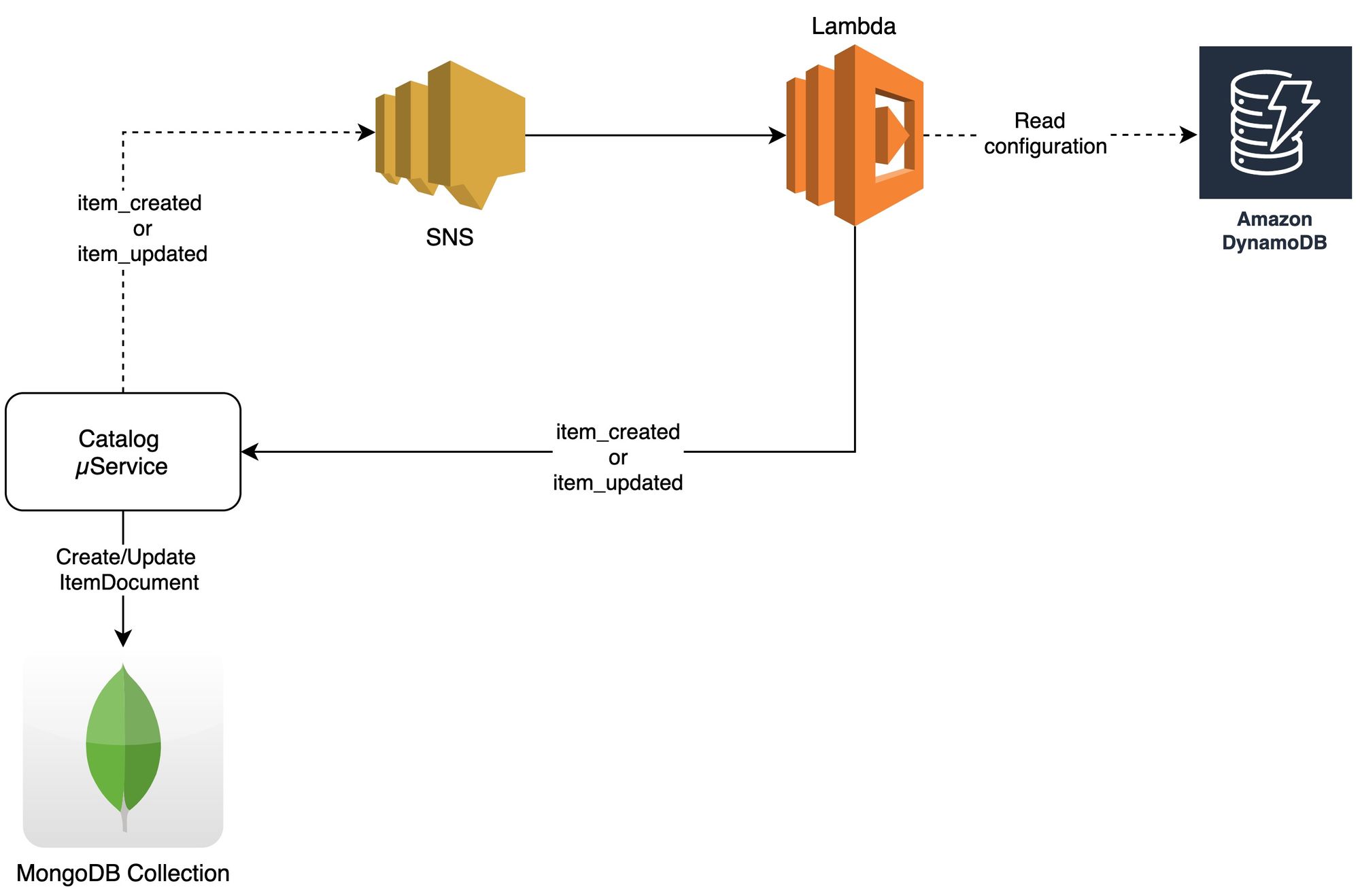
- Application Changes - Final changes were done in application for redirecting all the read queries to MongoDB instead of RDBMS. All the inserts/updates still happen in the master database (RDS), where as the search queries are routed to MongoDB.
Performance Evaluation
Performance Testing
We did performance testing on the 13 most consumed APIs in our catalog service with incremental load and sudden spikes. Results are as follows -
- Our search became faster as the maximum response time of the search API dropped from 1300ms to 480ms at 17k RPM. ( 2.8x improvement in Search performance)
- Maximum time taken for update operation, was reduced to 1400ms from 2200ms at 7k RPM. (1.6x Improvement in update operations)
- ~25% drop in the CPU utilisation was observed in RDS.
Since we had promising results, we decided to move this complete setup to production with similar infrastructure.
Production Impact
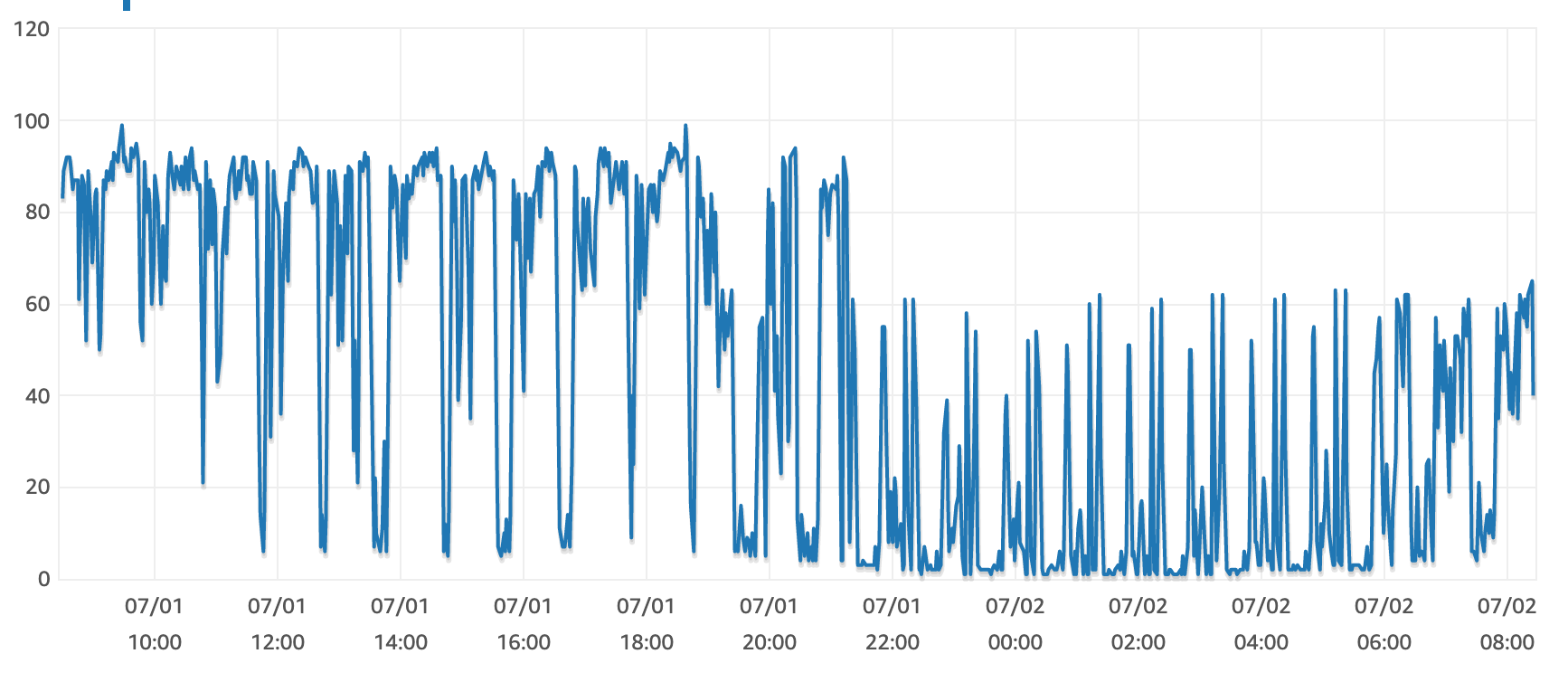
Impact on RDS - As soon as we deployed the changes on prod, CPU utilisation was observed in Catalog RDS was reduced by ~30%
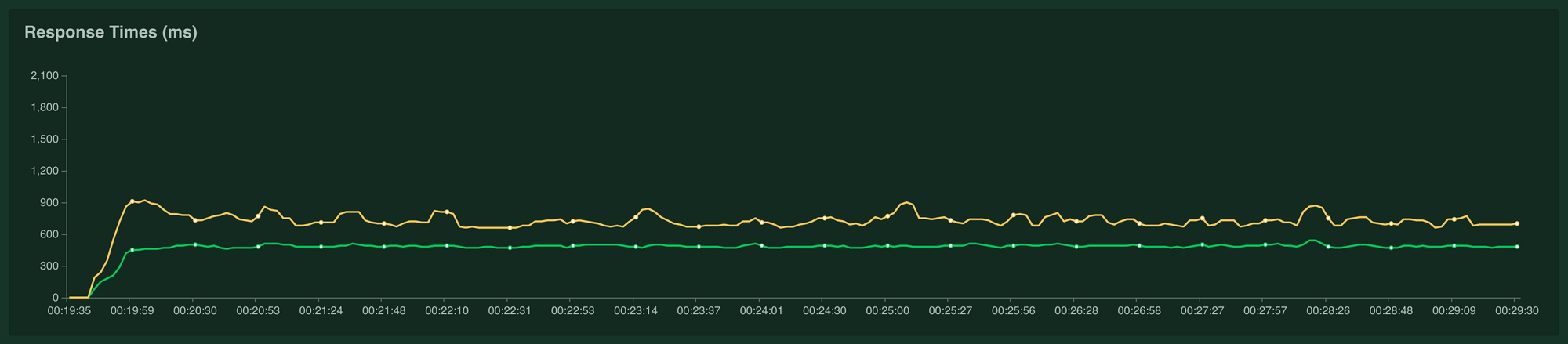
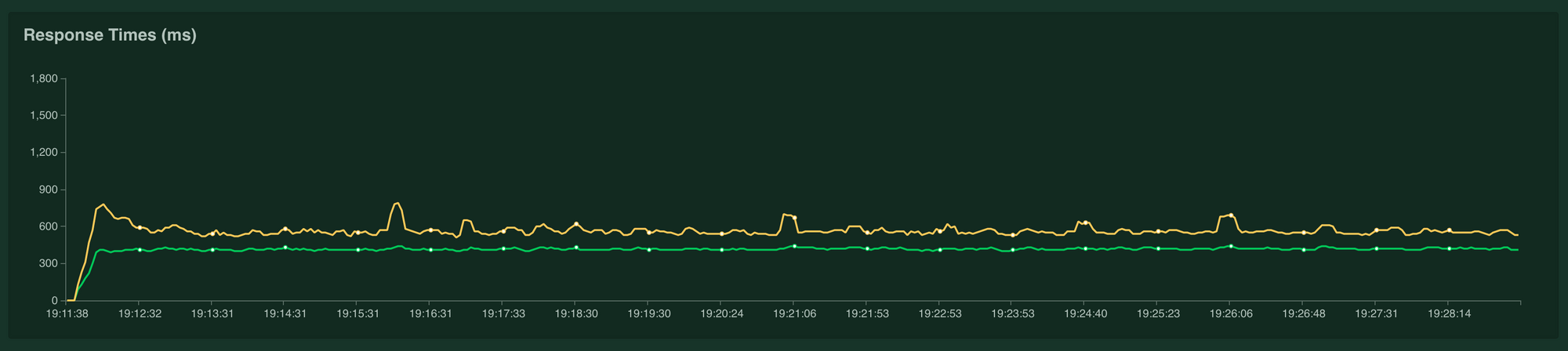
Impact on Response time - The response time were reduced by ~30%.
Summary
In this post, we discussed about the issues faced in the traditional RDBMS and how we overcame these issue by using MongoDB in our services preparing our systems for withstanding heavy loads and sudden spikes, while maintaining data consistency.
Join us
We are always looking out for top engineering talent across all roles for our tech team. If challenging problems that drive big impact enthral you, do reach out to us at careers.india@halodoc.com
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek and many more. We recently closed our Series B round and In total have raised USD$100million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


