

Optimizing Apache Hudi Workflows: Automation for Clustering, Resizing & Concurrency
In our journey towards building Halodoc's modern data platform 2.0 with a Lakehouse architecture, we have continuously strived to enhance performance and scalability to support large-scale analytical workloads. In our previous blog, we shared insights into the design considerations, best practices, and key learnings from implementing the Lakehouse architecture at Halodoc.
Building on that foundation, this blog focuses on our efforts to optimize Apache Hudi through automation, specifically for clustering, file resizing, and concurrency control, enabling streamlined operations and improved data processing efficiency.
After laying the foundation of Halodoc's modern data platform 2.0 with a Lakehouse architecture, we identified the need to optimize Apache Hudi workflows to further enhance performance and efficiency. To achieve this, we focused on automating three key processes:
- Clustering: Clustering is a data layout optimization technique that helps group the smaller files into larger, sorted files to minimize storage fragmentation and improve query performance.
- File Resizing: File resizing dynamically manages small files in the datalake to mitigate issues like query slowdown, pipeline slowdown, inefficient storage problems, etc.
- Concurrency Control: Concurrency control in Apache Hudi manages coordinated access to a table, ensuring atomic writes and consistent data through mechanisms like Optimistic Concurrency Control (OCC) and Multiversion Concurrency Control (MVCC).
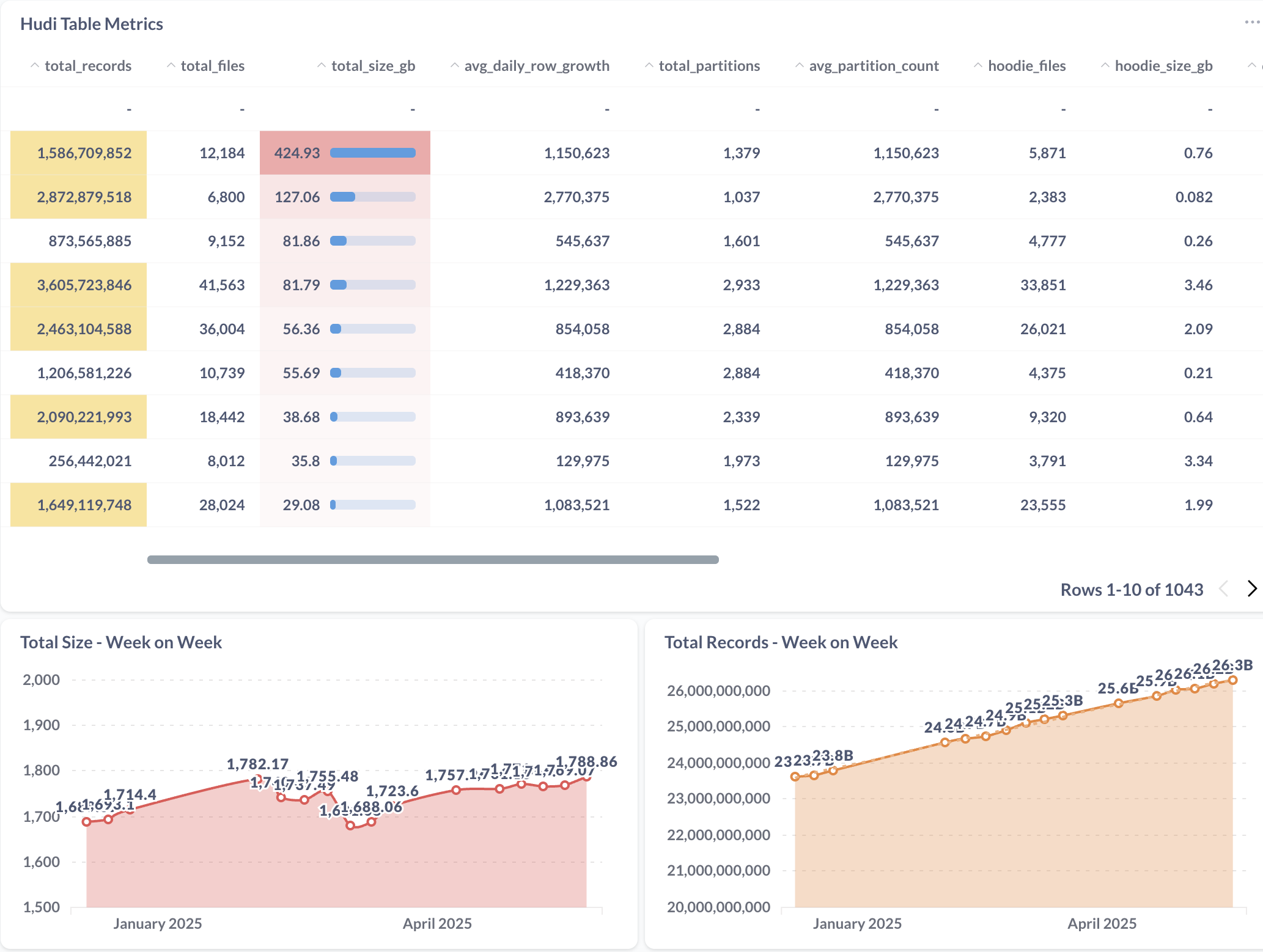
To enhance observability and performance monitoring of our Hudi tables, we built an in-house Hudi Metrics collection system using a scheduled pipeline. These metrics include table-level statistics such as row count and file size, gathered by executing queries and fetching relevant data from S3 using Boto3. This provided us with deeper visibility into the table health and helped us in our decision making.
Clustering
Clustering in Hudi is essential to optimize the storage and read performance of large-scale data tables. During our analysis, we observed that most active tables had small file sizes (around 1MB), far below the default Parquet file size of 120 MB. This led to a significant number of AWS S3 API requests and slower query performance. Additionally, migrating from MoR to CoW retained the smaller file sizes of older data, causing inefficiencies.
Methodology
- As non-partitioned small tables contributed most to the small tables, we prioritized clustering for non-partitioned small tables first.
- We introduced
is_clustering_enabledcolumn in our config table to control the tables with clustering enabled, so that we can enable it in batches to overcome any bugs while enabling. - Applied inline clustering specifically to tables without decimal columns or partition fields, as Hudi versions (up to 0.15) had bugs related to decimal data.
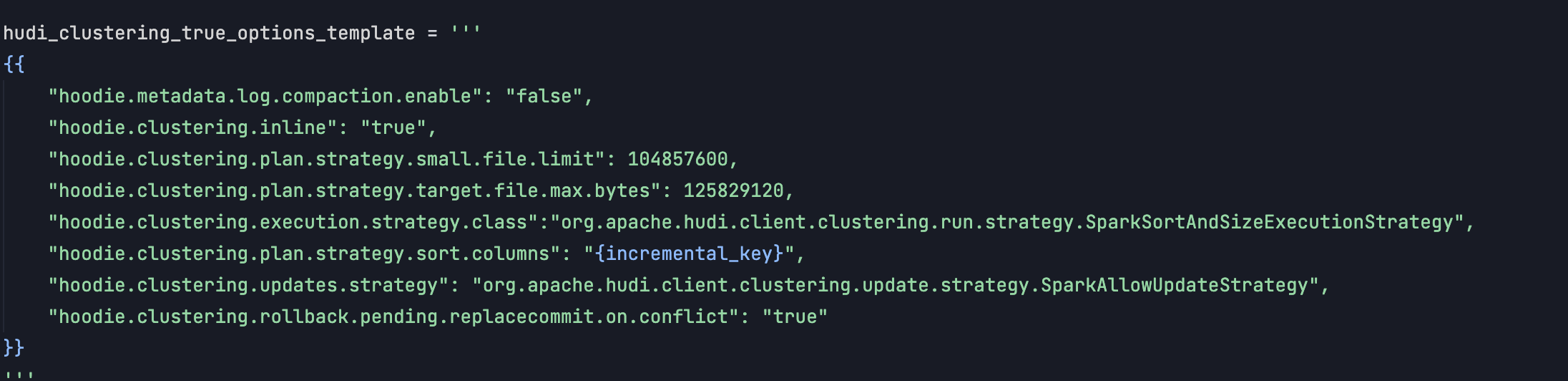
- Utilized the
SparkSortAndSizeExecutionStrategyto sort file groups by incremental key columns, enhancing read performance. - Clustering frequency was initially configured to run after every commit for faster processing, but now follows the default value of four commits.
Impact
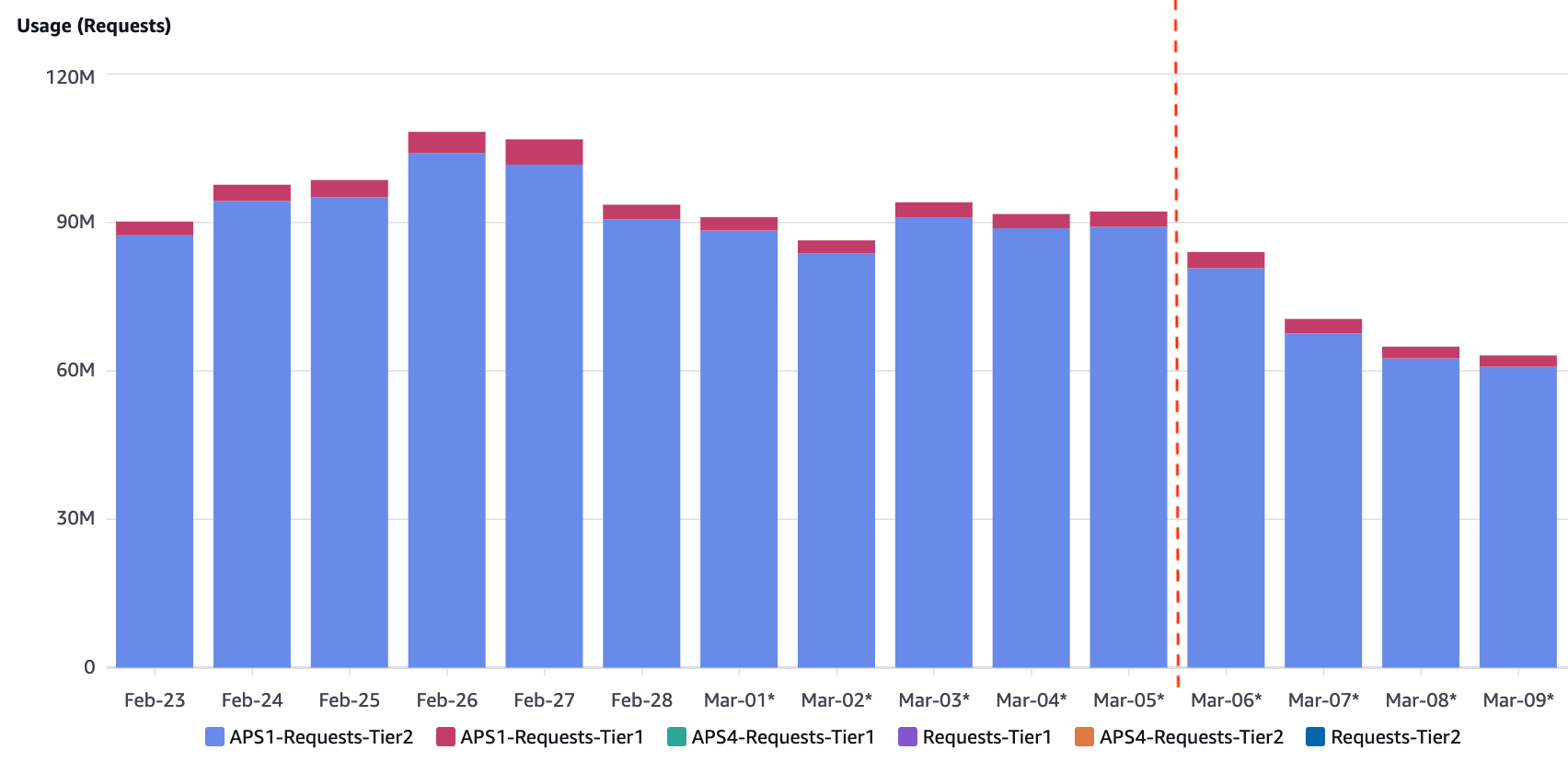
- Reduced S3 API Requests: Clustering reduced Tier 2 S3 API calls from around 88 million to 63 million per day, decreasing API costs by 26%.
- Faster Downstream Processes: Spark application metrics showed that clustering significantly reduced the runtime of dim and fact jobs by 13% (from an average of 5.4 minutes to 4.7 minutes).
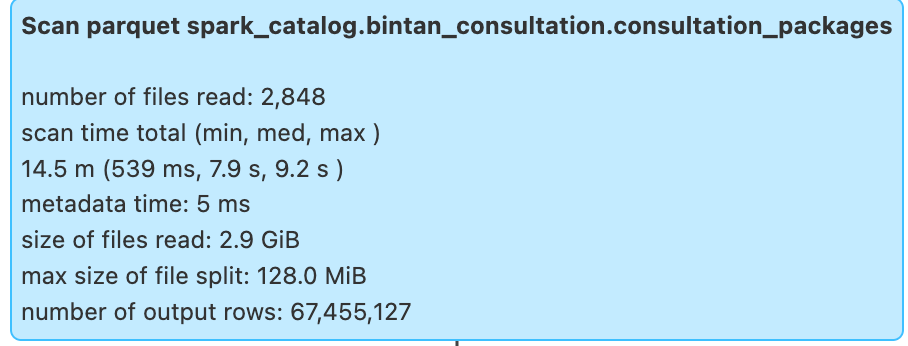
- Improved Spark Job Performance: A specific clustering example reduced the data scan time of a table with over 60 million rows from 14.5 minutes to just 8 seconds.

File Resizing
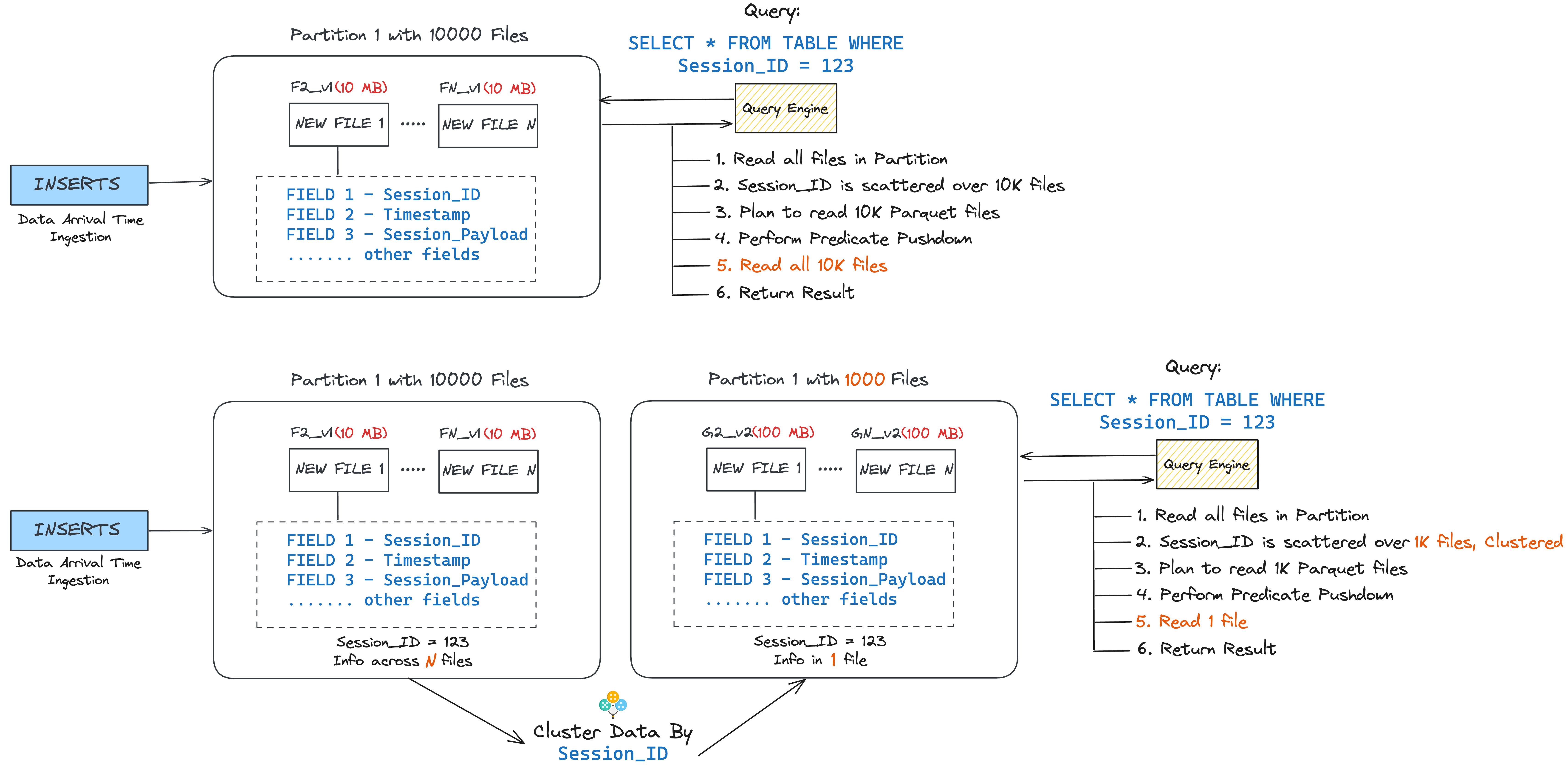
After clustering non-partitioned tables, we observed a noticeable reduction in S3 costs and Spark scan times. However, a deeper analysis using S3 Storage Lens revealed that partitioned tables still had a high concentration of small files. Further investigation with Hudi Metrics showed that 35% of these tables were unnecessarily partitioned. In such cases, even enabling clustering doesn’t help, as each partition may hold too little data to reach the target file size, leading to fragmented writes and limited effectiveness of clustering in reducing small files.
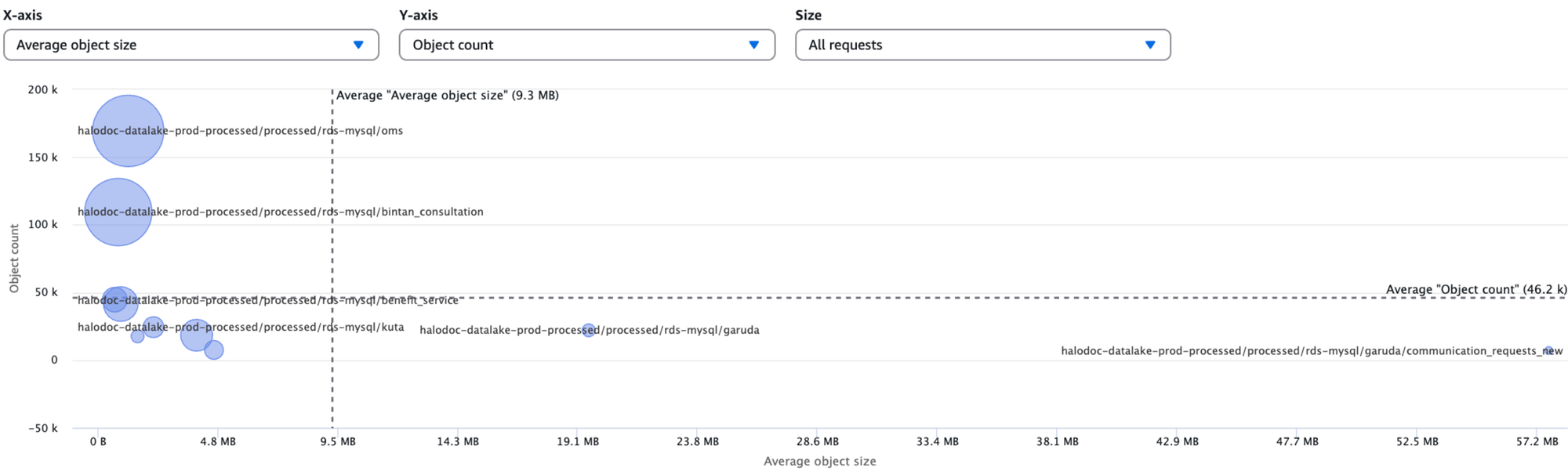
This highlighted the critical need to resolve file fragmentation to ensure optimal Lakehouse performance.
Methodology
- As per the collected Hudi Metrics, we filtered the partitioned tables in the first place. Then based on the avg_data_file_size we have shortlisted the tables which need to be converted to non-partitioned.
- Used a Spark job to read data from existing partitioned Hudi tables to capture the latest state.
- Data was written to a new non-partitioned Hudi table on a different path in S3, eliminating partition overhead and reducing small file issues.
- Incremental pipelines were updated to target the new non-partitioned path, improving performance and reducing S3 costs.
- This has significantly increased the avg_data_file_size to almost double the file size before, even in the partitioned tables in the data lake.
Impact
- Improved File Size Efficiency: Migrating 35% of partitioned tables to non-partitioned tables significantly increased the average data file size, reducing file fragmentation and storage overhead.

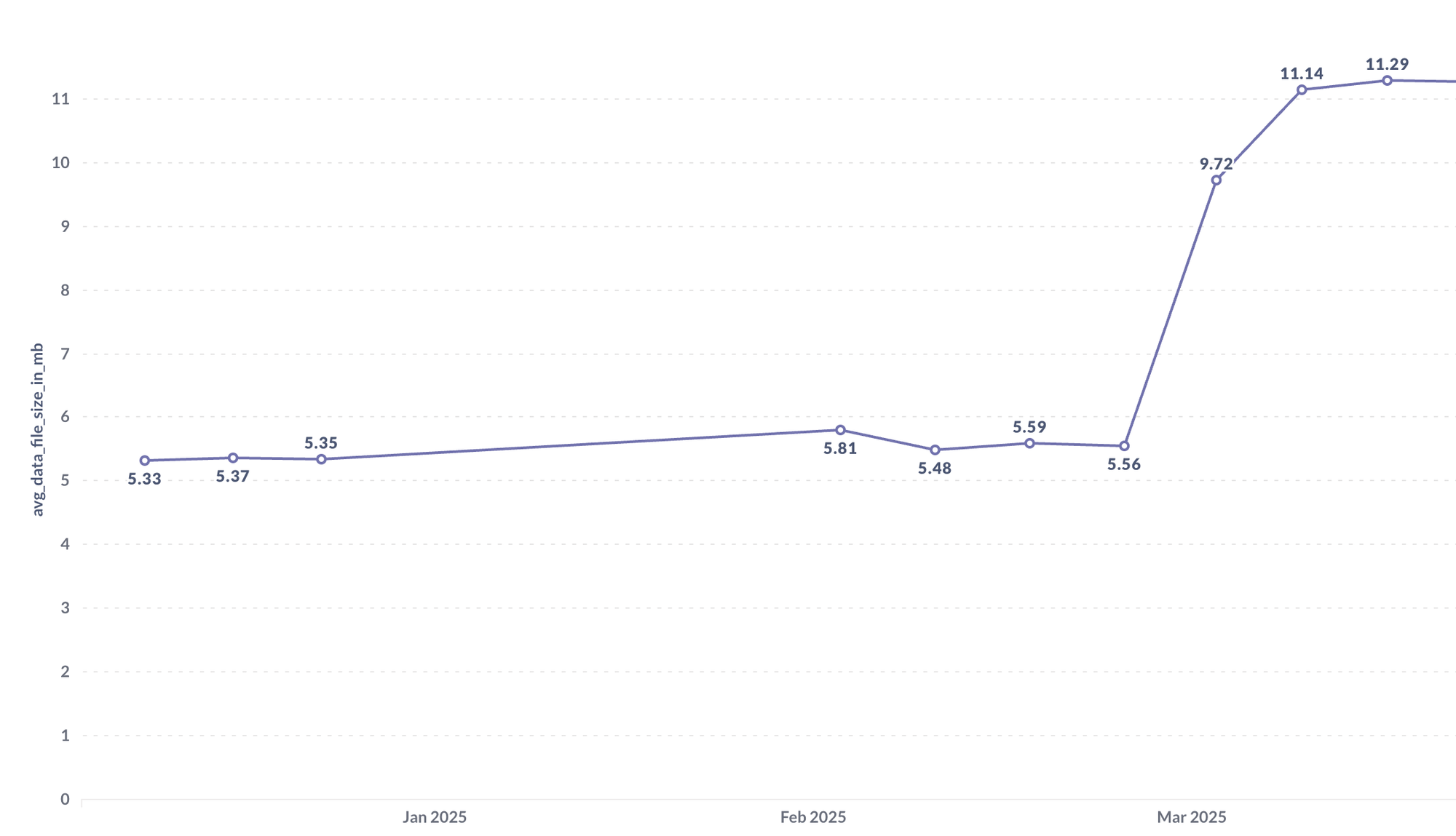
- Enhanced Query Speed: Reducing the number of small files resulted in faster read times, even for the partitioned tables, and improved overall performance of downstream reporting jobs.
- Reduced S3 API Costs: As mentioned above, this has further minimized the number of small files and decreased S3 API requests, leading to noticeable cost savings in data lake operations.
Concurrency Control
As the platform matured, while moving from a single-writer system to a multi-writer system, different types of writers came into play, like backfiller jobs, incremental jobs, migration jobs, etc. Hence, the necessity for introducing concurrency control came into the picture. The concurrency control in Hudi is the mechanism that allows multiple writers to modify data simultaneously while maintaining data consistency and preventing conflicts.
Methodology
- To address this, we implemented Optimistic Concurrency Control (OCC) to support multiple writers. OCC, coupled with file-level locking, ensures that concurrent write operations do not result in conflicts or data inconsistencies.
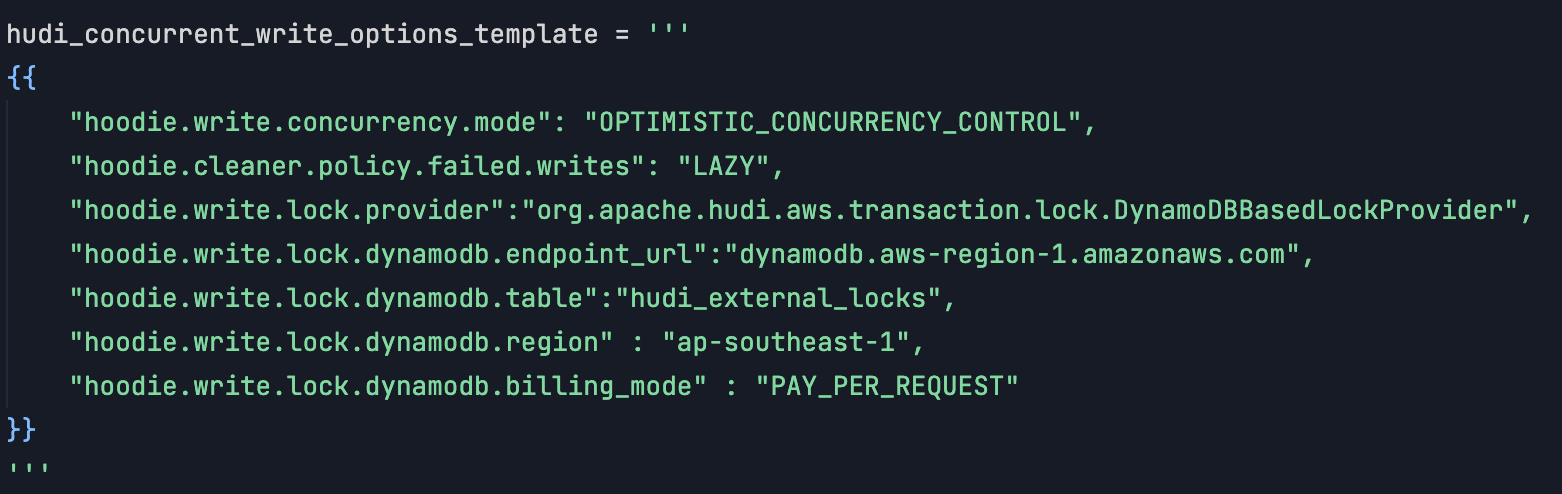
- To coordinate write operations, we introduced a DynamoDB-based external locking mechanism. During each write operation, Hudi generates a temporary lock file in the DynamoDB table

- The lock provider was configured to use DynamoDB, specifying the endpoint, table name, and region through the Hudi options.
Appropriate permissions were granted to EMR and Airflow for DynamoDB operations in the IAM, including creating, updating, and deleting the lock files.
Impact
- By implementing multi-writer concurrency control using OCC and DynamoDB-based locking, we significantly enhanced the scalability and performance of the data ingestion pipeline with very little additional cost of $1.5 per month.
- This approach allowed for efficient and consistent data processing across multiple concurrent writers, reducing write conflicts and improving overall system throughput.
Summary
In summary, implementing clustering, file resizing, and concurrency control significantly improved the performance and scalability of our data lake. Clustering optimized file sizes and reduced S3 API calls by 28%, while downstream job runtimes dropped by 13%. Through Hudi Metrics, we identified that 35% of partitioned tables were unnecessarily partitioned; migrating them to non-partitioned tables helped double the average file size and reduce fragmentation, further improved scan efficiency, and storage utilization. Concurrency control using OCC and DynamoDB-based locking enabled smooth multi-writer operations with strong consistency. These efforts collectively enhanced data processing and reduced operational costs.
References




Join us
Scalability, reliability, and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels, and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number one all-around healthcare application in Indonesia. Our mission is to simplify and deliver quality healthcare across Indonesia, from Sabang to Merauke.
Since 2016, Halodoc has been improving health literacy in Indonesia by providing user-friendly healthcare communication, education, and information (KIE). In parallel, our ecosystem has expanded to offer a range of services that facilitate convenient access to healthcare, starting with Homecare by Halodoc as a preventive care feature that allows users to conduct health tests privately and securely from the comfort of their homes; My Insurance, which allows users to access the benefits of cashless outpatient services in a more seamless way; Chat with Doctor, which allows users to consult with over 20,000 licensed physicians via chat, video or voice call; and Health Store features that allow users to purchase medicines, supplements and various health products from our network of over 4,900 trusted partner pharmacies. To deliver holistic health solutions in a fully digital way, Halodoc offers Digital Clinic services, including Haloskin, a trusted dermatology care platform guided by experienced dermatologists.
We are proud to be trusted by global and regional investors, including the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. With over USD 100 million raised to date, including our recent Series D, our team is committed to building the best personalized healthcare solutions — and we remain steadfast in our journey to simplify healthcare for all Indonesians.

