

Implementing Privacy by Design Through Privacy Checkpoint in CI Pipeline
Introduction
Protection of personal data is paramount for Halodoc to safeguard the privacy of the users. This objective requires integrating privacy considerations into every stage of product or service development, ensuring it is not an afterthought but a fundamental aspect or it is known as Privacy by Design.
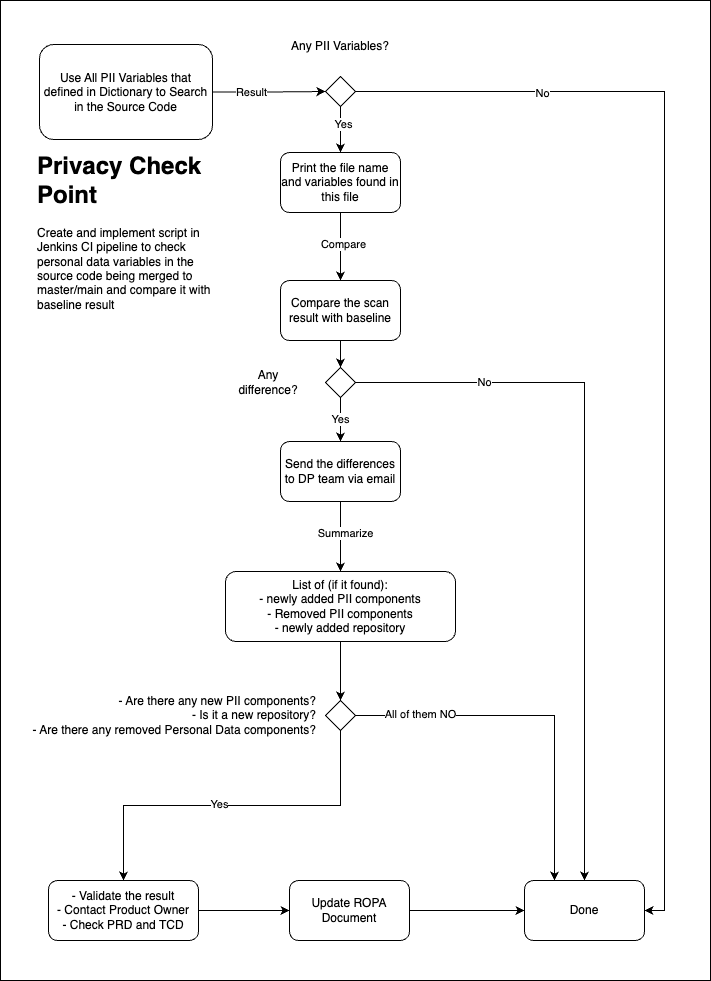
One of the key steps of Privacy by Design is to ensure that personal data being collected and processed in the platform are completely identified and recorded as the organization's Record of Processing Activities (ROPA document) prior to production. Halodoc implements a Privacy Checkpoint as part of the CI Pipeline of the application development to automate the PII variable identification process.
The Privacy Checkpoint
At Halodoc, the Privacy Checkpoint is a PII variable scanning approach that is implemented through a Jenkins Shared Library. This checkpoint scans source code for PII variables. The process involves six main steps:
- Establishing the Baseline for PII Scanning in the CI Pipeline by Creating a PIIScan Job in Jenkins
- Analyzing the Baseline results
- Update ROPA as Baseline
- Creating a checkpoint in the CI pipeline, and
- Analyzing the results of checkpoint
- Updating ROPA (if any variance).
1. Establishing the Baseline for PII Scanning in the CI Pipeline
The Baseline captures the current or as-is condition of PII variables in the platform prior development of a new application. It serves as a starting point for updating our Records of Processing Activities (ROPA) document. ROPA consists of any services that process personal data and its purposes. This is the example:

The baseline comprises establishing the PII Dictionary from existing PII variables and the Performance of Initial Scanning based on the PII variables.
a. Establishing PII Dictionary from existing PII variables
- Identify PII variables that are currently used in existing source code in production. These PII variables are then recorded as PII Dictionary. PII variables that contain similar information are grouped as a PII component. Examples: DOCTOR_PHONE and USER_PHONE are grouped as PHONE_NUMBER for the PII component.
- The PII dictionary is composed of two files: `piiData.txt`, containing the list of PII variables, and `dictionary.txt`, a Python-formatted mapping from PII variables to PII components.
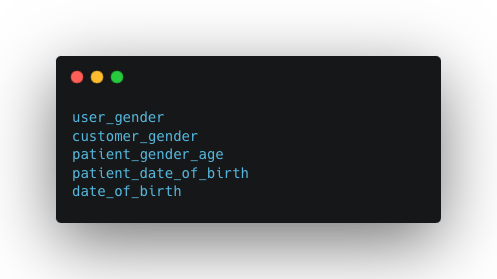
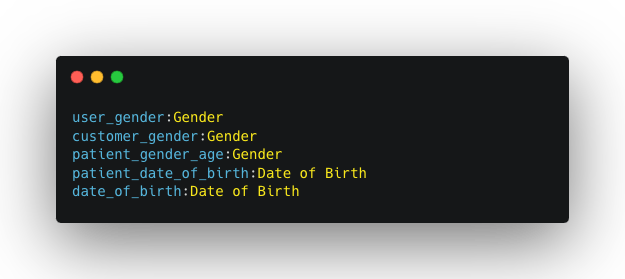
- piiData.txt and dictionary.txt files will be used as the reference to scan and identify PII variables in the existing repositories in production to capture existing PII variables in our ROPA documents.
b. First Scan Result of Existing Repositories:
- We conduct an initial scan of all repositories listed in Jenkins to capture the current state of PII variables.
- The results are stored in files, which are then saved to our cloud storage.
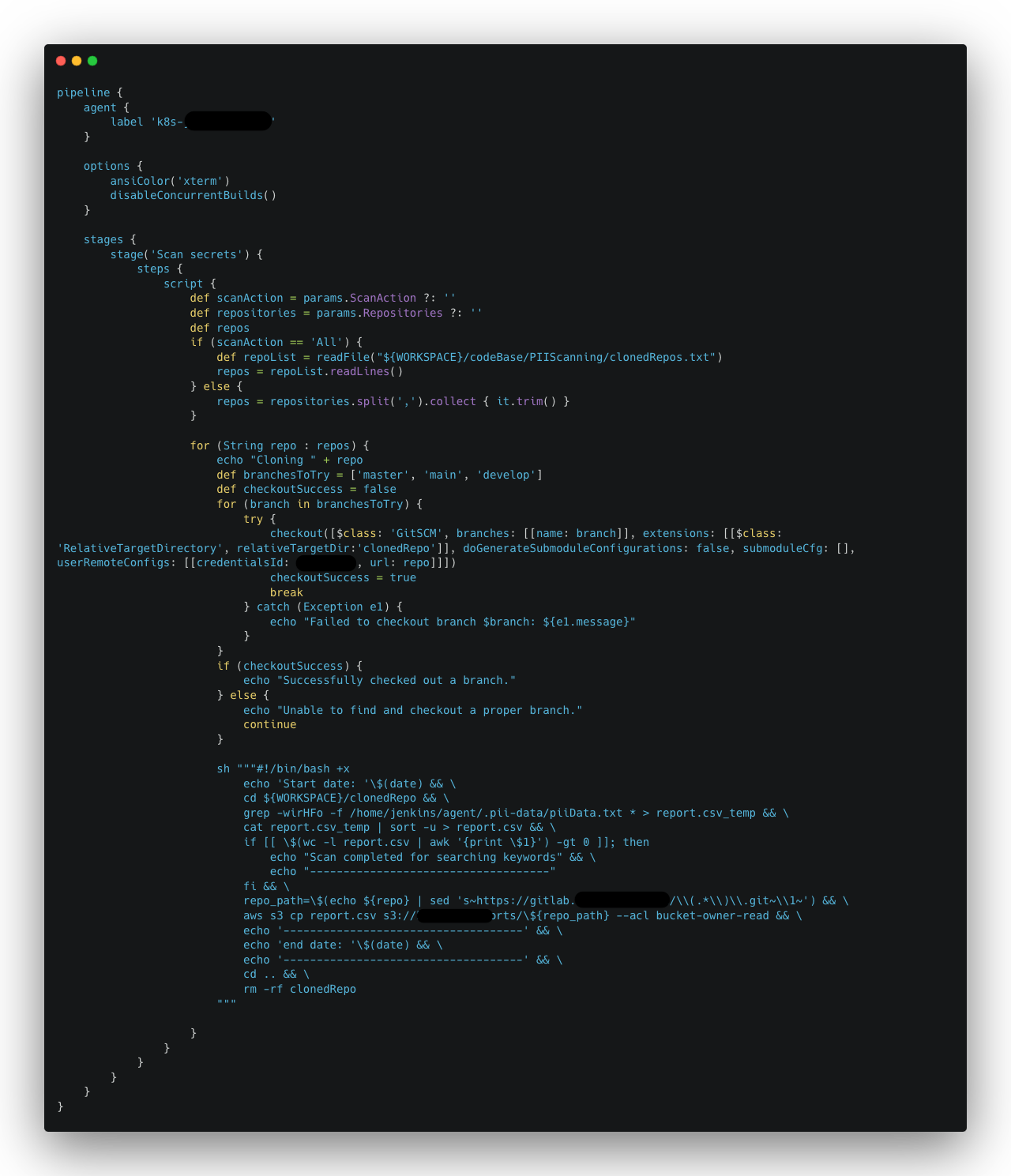
- Jenkins Job for creating a baseline is using a freestyle Jenkins job with logic as follows:
- Create a `clonedRepos.txt` file containing the repositories to be scanned.
- Use Git to clone each repository into the Jenkins workspace, focusing on main or master branches.
- Execute a PII variable scan based on the definitions in `piiData.txt` as defined in step #1 above for each cloned repository.
- Save the scan results in a file for each repository.
- Transfer the files to our secure cloud storage.
- Delete the cloned repository and associated scan results to maintain workspace hygiene.
- Repeat these steps for each repository listed until all have been scanned.
- The PII Scanning Code for the above steps is as follows:
- To run the PII Scanning job from Jenkins, a `PIIScanning.groovy` file is created as Jenkins configuration. This allows parameters to specify whether to scan all repositories or select specific ones.
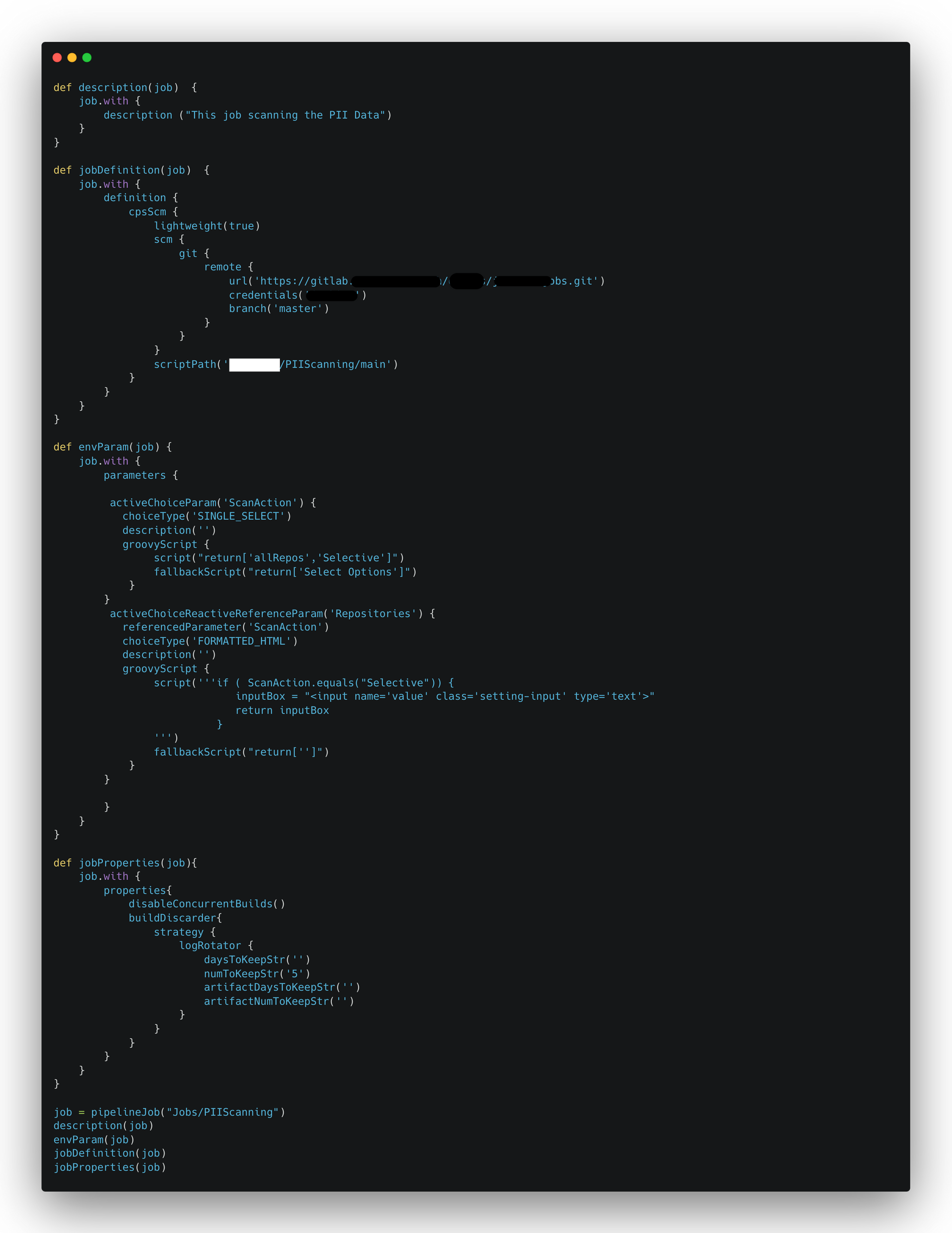
- After we put those 2 files into the Jenkins configuration folder, the PIIScanning job can be run from Jenkins and we can put parameters whether we want to scan all repositories or selected repositories. This is how it looks like in Jenkins.

- The scan results, displaying file paths and identified PII variables, are stored in the cloud storage. This baseline captures the current state of PII across our codebase which will be recorded in our ROPA document as initial.

2. Analyzing the Baseline results
The output of the privacy scan can be extensive, making analysis challenging. We have developed scripts to summarize and compare scan results, streamlining the analysis process. These scripts facilitate the identification of new or modified PII variables, aiding in manual verification and updates to the ROPA document.
Here are the steps when analyzing the baseline scan result:
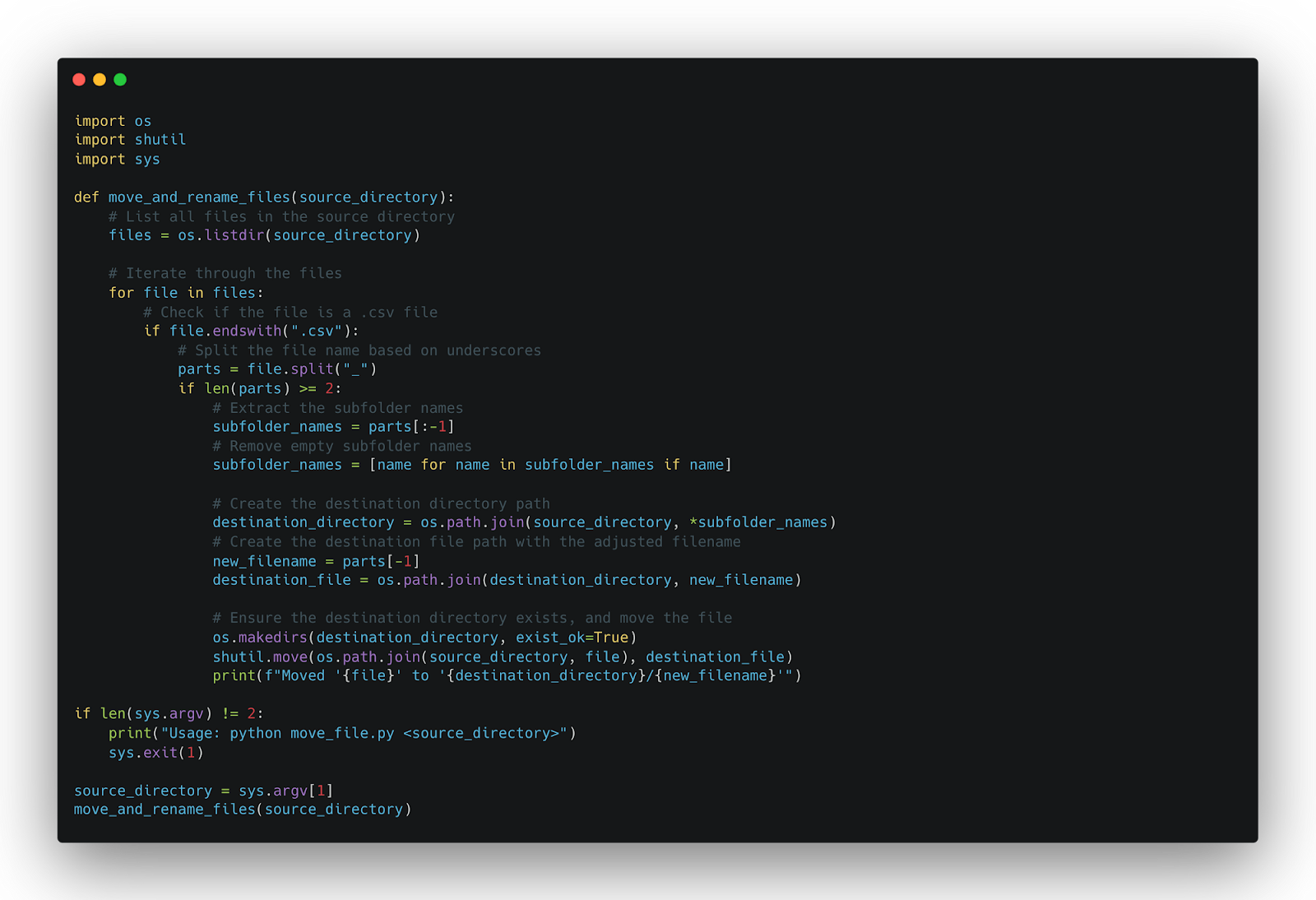
- download all the results to localhost and move those files to a specific folder (move_file.py)
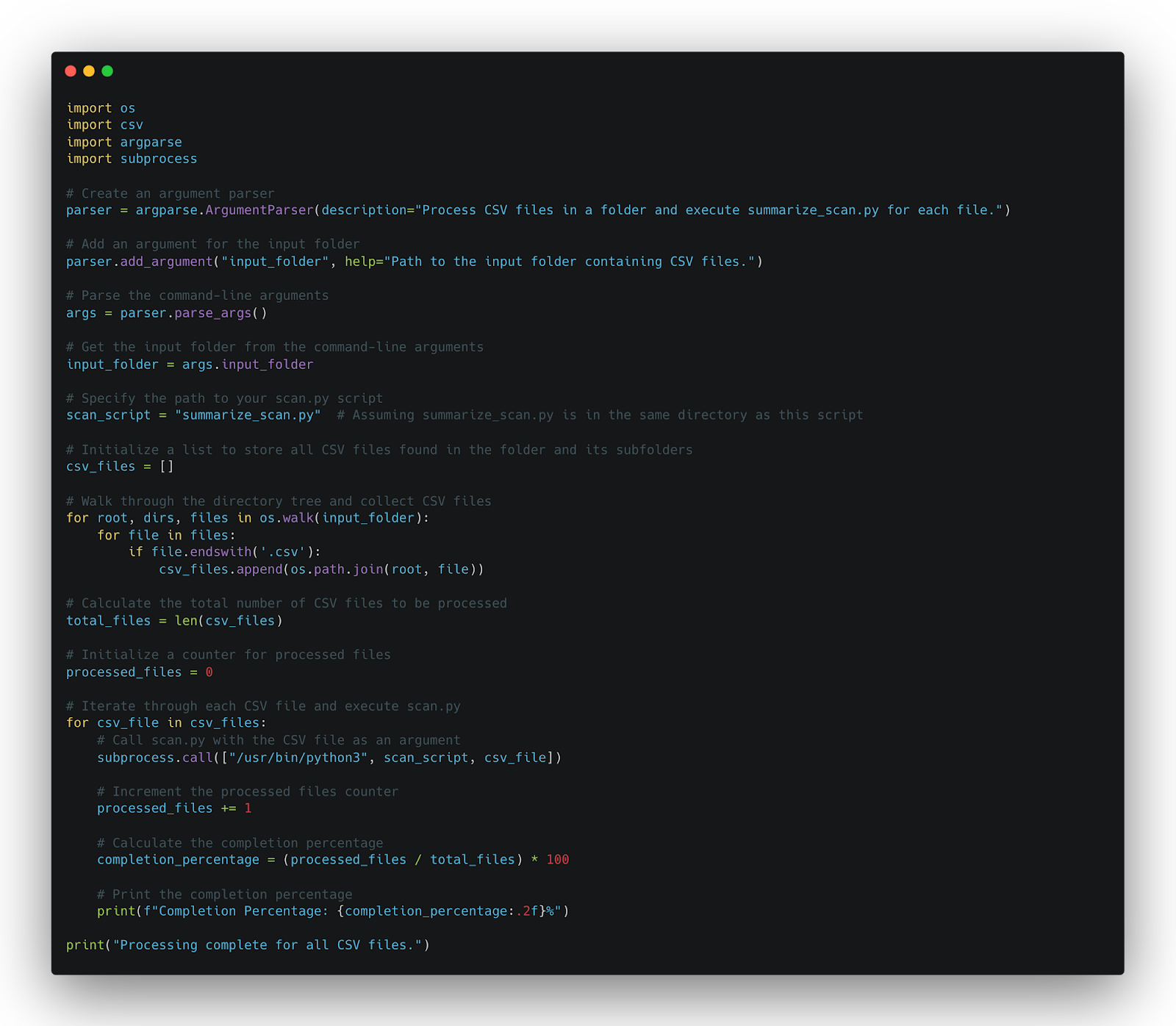
- run the scan to summarize the scan result by comparing the PII variables in the scan result with dictionary.txt. Exclude some keywords if needed. (call_scan_summarize.py)
- store the summary result in the baseline_ROPA folder in localhost manually. The summary file is stored as a .txt file with the same file name in another format.
We use Python to write the script for the above steps.
This is the simple script to move the file to a specific folder based on the output file name:
The call_scan_summarize.py script is created to call the main summarizing script (summarize_scan.py) in the iteration for each file which is found in the defined folder.
This is the main script for summarizing the scan result:
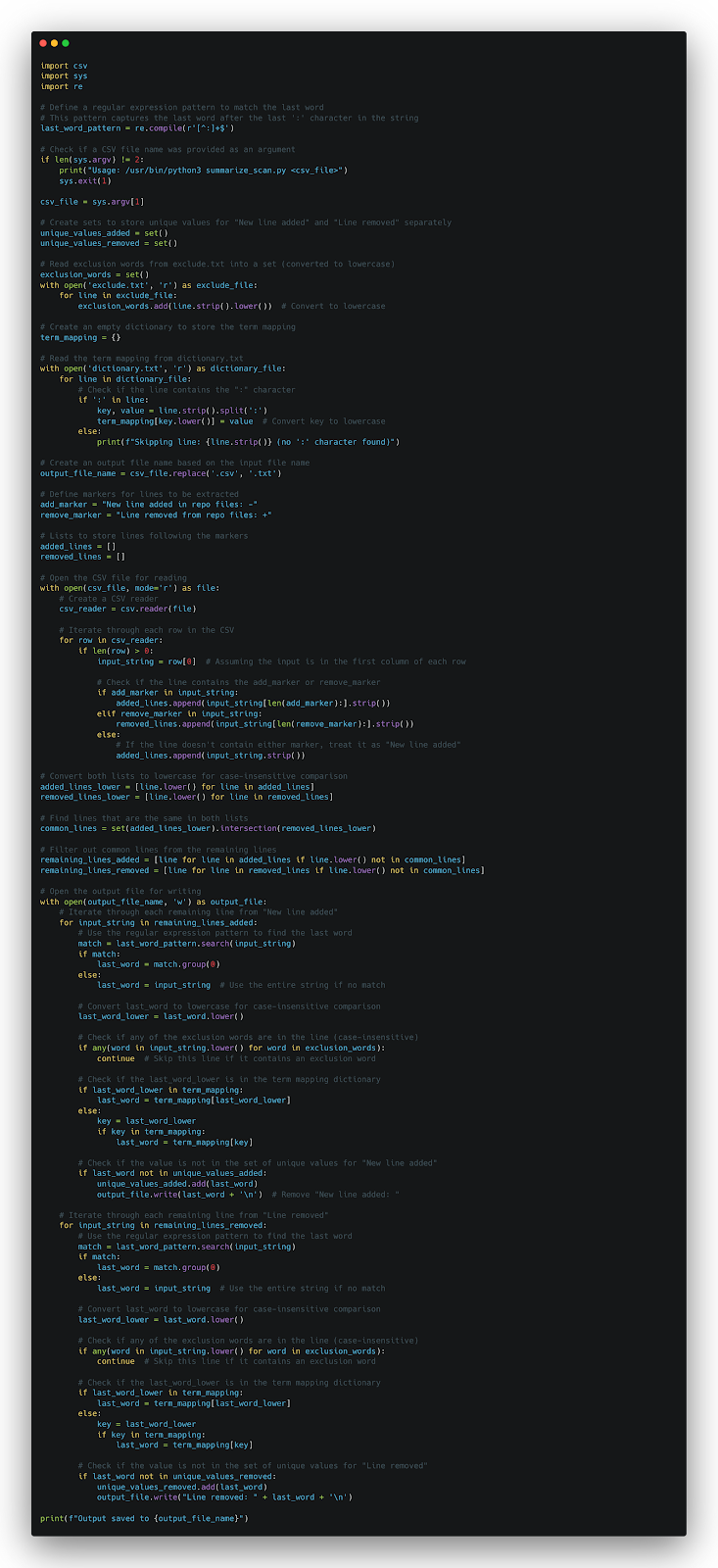
This is the sample of summarizing results which found some PII components such as gender, email address, and phone number for the repository named catalog:

After the summarization process is completed, all .txt files need to be put in the baseline_ROPA folder. The structure of the folder must be similar to the result of the move_folder.py script.
3. Update ROPA as Baseline
Based on the baseline scan, we need to verify the result to ensure that the variables are not part of the comment in the source code, prompt message, or any other condition that is not valid variables. If the result is valid then we need to put the repository name and its PII components in this ROPA document as a new record.
This updating ROPA document concluded the process of developing a baseline of personal data being collected and processed in our application.

4. Creating a Checkpoint in the CI Pipeline:
To develop a privacy checkpoint we will use a script similar to baseline scanning with an additional step that compares the current scan result to the baseline result. The variance of comparison will be the input to review whether there is any new PII variables being processed or there is any PII variables being removed from the source code.
After developing the privacy checkpoint script, the script will be integrated into the CI pipeline as a stage after the Source Control Management (SCM) checkout. It scans source code for PII variables and compares the results against the baseline. Any deviations trigger alerts, facilitating prompt action to address privacy concerns. These main processes will be elaborated below.
This is the code that needs to be added to the Jenkins Shared Library file:
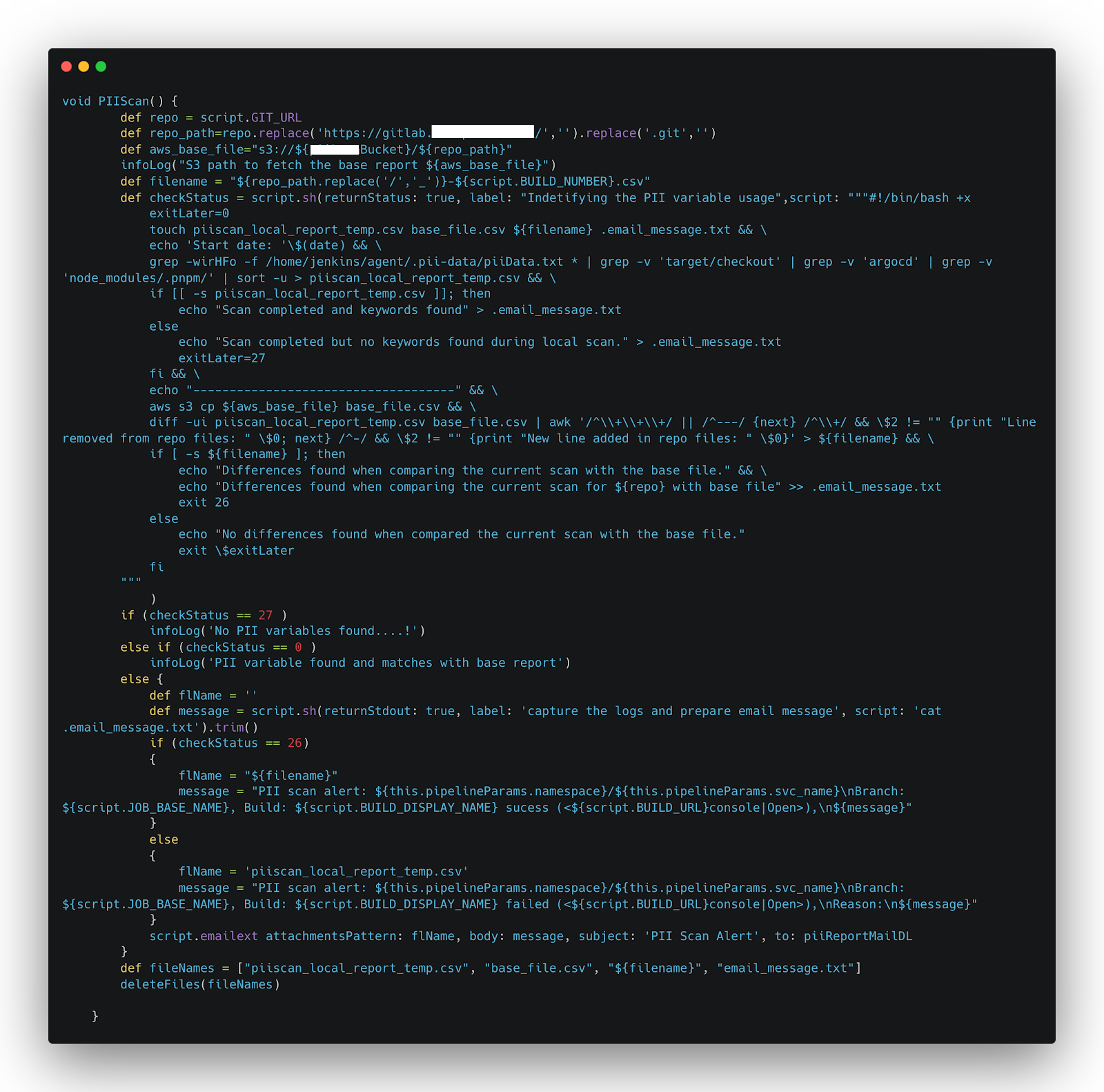
The functionality of the code can be broken down into the following steps:
1. Retrieve the base URL of the repository under consideration.
2. Generate a temporary file to serve as storage for the comparison results.
3. Utilize the `grep` command to compare the personally identifiable information (PII) variables defined in `piiData.txt` with all files located within the workspace folder. If no PII variables are identified in the repository, exit the process.
4. If PII variables are found, save the comparison results in the previously created temporary file.
5. Retrieve the baseline file from the specified cloud storage.
6. Use the `diff` command to compare the contents of the temporary file (containing the newly identified PII variables) with the baseline file. If there are no differences, exit the process.
7. If differences are detected, print the result, indicating variances between the temporary and baseline files.
8. If variations are identified, trigger an email notification containing the result, and attach the temporary file for further analysis.
This process ensures a systematic and automated comparison between the newly identified PII variables in the current repository and the baseline from the cloud storage. If any deviations are found, the system alerts via an email notification, providing transparency and facilitating swift corrective actions to maintain data privacy and compliance.
To integrate the PIIScan void into the pipeline stages and trigger the PII scan specifically during the production environment, add a PII Scan stage to the pipeline configuration file. Below is an example of how to structure this in a Jenkins pipeline script:

This is the sample output of the scan:

From this result, we have identified 2 changes in the service.java file:
1. The variable 'fullname' has been introduced to the service.java file. This implies that developers have included a new personally identifiable information (PII) variable related to the full name of an individual in the code.
2. The variable 'npwp_number' has been removed from the service.java file. This suggests that developers have taken action to eliminate a previously defined PII variable related to the NPWP number.
5. Analyzing the results of the checkpoint
For analyzing the checkpoint result the first 2 steps are the same as analyzing the baseline result. However, there is 1 more additional step after the summarizing process which is the comparison between the summarization result of the checkpoint with the summary of the baseline result.
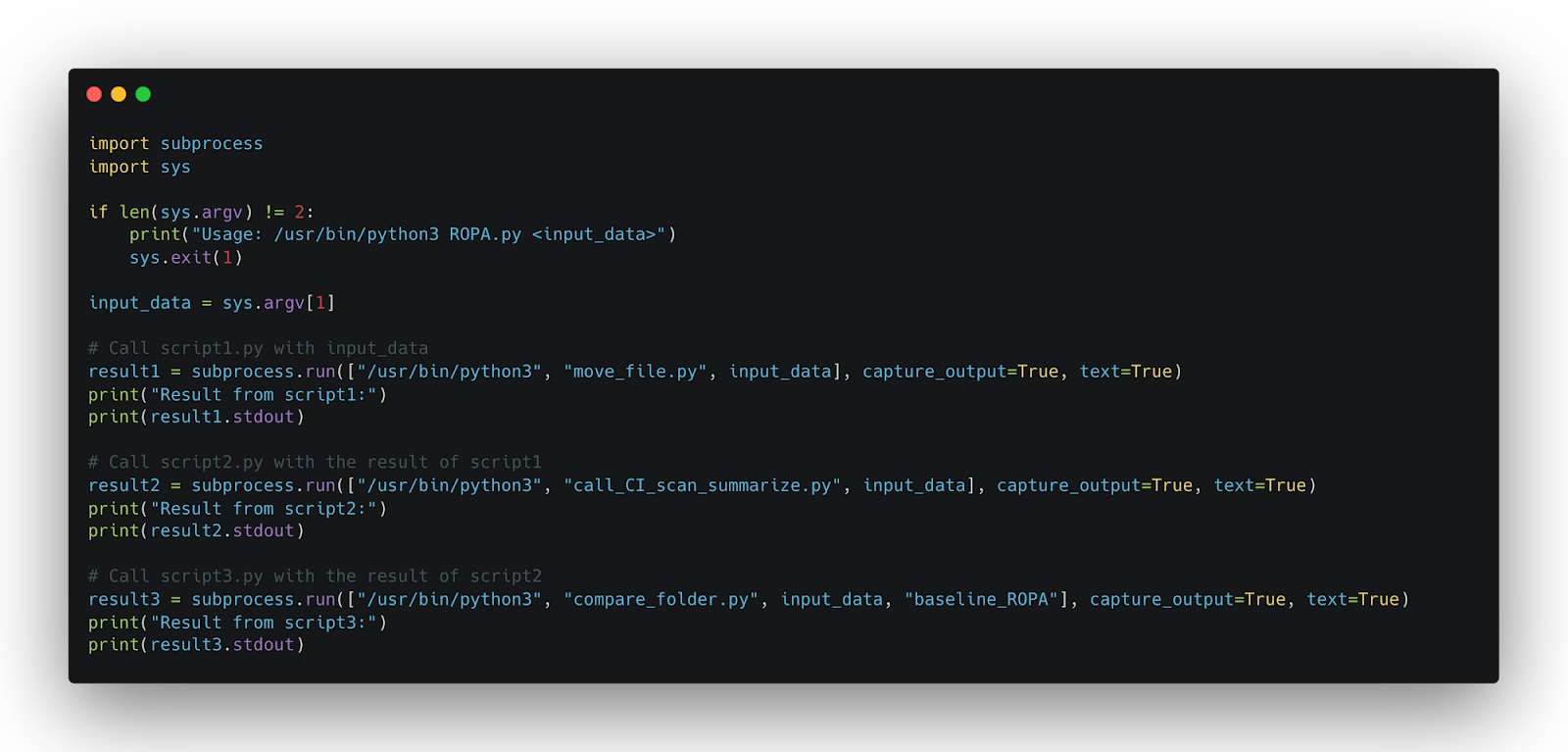
The comparison part works by comparing the files between a folder containing the checkpoint result and a folder containing a file of the summaries of the baseline scan. This is the script for compare_folder.py:
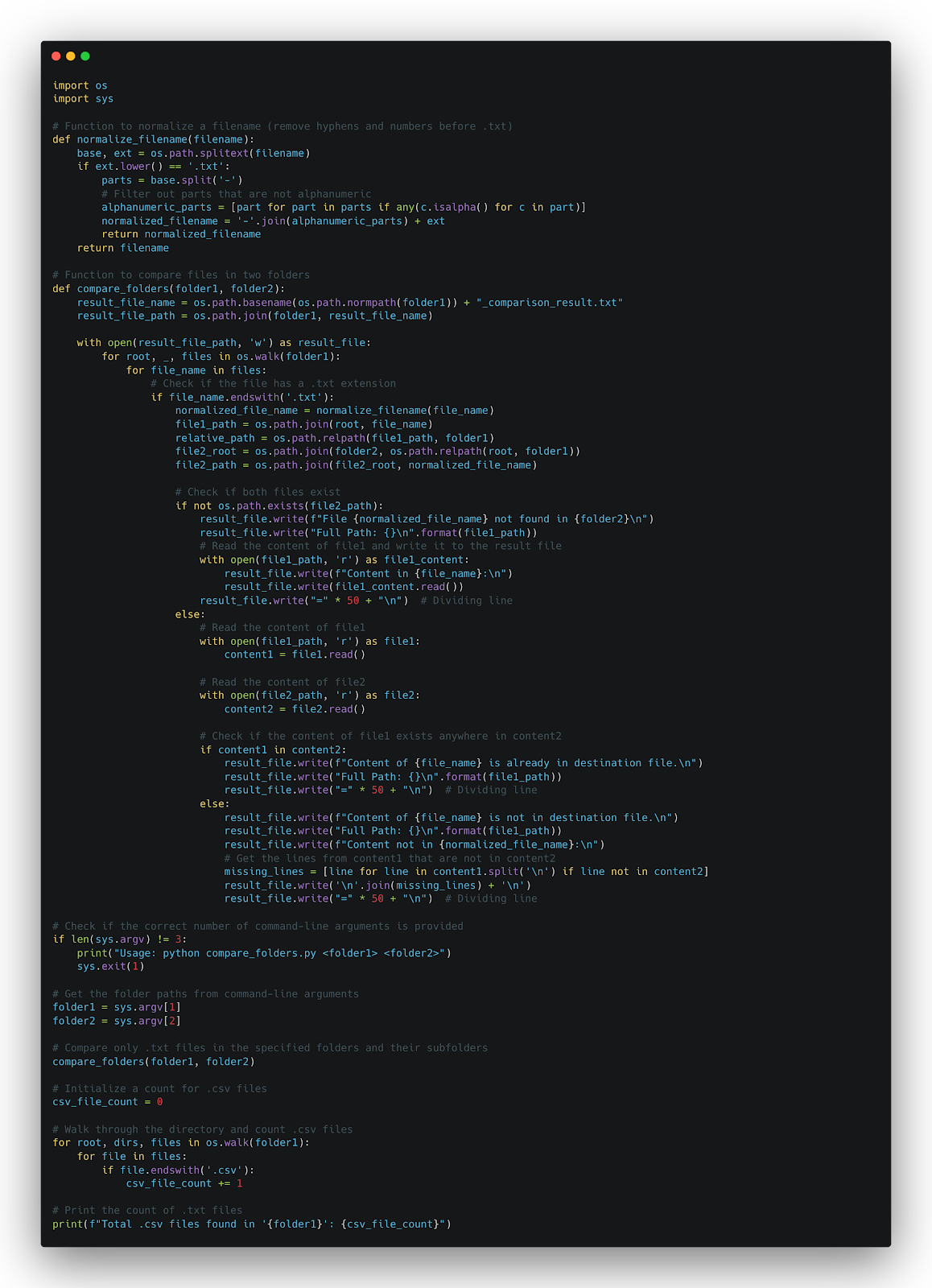
If any differences are found in this comparison, it will be printed in a .txt file. This comparison will also detect if there is any new repository in the Jenkins pipeline.

6. Updating the ROPA document
Based on the Privacy checkpoint scan result, any variances will also need to be verified. If the result is valid then we need to update it in this ROPA document. This checkpoint also can identify if any new repositories are deployed.
Conclusion:
Our adoption of privacy by design principles underscores the commitment to data privacy and compliance with regulatory requirements. By leveraging existing tools and developing effective scripts, we have integrated privacy considerations seamlessly into its development workflow. We remain poised to enhance our privacy practices further, with future improvements focused on automation and integration.
Implementation of the Privacy Checkpoint helps the organization to apply privacy by design principle and improve the compliance postures in safeguarding sensitive data responsibly and ethically.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. We recently closed our Series D round and In total have raised around USD$100+ million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


