

Security Operation Center (SOC)
The rising sophistication of cyber threats has made cybersecurity a top concern for organizations across various industries. Cybersecurity threats such as data breaches, ransomware attacks, and malware infections can cause significant financial losses, reputation damage, and legal liabilities for businesses and according to a report by Cybersecurity Ventures, the cost of cybercrime is projected to reach $10.5 trillion annually by 2025. To minimize the risk of these growing threats, we must be proactive in preventing, detecting, and responding to the potential threats to avoid the devastating consequences of a security breach and one of the solutions to achieve this goal is to implement a Security Operation Center (SOC). In This blog post, we will start with an introduction of SOC, breaking down their key components and samples of use-cases as well as how SOC functions are built and implemented in Halodoc.
Overview Of Security Operation Center (SOC)
The concept of a Security Operation Center (SOC) has been around for several decades and most of us are more or less familiar with this term and their existence in the organizations. A SOC itself is a centralized function within an organization to continuously monitor various cyber security threats and improve an organization's security posture.
To ease our understanding let's break down the key components of a SOC on these following points and see the figure 1 for the high-level illustration. The SOC team should have access to a range of security tools and technologies, especially on the Security Information and Event Management (SIEM), Endpoint Detection and Response (EDR), Cloud Security Telemetry, etc. Other important technologies include firewalls, intrusion detection and prevention systems which will help SOC team to monitor and detect security incidents, and automate incident response processes wherever possible. In addition to this, the SOC team typically includes SOC analysts, engineers, and other support personnel who are responsible for monitoring and responding to the security incidents. One of the most important things about SOC is the ability to establish incident detection and response practices to identify and mitigate security incidents in a timely manner. These practices are governed by specific playbooks as a reference for the SOC team. One of the examples is developing an Incident response playbook to address specific security incidents for ensuring consistent treatment in responding to the specific attack such as phishing attack, malware infection and web defacement.
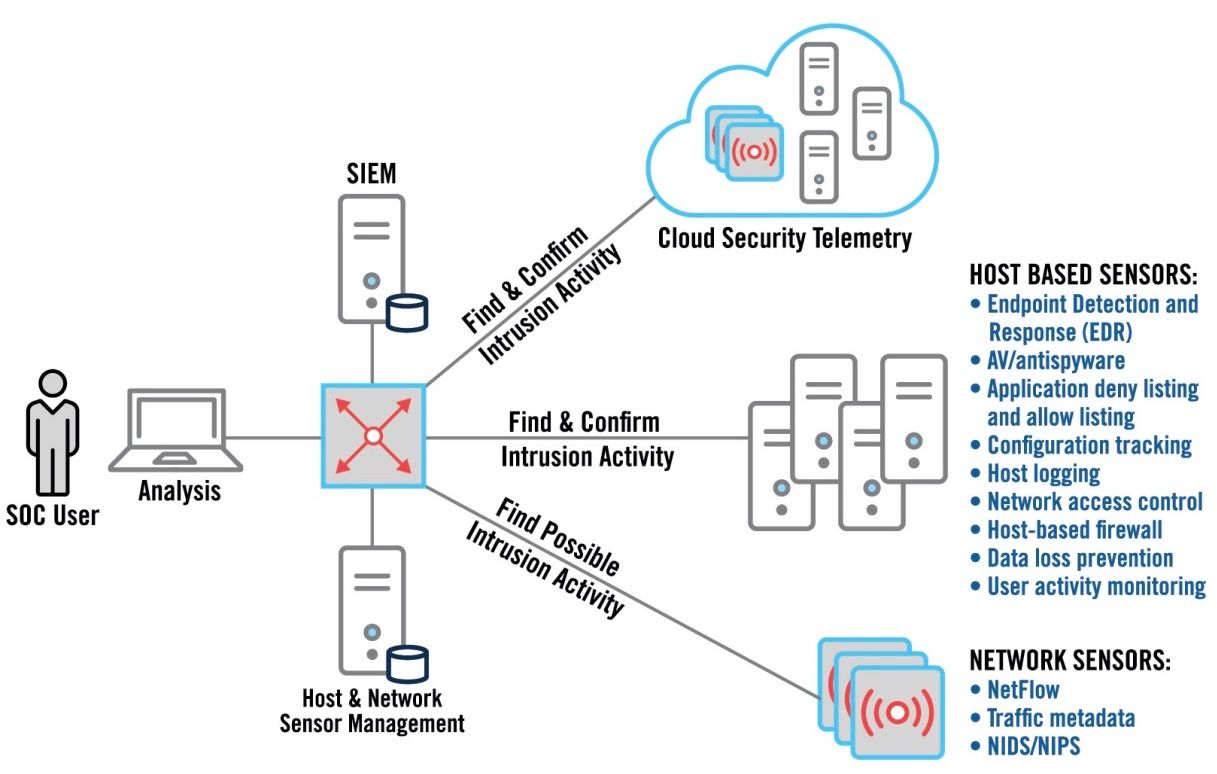
Why Do We Need Security Operation Center (SOC) ?
As we have described in the initial paragraph that cyberthreats become increasingly sophisticated and frequent where we should be more proactive in detecting and responding to the potential security threats. This is where the Security Operation Center (SOC) will play a part by providing a centralized unit for monitoring and analyzing an organization’s security posture around the clock.
Here are several key reasons on why Organizations like us requires a SOC functions :
- Early detection and response: SOC can detect potential security threats and incidents early, allowing organizations to respond promptly and minimize the impact of an attack. This can reduce the risk of financial loss, damage to reputation, and legal liabilities.
- Proactive approach to cybersecurity: SOC takes a proactive approach to cybersecurity by continuously monitoring an organization's infrastructure and systems which will help to identify potential vulnerabilities and security gaps before being exploited by cybercriminals.
- Improved incident response: SOC has a team of experienced security analysts who can respond quickly and effectively to security incidents. They are expected to identify the security threats or incidents and work hand in hand with respective subject matter experts (SME) to take appropriate action for mitigating the potential risks that might occur.
- Better security posture: SOC can help organizations improve their overall security posture by identifying vulnerabilities and recommending security controls. This can reduce the risk of future security incidents and help organizations stay ahead of evolving cyber threats.
How Halodoc Built Security Operation Center (SOC)?
Pain Points Identification
We started by listing down our pain points where we identified two main issues on why SOC function should be established:
- Platform was required to correlate and analyze the logs generated by our systems to identify the event anomalies and also critical security alerts that impede our ability to effectively respond to the potential threats.
- Sufficient playbook & automation to do around-the-clock monitoring of our security infrastructure for timely detection and response to the potential threats.
SIEM Technology Implementation
We start identifying the feasible solution to overcome our pain point by looking at the platform which has the capability to collect, aggregate, filter, store, correlate and visualize security-relevant data and form it into actionable information. The relevant technology which will be able to accommodate this requirement is Security Information and Event Management (SIEM).
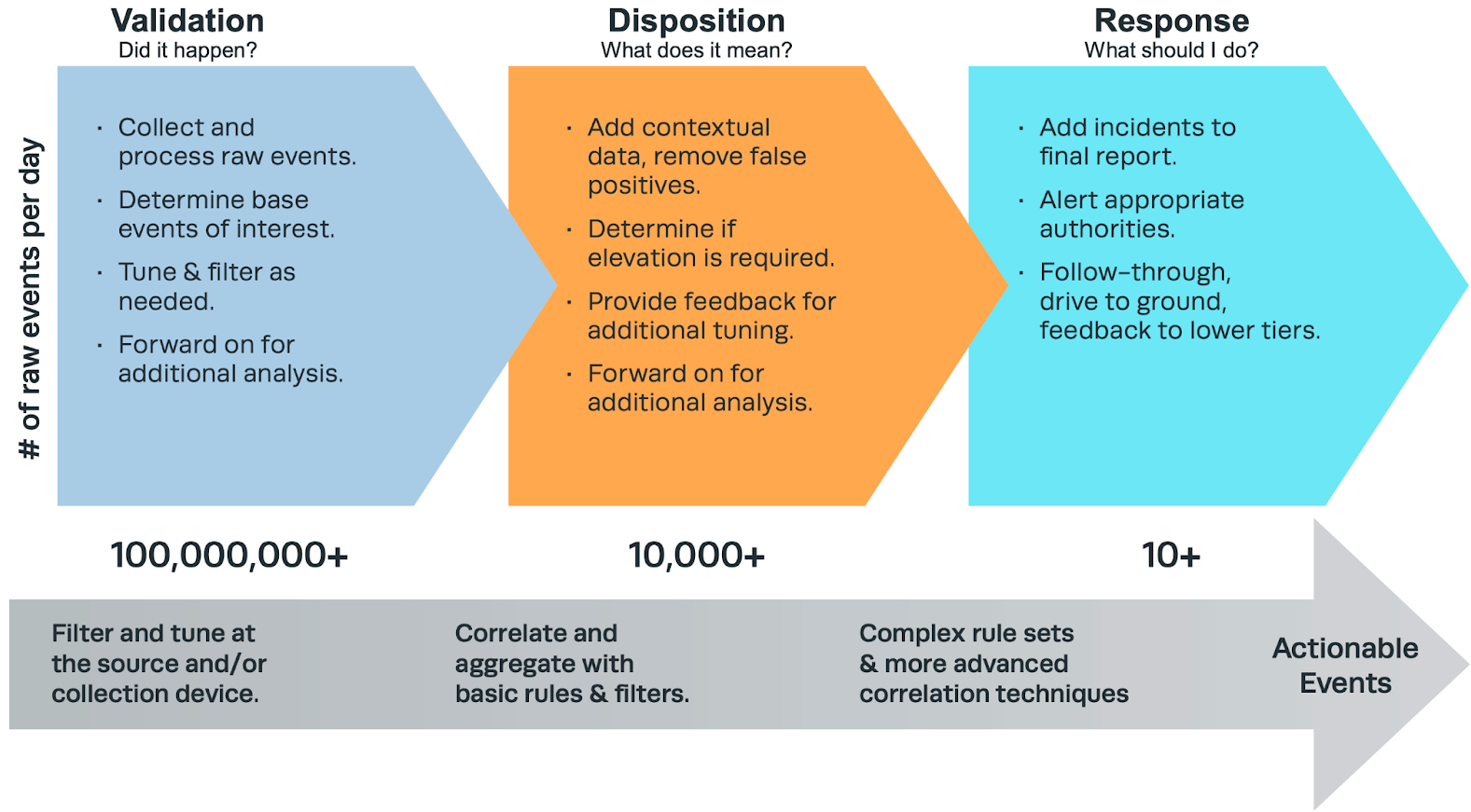
SIEM Technology will help us to collect the logs, time-strapped records of events, using either agentless or agent-based mechanisms and once the logs are aggregated within the SIEM, the next step will be the normalization process by using various analytical techniques, including log correlation and machine learning algorithms. See this following figure for the SIEM event lifecycle.
Furthermore, we are designing the architecture diagram to help us identify and prioritize the log sources that we are going to monitor for security events that will help us to collect and analyze the relevant data sources if there are any dependencies, technical limitations that need to be addressed during the SIEM technology development. See this following for our high level architecture diagram:
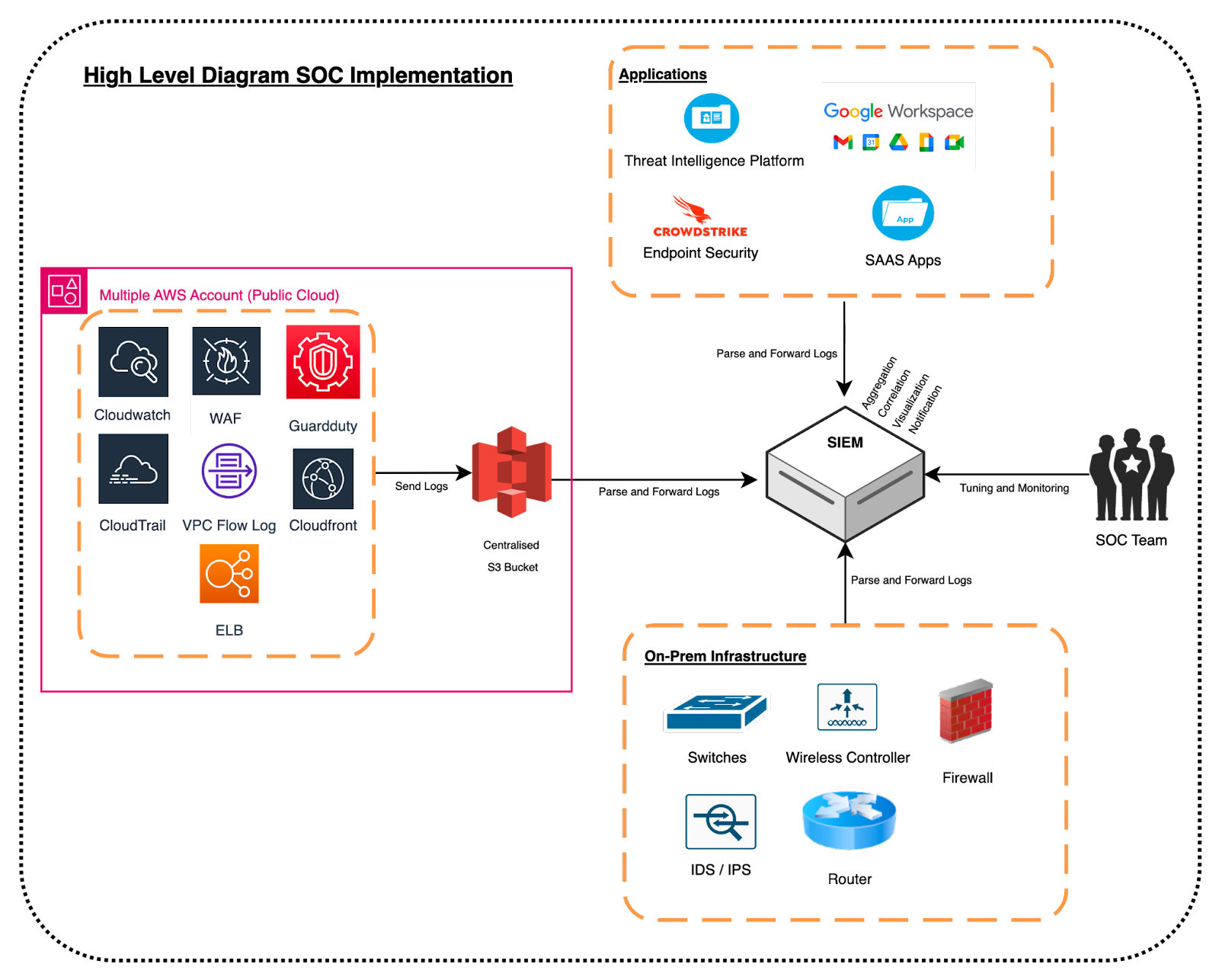
Once we are designing the SOC architecture diagram, the most important part is to do the evaluation of the SIEM product by performing the evaluation of the SIEM features, costs and also the long term support, where we have selected DSIEM solution to deploy in our organization.
DSIEM itself is a security event correlation engine for ELK stack that allows this platform to be used as a dedicated and full-featured SIEM system. Also, DSIEM will provide an OSSIM-style correlation for normalized logs/events, perform lookup/query to threat intelligence and vulnerability information sources, and produce risk-adjusted alarms.
There are two types of installation which is basic installation where we need to prepare one host with docker and docker compose installed and we can use the supplied Docker Compose files that includes DSIEM engine and all required ELK Stack or we can use the advanced deployment that support clustering mode for horizontal scalability that leveraged container orchestration engine, including kubernetes. To simplify the process let's do the DSIEM basic installation by following these steps :
DSIEM Installation
Prepare DSIEM Host
At Halodoc we are using advanced deployment that support clustering mode for horizontal scalability where we are leveraging AWS Elastic Kubernetes Services (EKS) for container orchestration engine with several front-end and back-end nodes and we are using Elastic Block Storage (EBS) for persistence storage.
DSIEM Deployment
- Copy this Github repository, unzip it, then open the result in terminal.
$ unzip dsiem-master.zip && cd dsiem-master
- Suricata needs to know which network interface to monitor the network traffic. Let's use the network interface that has a working Internet connection on our system like this :
$ export PROMISC_INTERFACE=eth0
- Replace eth0 above with the actual interface name given by ifconfig or similar commands. For testing purpose, it's not necessary to configure the interface to really operate in promiscuous mode.
- Set the owner of filebeat config files to root :
$ cd deployments/docker && \
sudo chown root $(find conf/filebeat/ conf/filebeat-es/ -name "*.yml")
- Run ELK, Suricata, and Dsiem in standalone mode:
$ docker-compose pull.

$ docker-compose up
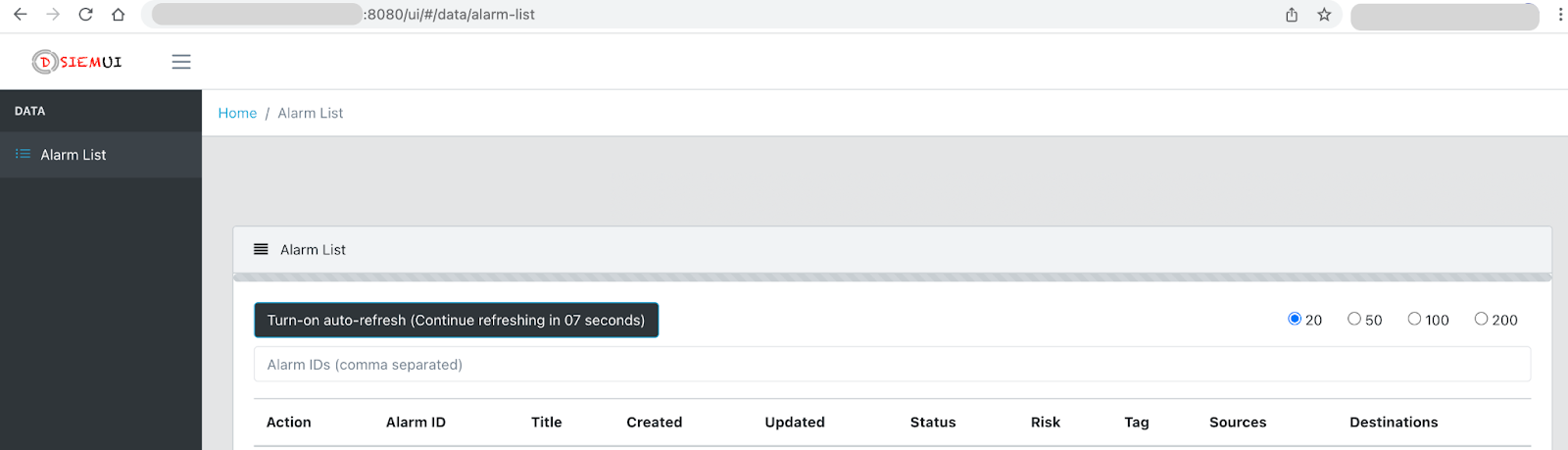
- Everything should be up and ready for testing in a few minutes. Here's things to note about the environment created by docker-compose:Dsiem web UI should be accessible from http://hostip:8080/ui
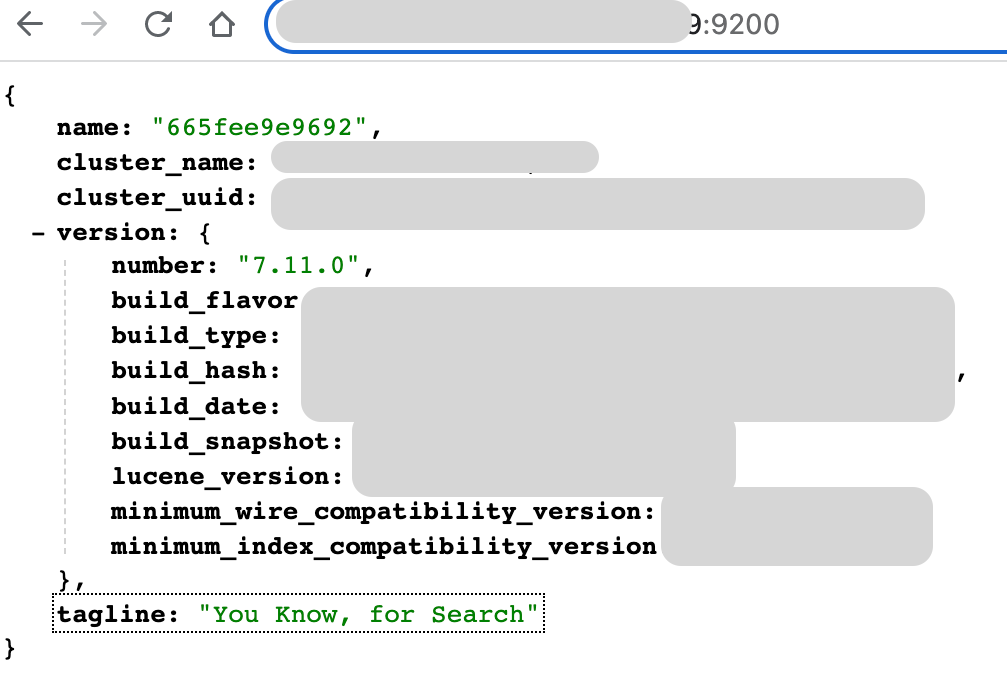
- Elasticsearch from http://hostip:9200
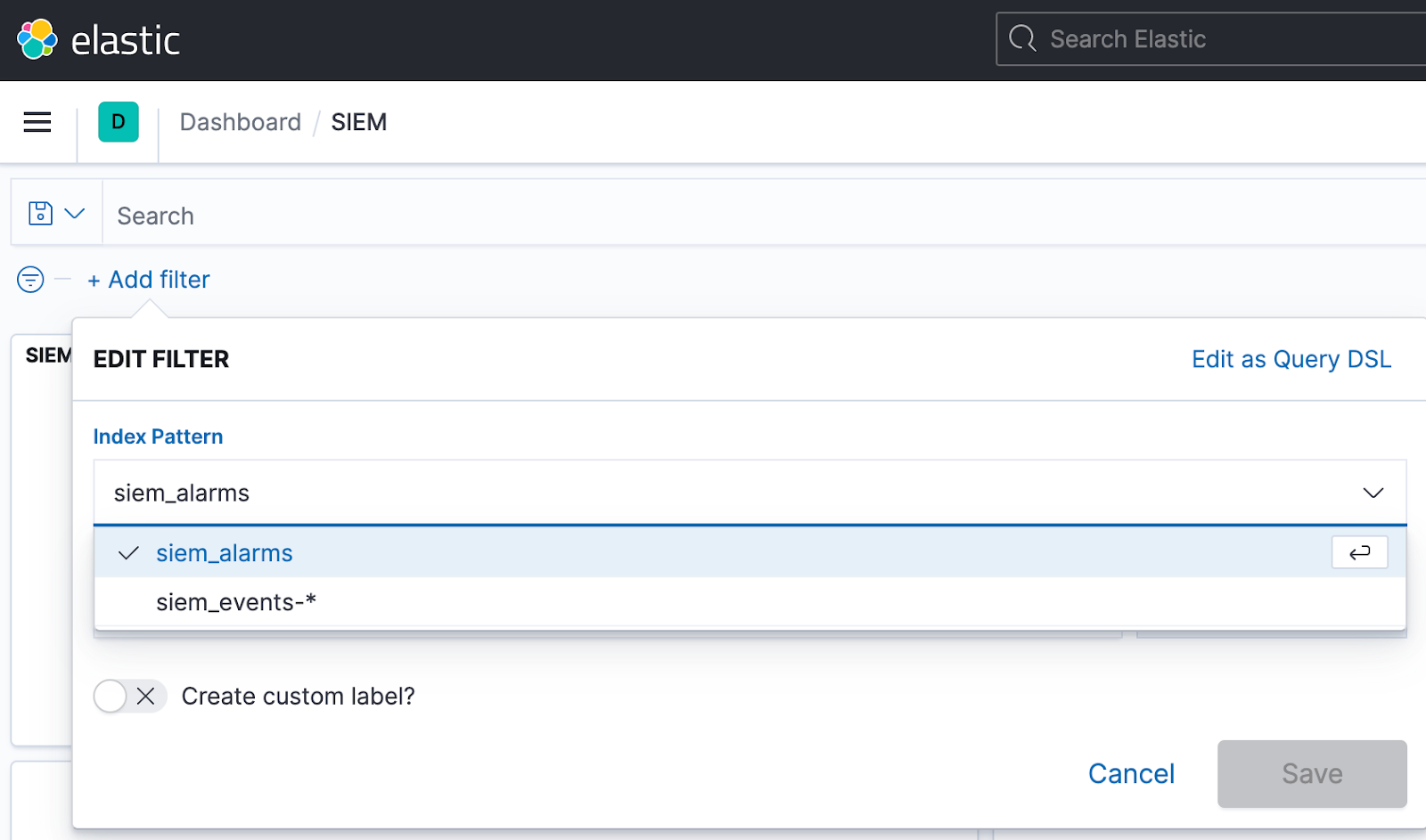
- Recorded events will be stored in Elasticsearch index pattern siem_events-*, and alarms will be in siem_alarms like below.
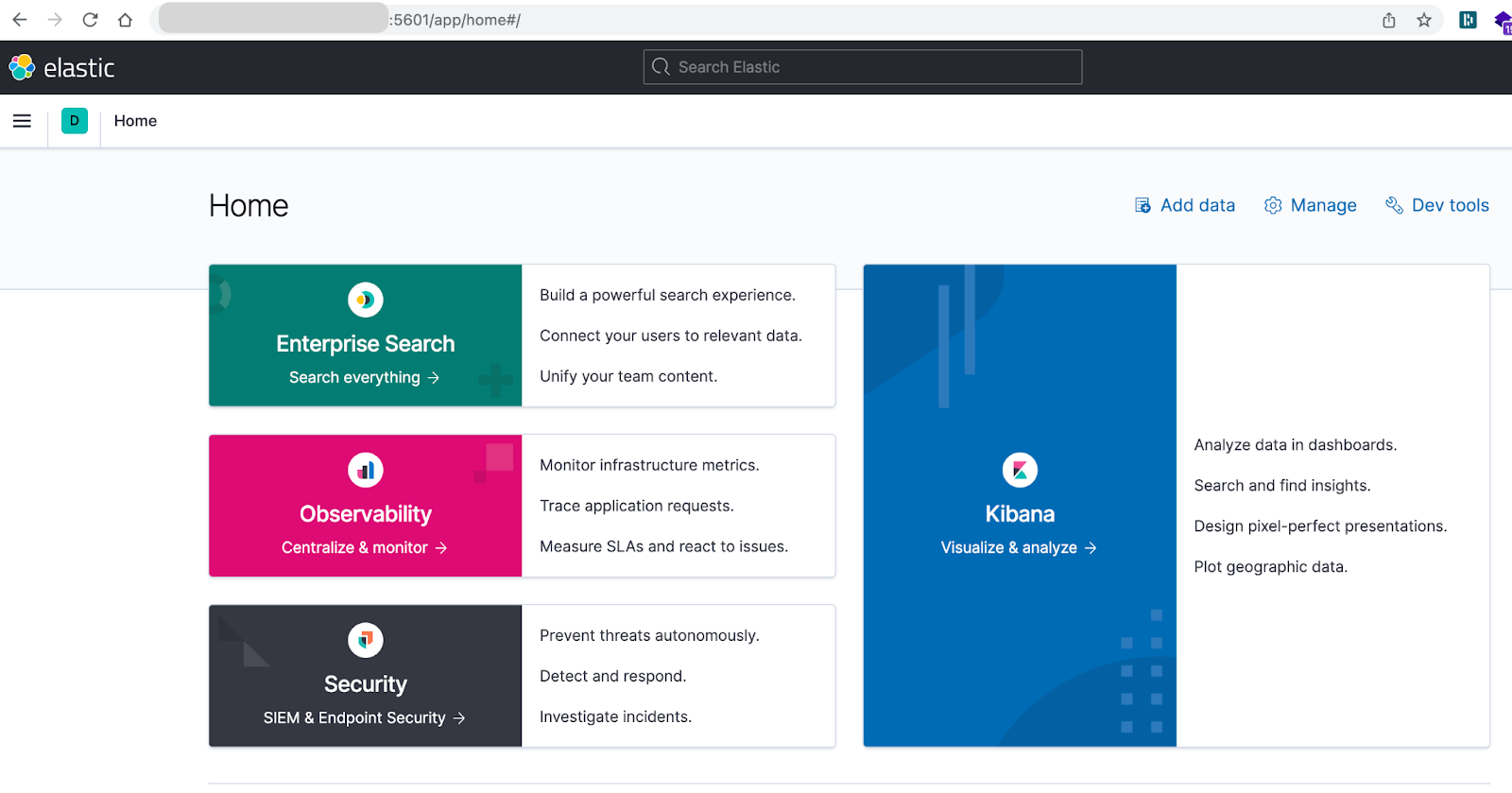
- Kibana from http://hostip:5601.
- Once Kibana is up at http://hostip:5601, we can import Dsiem dashboard and its dependencies using the following command:
$ ./scripts/kbndashboard-import.sh localhost ./deployments/kibana/dashboard-siem.json

- We can see that the SIEM dashboard is available in Kibana.
- We have completed performing basic installation of DSIEM, the next step would be setting up the log collection where we can configure via API, event log forwarding or via agent deployment for sending into the DSIEM system. Furthermore we should do the normalization to establish the correlation rules to allow us identifying the patterns and anomalies based on the ingested logs.
DSIEM Use Case Development
DSIEM Use Case and Rules Processing
Once the normalization process is completed, we should be able to develop a use case which will typically contain a set of rules to evaluate an incoming normalized event and to trigger the alarm when the rules conditions are met.
Let see this following example on how we can create a sample use case that will contain 3 stages, with the detection threshold and reliability increasing in each subsequent stage to detect Authentication attacks specifically for OTP Brute Force attempts in the applications.
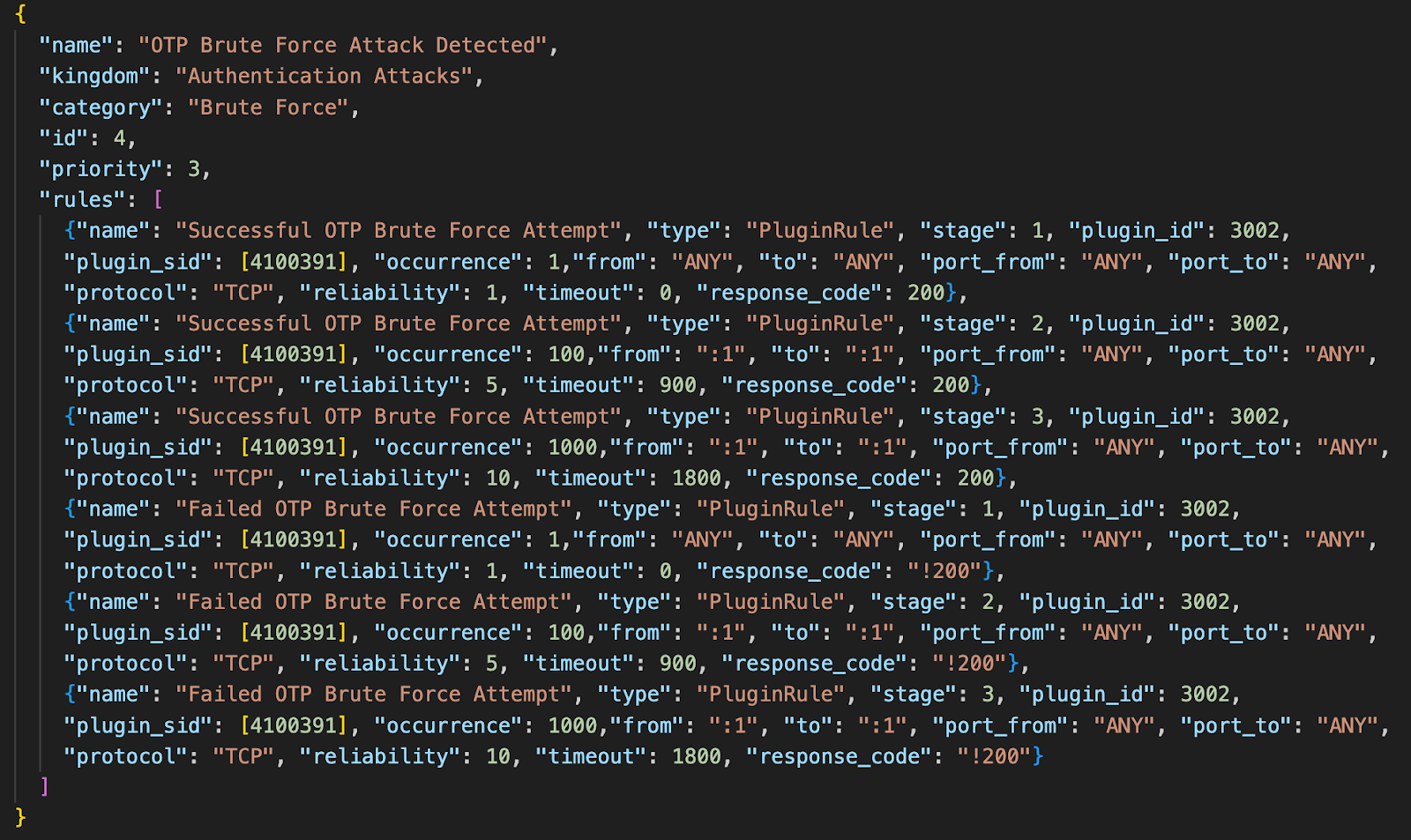
When an incoming event matches use case stage 1 rule condition, DSIEM will create a backlog object associated with the use case to track the progress of this potential alarm.
DSIEM then wait for incoming events that match the next rule (i.e. stage 2) rule condition, until one of these conditions happen:
- Count for matching events reach the stage occurrence value, in which case evaluation will continue to next rule (i.e. stage 3); or
- timeout duration (in seconds) has elapsed since the first matched event, in which case the backlog will be discarded.
The above repeats until evaluation of the last rule completed and the backlog object will be removed.
DSIEM Alarm
Dsiem calculates a risk value for backlog when the current stage's rule condition matches with the incoming events. An alarm will be triggered when the backlog risk value is ≥ 1, where the Risk value calculation is based on this following formula:
Risk = (reliability * priority * asset value)/25
Where:
- Reliability (1 to 10): the active rule reliability value. Higher reliability means higher confidence on the likelihood that the (potential) alarm is a true positive.
- Priority (1 to 5): The Use case priority value. This reflects the use case level of importance. Those with more severe impact should be given a higher priority.
- Asset Value (1 to 5): From the asset value set on assets_*.json config files. This reflects the criticality of the impacted assets. Higher value should be assigned to the more critical assets.
Given the above, we can calculate that the risk value of any backlog will vary from 0.04 when all parameters are at their minimum, to 10 when all parameters are at their maximum and alarm will only be created when the value is ≥ 1. See this following for the default thresholds in DSIEM :
- Low risk ⟶ risk value of 1 to less than 3
- Medium risk ⟶ risk value of 3 to 6
- High risk ⟶ risk value of more than 6 to 10
Sample Alarm On The OTP Brute Force Attack Use Case
Let's assume our DSIEM configured with OTP Brute Force Attack Detected use case, and our assets_*.json file that defines an asset value of 4 for 180.0.0.0/32 network which will pointing to testinghalodoc.com domain that has the login module with OTP authentications.
When Dsiem receives these following series of events:
- plugin_id: 3002, plugin_sid: 4100391,src_ip: 211.78.117.238, dst_ip: 180.0.0.1, response_code: 200 (repeated 1x)
- plugin_id: 3002, plugin_sid: 4100391,src_ip: 111.222.333.444, dst_ip: 180.1.1.1, response_code: 200 (repeated 1x)
- plugin_id: 3002, plugin_sid: 4100391,src_ip: 211.78.117.238, dst_ip: 180.0.0.1, response_code: 400 (repeated 99x)
- plugin_id: 3002, plugin_sid: 4100391,src_ip: 211.78.117.238, dst_ip: 180.0.0.1, response_code: 200 (repeated 200x)
- plugin_id: 3002, plugin_sid: 4100391,src_ip: 211.78.117.238, dst_ip: 180.0.0.1, response_code: 400 (repeated 700x)
The following processing will take place:
1st Event:
- Event matches 1st use case rule condition because:
- Event having the same value for plugin_id [3002], plugin_sid [4100391], and response_code [200] that indicate the OTP was successfully triggered.
- Event src_ip [211.78.117.238] and dst_ip [180.0.0.1] match the use case to the condition of ANY. This is because ANY will match all possible values.
- Backlog #1 is created to track this potential alarm.
- Backlog #1 has fulfilled all of its condition, including its required number of occurrence (1 event). This starts a risk calculation of risk = (reliability * priority * asset value)/25 = (1 * 3 * 4)/25 = 0.48 and there will be no alarm created.
- Backlog #1 now moves to the 2nd correlation stage and starts monitoring for incoming events that would trigger the 2nd stage rule condition.
2nd Event:
- Event does not match backlog #1 2nd rule condition because of the mismatch in the src_ip [111.222.333.444]and dst_ip [180.1.1.1]
- Since this event does match with the 1st use case rule, a new backlog #2 will be created to track it separately from backlog #1.
100th Events:
- Event having the same value for plugin_id [3002], plugin_sid [4100391], response_code [200] 1 times for success OTP, response_code [400] 99 times which was configured as [!200] in the stage 2 that indicates the OTP was not triggered successfully.
- Event matches backlog #1 2nd rule condition. since the event src_ip [211.78.117.238]and dst_ip [180.0.0.1] match the use case from value of :1. That :1 denotes a reference to the from value matched in the first rule.
- Since the event count reaching the occurrence limit (100 events), hence the risk value will be recalculated to = (5 * 3 * 4)/25 = 2.4 which will generate a Low risk alarm, and will also move backlog #1 to the 3rd correlation stage.
300th event:
- Event having the same value for plugin_id [3002], plugin_sid [4100391], response_code [200] 201 times for success OTP, response_code [400] 99 times which was configured as [!200] in the stage 2 that indicates the OTP was not triggered successfully.
- Event matches backlog #1 2nd rule condition. since the event src_ip [211.78.117.238]and dst_ip [180.0.0.1] match the use case from value of :1. That :1 denotes a reference to the from value matched in the first rule.
- Total event count still not reaching to the 3rd rule condition, hence there risk value will not be recalculated. and will also move backlog #1 to the 4th correlation stage.
1000th events:
- Event having the same value for plugin_id [3002], plugin_sid [4100391], response_code [200] 201 times for success OTP, response_code [400] 799 times which was configured as [!200] in the stage 3 that indicates the OTP was not triggered successfully.
- Event matches backlog #1 3rd rule condition. since the event src_ip [211.78.117.238]and dst_ip [180.0.0.1] match the use case from value of :1. That :1 denotes a reference to the from value matched in the first rule.
- 1000th events match backlog #1 3rd rule condition and the event count reaching the occurrence limit (1000 events) and the risk value will be recalculated to = (10 * 3 * 4)/25 = 4.8. This results in an update of the associated alarm risk label from Low to Medium.
Backlog #1 now has no more rules to process and will be immediately deleted from DSIEM memory.
For Backlog #2, it will keep waiting for an event matching to the 2nd rule for 15 minutes (900s) and will be expired and deleted if there is no match event.
Key Activities Of Security Operation Center In Halodoc
Finally after we are able to overcome the our pain points, our SOC functions have been operationalize and let's have a look closer at these following key responsibilities of the SOC function in our organization :
- Monitoring: SOC will continuously monitor Halodoc infrastructures, network traffic, and applications for signs of suspicious activity or potential security incidents.
- Threat intelligence: SOC gathers and analyzes threat intelligence from the Threat Intelligence Platform and other external sources to stay informed about the latest threats and attack techniques that are relevant to Halodoc organization.
- Vulnerability management: SOC is responsible for identifying and prioritizing vulnerabilities in Halodoc ecosystems by taking the necessary steps to assess and work hand in hand with the respective team for mitigating the vulnerabilities.
- Incident response: If a security incident is detected, SOC Team will respond quickly to contain the incident, assess the impact, and initiate the appropriate response based on the playbook of an incident response.
- Use Case Development : SOC team are responsible to develop and tuning the SIEM use case, see this following table for the sample correlated use cases that have been implemented in our organization.
Figure 9. Sample SIEM Use Cases Implementation.
- Reporting: Regular reporting is a crucial component of effective SOC operations, and the SOC team at Halodoc is responsible for providing regular reports to senior management. Specifically, we have implemented these two types of reports :
(1) Threat Intelligence : Summary of the latest threat intelligence information and trends, including information on new and emerging threats and vulnerabilities that are relevant to Halodoc organization.
(2) Incident Response : Summary of the incidents that the SOC has responded during the reporting period that includes the types, risk rating and impact of the incidents, as well as the response actions taken by the SOC team. - Continuous Improvement : Building a SOC is not a one-time solution for an organization including us, hence we are adopting a culture of continuous improvement and trying to explore further to leverage the automation and artificial intelligence technologies mainly to reduce human error and enhance our incident response capabilities. With a continuous improvement mindset, we are hoping our organization will always stay ahead of the evolving threat landscape and effectively protect our digital assets.
Conclusion
In today's digital age, cybersecurity threats are a real and persistent risk. Organizations must take cybersecurity threats seriously and consider implementing a SOC to protect their business. Whether we choose to build an internal SOC or use an external partner, it's important to have the right tools and technologies in place to monitor and analyze security events in real-time. With the right SOC in place, organizations can stay ahead of potential security threats and protect their business from the potentially devastating consequences of a security breach.
Join Us
Scalability, reliability, and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. We recently closed our Series C round and In total have raised around USD$180 million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalized for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


