

AWS EKS Disaster Recovery Strategy
In today's digital world, businesses are heavily dependent on data and technology to function efficiently. Any disruption in this system can lead to downtime, resulting in financial losses, damage to the company's reputation, and dissatisfied users. At Halodoc, we've mastered this balance by relying on AWS Elastic Kubernetes Service (EKS). In this blog post, we will delve into the robust, automated recovery strategy, designed to keep our applications up in case of an anomaly in the EKS cluster.
What makes Disaster Recovery for Amazon EKS so vital?
Halodoc relies on AWS Elastic Kubernetes Service (EKS) to manage its applications, benefiting from its reliability, scalability, and customisation. Though EKS provides a highly available environment, no system is immune to failures. Managing emergencies resulting from disruptions in EKS is of utmost importance, as outlined in the reasons below.
Disaster Recovery helps minimise downtime by providing a mechanism to failover to a secondary site or cluster in the event of a disaster, ensuring that your services remain accessible.
Maintaining a reliable service is crucial for customer trust. Demonstrating that you have a robust Disaster Recovery plan in place can boost your customers' confidence in your services.
Disaster Recovery mechanisms can help reduce the financial impact of service outages.
Disaster Recovery plans often involve regular testing and validation to ensure they work as expected. This can lead to improvements in your overall infrastructure's reliability.
In times of crisis, EKS expedites recovery, and its connection to the extensive AWS ecosystem which opens up a world of possibilities. This choice allows us to deliver dependable and adaptable services while harnessing the full potential of AWS.
Let's take a closer look at our deployment process !
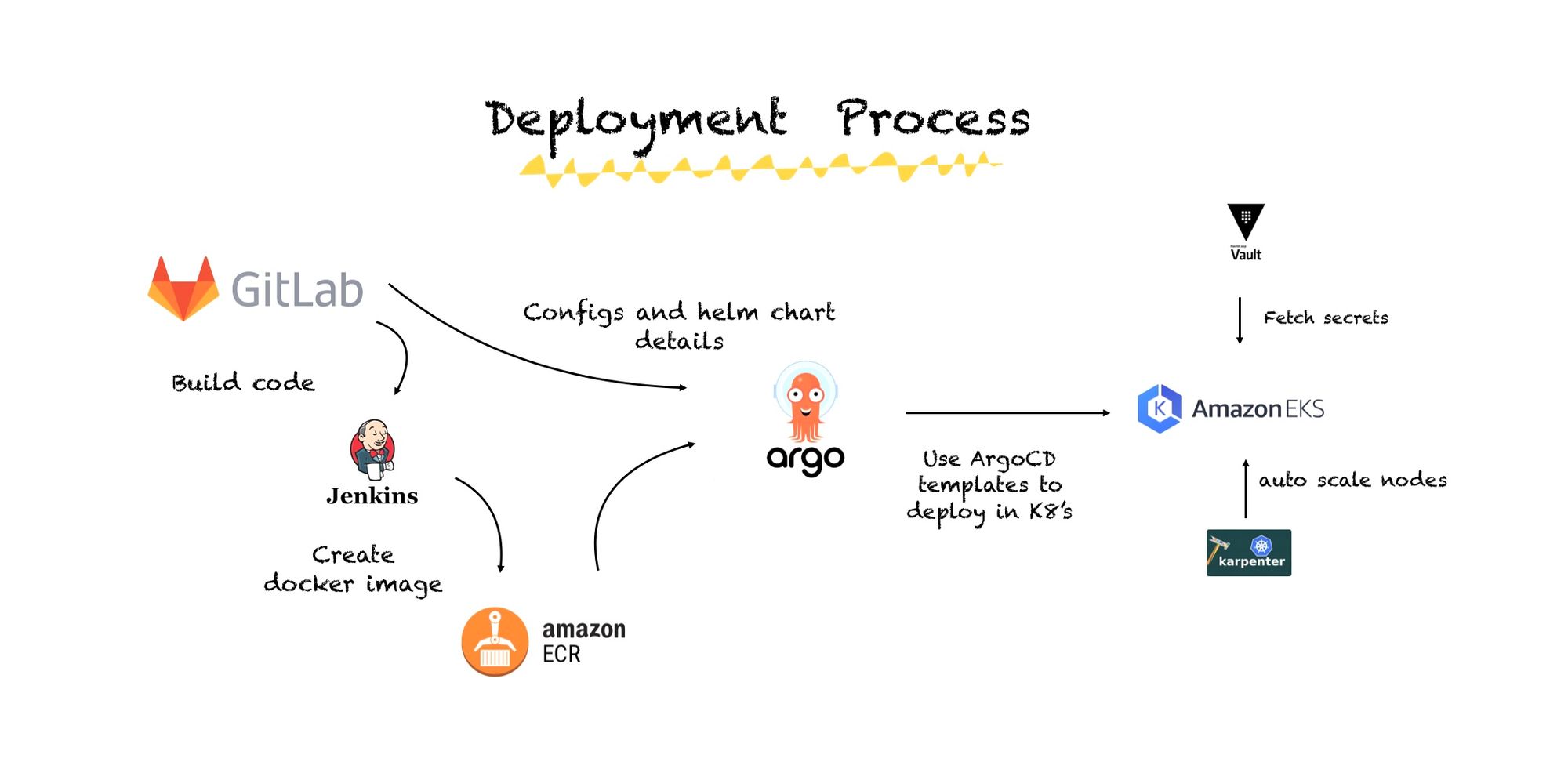
At Halodoc, we maintain our application source code and configuration files within a self-hosted GitLab repository, providing a centralised and version-controlled platform for our software assets. Our deployment process is well-orchestrated and follows a standardised approach. Initially, Jenkins, our continuous integration tool, takes the lead by automating the creation and distribution of Docker images for our services. These images are securely stored in the Amazon Elastic Container Registry (ECR), a dependable container registry provided by AWS as private images.
Once the Docker images are housed in ECR, we leverage ArgoCD, a GitOps-based continuous delivery solution, to handle the deployment process. ArgoCD ensures that our applications are deployed consistently and securely by synchronising the desired state defined in our Git repository with the actual state in our Kubernetes clusters.
Security and secrets management are of paramount importance, and to address this concern, we utilise HashiCorp Vault. Vault is our go-to tool for fetching and managing sensitive information, such as credentials and API keys, providing an additional layer of security for our deployments.
To further optimise and fine-tune our infrastructure, we also make use of specialised tools like Karpenter and Istio. Karpenter aids in managing our Kubernetes cluster autoscaling, ensuring efficient resource allocation, while Istio enhances network security and control in our tech stack. In this way, we maintain the integrity, security, and reliability of our applications throughout their lifecycle.
Action plan during an EKS Disaster
Our EKS cluster is strategically deployed across multiple Availability Zones (AZs), ensuring that it can automatically handle AZ-specific failures. In the case of an EKS disaster resulting from factors like regional outages, deliberate or accidental damage, such as EKS corruption or a malware attack, Halodoc follows a systematic approach to recover the system efficiently in MTTR of 60 min:
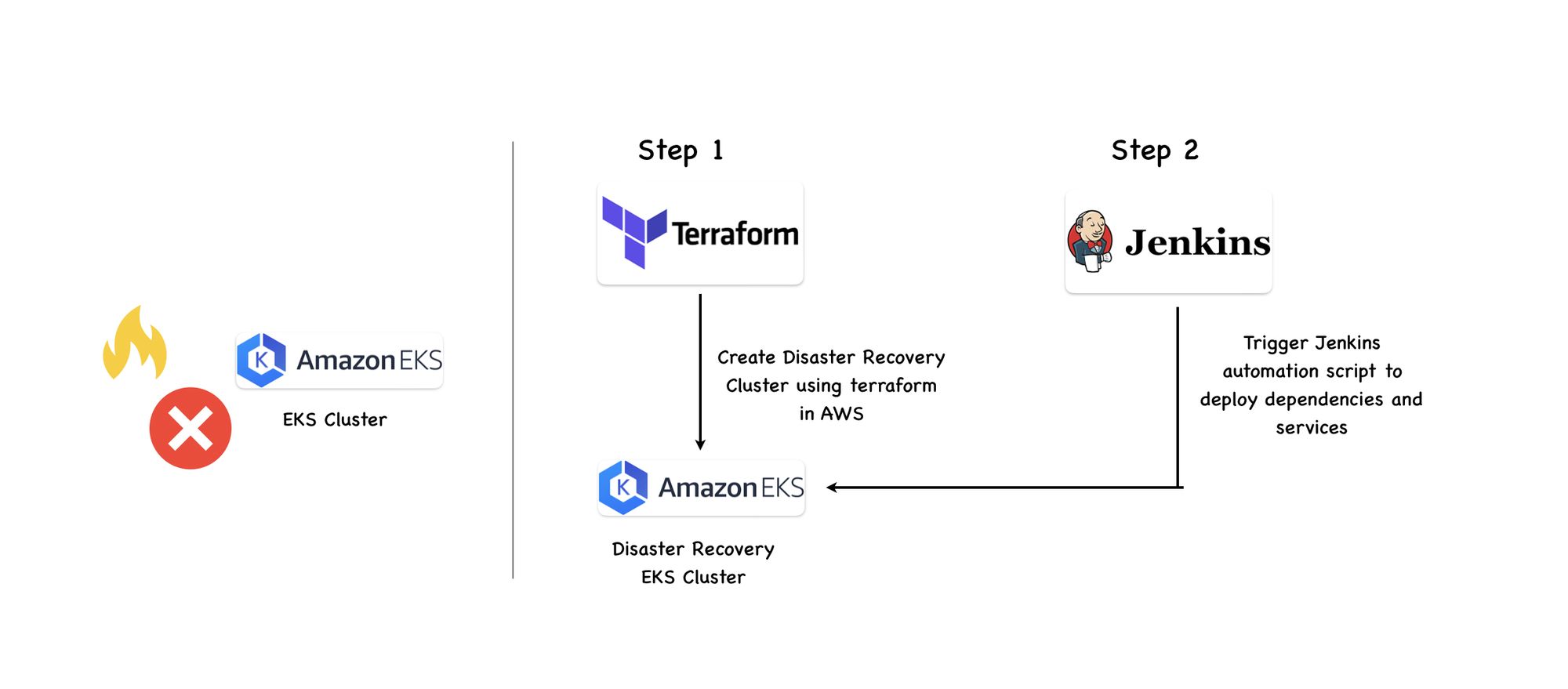
- Creation of a New EKS Cluster (15-20 minutes): Halodoc utilies a modular approach in Terraform for the automated creation of new Amazon Elastic Kubernetes Service (EKS) clusters. This approach encompasses the generation of all necessary dependent resources, such as Identity and Access Management (IAM) roles, security groups, node groups, and configuration maps.
- Run the Automation Script (10 minutes): Execute the automation script to configure and prepare the DR cluster.
- Review and Merge MR for ArgoCD Templates (5-10 minutes): In our workflow, we incorporate a process that involves reviewing and merging the Merge Request (MR) generated by an automation script for ArgoCD templates. This task typically takes between 5 to 10 minutes for a review, is crucial as it applies to all 150 services we manage.
- Update Load Balancer Endpoints (10-15 minutes): After successfully launching our services, a critical next step involves updating the new endpoints for load balancers across various AWS services. This process, which is manual, is essential due to the dynamic nature of Load Balancer endpoints. This update process encompasses several AWS services, including CloudFront, Route 53, and API gateways, underscoring the importance of meticulous attention to detail in our operational run-book.
In the following sections, we will delve into each of these aspects, providing practical guidance to help you fortify your EKS clusters against potential disasters.
DR EKS Creation
We have adopted Terraform as our go-to tool for managing infrastructure in an automated and efficient manner. Specifically, when it comes to setting up Amazon Elastic Kubernetes Service (EKS) clusters, we employ a modular approach, breaking down the configuration into manageable, reusable components.
The beauty of Infrastructure as Code (IaC) is that it allows us to define our infrastructure, including the EKS clusters, in code form. This means we can specify the exact configuration, resource requirements, and any associated dependencies in a human-readable format.
With this approach, the process of creating an EKS cluster becomes highly streamlined. When we need to spin up a new cluster for disaster recovery, we simply apply our Terraform configuration in the desired AWS region, and the tool takes care of the rest. This not only ensures that the cluster is set up correctly with all the necessary resources but also significantly reduces the time required.
Automation Script Workflow
Let's closely analyse each aspect of the automation workflow and determine the recovery processes.
- Login to Disaster Recovery (DR) Cluster: First we get the configurations for the new DR EKS cluster using AWS CLI and store it in the form of variables.
- Set Up AWS Load Balancer Controller: Ensure smooth traffic management by installing the AWS Load Balancer Controller to create load balancers as required.
- Integrate the Cluster with ArgoCD: Simplify deployment and management by adding the cluster to ArgoCD using the ArgoCD CLI.
- Implement Karpenter and Node Provisioning: Deploy Karpenter via ArgoCD to optimise node allocation for applications by deploying provisioners and node templates in an automated fashion.
- Integrate Istio: Install Istio and apply the ingress templates to create new endpoints to access the services.
- Install Vault Ingestor in the Disaster Recovery (DR) Cluster: Secure the DR cluster by installing the Vault Ingestor to facilitate secure access to secrets and sensitive information.
- Update Vault Paths for Application Roles: Ensure that all roles necessary for applications to access the DR cluster are correctly configured and updated within Vault.
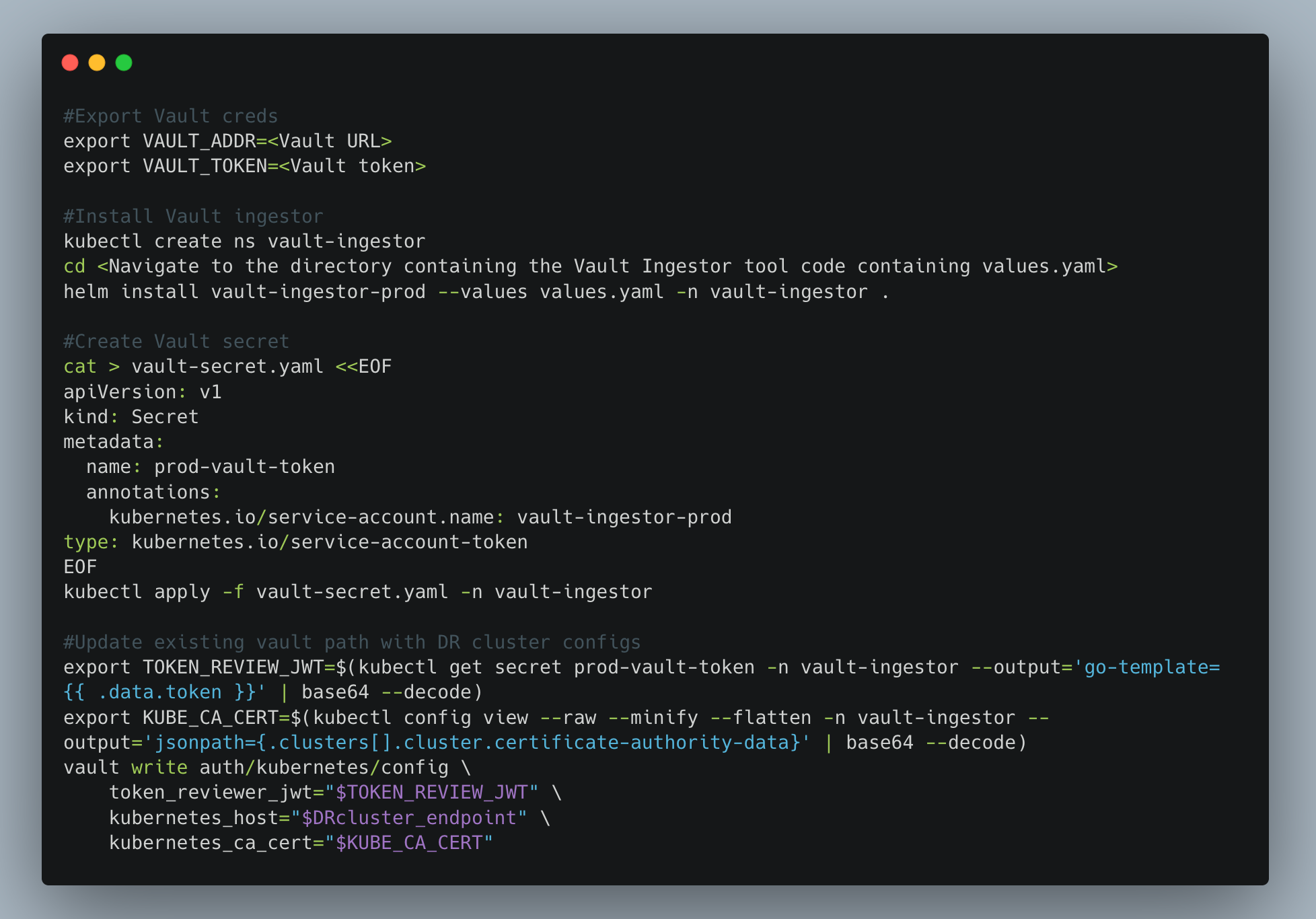
- Update Vault Paths for Application Roles: Ensure that all roles necessary for applications to access the DR cluster are correctly configured and updated within Vault.
- Create Namespaces and Add New Relic Key: Set up namespaces within the cluster and integrate the New Relic key for monitoring and performance tracking in all these namespaces.
- Create ArgoCD Templates: ArgoCD templates are dynamically generated, incorporating the most recent cluster configurations, and utilizing previously deployed templates as a foundation. The updated templates include the latest image configurations, GitLab URLs for accessing configuration files, and comprehensive Helm chart details.
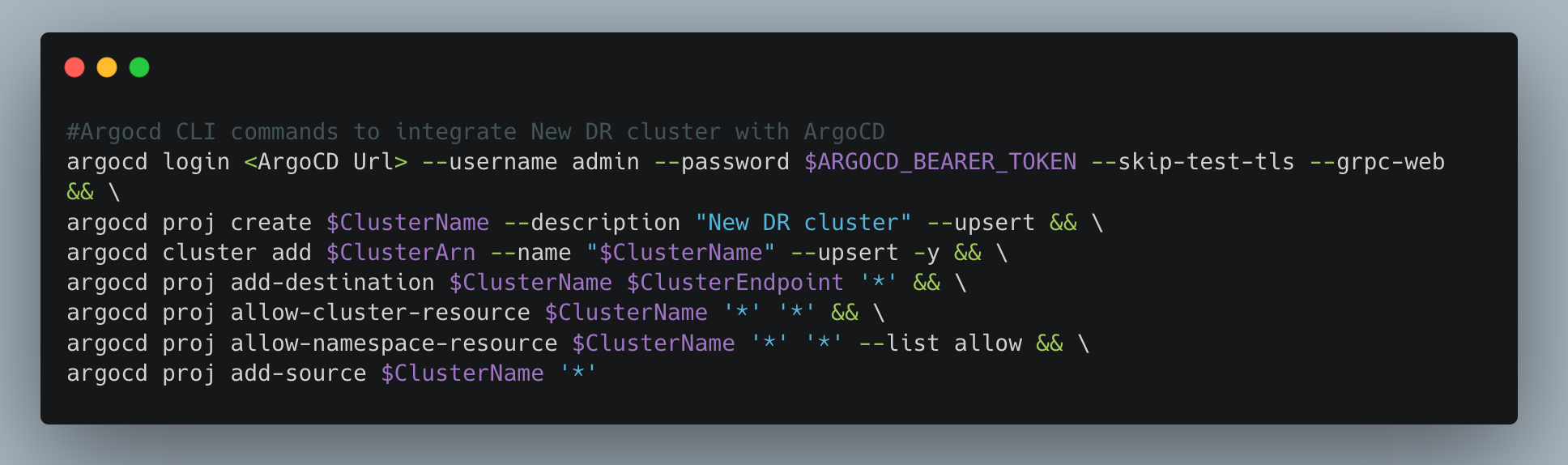
- Deploy Services with one click: Automate the deployment process by merging the Merge Request (MR) generated by Jenkins, which contains the ArgoCD templates for deploying the services.
- This automation script is used in the form of a Jenkins Job that can be accessed by the administrators. Each step outputs logs and has approval checks for smooth and meaningful flow.
Deploying Services using ArgoCD
ArgoCD operates by linking your application configurations, including details like container images, cluster names, and resource requirements, with a Git repository. For automated deployments, we utilise the pre-existing ArgoCD templates for our services. When implementing disaster recovery, the primary modification is updating the name of the new Amazon Elastic Kubernetes Service (EKS) cluster and initiating a new GitLab merge request which upon merging deploys all the services in DR cluster. Post-merging, it is essential to closely monitor the deployment progress of these services to ensure smooth operations and effective implementation of changes.
This approach adheres to the principle of defining the desired state of your applications declaratively. ArgoCD continuously monitors your Git repository for changes, and when it detects modifications, it automatically synchronises your EKS cluster to align with the updated configuration. This automated process streamlines application updates, eliminating the need for manual interventions.
Update Load Balancer Endpoints
Following application deployment, dynamic load balancers are generated via Helm charts, serving as the external entry point for application access. Internal communication occurs between services using svc endpoints. To streamline updates across AWS resources, it is important to ensure synchronisation of the newly created load balancers with AWS components everywhere applicable such Route 53 for DNS management, CloudFront for content delivery, and API Gateway for efficient API handling which varies based on the use-case.
Advantages of this Approach
- Cost-Effective Approach: This approach is highly cost-effective because we create only essential resources on the fly during disaster scenarios. This includes the dynamic provisioning of the IAM role for Karpenter and the IAM role and policies for the AWS load balancer controller as required.
- Independence from Third-Party Tools: Our disaster recovery strategy operates self-sufficiently, without reliance on external third-party solutions, reducing complexity and dependencies.
- Elimination of Backup and Version Maintenance: We circumvent the need for creating backups and managing multiple versions of data, simplifying the maintenance process and reducing administrative overhead.
- Optimization of Existing Resources: Since we have planned for EKS recovery assuming all other utilities are up and running, we prioritise the utilization of existing resources whenever possible, ensuring efficient resource allocation and cost savings.
- Rapid Response: Our disaster recovery mechanism is designed for swift and efficient response which takes less than 60 min to start functioning from scratch.
Conclusion:
As we wrap up our story on Halodoc's disaster recovery, it's clear that resilience and scalability are embedded in our tech DNA. The primary goal of Disaster Recovery is to minimise downtime, data loss, and financial impact, allowing businesses to recover and resume normal operations swiftly.
Performing regular drills on DR either quarterly or semiannually will help employees to be familiar with the tools and resources available for handling emergencies. Let's join forces to create a digital world that's strong and scalable, even in the face of challenges.
Join us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. We recently closed our Series D round and in total have raised around USD$100+ million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalized for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


