

Bulk Database Archival
Context
As previously described in one of our blogs (here), at Halodoc we use our in-house calendar management service called Kuta for managing schedules of various entities on our platform. Kuta uses MySQL as the primary data store for storing all the event related information. Kuta provides functionality to create events with a recurrence rule; this capability allows the operational team to create schedules for future time slots as well(up to 1 year). Coupled with the ever increasing inventory of Halodoc, we noticed that the size of Kuta MySQL database was increasing dramatically, with some of the tables crossing more than 300 million record count.
When we analysed the actual data stored in the database, we noticed that more than 60% of the records were for the past time slots. After having discussed with the product team, we realised that we actually don’t need to store the event information for the past timeslots. We decided to take a different approach for the way we solved the recurring events problem in Kuta. As part of the change in design, we wanted to first perform bulk archival of all the past event information in one go. This would drastically reduce the total database size and improve the performance. It also provides an opportunity to scale down the AWS RDS instance type, thereby helping us with cost reduction as well.
Here we will be discussing the approach that we took for bulk archival of Kuta RDS with minimal downtime leveraging AWS Data Migration Service(DMS) Managed Service.
Constraints
As mentioned above, Kuta is one of the most critical services for Halodoc backend. Due to this we had several constraints that we had to consider while planning this bulk archival.
- Minimal downtime - this the most important constraint, we can’t have more than a few minutes of downtime considering the Kuta service has an impact on all the product lines of Halodoc.
- We can’t perform bulk delete operation on the production RDS, as this would cause huge replication lag for the replica and thereby cause inconsistency for the production application.
Approach
Considering all the constraints mentioned above, we came up with the following steps for solving the problem. Brief overview of the approach is represented in the below diagram:
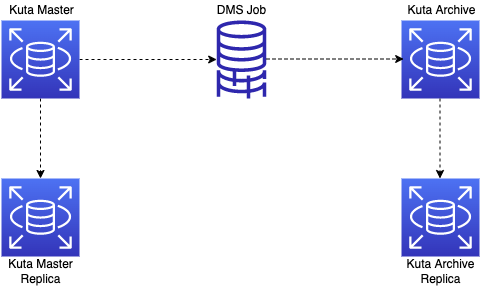
To briefly summarise the approach we have taken: We created a new RDS instance(Archive) from the latest snapshot of the production instance(Master). We then performed all our deletion operations in the Archive instance. Once the deletion of the records is complete, we then would use the DMS task to synchronise the latest records between Master and Archive instances. Once the synchronisation is complete, we can then switch the application traffic from Master instance to Archive instance.
Detailed steps for the approach are mentioned below:
1. Enable Binary log in Kuta Master
- We set the Binary Log retention period to 7 days (maximum value possible in RDS).
- Reason for this step would be explained in the Step 4 where we will be using AWS DMS to transfer the records from master to archive instance.
2. Create ‘Kuta Archive' RDS instance
- We create a new RDS instance from the latest snapshot of Kuta Master.
- This RDS instance is created with similar or higher configuration than our Master RDS instance.
3. Perform deletion activity in ‘Kuta Archive’ instance
- We wanted to delete the data from three tables: events, calendar_events, event_attributes.
- events table is referenced through foreign key in calendar_events and event_attributes tables.
- Our deletion criteria is based on events table - which has the start and end times for each time slot.
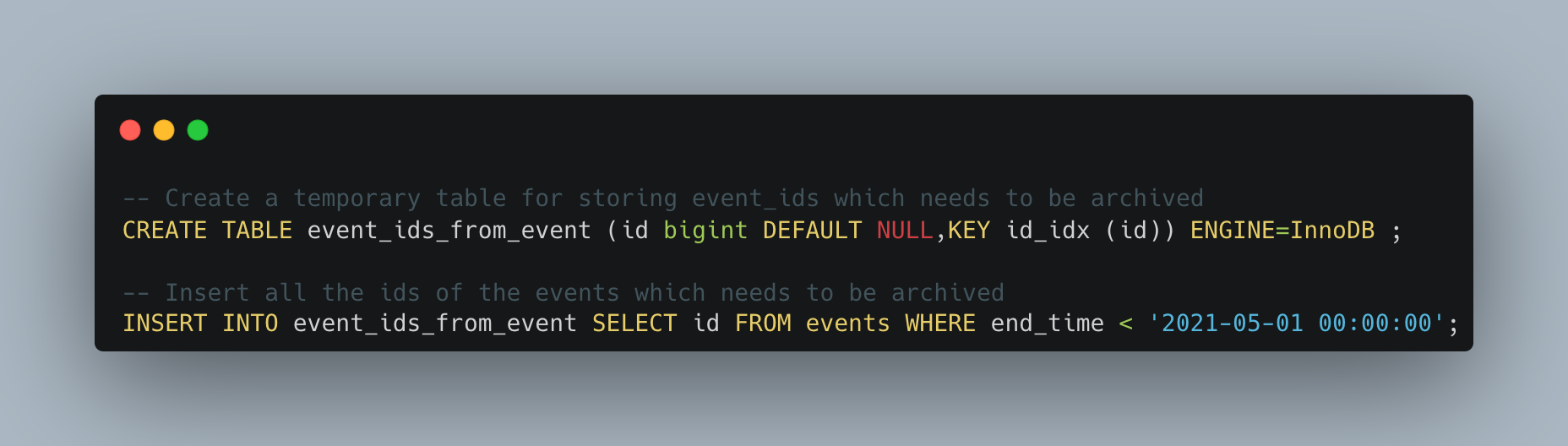
- To avoid the foreign key join to events table while deleting calendar_events and event_attributes, we created a temporary table and stored all the event_ids which needs to be deleted.
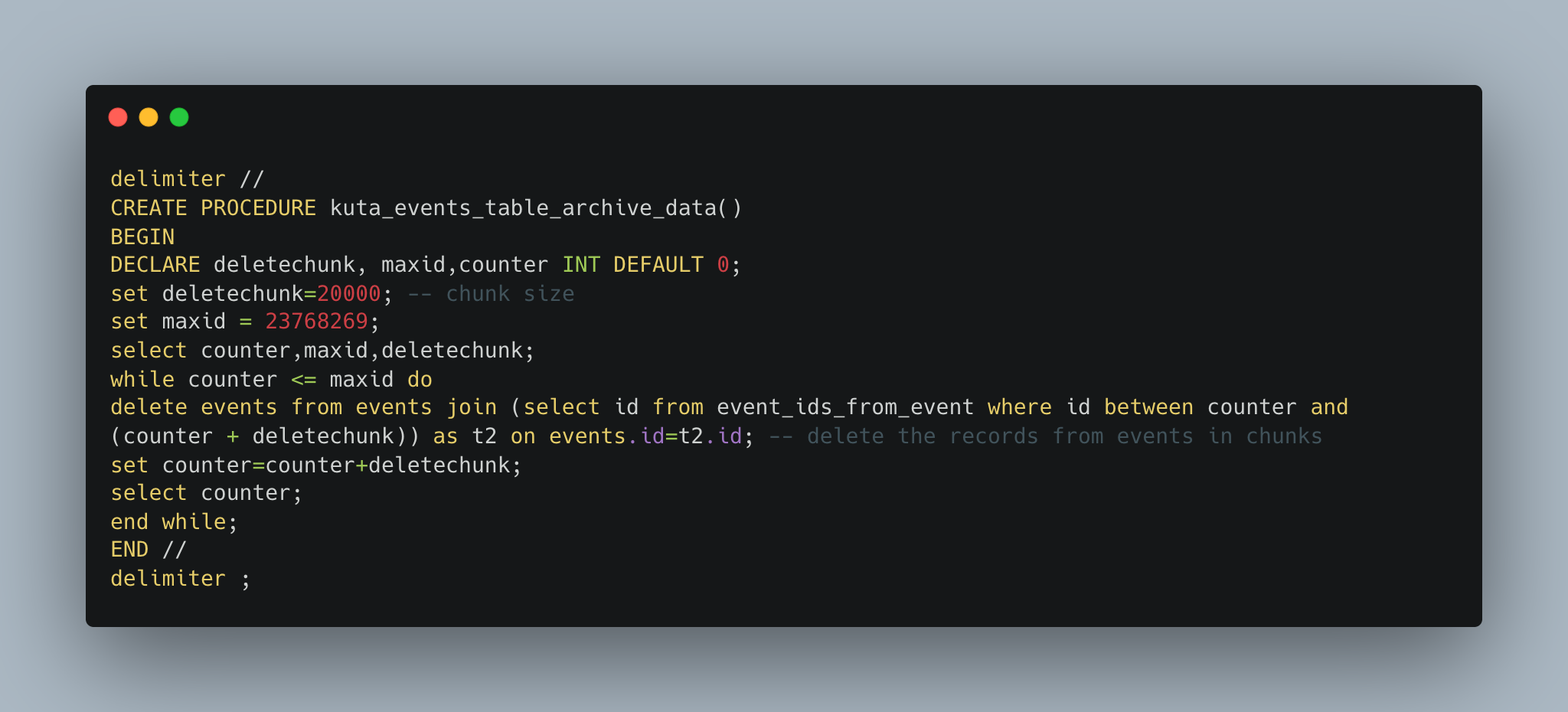
- We declared three MySQL procedures, which would delete the records from each of the tables in chunks(of 20k). Example of one procedure is shown below:
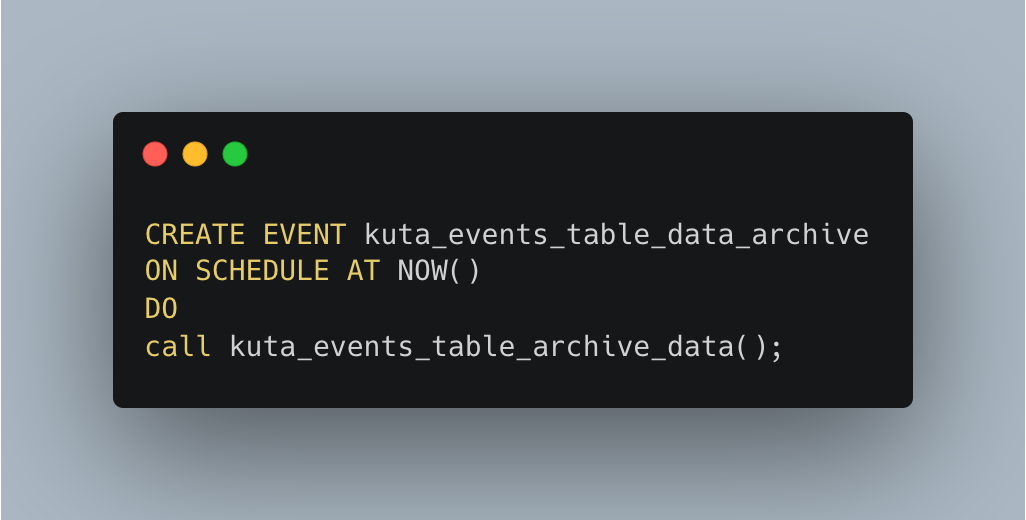
- Trigger the MySQL procedure through events, which would cause the procedures to run in background.
- We then have to wait till all the three procedures complete executing.
4. Data synchronisation between the Master and Archive RDS
- AWS DMS helps in migrating databases quickly and securely with no downtime.
- Create Replication instance: Make sure to select appropriate instance type and VPC.
- Create source and target endpoints that have connection information about your data stores. In our case this would be creating a source endpoint with Kuta Master RDS instance and target endpoint with Kuta Archive RDS instance.
- While creating endpoints make sure that the MySQL user provided should have privileges of SELECT, REPLICATION SLAVE, REPLICATION CLIENT.
- Test both endpoint connections with VPC and replication server created earlier, run test once to check if connection is successful.
- Create migration tasks to migrate data between the source and target endpoints.
- Under Task configuration provide information Task identifier, Replication instance, Source and Target database endpoint.
- Migration type: Ongoing changes.
- Enable custom CDC start position: Select the UTC timestamp of the latest record present in the Archive instance with some buffer time of 20 mins.
- Target table preparation mode: Nothing.
- Include LOB columns in replication: Limited LOB.
- Table mappings: ADD selection rules provide the conditions as required and create task.
- Start the replication.
- Validate if the replication is happening as per expectation - Validating the timezone of the records.
5. Traffic Switch from Kuta Master to Kuta Archive RDS Instance
- Make sure DMS task is completed and all the latest transactions are present in the Archive instance.
- Down the application before switching the traffic, as there can be ongoing replication from the DMS task before the application is restarted.
- Validate if all the data is synced between the Master and Archive instance.
- Stop the DMS task.
- Switch the database endpoint for kuta application from Master instance to Archive instance.
6. Stop/Delete older Kuta RDS instance
- Here we can take a final snapshot of the the Master RDS instance, before decommissioning the RDS.
Issues and Learnings
- Write IOPS Bottleneck: We had configured GP2 Storage type for our Archive Instance, AWS provides fixed Write IOPS(3x Storage size) performance along with additional burst headroom. When we were performing deletion operations, the burst IOPS provided for the RDS got exhausted quickly and post that deletion queries were running very slowly as the fixed Write IOPS wasn’t enough for our workload. As a solution, we temporarily switched the RDS storage type from GP2 to Provisioned IOPS with sufficient IOPS preconfigured, this helped us perform deletions faster.
- MySQL Table Fragmentation: After the deletion activity was completed, we didn’t see much improvement in the storage space used by the RDS instance. After much researching, we learned that due to table fragmentation in MySQL the storage space might not be released back to the OS after the deletion. As a solution, we ran OPTIMISE TABLE command for all 3 tables for which we performed deletion, then we saw significant reduction in storage space utilisation.
Summary
We were able to perform bulk archival of data for one of the most critical services with minimal downtime. Here are some of the metrics:
Before Deletion:
- DB Size: 330~ GB
- events rows: 144~ million rows
- event_attributes rows: 386~ million rows
- event_attributes rows: 143~ million rows
After Deletion:
- DB Size: 90~ GB
- events rows: 57~ million rows
- event_attributes rows: 151~ million rows
- event_attributes rows: 62~ million rows
As we can see from the metrics, we have deleted 100s of millions of records. This has significantly improved the storage space and also improved the performance of the queries by ~20%. Now that we are done with bulk archival of Kuta RDS, we are planning to have an automated archival process driven through code.
Join us
Scalability, reliability, and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 4000+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek and many more. We recently closed our Series C round and In total have raised around USD$180 million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


