

Automated Data Governance Strategies: Securing PII in Our Data Warehouse
In Halodoc, an essential component of providing data that guides our decision-making is our data platform. We consciously use Amazon Redshift as our main data warehouse solution, using it to store reporting tables that follow the dimension-fact modeling methodology. These tables serve as the foundation for insightful analytics and decision-making.
In this blog, we have documented the implementation of an automated data masking technology on our data warehouse. It includes identification of Personal Identifiable Information (PII) across the data warehouse, and masking them according to our set data governance rules. Through this implementation, we are able to effectively safeguard PII data within the data warehouse, and achieve a comprehensive data governance solution.
Dynamic Data Masking
Dynamic Data masking allows organizations to control access to sensitive data at the query level, dynamically masking or obfuscating certain columns based on user permissions. Based on the role being used by the querier, dynamically the data will get masked when the results are being shown.
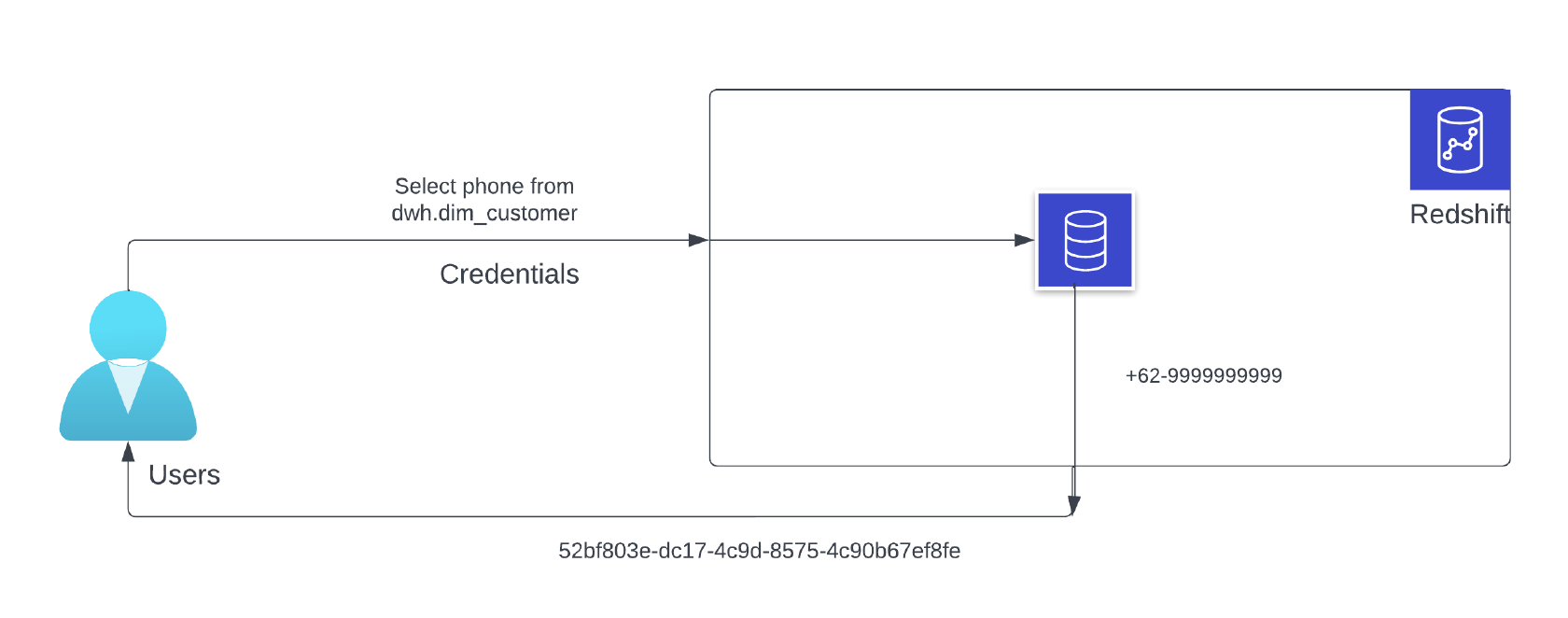
Example:- If we want to mask the data to the role analytics in Redshift, then all the users who are attached to this role including the dashboards and visualization tools will get the hashed (masked) data when queried.
Steps for creating a masking policy
- Define the functions for masking_expressions according to the requirements and governance rules in the Redshift environment.
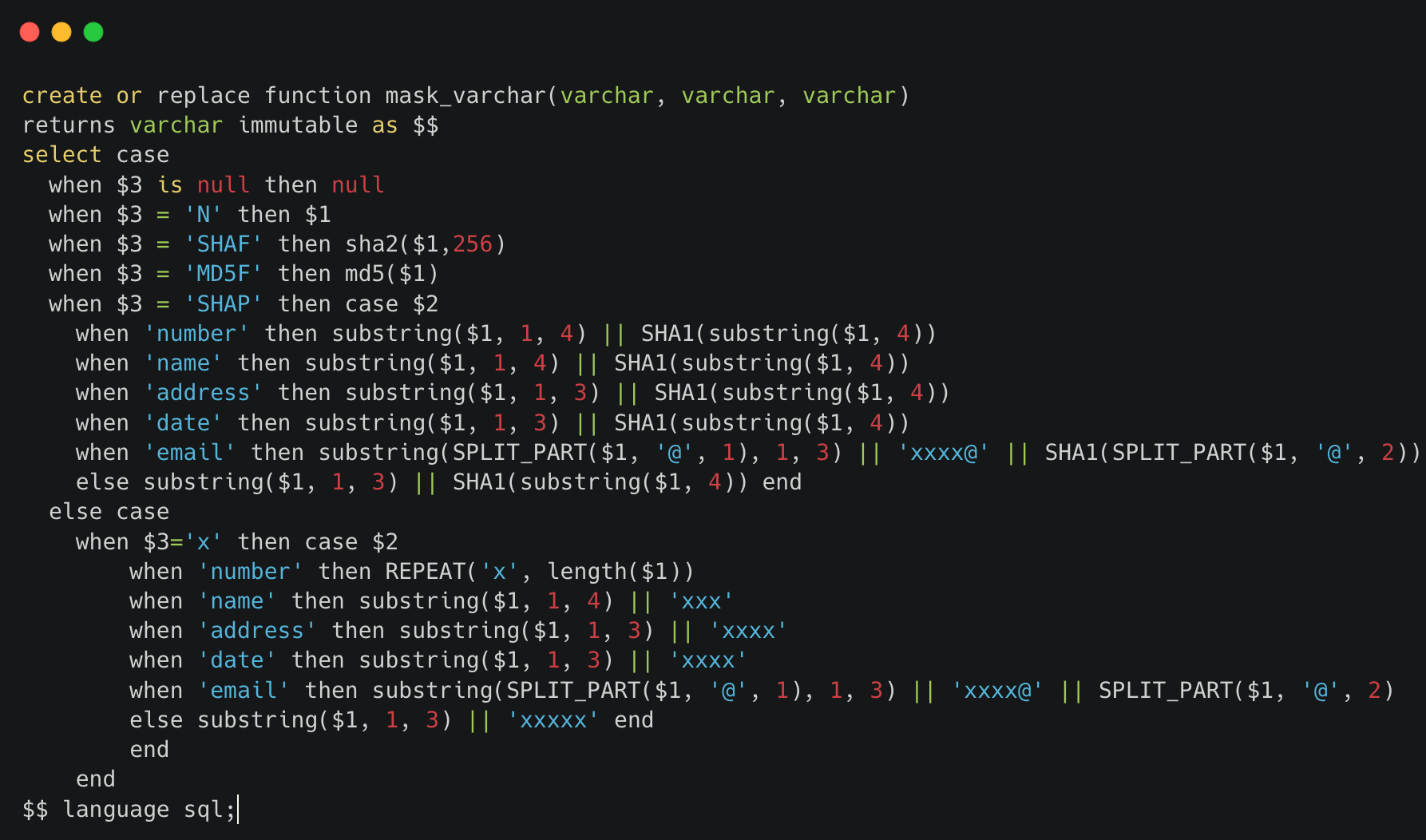
2. Create a masking policy for a particular data type using masking_expression in the Redshift environment.

3. Follow the same steps for different data types like numeric, varchar, etc.
Next step is to Attach Masking Policy, which attaches the policy to the specified column of a specified table.

Below query can be used to find the data type of each column and assigning the policy according to it can be handled in the script with the help of the following query.

This is the manual procedure to be followed for each column in order to mask them in the redshift. Whenever new tables and columns are added frequently to the warehouse, monitoring them and manually identifying the PII data would be a tedious task. Therefore, for the purpose of identifying new PII data at regular intervals, the PIICatcher tool has been selected to facilitate this automation.
PIICatcher
PIICatcher is a Python library for scanning PII and PHI information. It finds PII data in the databases and file systems and tracks critical data. It supports Redshift, Athena, MySQL DB, etc. The tool was chosen as it provides the following features:
- Full-load and incremental-load: - PIICatcher stores the metadata of every scan in the PostgreSQL table which is referred in the subsequent scans. During incremental load, it identifies PII in new tables or additional columns created in existing tables since the last run. In full load, it scans all the tables in the source for PII.
- Column name based scan and data based scan: - This directs PIICatcher to identify PII based on either the sample size of data or solely on the column name. In our case, we opted for column name-based scanning, allowing for more refined output filtering.
- Include schema/tables filter: - The "include schema" regex filter enables the selection of specific schemas in the data warehouse for PIICatcher to scan for PII columns.
Automation flow
The automation gets triggered by the scheduled job in the Jenkins job which takes the scan method as the parameter which has the default value of incremental-load.
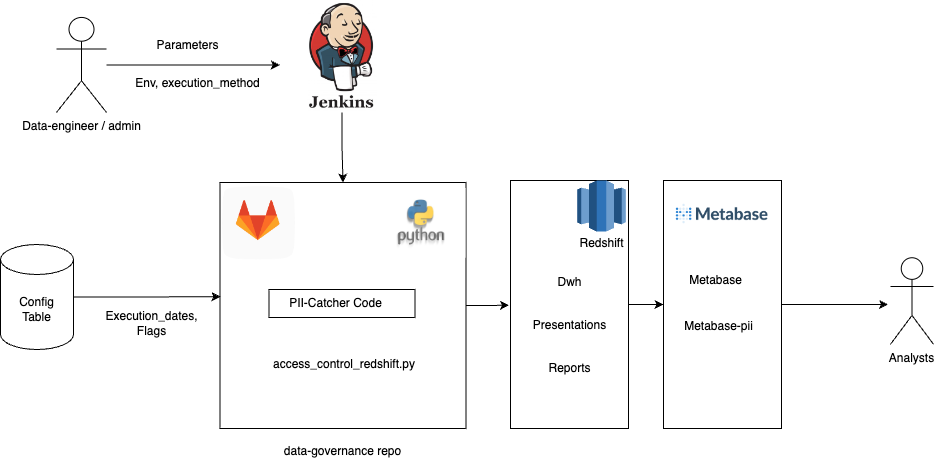
This automation has 2 categories -
- Dry-Run:- In this method, the Redshift is added as the source for scanning to the PIICatcher. Its output is filtered again with the list of blacklisted_keywords to get better accuracy and to avoid non PII columns from getting masked inadvertently. It will be shared to Slack in the JSON format after every scheduled Dry-Run, for the Security team to perform cross-verification on the identified PII data. The same JSON file will be stored in the AWS S3 bucket for accessing it in the Mask-Run.
- Mask-Run:- This method runs after 3 days of Dry-Run. In this method, the JSON file which is the output of PIICatcher stored in S3 will be accessed and the same list of columns will be considered for Dynamic Data Masking.
How do we determine which scheduled run is Dry-Run or Mask-Run?
Config_table: - Using the Configuration table we store the dates of dry_run_execution_date and mask_run_execution_date and compare every scheduled run date with it. We can also store the parameters to PIICatcher like schema_list, role for masking, and a few flags to control the pipeline in the config_table which enables easy maintenance.

Execution Process
- When Jenkins triggers this pipeline, configs are fetched from config_table, and the execution date is checked if the current run is Dry-Run or Mask-Run.
- In the Dry-Run and incremental-load scan method, AWS Redshift is selected as a source. All the tables of the schema we included will be scanned thoroughly and checked for PII columns with the set of RegEx classified into categories of PII like email, zip code, etc.
- If there is a False Positive, RegEx can be handled according to our needs.
- The list of columns is sent to Slack for verification at the end of Dry-Run and stored in S3 in JSON format for the upcoming Mask-Run.
- In the maskRun, the result is accessed and iteratively all the columns will be attached with the masking policy created in Redshift.
The masking policy is attached to a certain role in Redshift, through which the dashboard users will fetch the data.
Example: If the masking policy is attached to the analytics role, a Dashboard user belonging to the same role would have the data dynamically masked.
PS:- In order to get the access to PII data in the dashboard, create a new user in Redshift and attach it to the different role such that, access to PII data is restricted to authorized individuals within the organization.
Overall, through this automation we are able to achieve identification of PII data in the new tables and columns which get created day by day and attach the masking policy to them without human intervention. Given that the process of manually executing the attachment of the masking policy must be carried out column by column, this automation is notably saving time and mitigating repetitive tasks.
Summary
In this blog, we have covered the way to implement the automated pipeline for masking the PII data in the data warehouse. This includes the integration of the PIICatcher tool to identify PII data residing within the warehouse and creation and attaching the masking policies to the identified PII columns. By this, we are able to dynamically mask the data to the restricted individuals in the organization. In this way, we have made sure that all the personal data is safeguarded in the data warehouse which is leading to achieving comprehensive data governance.
References
Join us
Scalability, reliability, and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek and many more. We recently closed our Series C round and In total have raised around USD$180 million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalized for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


