

Cost Optimization Strategies for scalable Data Lakehouse
At Halodoc, we use Data Lakehouse architecture as an important part of our scalable Data Platform which helps Halodoc to be a data-driven organization. In our previous blog, we had wrote about the Data Lakehouse architecture followed at Halodoc.
In this blog, we will be discussing about the cost related challenges we had faced when our Data Lakehouse scaled and how we have overcome such costs by optimizing the process.
Data Lakehouse platform mainly comprises of below components:
- Cloud Storage – e.g. AWS S3
- Open Table Format – e.g. Apache Hudi
- Processing Engine / Frameworks – e.g. EMR (Elastic MapReduce) / Apache Spark
Lets discuss the pitfalls to be aware of in these components, which can cause higher costs if not rightly configured and how at Halodoc we analyzed and configured these components to have a cost effective Data Lakehouse when scaled.
Efficient Data Lifecycle Management
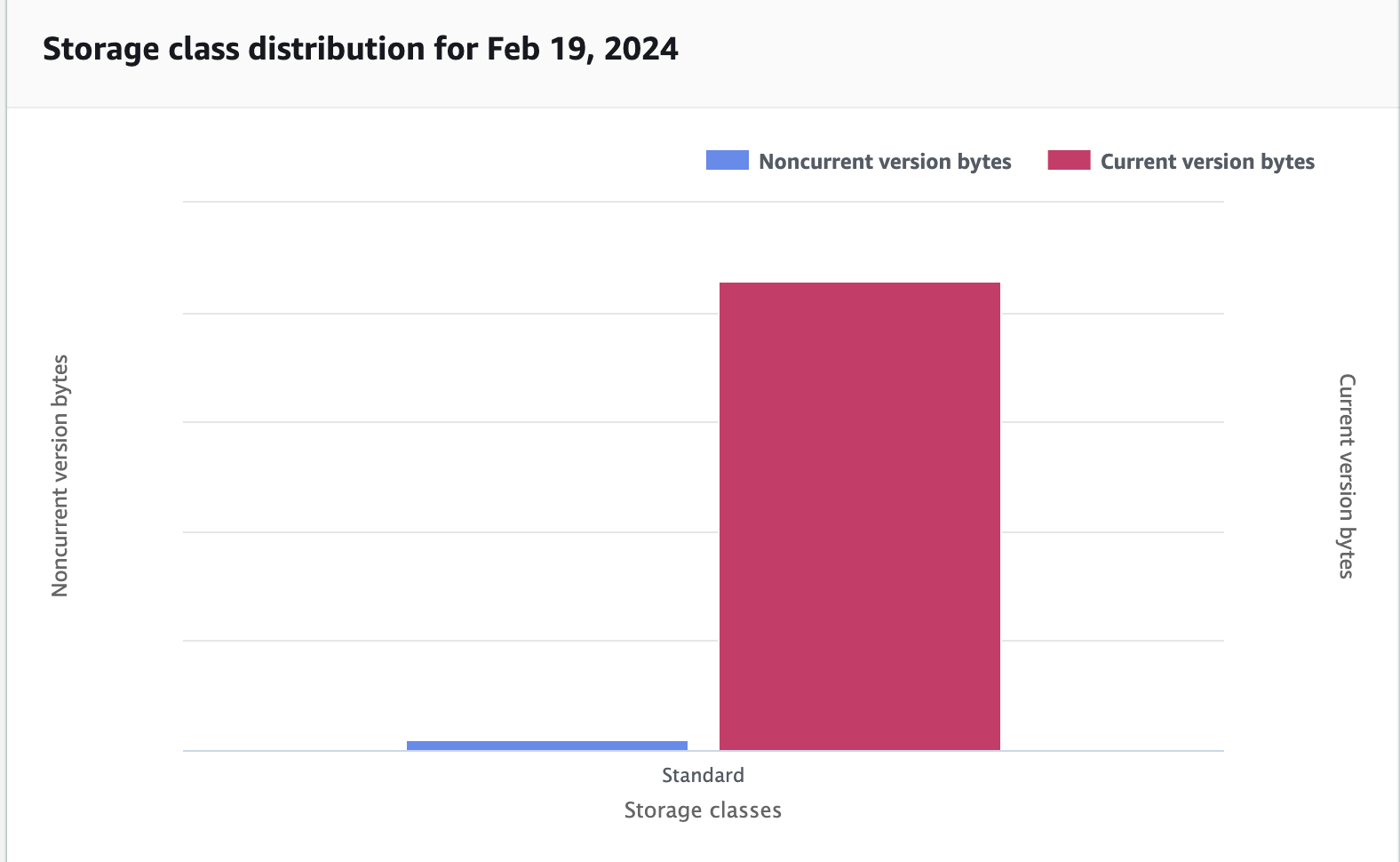
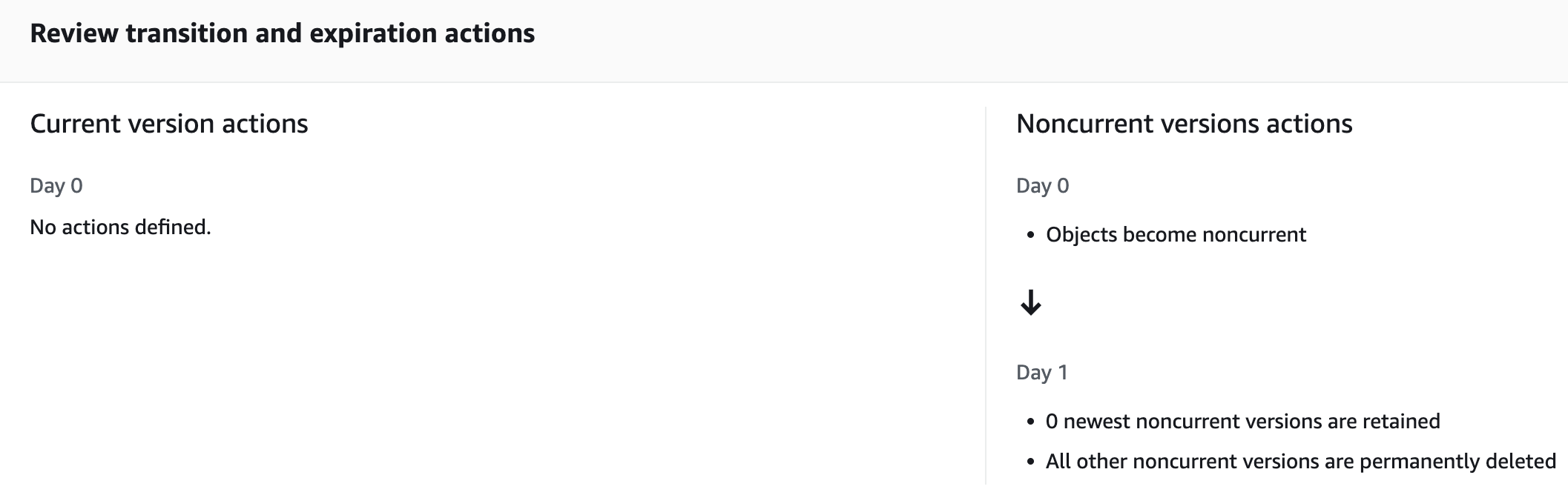
1. Handling S3 non current versions
Open Table Formats like Apache Hudi have their own mechanism to maintain commits of a table by adding new set of data and commit files during each upsert operations, If we enable file versioning without proper Lifecycle Management of non current files, this can lead to a higher storage costs due to too many versions as well as delete markers created in S3.
This can be analyzed using S3 Storage Lens 'Storage class distribution' option
and fixed by enabling Lifecycle rule configuration to clean up non current files post 1 day.
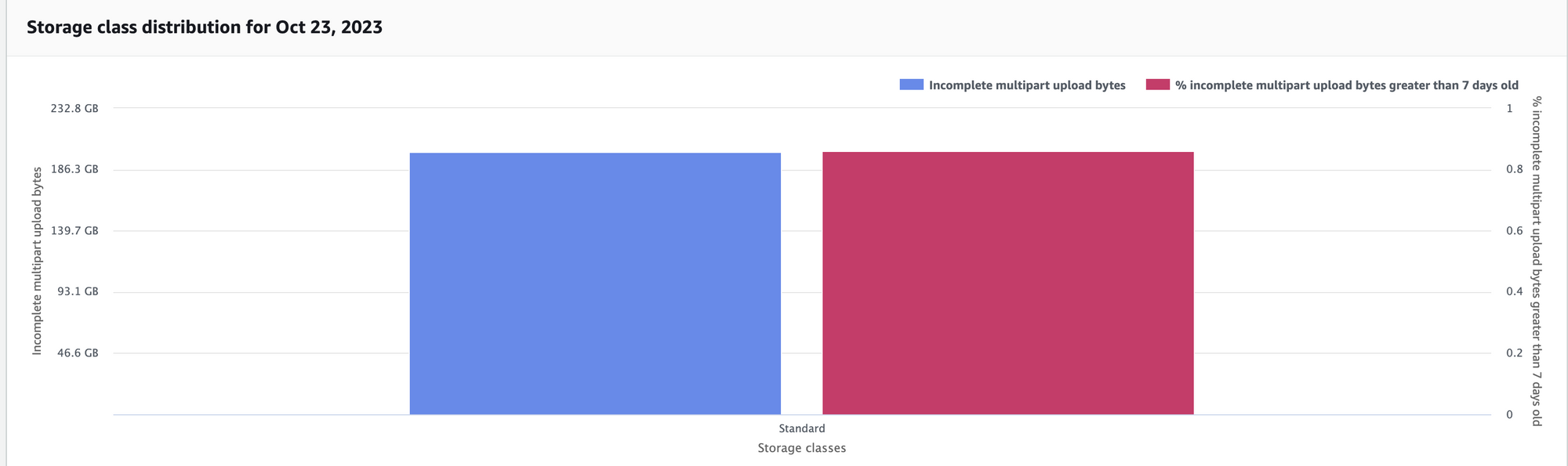
2. Cleaning up incomplete multipart upload files
Over the time, few data pipelines can fail or abort while uploading larger multipart files. Not having a proper lifecycle rule to clean these can cause increase in data storage.
As seen in the image below we can use S3 Storage Lens 'Storage class distribution' option to analyze the usage of incomplete multipart files and can be fixed by configuring S3 lifecycle rule to clean such files post 1 day.

Apart from these we also need to have Lifecycle policies enabled for ephemeral data like Elastic MapReduce Logs, AWS Athena Query Results etc.
Keeping a check on S3 API Costs
One of the major cost component in Data Lakehouse if not handled correctly can be S3 API costs. When we scan Apache Hudi or any open table format tables in Spark or Athena jobs, they invoke S3 API’s to access the data or metadata from S3 (List, Get, Head APIs). As data scales, this can cause too many API calls. Below options helped us to reduce S3 API usage.
1. Use partition pruning effectively
When a table is partitioned on a column, Hudi creates prefixes for that column on S3. When we scan such tables with filter on partition column, Spark pushes this filter to Hudi to only read selected prefix paths instead of scanning the whole table.
Make sure to use partition columns in query filters and also keep Apache Hudi up-to-date to fix any bugs that cause partition pruning not to work like Hudi Issue#6174.
To verify if partition pruning is working correctly, we can check in the Spark History UI's SQL / DataFrame tab. If partition pruning is working as expected then the number of partitions read will be smaller count as per the query filter applied.

2. Use Hudi Metadata table indices feature
To get the current state of a table, Hudi has to perform costly files list operations on S3 while reading or writing a table. This can be avoided by enabling and using Hudi metadata table indices feature using Hudi options like below:
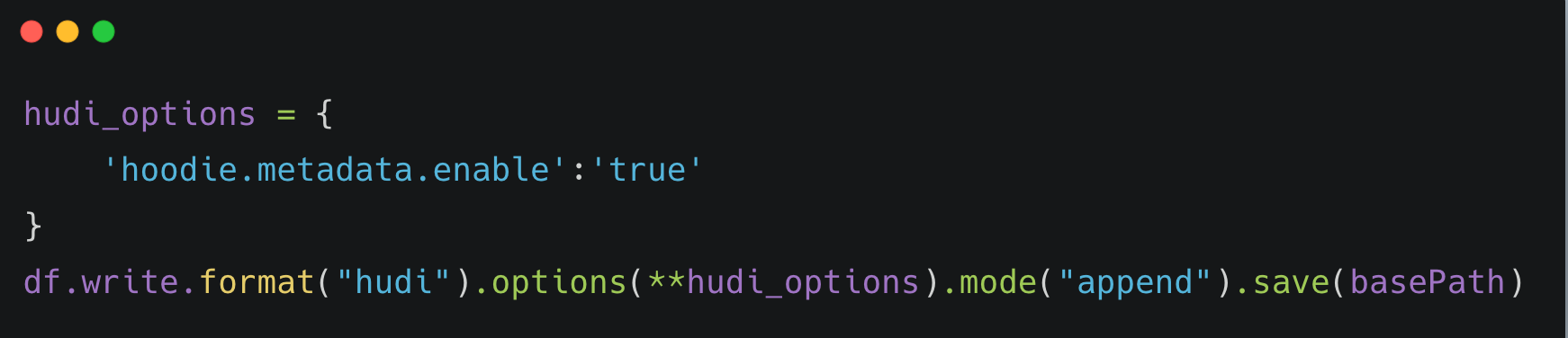
This option creates Files Index under the table path's .hoodie/metadata/files prefix and avoids costly listing of files during read or writes by reading file list from this prefix instead of performing a whole table prefix file scan.

Hudi also provides few more indices for better query planning and faster lookups like column_stats index, bloom_filter index which can be enabled by using below Hudi options while reading and writing to a Hudi table:

With above indices enabled, we can observe Spark running far lesser tasks to perform same read operation which in turn reduces S3 APIs called by this Job.
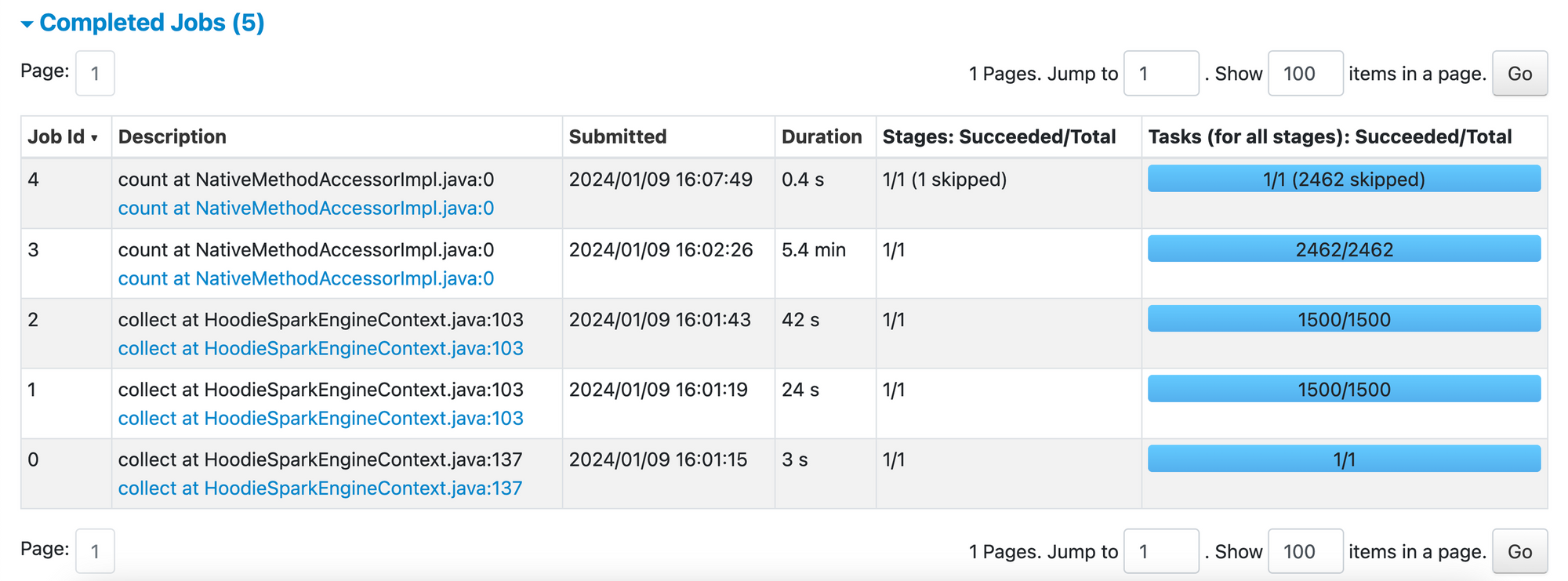
hoodie.metadata.enable = false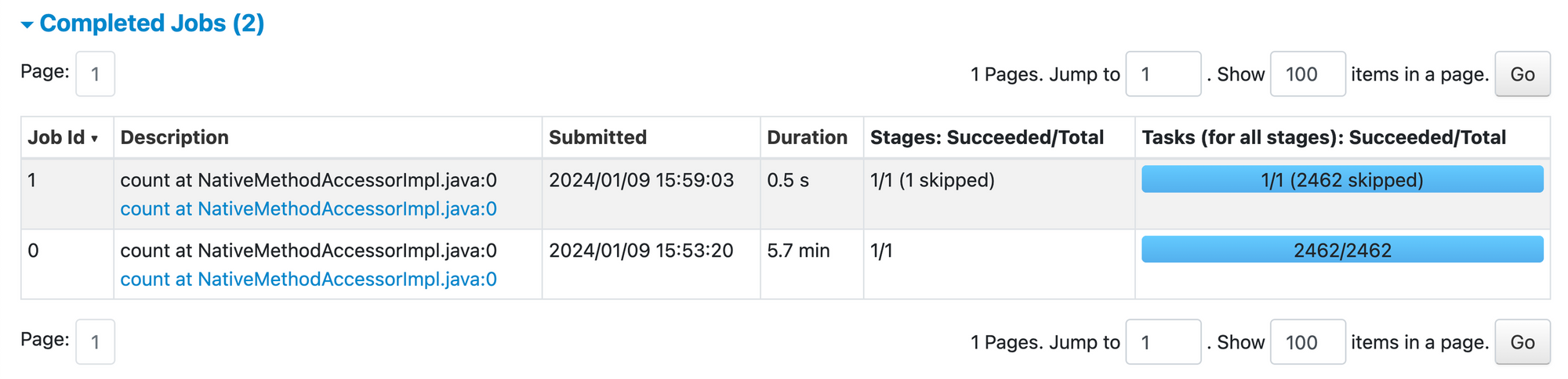
hoodie.metadata.enable = true3. Configure Hudi Cleaner and Archival
Apache Hudi comes with automatic cleaner and archival utilities, basic functionality of these are mentioned below. For normal use cases, default config works fine. But when we are operating at a larger scale, these utilities can play important role in cost saving as well as for good maintenance of a Data Lakehouse.
Cleaner: Cleaner process takes care of deleting the older versions of data files. As we upsert more data into a table, newer merged data files are written, and old files are kept for time travel purpose. We can use configs like below to enable cleaner to automatically clean old data files to save storage.
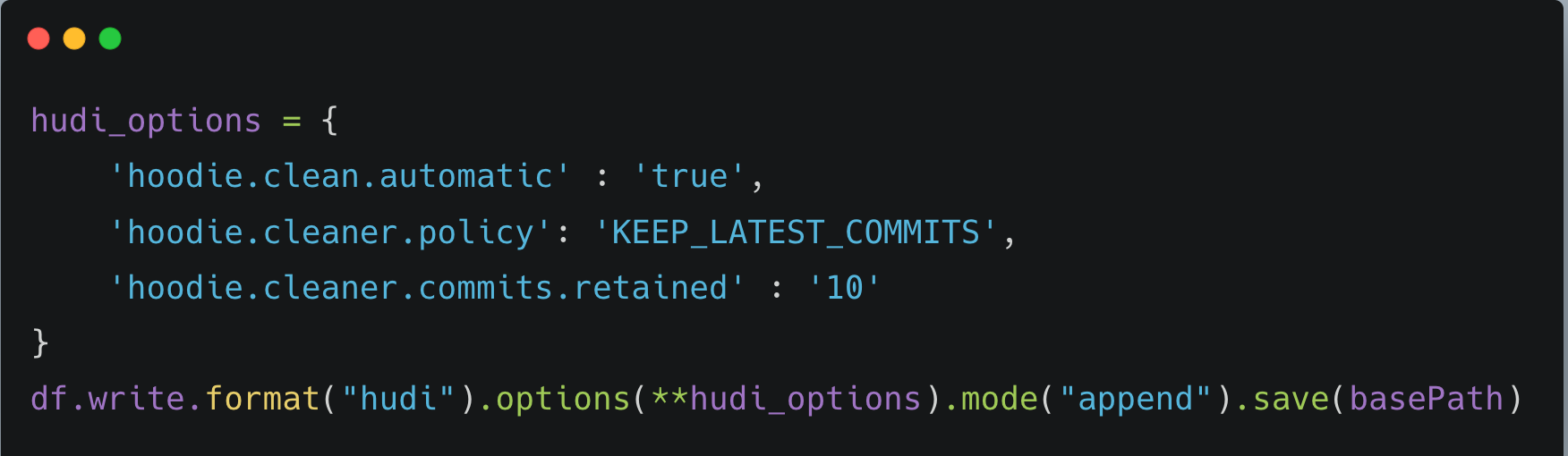
Above configs enable Hudi to run cleaner process after each commit automatically to clean old data files added beyond recent 10 commits.
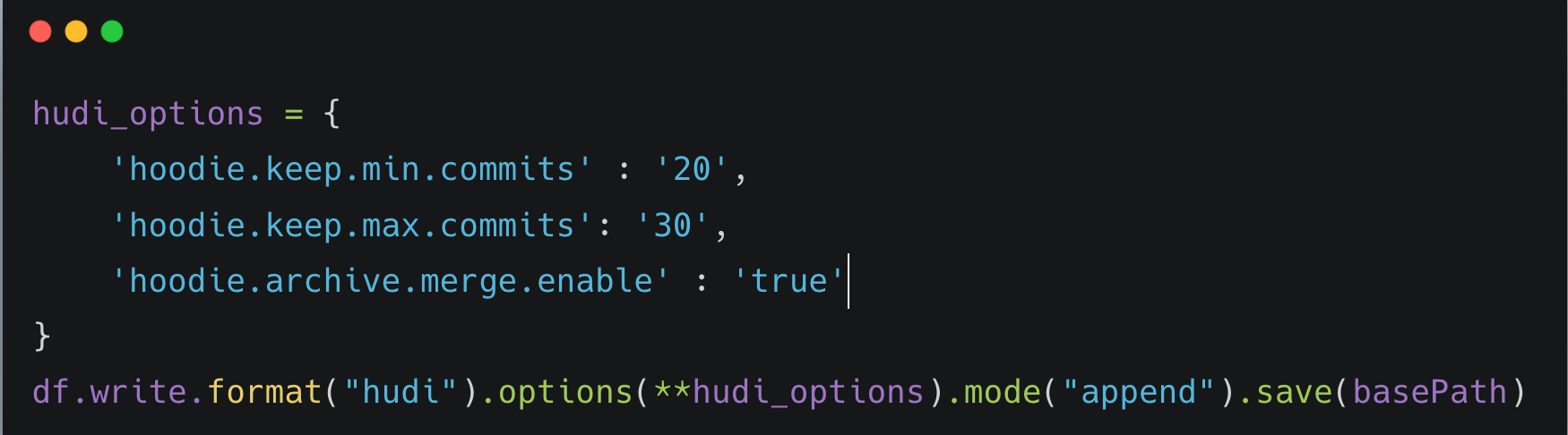
Archival: Archival process takes care of archiving old commit files of a Hudi Table. Similar to data files, Hudi also keeps writing commit metadata files in .hoodie prefix for each commit. When working on a larger scale, there can be necessity to cleanup these to fasten the process of reading recent commits by Hudi.
Below configs will help in archiving old commits into a different prefix .hoodie/archived under table path by Hudi.
Outcome of using these strategies
Using the above explained strategies, we were able to achieve below results:
- 66.3% reduction in our S3 API Requests from 10.9M to 3.6M requests.
- 41.5% reduction in our overall S3 costs.
- 34.2% reduction in our EMR Costs.
Summary
In this blog, we went through different ways to check and optimize costs in a Data Lakehouse system comprising of S3, Apache Hudi and Spark processes. We discussed about Data Lifecycle Management in cloud storage, how to reduce S3 API calls using partition pruning and Hudi's metadata indices and also we went through Cleaner and Archival utilities provided by Hudi to cleanup old data and commit files of a table automatically. These methods have helped us at Halodoc to reduce our Data Lakehouse costs significantly.
References
- https://hudi.apache.org/docs/metadata/
- https://hudi.apache.org/docs/hoodie_cleaner/
- https://aws.amazon.com/blogs/storage/optimize-storage-costs-by-analyzing-api-operations-on-amazon-s3/
Join us
Scalability, reliability and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek and many more. We recently closed our Series C round and In total have raised around USD$180 million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


