
Implementing Apache Yunikorn on EMR on EKS at Halodoc
At Halodoc, most of our data workloads revolve around Apache Spark. Every day and every hour, Spark jobs transform raw data into structured tables, such as dimensions and facts, that power analytics in Amazon Redshift. If data is the fuel, Spark is the engine that refines it.
But the story does not stop at the final tables that analysts see. Long before data reaches Redshift, Spark is already at work behind the scenes. In the earlier stages of our pipeline, it writes ingested data into Apache Hudi tables, forming what we call our processed zone. This layer becomes the foundation that ensures downstream transformations are reliable & consistent
These workloads run on EMR on EKS, where Spark applications are launched using spark-submit and scheduled as part of Apache Airflow workflows. Some jobs run daily to build aggregated models that support long-term analysis. Others run hourly to keep datasets fresh and aligned with near-real-time operational needs. The cadence of these jobs reflects the rhythm of our business, constantly running at different frequencies and evolving based on newer business needs.
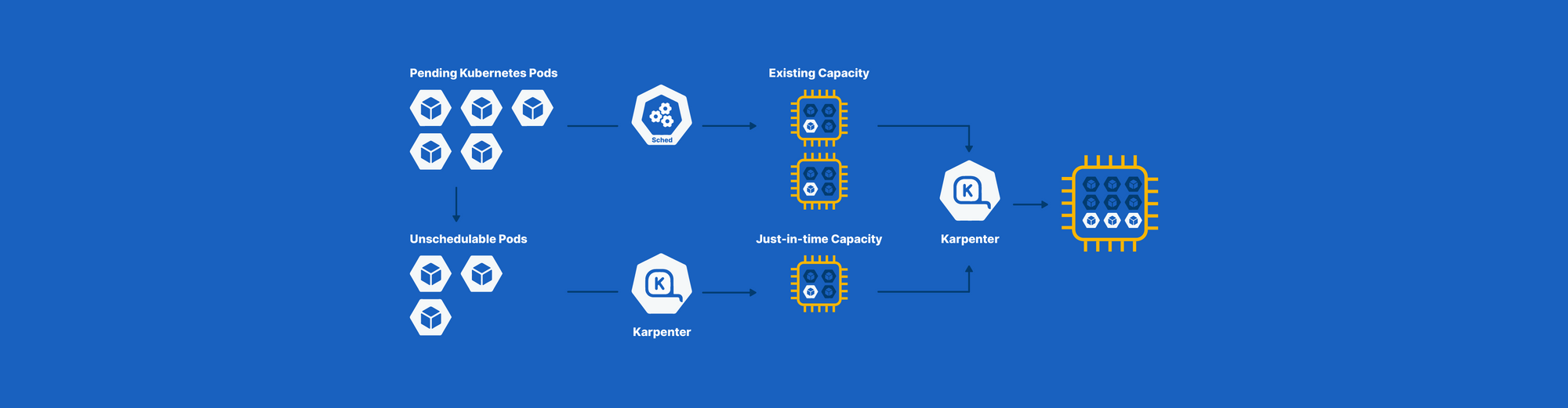
Because the size and frequency of these workloads vary, compute demand fluctuates throughout the day. There are moments when the platform is relatively calm, and others when multiple heavy jobs run in parallel. To handle this dynamic environment, we rely on Karpenter to provision nodes on demand within our EKS cluster. When Spark workloads scale up, the cluster expands with them. When demand decreases, unused capacity is automatically removed.
In this way, Spark on EMR on EKS forms the backbone of our data processing platform. Its efficiency directly influences cost, performance, and reliability. More importantly, it determines how quickly and confidently we can turn raw data into insights that drive decisions across Halodoc.
When Spark Met the Kubernetes Default Scheduler
At first glance, everything seemed to be working exactly as designed. Our Spark workloads were already running on EKS, with Karpenter dynamically provisioning nodes whenever demand increased. The architecture looked modern, elastic, and cloud-native. Autoscaling was in place, and resources were expanding on demand. From an infrastructure perspective, there was no obvious red flag.
Yet as the platform matured and workloads intensified, subtle scheduling behaviors began to surface. The system was technically functioning as expected, but the behavior at the application level told a different story. What looked elastic from the outside started revealing coordination gaps under real production pressure.
The Invisible Deadlock
A Spark application is not a single unit; it’s a coordinated system of one Driver and multiple Executors. However, Kubernetes’ default scheduler doesn’t understand that relationship. It evaluates each Pod independently. So what happened in our Halodoc data platform?
- The Driver got scheduled
Since the Driver typically requests fewer resources compared to the total Executor footprint, it was often placed quickly on an available node. From Kubernetes’ perspective, this was a normal scheduling decision. - Executors were scheduled partially
As cluster capacity became constrained, the scheduler placed only a subset of Executor pods while leaving the rest in a pending state due to insufficient available resources. During burst periods, we would observe some Executors waiting in a pending state for 3–5 minutes before being allocated - The job never fully started
While Spark can technically begin execution with fewer Executors than requested, the reduced parallelism often leads to severe performance degradation and unpredictable behavior under production workloads.
The problem wasn’t just scheduling. It was coordination.
Multi-Tenancy: When Fairness Becomes Chaos
As business continued to grow, so did the demands on our data platform - more transactions, more user interactions, more operational data.
The default scheduler follows a mostly FIFO approach at the Pod level. But Pods from different jobs were mixed together in the scheduling queue.
When multiple Spark jobs were triggered at the same time, we observed :
- Drivers from different jobs got scheduled
- Executors from all jobs got scheduled simultaneously
- Karpenter interpreted this as massive demand
- Nodes scaled out aggressively
Instead of controlled parallelism, we got a resource free-for-all. The cluster wasn’t just busy; it was reacting to bursts without understanding job boundaries.
This became particularly concerning for critical workloads such as finance reconciliation (Recon) jobs, which require predictable resource access and should not compete directly with lower-priority data processing tasks. Without clear boundaries, even important jobs risked being delayed during peak activity.
Burst Scaling and the Cost Whiplash
Our ETL pipelines run on fixed schedules. Naturally, many jobs start within the same time window. This created a predictable but sharp workload spike.
Kubernetes attempted to schedule everything immediately. Karpenter provisioned nodes rapidly to satisfy the surge. Within minutes, the cluster size ballooned.
And then… the jobs finished.
Nodes became underutilized almost instantly. From a cloud-cost perspective, this was painful:
- Rapid scale-out
- Short-lived utilization
- Eventual scale-down
Elasticity without coordination turned into inefficiency. Because nodes were provisioned rapidly to satisfy Executor demand, Driver pods sometimes ended up running on larger instances than they actually required.
Why Apache YuniKorn?
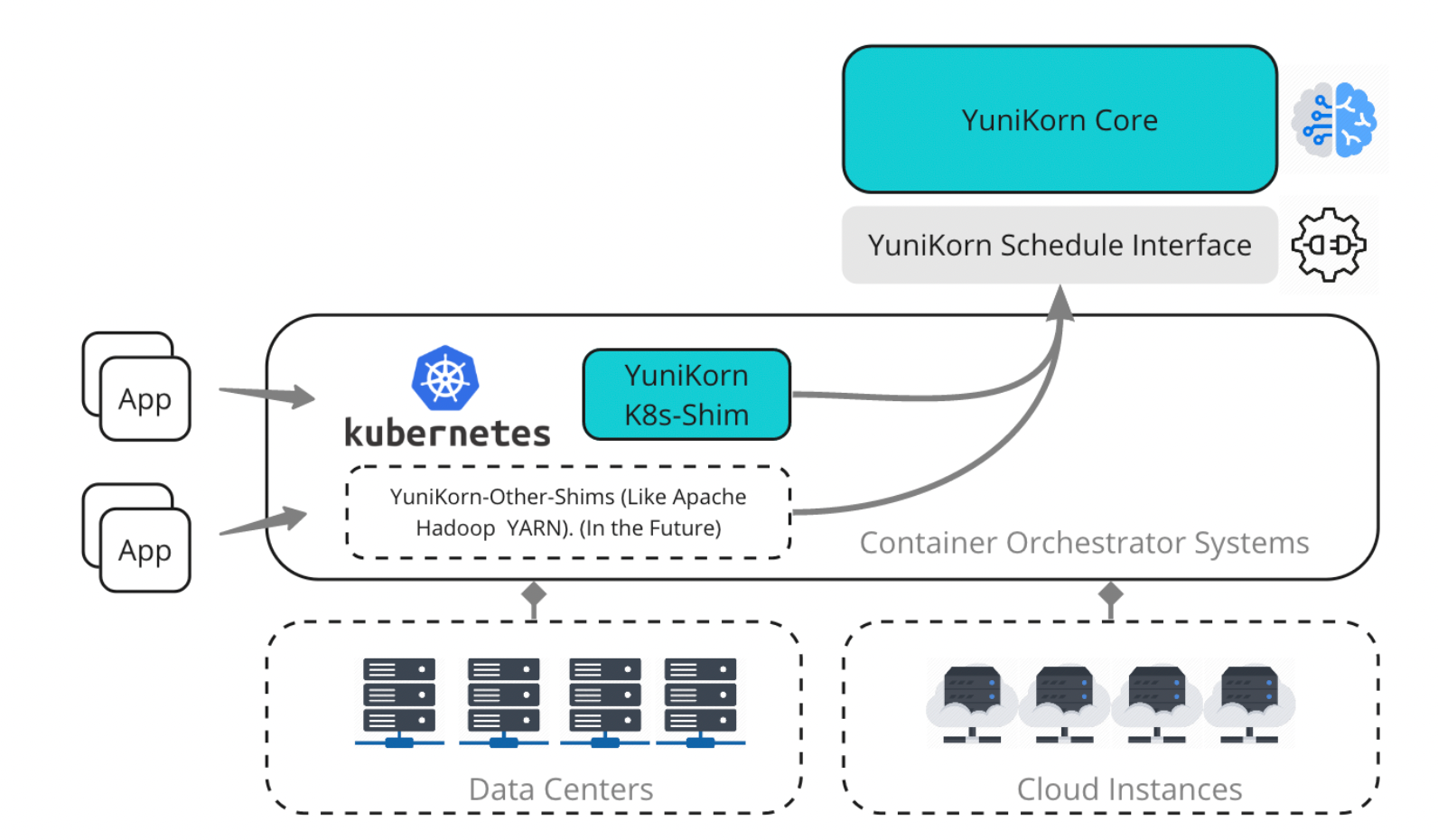
After identifying the coordination gaps in our scheduling model, we knew the solution wasn’t simply adding more nodes or tweaking autoscaling thresholds. The core issue was that our workloads required application-aware scheduling, fairness across growing business demands, and better control over resource allocation.
Replacing Kubernetes entirely was not an option. We needed something that could enhance the scheduling layer without disrupting the foundation of our platform.
That’s when we started evaluating Apache Yunikorn.
What stood out was not just its feature set, but how closely it aligned with the specific failure modes we had observed in production.
Application-Aware Scheduling with Native Gang Support
One of the most critical gaps we identified was the lack of coordinated scheduling for distributed applications like Spark.
YuniKorn provides native gang scheduling support, ensuring that related Pods, such as Spark Drivers and Executors, are scheduled together as a logical unit. Instead of partially launching applications and leaving them in limbo, the scheduler waits until sufficient resources are available for the entire group.
This directly addressed the invisible deadlock pattern we had encountered.
Structured Multi-Tenancy Through Hierarchical Queues
As business growth increased workload concurrency, fairness became more important than raw elasticity.
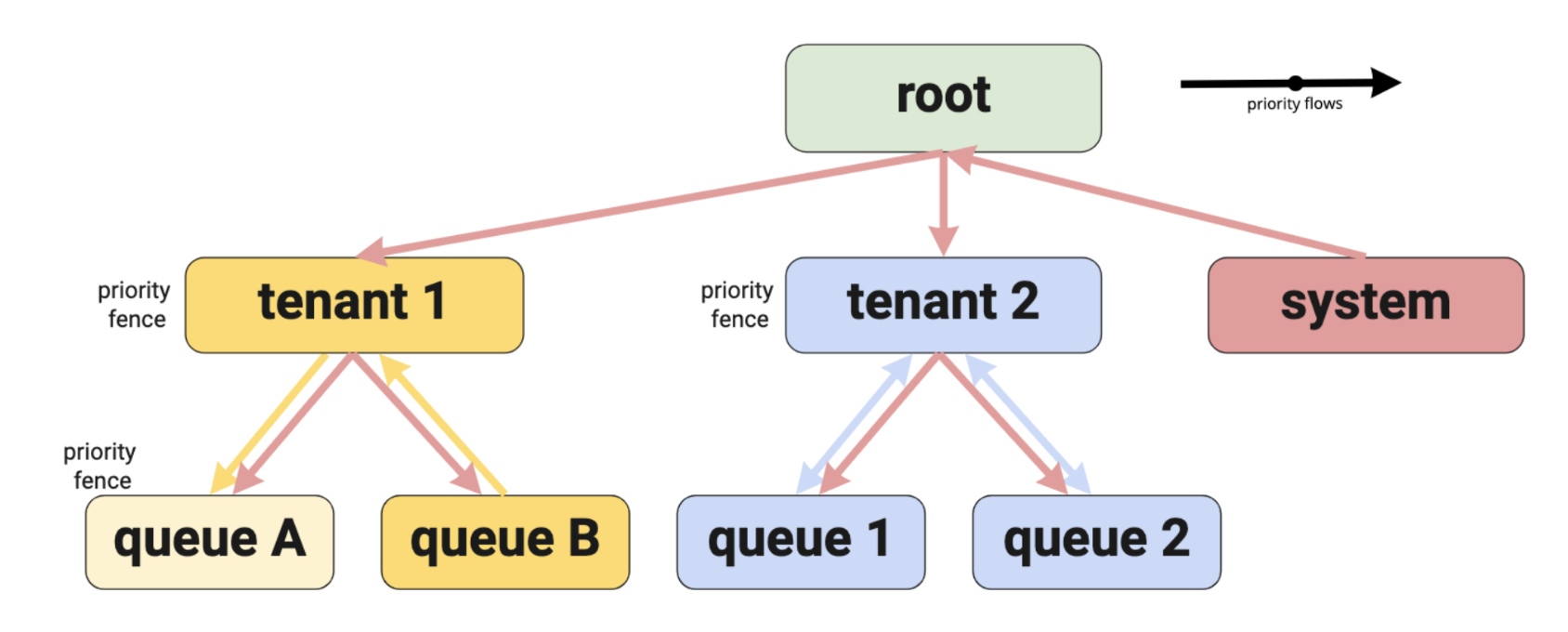
YuniKorn introduces a hierarchical queue model that structures resource allocation in layers. As illustrated above, workloads are organized under a root queue, which is then divided into tenant-level queues and further segmented into application-level queues. This hierarchy allows resources to be partitioned logically - for example, separating system workloads from tenant workloads, and isolating different job categories within each tenant.
Instead of placing all Pods into a single flat scheduling pool, each workload is assigned to a specific queue with defined capacity and priority boundaries. This ensures that one tenant or job category cannot monopolize cluster resources during peak demand. With these boundaries in place, resource competition becomes controlled instead of chaotic.
Better Bin Packing, Better Utilization
Another lesson from our burst-scaling pattern was that elasticity alone does not guarantee efficiency.
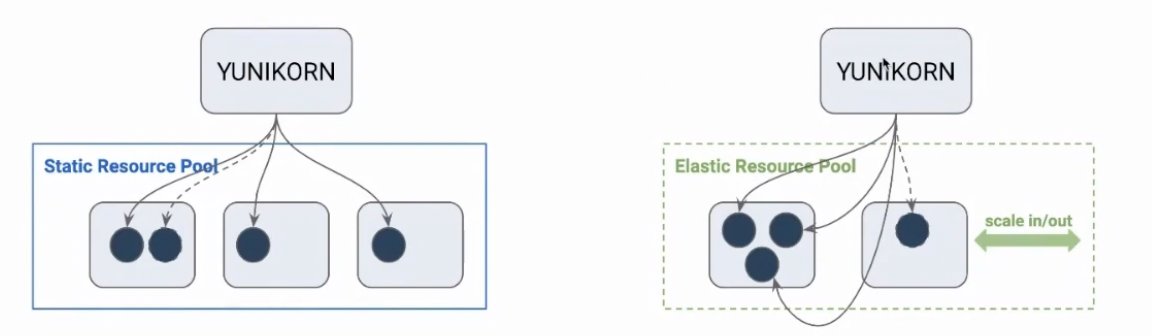
YuniKorn’s improved bin-packing and node-sorting strategies reduce resource fragmentation by placing workload components, illustrated as blue dots representing individual Spark Drivers and Executors, more compactly onto existing nodes. Under the default Kubernetes scheduler, these components are spread across multiple nodes, leaving unused capacity gaps that trigger premature scaling.
With bin packing enabled, workloads are consolidated more tightly, increasing utilization across existing nodes. Instead of scaling outward immediately, we could make better use of what was already available.
Incremental Adoption Without Architectural Disruption
Perhaps most importantly, YuniKorn gave us flexibility.
It can operate alongside the default Kubernetes scheduler or fully replace it. This allowed us to introduce it incrementally, minimizing risk and avoiding a full redesign of our cluster architecture.
For a production healthcare platform, incremental evolution is often more valuable than radical change.
Implementing Gang Scheduling
Choosing YuniKorn was only the first step. The real shift happened when we translated its capabilities into practical changes in how our Spark workloads were scheduled.
The invisible deadlock we previously experienced stemmed from one core mismatch: Spark applications behave as coordinated units, while the default scheduling model treated them as independent Pods. To eliminate partial execution states, the scheduler needed to treat each Spark job as a single unit instead of independent Pods.

With YuniKorn in place, we enabled gang scheduling for our Spark workloads. This ensured that the Driver and its associated Executors were treated as a single scheduling group.
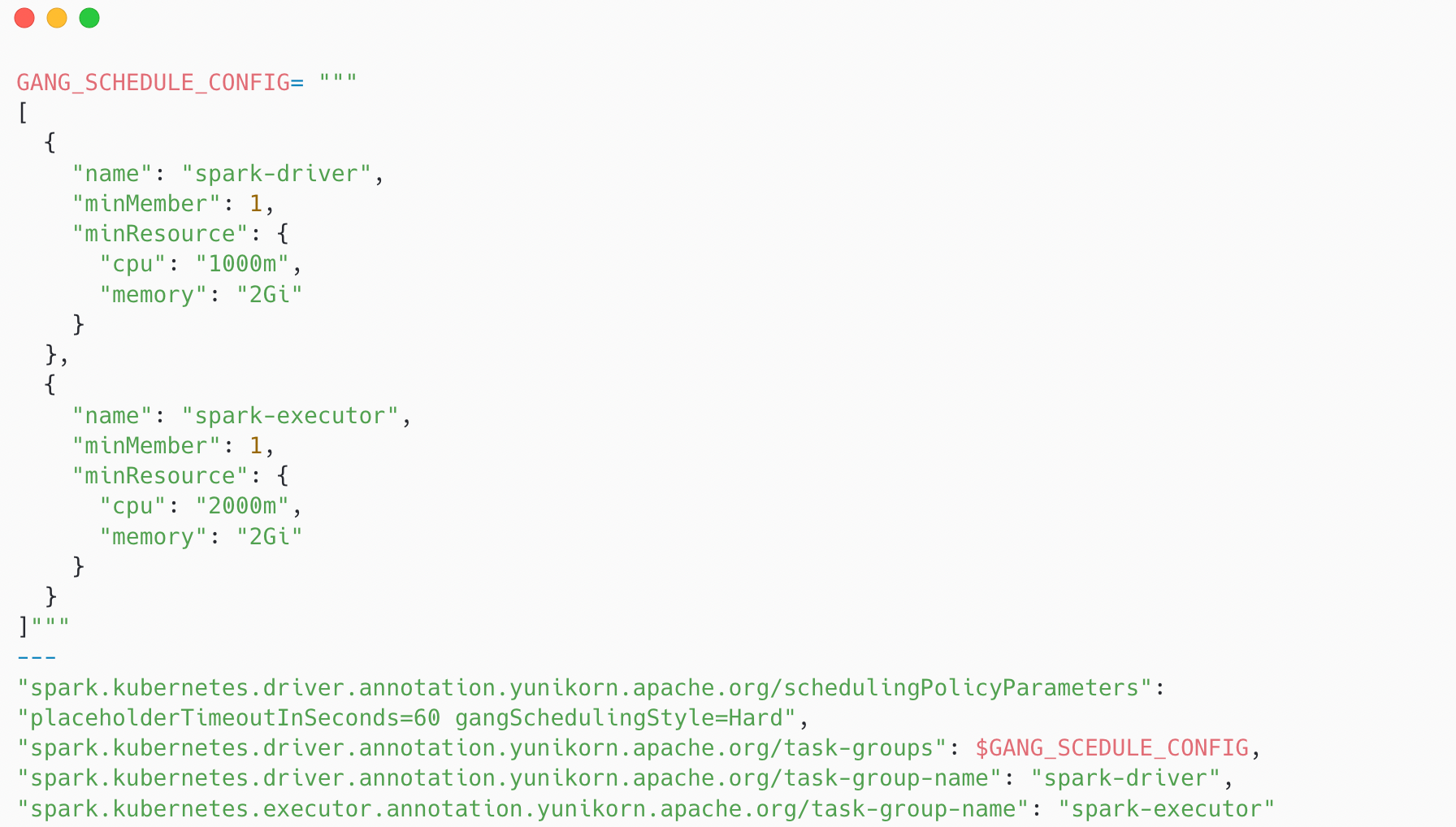
There are two types of gang scheduling styles:
- Hard: Requires all pods in a task group to be scheduled together. The job will not start until all requested resources are available.
- Soft: Allows a job to start even if only some of its pods have been allocated resources, while the remaining pods continue to wait.
For our data platform, the choice was clear. One of the core issues we wanted to eliminate was the scenario where a Driver runs alone without sufficient Executors

In practice, enabling this required us to define a task group as part of the Spark job submission. The task group specifies how many pods belong to the application and what resources they collectively require. The resource definitions in the task group needed to align precisely with the actual Spark configuration, including driver and executor CPU and memory requests
One subtle detail we discovered during implementation relates to task group identifiers. The documentation mentions that each task group must have a unique identifier. However, in reality, we did not need to generate unique keys manually. Kubernetes already guarantees pod-level uniqueness, and YuniKorn operates on top of that mechanism. As a result, no additional orchestration logic was required during job submission.
The overall change was conceptually simple but operationally meaningful. Instead of launching Spark components independently and hoping they converge, we now declare upfront what the application needs - and let the scheduler make an all-or-nothing decision.
Configuring Hierarchical Queues
While gang scheduling solved the coordination problem within a single Spark application, it did not address a broader question: how should multiple applications share the cluster fairly?
As our workloads continued to grow, simply ensuring that each job started correctly was no longer sufficient. We also needed a mechanism to control how resources were distributed across concurrent applications, especially during peak windows.
This is where hierarchical queues come into play.
In YuniKorn, queues act as logical boundaries for resource allocation. They allow us to define how much of the cluster can be consumed by different workload categories, teams, or job groups. Before submitting Spark applications, we first needed to design and define a queue hierarchy that reflected our workload structure and governance model.

By creating queues in advance, we can control how resources are distributed across teams, environments, or job types. Each Spark job is then submitted to a specific queue, allowing the scheduler to enforce fairness, limits, and prioritization policies at the queue level.
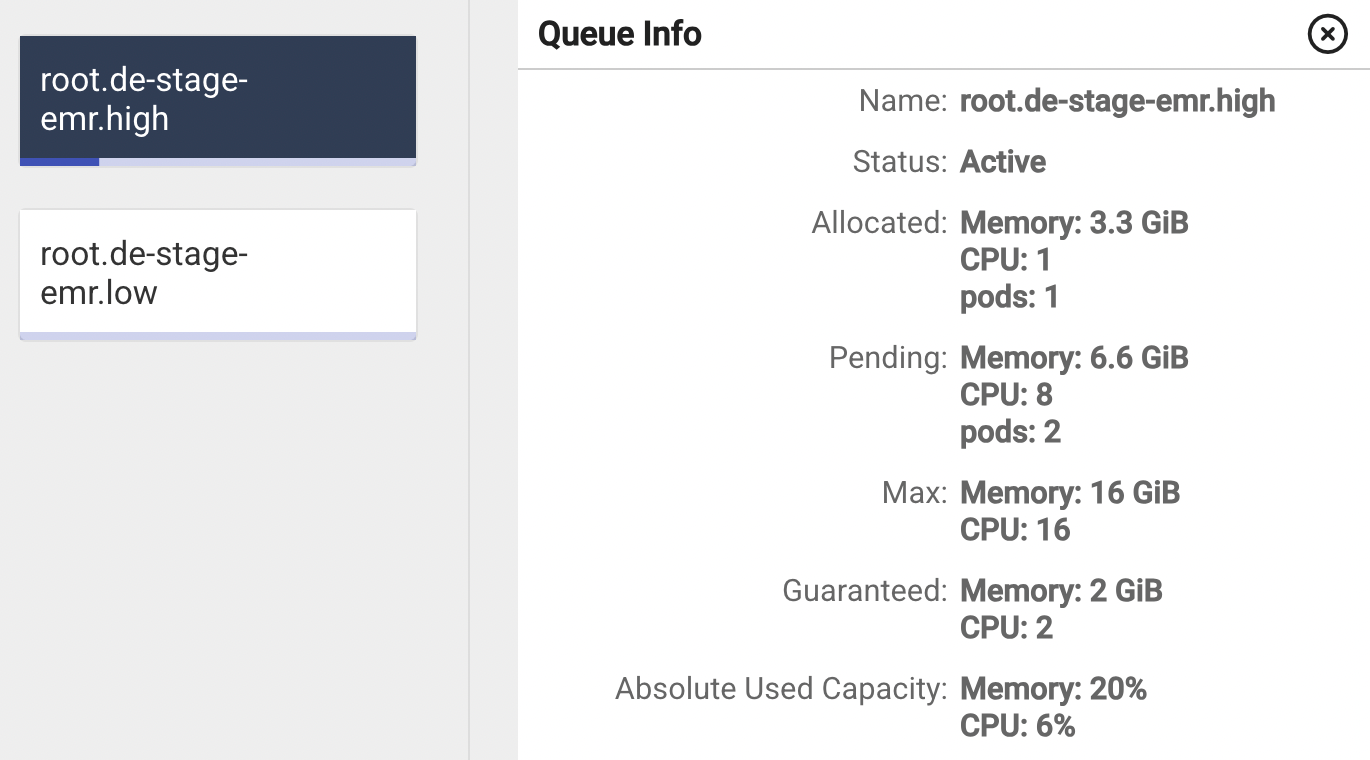
As shown in the configuration above, we define multiple queues under the queues section, each representing a logical boundary within the cluster. For every queue, we specify its name along with explicit resource limits that govern how much of the cluster it is allowed to consume.
The max field plays a critical role here. It defines the upper resource boundary for a given queue. Even if additional cluster capacity is technically available, a queue cannot exceed this configured limit. In other words, scaling is no longer purely reactive to unschedulable pods - it is constrained by intentional governance rules.
However, defining queues at the cluster level is only one side of the equation. We also need a way to ensure that each Spark application is submitted into the correct queue. Without explicit assignment, workloads would still default to the root queue, defeating the purpose of hierarchical isolation.

During our Proof of Concept (PoC), we discovered that defining the queue annotation at the driver level was sufficient for our use case. The executors automatically inherited the queue assignment from the driver, and we did not need to explicitly define:

This mechanism fundamentally changes our cluster’s behavior under pressure. Instead of allowing concurrent workloads to aggressively trigger node provisioning, applications that exceed their allocated capacity will remain queued. They wait, rather than immediately expanding the cluster.
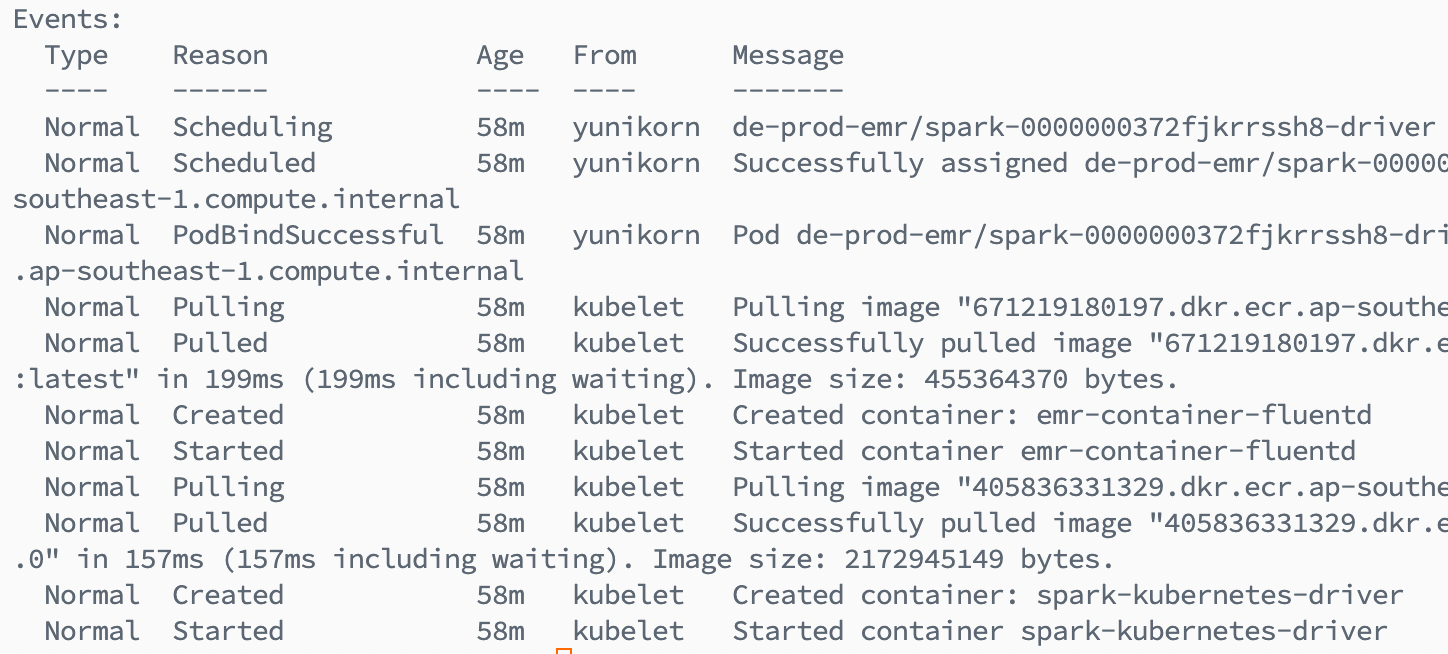
For our platform, this was particularly important during burst windows. Previously, multiple Spark applications starting at the same time could cause rapid scale-outs followed by short-lived utilization. By enforcing queue-level boundaries, we introduced controlled contention instead of uncontrolled expansion. The result was a more predictable scaling pattern and better cost discipline during peak workloads.
Preventing Indefinite Pending States
While queue limits gave us stronger control over resource allocation and prevented aggressive cluster scale-outs, they also introduced a new operational consideration.
During our PoC phase, we encountered an interesting edge case. If a Spark job requested resources that exceeded the configured max capacity of its assigned queue, YuniKorn behaved exactly as designed - it refused to allocate additional resources beyond the queue boundary.
From the scheduler’s perspective, this was correct.
From the application’s perspective, the job appeared to be stuck in a pending state indefinitely.

However, instead of rejecting the job outright when the requested resources exceed the queue’s limit, we implemented a controlled fallback mechanism. In such cases, the workload is redirected to the default Kubernetes scheduler.
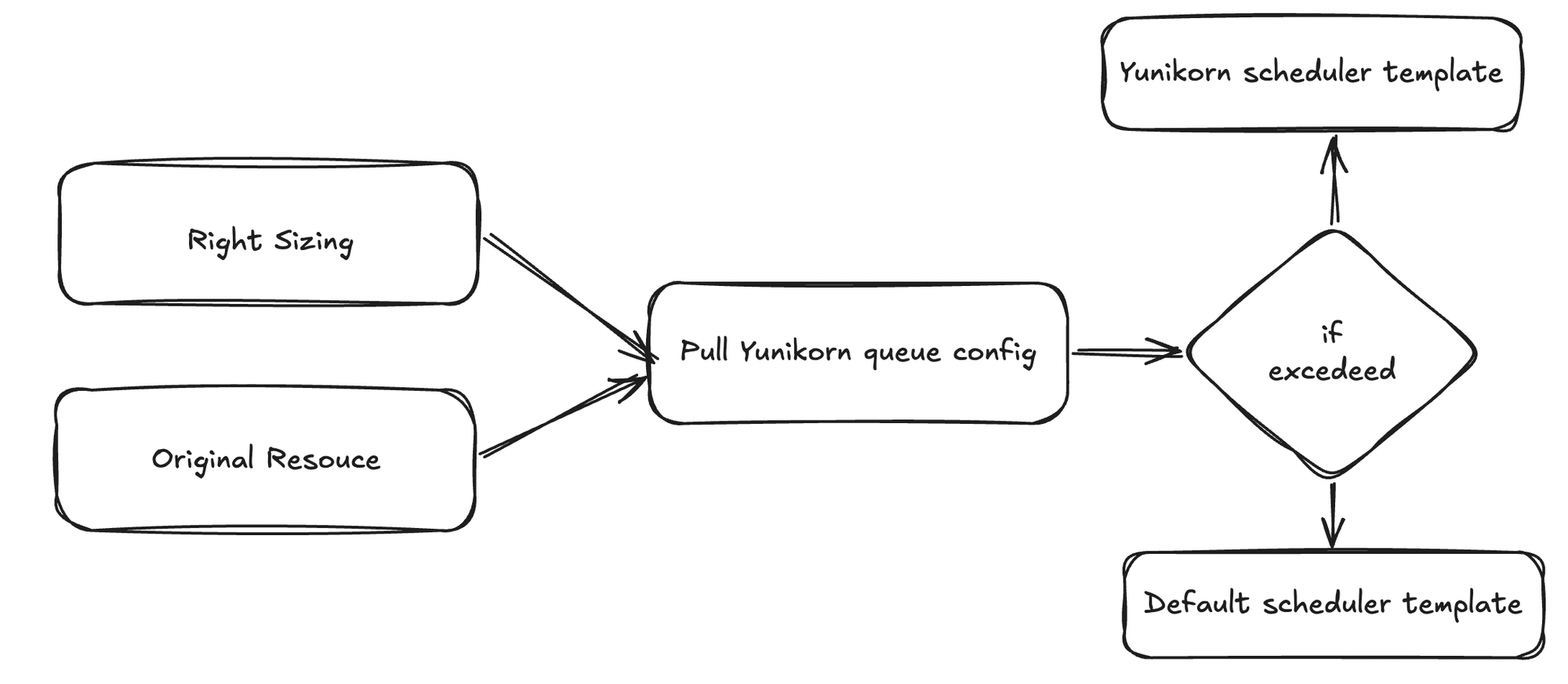
Our validation flow works as follows:
- Read the intended resource request
We retrieve the resource configuration that will be submitted to EMR on EKS, whether it comes from right-sizing logic or the original static configuration. - Apply a Safety Buffer
We retrieve the resource configuration that will be submitted to EMR on EKS, whether it comes from right-sizing logic or the original static configuration. - Always consider the original configuration
Since right-sizing can be toggled off, we include the original resource definition in the validation logic to maintain consistent checks. - Query the Target Queue via YuniKorn API
We retrieve the current queue configuration and limits directly from the YuniKorn scheduler API, based on the queue specified in the job submission. - Compare and decide
If the total requested resources exceed the queue’s configured maximum capacity, the validation fails. Instead of allowing the job to remain pending indefinitely, we automatically fall back to the default Kubernetes scheduler.
Enabling Bin Packing Node Sorting
One of the patterns we previously observed was aggressive scale-out during workload spikes. Even when capacity technically existed in the cluster, resource fragmentation often made it appear as if new nodes were required. The result was reactive provisioning - followed shortly by underutilization.
Before scaling the cluster any further, we needed to ask ourselves: are we truly exhausting the capacity we already provisioned, or are we scaling because of inefficient placement?
This is where bin packing became important.

By enabling bin-packing–based node sorting, we shifted the scheduler’s placement strategy. Instead of spreading Pods evenly across nodes, YuniKorn prioritizes filling up existing nodes first. The goal is to consolidate workloads tightly before triggering additional node provisioning.

This subtle change in placement strategy has significant downstream effects. By reducing resource fragmentation, we lower the likelihood of unnecessary scale-outs. Nodes are utilized more efficiently, and scaling becomes a deliberate response to real capacity exhaustion - not an artifact of scattered allocation.
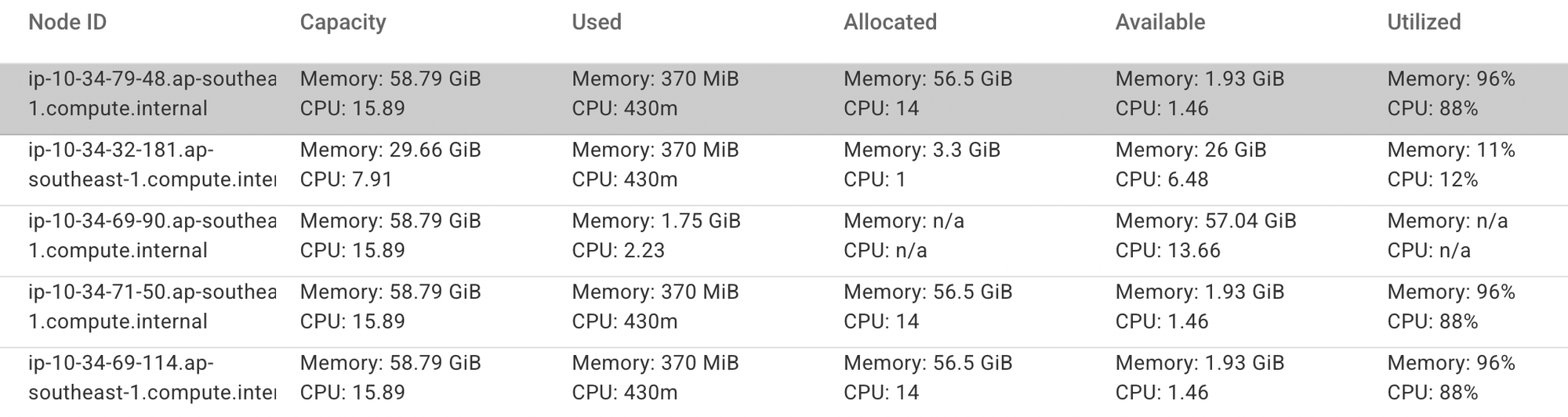
Operationally, the impact of this change is clearly visible through the YuniKorn UI. The interface provides detailed insights into each node’s total capacity, allocated resources, available headroom, and overall utilization. This level of visibility allows us to observe how workloads are consolidated over time, rather than being scattered across the cluster.
After enabling bin packing, we observed node utilization climbing significantly — in some cases reaching 96% and above before triggering additional scale-outs. This confirmed that workloads were being packed efficiently onto existing nodes, reducing fragmentation and ensuring that new capacity was provisioned only when genuinely necessary.
More importantly, bin packing reinforced a broader principle in our platform design: scale only when necessary. By improving placement efficiency first, we ensured that cluster growth was driven by genuine resource needs rather than scheduling side effects.
Lessons Learned
Looking back, the challenges we faced were not purely about capacity, but about coordination and governance. What initially appeared to be scaling limitations were actually scheduling behaviors surfacing under real production load. This reinforced an important lesson: adding more resources is often the simplest reaction, but not always the right one.
Introducing stronger controls improved predictability, but it also required better visibility and validation to avoid unintended side effects. By evolving the platform incrementally rather than replacing components outright, we were able to improve reliability and efficiency without disrupting ongoing workloads.
In the end, this journey was less about changing a scheduler and more about maturing how we approach scaling in a distributed system.
Conclusion
By introducing Apache YuniKorn into our EMR on EKS platform, we fundamentally changed how cluster resources are allocated and consumed. The shift was not about replacing the Default Scheduler Kubernetes, but about adding application-aware coordination and structured governance on top of it.
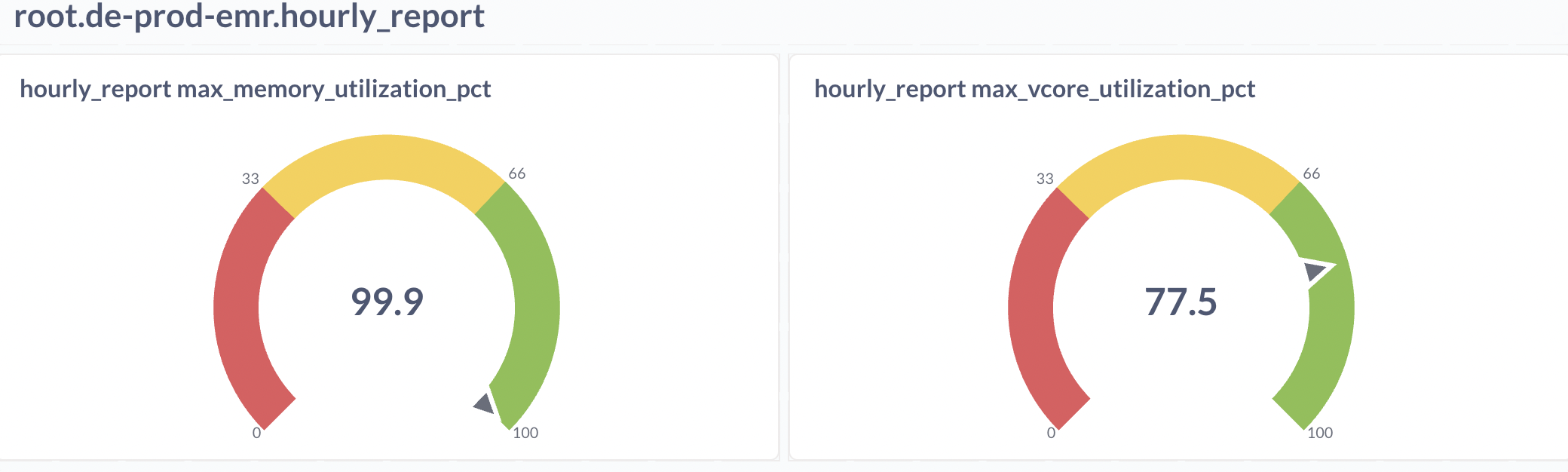
We started conservatively, migrating only low-priority workloads into the queue-based scheduling model. Even within this limited scope, the results were measurable. We observed node memory utilization exceeding 90% and CPU utilization reaching approximately 88% with bin packing enabled, significantly reducing resource fragmentation before triggering additional scale-outs.
This translated into approximately a 10% reduction in EC2 costs, driven primarily by preventing unnecessary node provisioning and allowing workloads to operate within clearly defined capacity boundaries.
With improved scheduling predictability and more efficient provisioning behavior, we were also able to gradually increase our use of Spot instances, further optimizing our overall compute footprint.
At the same time, this is not a one-time optimization. We continuously monitor workload behavior, analyze scheduling patterns, and fine-tune configuration parameters to further improve node utilization and maintain efficiency as demand evolves.
For teams running Spark workloads on EMR on EKS, especially those seeking better CPU and memory utilization or looking to optimize compute costs, it is worth evaluating YuniKorn as a scheduling layer. With the right configuration and observability in place, it can provide meaningful improvements in both efficiency and predictability.
Reference



Join us
Scalability, reliability, and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number one all-around healthcare application in Indonesia. Our mission is to simplify and deliver quality healthcare across Indonesia, from Sabang to Merauke. Since 2016, Halodoc has been improving health literacy in Indonesia by providing user-friendly healthcare communication, education, and information (KIE). In parallel, our ecosystem has expanded to offer a range of services that facilitate convenient access to healthcare, starting with Homecare by Halodoc as a preventive care feature that allows users to conduct health tests privately and securely from the comfort of their homes; My Insurance, which allows users to access the benefits of cashless outpatient services in a more seamless way; Chat with Doctor, which allows users to consult with over 20,000 licensed physicians via chat, video or voice call; and Health Store features that allow users to purchase medicines, supplements and various health products from our network of over 4,900 trusted partner pharmacies. To deliver holistic health solutions in a fully digital way, Halodoc offers Digital Clinic services including Haloskin, a trusted dermatology care platform guided by experienced dermatologists.We are proud to be trusted by global and regional investors, including the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. With over USD 100 million raised to date, including our recent Series D, our team is committed to building the best personalized healthcare solutions — and we remain steadfast in our journey to simplify healthcare for all Indonesians.


