

Streamlining Code Reviews: An Introduction to Semgrep
At Halodoc, we embrace shift-left security testing and as part of that, we have implemented Software Composition Analysis (SCA), Static Analysis Security Testing (SAST), Dynamic Analysis Security Testing (DAST) at Halodoc. In today’s fast-paced development environment, high-quality software delivery is essential to success. Code review is one of the most important ways to ensure code quality. In this blog, We'll talk about Semgrep and it's automatic source code review capabilities and most importantly, detecting vulnerabilities through it.
What is Semgrep?
Semgrep is a modern, open-source static analysis tool that simplifies code reviews and detects vulnerabilities early in the development process. Semgrep's rule-based approach and extensive rule library make it easy to detect and fix common coding mistakes such as improper use of functions/methods and security issues.Semgrep interfaces with well-known tools like IDEs, Git, and CI/CD pipelines and supports many different programming languages. By identifying flaws and vulnerabilities early in an automated way, lowering the need for manual code review, and enhancing code quality, Semgrep can help save time and money.
Working of Semgrep
Semgrep analyses source code to find patterns that match particular rules. A rule is a pattern or template that specifies a certain kind of problem, such as possible security vulnerability or a breach of coding best practices. There are many built-in rules in Semgrep, and you may also write your own unique rules specifically for your business use-case.
Semgrep searches for patterns in code that fit the rules listed in its rule library when it scans the source code. When a pattern matches a rule, Semgrep creates a finding that contains details about the problem and the place in the code where the rule was activated. Both the query and the source code are converted into Abstract Syntax Trees (ASTs), and the query AST is then used as a tree-matching query.
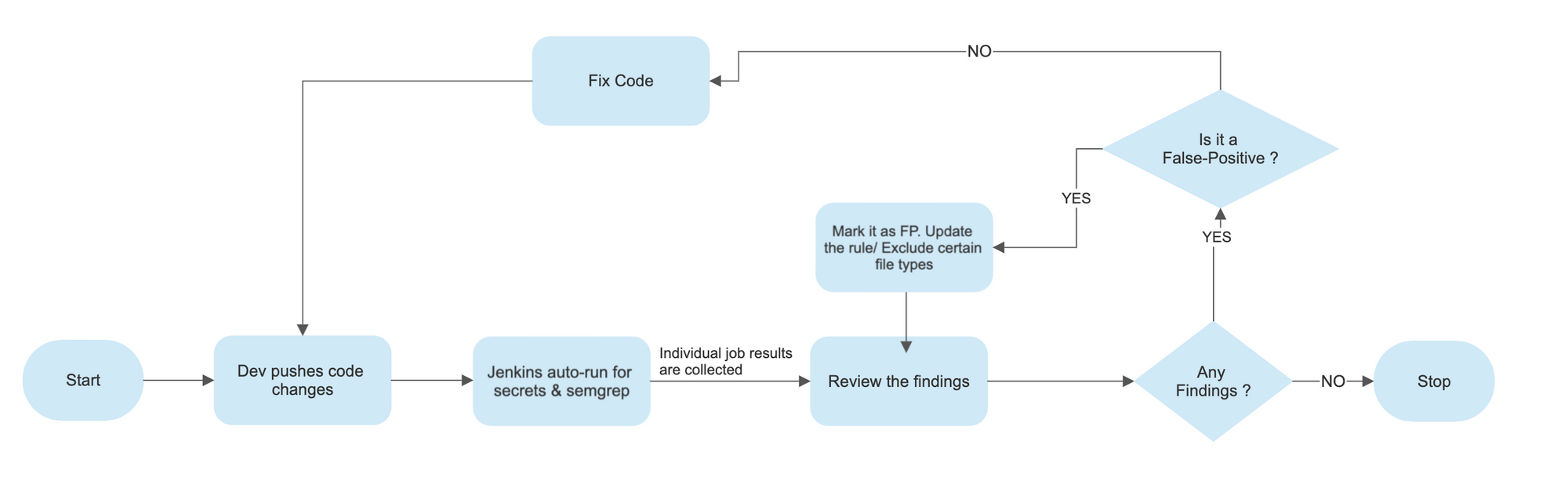
Benefits of using Semgrep at Halodoc
- Cost : Identifying vulnerabilities in production and addressing them is a risky affair, but with semgrep we are able to identify issues on severity basis and address early in the development cycle. The cost savings is seen over time
- CI/CD :Integration of semgrep as a stage into CI/CD pipeline on all our major builds helped us understand and segregate the codebase into languages and detect any ERROR rated vulnerabilities
- Secrets :Increased coverage for secrets in code beyond check-secrets, like usernames with custom names (username/password referred in objects and commonly used combinations of those variables)
- Custom rules : Semgrep offers writing own custom rules, which we are leveraging to detect beyond security vulnerabilities like identifying patterns for missing code standard in try-catch exceptions
- Vulnerabilities : Some benefits that can be fully leveraged are cross-platform support across languages (check scope below) and Early detection of critical vulnerabilities like SQL injection (check semgrep rules below) and other top OWASP vulnerabilities.
Shift left approach
Semgrep can be integrated into CI/CD pipeline, enabling us to scan code as soon as it is committed to the repository. This "shift left" approach to security and quality ensures that problems are discovered early on when they are simpler and less expensive to solve.
Here at Halodoc, we embrace Shift-left testing approach, below is our standard security testing process :
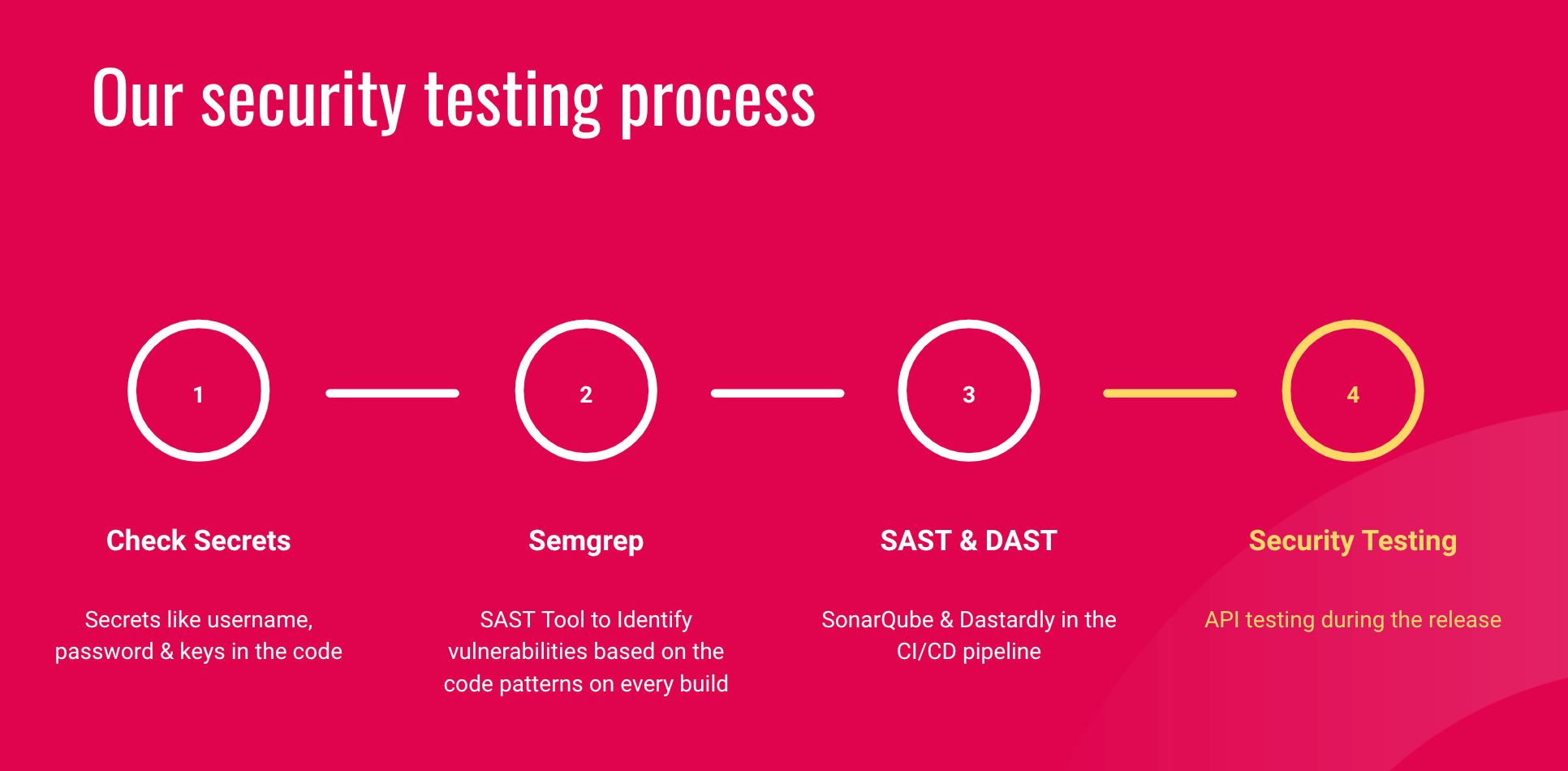
We are equipped with tools to identify the vulnerabilities using the shift-left methodology before the code is pushed to production. In a typical situation, these vulnerabilities will be discovered during security release testing, third-party testing, or bug bounty programmes. The low hanging fruit (across severity levels), dependency vulnerabilities, and coding standards enforcement will all be caught by having SAST in CI/CD pipeline.
How to setup Semgrep in CI/CD?
- Create an Amazon Elastic File System (EFS) cluster.
- Create a Jenkins agent pod in your Kubernetes cluster to act as a Jenkins slave.
- Configure the Jenkins agent pod to use Semgrep to scan your code for security vulnerabilities.
- Store all the Semgrep rules in a private gitlab repo and Jenkins web-hook to sync these rules to an Elastic File System (EFS), so that all Jenkins slave can access these rules without cloning it multiple times.
- Install semgrep-cli on all the Jenkins slave
- As part for CI/CD Jenkins pipeline stage, we run semgrep rules against the service code
semgrep --config=/etc/semgrep/semgrep-rules/ --json --exclude='*.ts' --exclude="template/plugins" --severity WARNING --severity ERROR -o temp.txt 
- We parse the report with `jq` to get only required information, then push this data to prometheus push-gateway
curl -s --data-binary @.finalSemGrepReport.json /metrics/job/semgrep-/instance/ - We have created the dashboard in garafana which can read the semgrep results from prometheus.
- The data is fed from Prometheus to the Grafana dashboard, where we have all security-related items in one spot (Semgrep report & many things from SCA like vulnerable service images, vulnerable services & kubernetes)
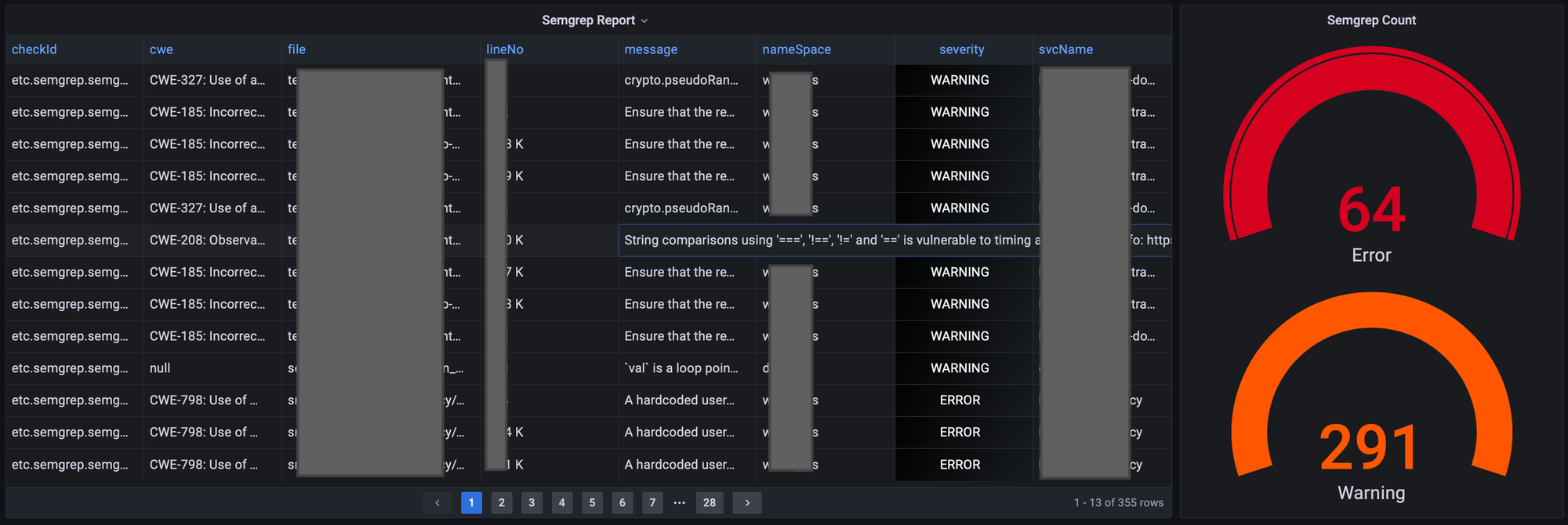
Throughout the blog, you'll find references of Semgrep detecting SQL injection vulnerabilities, Hardcoded usernames & passwords, misconfigured headers and enforcing code standards like the one in the above image. Most of these could not be found by any other process in the entire security testing process.
Semgrep Rules
Semgrep's rule library contains hundreds of pre-defined rules for detecting common coding mistakes and security issues. The rules cover a wide range of issues, including:
- SQL injection
- Cross-site scripting (XSS)
- Code quality issues (such as unused variables, unreachable code, and more)
- Security misconfigurations
- Hardcoded secrets and credentials
We can also create own custom rules to suit specific needs. Semgrep rules are written in YAML and can be easily shared and reused.
This is a custom rule to detect hardcoded secrets in your JS files (far improved version than the default rule Semgrep)
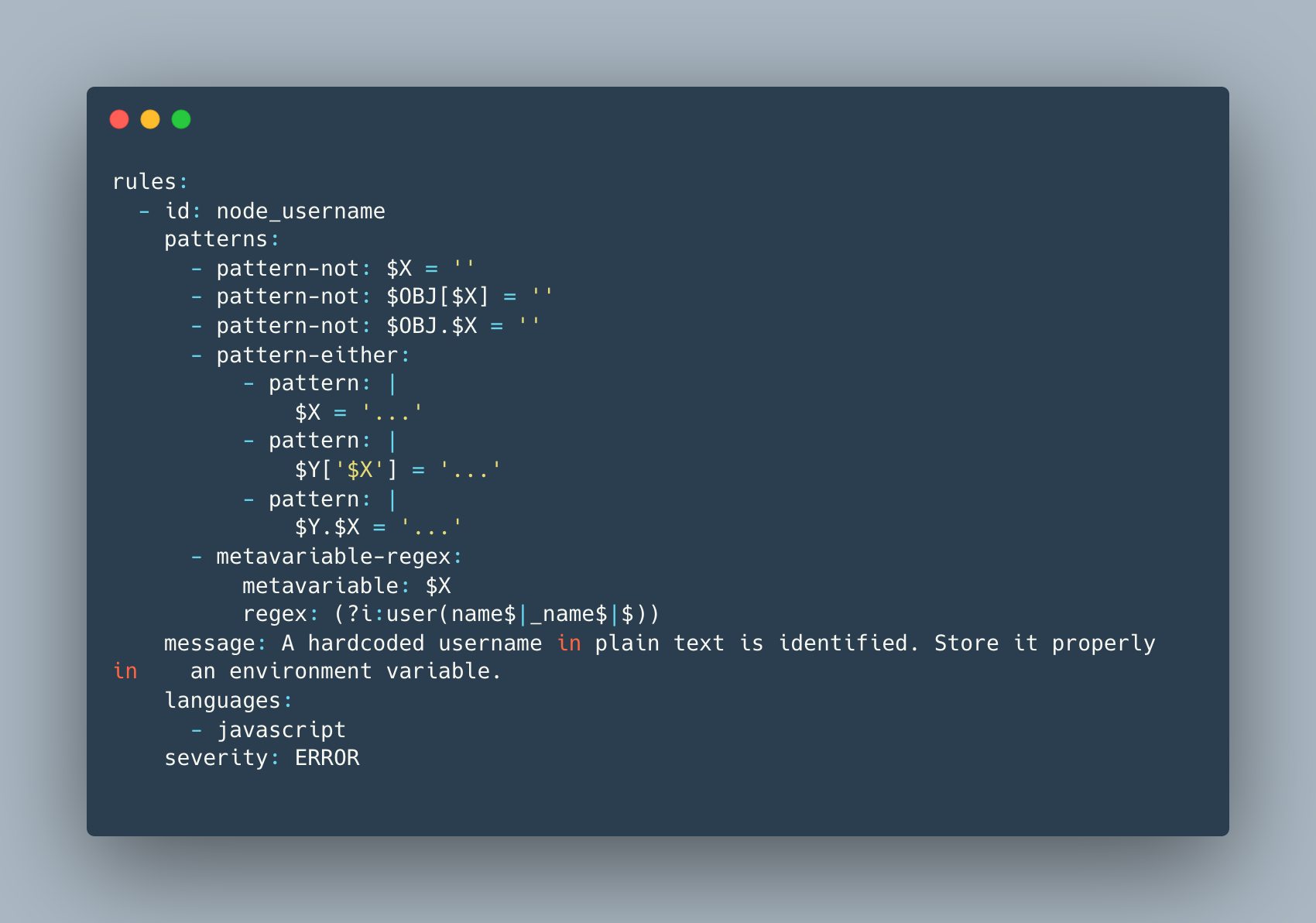
Major improvements we did to reduce false positives are :
- Use variables instead of hardcoded names (this eliminates case sensitivity)
- Avoid empty set with this addition <Pattern-not: $X=''>
- Include all patterns of assignment ( variable, array, object )
- Use of metavariable regex to end with user, username, user_name (to avoid other variables with 'user' in their name)
We have enhanced many other rules along the way, Semgrep offers custom rules for enterprise customers at a price, but if you'd want to construct your own rules, one can develop better rules for Top 10 OWASP vulnerabilities like Insecure Direct Object Reference (IDOR) & SQL Injection and Cross-Site Scripting (XSS) endpoints.
Let's look at one such vulnerability that was found through Semgrep rules, i.e, SQL Injection.
Here is a SQL injection vulnerability we found with refined rules where a prepared statement was missing.
Vulnerable Code : Look at the line 133 where a Query is executed without prepared statements which is vulnerable for SQL injection.
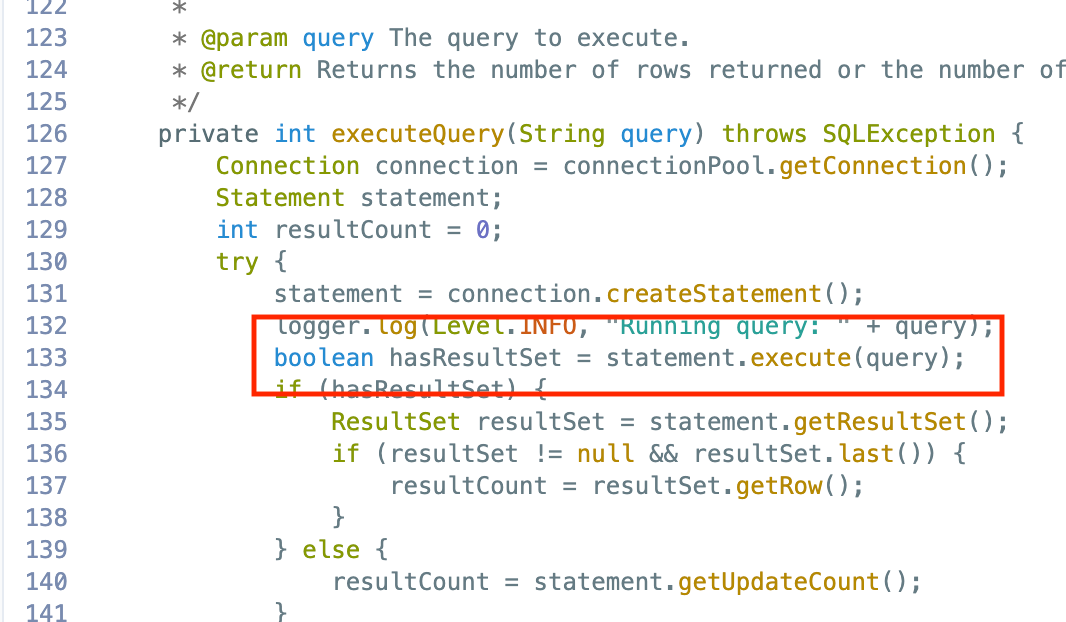
You can see that Semgrep caught the above vulnerable code in stage. Now, this will be fixed, before the code is pushed to production.
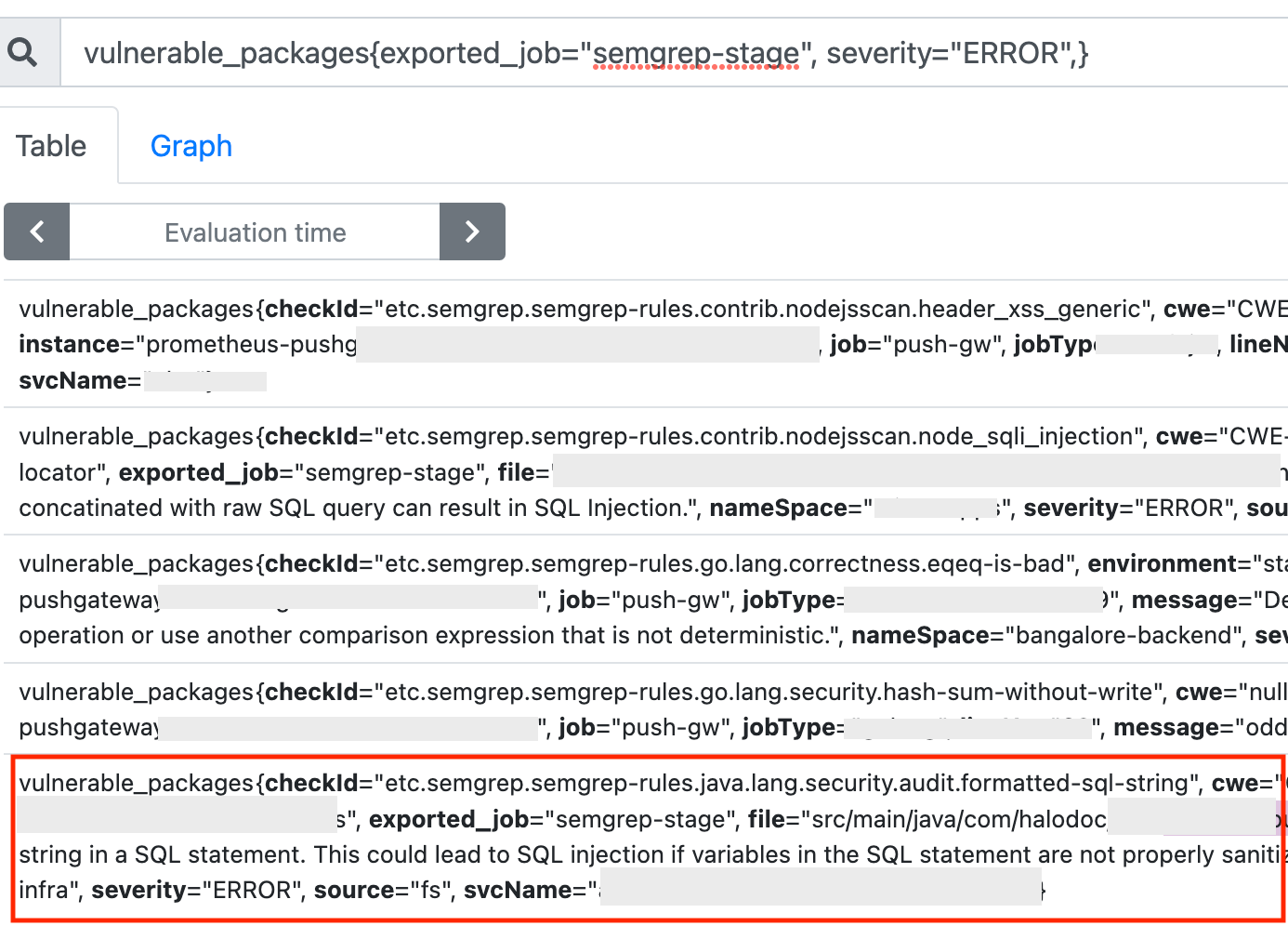
Scope
Semgrep can be used to scan a variety of codebases, including
- Python
- Java
- JavaScript
- Go
- PHP
- Typescript
It can also be used to scan cloud infrastructure code, including
- Kubernetes
- Terraform
This makes Semgrep a versatile tool that can be used in a variety of development environments.
Tuning and Maintenance, Every good thing has a catch !
Semgrep, like any static analysis tool, might produce false positive results (i.e., findings that are not issues). Semgrep should be adjusted to your particular codebase and requirements in order to reduce false positives. You can achieve this by modifying the rules' severity levels, disregarding particular files or directories, and fine-tuning rules to minimise false positives.
By upgrading its rule library and keeping an eye out for new releases, Semgrep must likewise be continuously maintained. Semgrep's rule library is continually being updated, and these upgrades could include new rules or make old rules better. We adhere to the following:
Narrow the Scope of Analysis
To exclude specific code paths or files

- We have excluded third party client-side libraries and reduce the noise with the exclusion
--exclude="template/plugins" - Also, we have excluded unit test files generated with AngularJS which result in huge noise
--exclude='*.ts'
These two alone reduced a huge noise to signal in the findings (around 2k entries)
Fine-tune the Rules

This is a comparison of how we adjusted the rulesets for hardcoded credentials. The irony is that the legacy rule has hardcoded patterns to detect credentials that have been hardcoded and we have moved away from hardcoding and implemented variables and used metavariable-regex to cover all possible username combinations used. Similar approach is used for hardcoded passwords.
Note : There are some limitations with Semgrep like, no solution to separate front-end & back-end Javascript for JS rules, only stringent rules are the way.
Another way to reduce false positives is to improve the rules. A sizeable number of rules are included with Semgrep out of the box, although not all of them may be appropriate to your project. By adapting the rules to the particular needs of your project, you can reduce the number of false positives.
Verify False Positives Manually
Finally, if you still encounter false positives even after taking the above steps, you can manually review and verify them. This can be time-consuming, but it is often the most effective way to ensure that Semgrep is not flagging code as vulnerable when it is not.
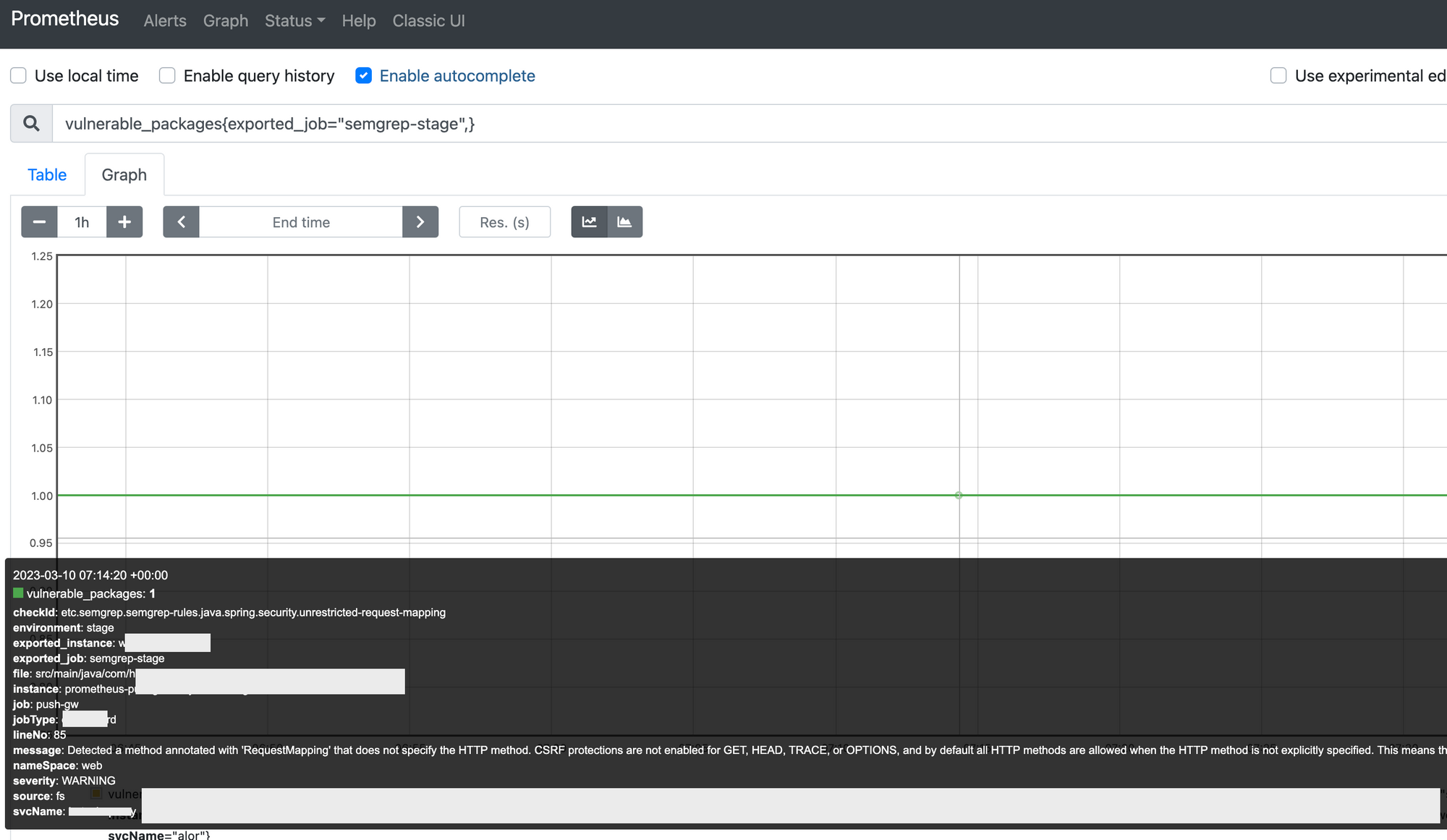
If you are using the above mentioned setup, You can query based on environment, service name and also by rule to narrow down the findings and streamline them in prometheus for verifying manually. Also, look for new findings based on time intervals.
Conclusion
Automating code analysis with Semgrep in Jenkins can help to streamline code reviews and catch bugs early in the development process. By setting up Semgrep in Jenkins, you can automate the process of running code analysis and generate reports of any issues found. This can save time and effort in manual code reviews, as well as improve code quality by catching issues before they make it into production. With the Semgrep plugin for Jenkins, you can easily integrate Semgrep into your development workflow and start automating your code analysis today.
Join Us
Scalability, reliability, and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com
About Halodoc
Halodoc is the number 1 all around Healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. We recently closed our Series C round and In total have raised around USD$180 million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalized for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


