
Smooth MFE Deployments: Tackling Downtime of Breaking Changes
In today's digital landscape, websites are no longer just static collections of web pages. They are dynamic platforms designed to deliver information, services, and functionality to users seamlessly over the internet. At Halodoc, we've adopted a modern approach to frontend development by leveraging Micro Frontends (MFEs).
Introduction: Understanding MFE Deployment Challenges
MFEs break down the frontend into smaller, independently deployable modules. This architecture enhances scalability and flexibility, allowing teams to work on different components independently while maintaining a cohesive user experience. Although MFEs are integrated into the website, they function as separate services, enabling faster iterations and streamlined deployments. Unlike monolithic applications, MFEs introduce complexities related to versioning, compatibility, and deployment strategies.
- Synchronised Deployment – Ensuring smooth rollouts without downtime requires a well-planned deployment process, especially when multiple services interact.
- Traffic Routing & Caching – Serving the correct version of an MFE while handling cache invalidation in a distributed system like AWS CloudFront requires careful planning.
To address these challenges, we need a robust deployment strategy that minimises risk while ensuring seamless updates. Let’s explore how we achieve this with version management and automated CI/CD pipelines.
At Halodoc, we have two interconnected projects that form the backbone of our website:
- Website: This handles both static and dynamic content. It uses a NodeJs server to manage dynamic requests.
- Micro Frontends: This project is dedicated to serving static content through Amazon S3, ensuring high availability and reliability for assets like images and JavaScript files.
This dual-architecture, with a Content Server for dynamic processing and a Static Content Hub for asset delivery, is designed for scalability and performance. It ensures reliable operation, making it ideal for high-traffic applications that require efficient and sophisticated infrastructure.
Breaking Changes & Downtime: Why Do They Happen?
Breaking changes arise when updates aren’t aligned properly. Major updates (e.g., updating angular versions) can introduce changes that break existing implementations. Partial rollouts may cause users to see inconsistent behaviour. An older server-side rendering setup is incompatible with the updated frontend framework leads to blank pages.
Our Initial Deployment Approach & Its Shortcomings
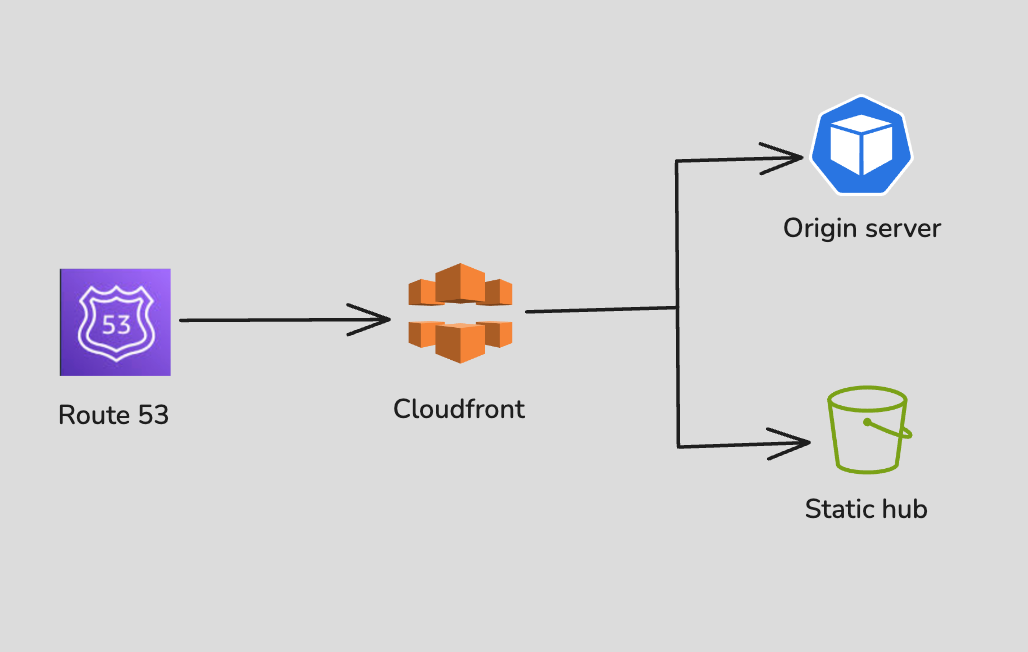
Initially, our setup had a single running version of the application. When a user made a request, it followed this flow,
1. The user accesses and the request is routed through Route 53, which resolves the domain name to its corresponding CloudFront distribution.
2. CloudFront receives the request and determines how to handle it based on its caching and routing rules.
3. CloudFront forwards the request to the specified origin, configured in its behaviours (e.g., an S3 bucket or an application server) based on the requested path.
4. The origin server processes the request, and the response is sent back through CloudFront to the user, benefiting from caching and optimised delivery.
The shortcomings? Both the server and MFE had to be deployed together or in quick succession. If one was updated before the other, it could lead to broken functionality or inconsistencies. This approach lacked flexibility and increased deployment risks.
For minor updates like bug fixes or backward-compatible changes, there’s no downtime since the new version can be deployed without disrupting the existing setup. However, during major upgrades—such as Angular migrations or breaking changes—compatibility issues arise if the Server and MFE are not upgraded together.
Impact of Interdependent Service Mismatches:
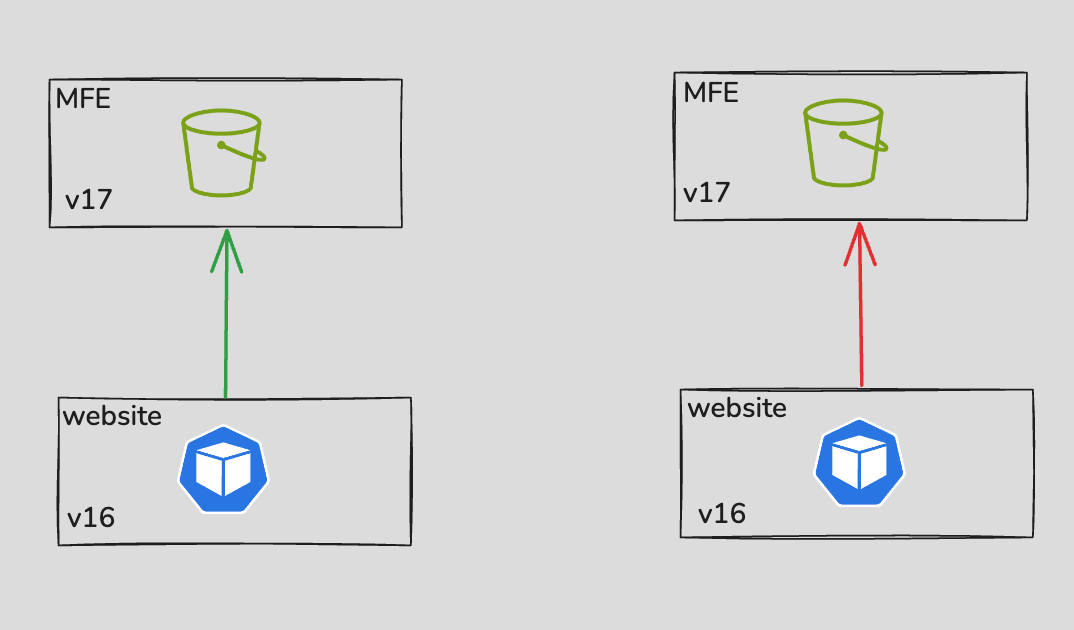
- API mismatches: The server might try to send a request to MFE that's a version too ahead.
- Breaking changes: The MFE, now on Angular v17, may not support features or structures expected by the server running Angular v16.
- User impact: If requests go haywire, users might see broken pages or chaos — like trying to use a vending machine that keeps giving the wrong snack.
Real world Implications:
In high-traffic applications like Halodoc, where users depend on a seamless experience, such breaking changes can have significant consequences, including:
- Downtime or Errors: Pages might refuse to load or show up with random glitches.
- Negative User Experience: Users experiencing errors will probably exit faster than a dropped Wi-Fi signal.
- Rollback Complexity: Reverting to a previous version mid-deployment can introduce additional risks.
Key Strategies to Prevent Downtime in MFE Deployments
Maintain two environments to switch traffic seamlessly and avoid downtime. Version Tracking - Store and manage current versions in a dedicated config file to ensure compatibility. Gradual traffic shifting allows safe rollouts by directing a small percentage of users to the new version before full deployment. Robust monitoring and alerts help detect failures early, while CI/CD automation streamlines deployments, reducing manual errors and ensuring a smooth, reliable process
Version Management: Handling Breaking Changes Efficiently
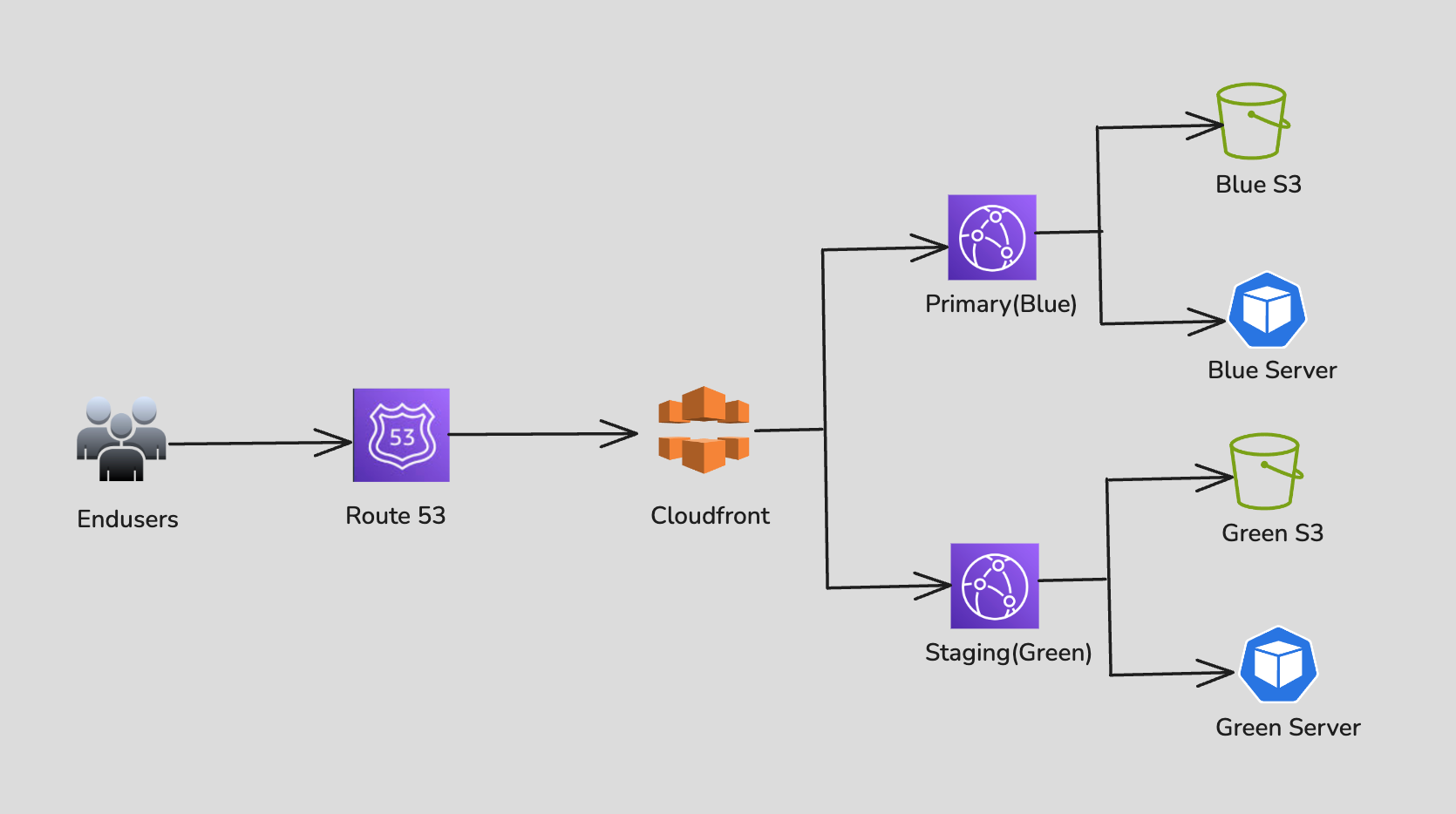
We track the current versions of the server and MFEs in blue and green environments using a configuration file. Semantic versioning (x.y.z) helps distinguish between major, minor, and patch updates. We have implemented a deployment pipeline that triggers specific workflows based on the type of version being deployed, ensuring efficient version management and release processes. The version details are maintained in the package.json file, which allows us to manage and control deployments effectively.
CloudFront Setup:
- Primary distribution(Blue): Blue S3 bucket and Blue Node server.
- Staging distribution(Green): Green S3 bucket and Green Node server.
Similarly, on the server side, we maintain separate blue and green environments. We maintain a configuration file in a dedicated S3 bucket to store the current version of both the server and MFE in the blue and green environments.
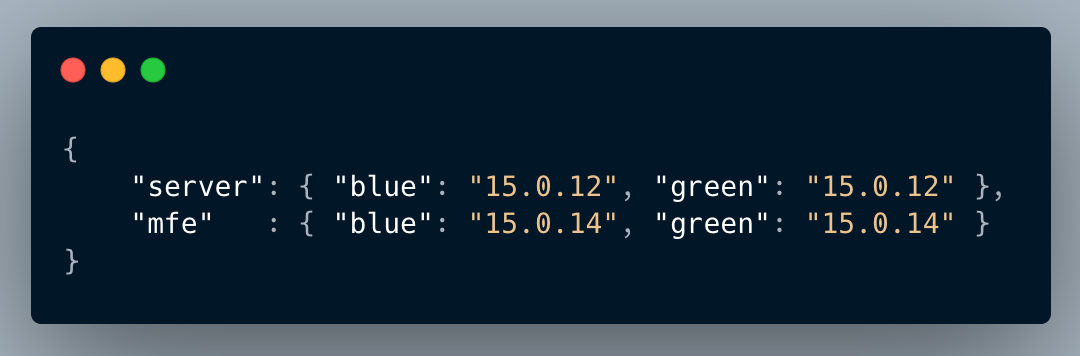
This allows us to make informed decisions in the deployment pipeline, such as determining whether routing should be enabled based on the version being deployed. This setup helps track versioning and facilitates controlled deployment and routing decisions. We have also implemented measures to handle edge cases, such as ensuring that during major version deployments, both services (Server and MFE) are fully deployed to the green environment before promotion.
Canary Releases: Deploying Safely with Minimal Risk
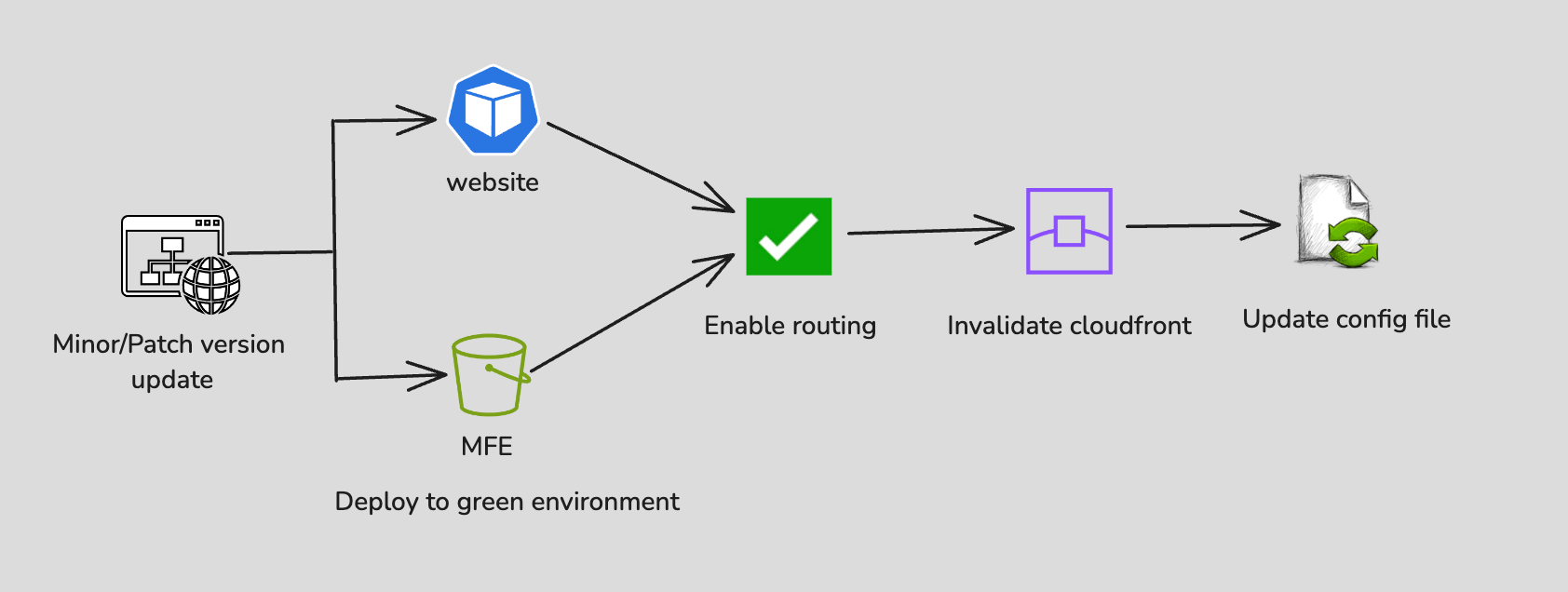
Minor/Patch Versions: Each time the project pipeline runs, it deploys exclusively to the green environment and enables routing, avoiding direct deployments to blue.
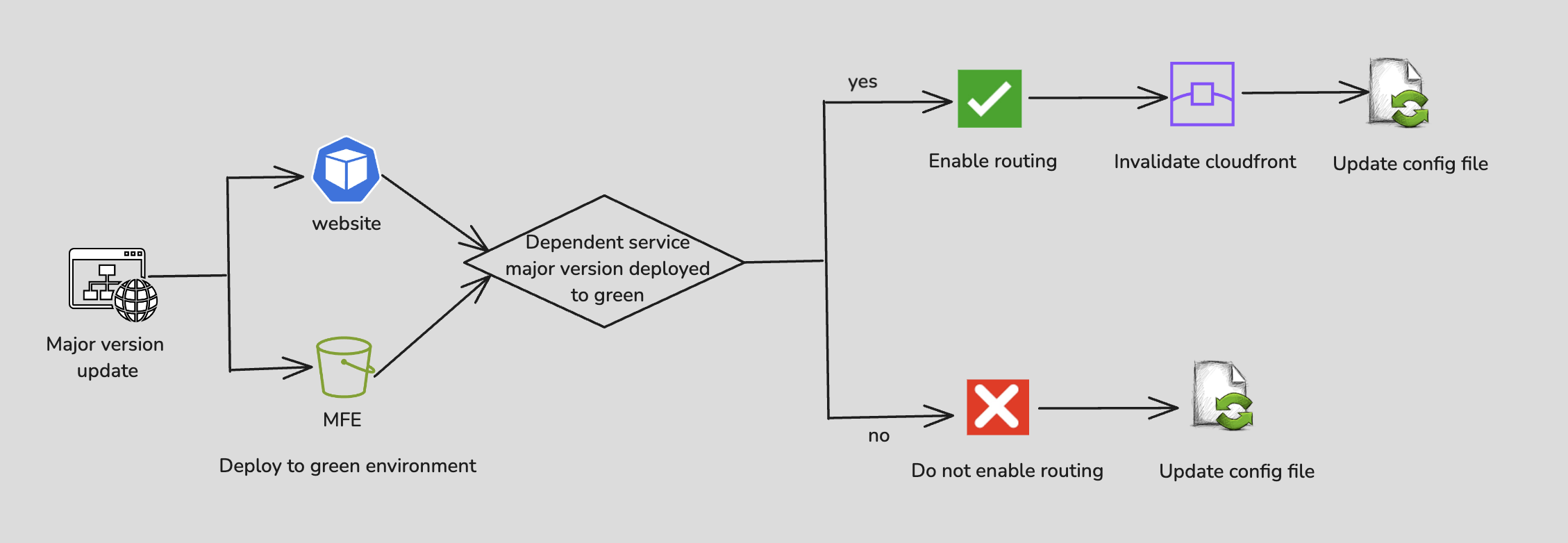
Major Versions: Each time the project pipeline runs, it deploys to the green environment. Verify if the dependent service is deployed with a major version by checking the config file. If yes, enable routing. If not, do not enable routing.
The promotion to blue involves copying all artefacts from the green S3 bucket to the blue S3 bucket, ensuring consistency across environments. Additionally, the server-side deployment is updated to route 100% of traffic to the blue environment.
CI/CD Enhancements: Automating Deployment Checks
The Rollout Process: Step by Step
- Pipeline Magic: The moment a developer commits to Git, our pipeline kicks off, configuring and syncing the green environment for action. It builds the code, runs checks, pushes docker image to ECR, and syncs build artefacts to the green S3 bucket — basically packing everything in a suitcase, ready for travel.

- Minor/Patch Updates: The green environment will be updated with the latest changes, routing is enabled, CloudFront invalidation clears outdated cached content, ensuring users get the latest updates and the config file is updated like a checklist — all checked off.
- Major Updates: Here, we’re a little more cautious, checking if dependent service is updated before allowing traffic. Think of it as making sure your teammates are on the same page before launching the big change.
The Promotion Process: Taking the Plunge
Now, everything’s ready in green, and it’s time to promote the changes to blue. The developer initiates the promotion job by specifying which service to promote. Here’s how it goes:
- Minor/Patch version Promotion: The green image tag is copied to blue and update blue traffic to 100 percent, and voilà — traffic is now routed to the blue environment. We copy all artefacts to the blue S3 bucket. We disable the staging distribution, finalising the transition.
- Major version Promotion: For major updates, we promote both the server and MFE simultaneously to ensure zero downtime. No one likes interruptions, right?

Cache Invalidation: Ensuring Users Get the Latest Updates
Cache invalidation ensures users always receive the latest updates by preventing outdated content from being served. CloudFront invalidation clears cached files, allowing new versions to be displayed immediately after deployment. Automating this process eliminates manual effort and reduces the risk of stale content.
Best Practices for Seamless MFE Deployments
For seamless MFE deployments, it’s important to maintain strict version control and use semantic versioning to track changes. Implementing version management strategies minimises downtime by allowing traffic to be switched between environments effortlessly. Automated CI/CD pipelines streamline the deployment process and ensures consistency. Utilising CloudFront cache invalidation guarantees users see the latest updates instantly. Finally, fostering a culture of cross-team collaboration ensures server and MFE updates are synchronised, reducing deployment risks and enhancing stability.
Conclusion: Achieving Reliable, Downtime-Free MFE Deployments
Every change takes a test drive in the green environment first, so we catch issues before they cause chaos ensuring reliability. No nasty surprises, just smooth sailing! Traffic? It hops over to blue without a hitch, no interruptions, just uninterrupted browsing. Static and dynamic content run in their own lanes, so we can scale and optimise without stepping on each other’s toes.
By implementing a version based deployment strategy, we have successfully streamlined the deployment process and ensured no disruption during updates. This setup enhances user experience by ensuring zero downtime and eliminating manual intervention. Improved users experience, even during major updates, thanks to the smooth transitions between environments. Additionally, identifying bugs early with less traffic minimises risks. The result? A more reliable and efficient infrastructure management system that enables faster, safer deployments. With reduced risks and a streamlined workflow, our deployment process has become more predictable, improving the overall efficiency.
References :
Join Us
Scalability, reliability, and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels and if solving hard problems with challenging requirements is your forte, please reach out to us with your resumé at careers.india@halodoc.com.
About Halodoc
Halodoc is the number one all-around healthcare application in Indonesia. Our mission is to simplify and bring quality healthcare across Indonesia, from Sabang to Merauke. We connect 20,000+ doctors with patients in need through our Tele-consultation service. We partner with 3500+ pharmacies in 100+ cities to bring medicine to your doorstep. We've also partnered with Indonesia's largest lab provider to provide lab home services, and to top it off we have recently launched a premium appointment service that partners with 500+ hospitals that allow patients to book a doctor appointment inside our application. We are extremely fortunate to be trusted by our investors, such as the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. We recently closed our Series D round and in total have raised around USD$100+ million for our mission. Our team works tirelessly to make sure that we create the best healthcare solution personalised for all of our patient's needs, and are continuously on a path to simplify healthcare for Indonesia.


