

A practical guide to scalable pagination: Offset, Keyset and Beyond
In any large-scale application, efficient pagination plays a critical role in ensuring both system performance and a smooth user experience. As data volume increases, fetching all records at once becomes impractical — making pagination a foundational component, not just a UI enhancement. It directly impacts query execution, backend load, and API responsiveness.
At Halodoc, the continuous growth of data and evolving access patterns highlighted the limitations of a one-size-fits-all approach to pagination. To meet these demands, we redesigned our pagination architecture to support flexible, strategy-driven solutions. In this post, we walk through how to choose the right pagination strategy for varied use cases, and how we standardised the logic using a factory-based design to ensure consistency, scalability, and maintainability across systems.
Why Pagination is Critical in High-Scale, Data-Heavy Systems
- Limits frontend memory and rendering load, enabling smooth scroll and fast interactions even with large datasets.
- Serves only recent or relevant data instead of overwhelming the interface with unnecessary records.
- Mitigates unbounded data access by constraining fetch size, ensuring predictable query performance, preventing memory spikes, and minimising risk to core backend systems under load.
Choosing the Right Pagination Strategy: Offset, Keyset and Exclusion
To build a unified and scalable pagination system at Halodoc, we analysed our varied use cases and identified three core pagination strategies: Offset, Keyset, and Exclusion. Below is a breakdown of each strategy covering when to use it, how it works, and best practices to follow.
Offset-Based Pagination: Easy to Implement, Challenging at Scale
When to Use:
Best suited for small datasets, admin panels, or any interface requiring direct access to arbitrary pages (e.g., Page 10, Page 20). It’s easy to implement using page numbers and supports jump-to-page functionality.
How it Works:
The client sends a page number, which is converted to an offset using (page_no - 1) * per_page. The database skips that many rows and returns the next set using LIMIT. Simple to implement, but performance degrades with higher offsets.

Recommended Practices:
- In common practice, total records are fetched to check if a next page exists, but this adds an extra DB call. Instead, fetch one extra record and use it to set a
has_nextflag to indicate if the next page is available. - Enforce a maximum limit (e.g., limit <= 100) at the API level to prevent over-fetching and reduce query load.
- Introduce lazy loading of total counts — only compute them when explicitly requested (e.g., when the user scrolls to the end or asks for total pages).
- Archive historical data or partition tables to reduce index size and improve query speed.
Keyset-Based Pagination: Fast, Stable, Live-Ready
When to Use:
Ideal for large or frequently updated datasets — such as live feeds, transaction logs, or orders — where performance and consistency matter more than jumping to an exact page number.
How it Works:
Keyset pagination uses a stable sort key (e.g., created_at, id) to fetch the next set of results relative to the last item retrieved, instead of skipping rows.

Here, created_at acts as the cursor — only rows after the given value are returned. This makes the query index-friendly and consistent even if new rows are inserted during pagination.
Recommended Practices:
- Choose a sort key that’s indexed and ideally unique (e.g.,
(created_at, id)) to maintain deterministic ordering. - Encode cursors as opaque strings (e.g., Base64-encoded JSON) to protect internal metadata and support stateless APIs.
- For bidirectional navigation (next/previous), maintain both forward and reverse cursor logic in your backend.
Exclusion-Based Pagination: When Duplicates Are a Problem
When to Use:
Ideal for aggregated representations of data pulled from multiple systems — where primary keys might clash and default sorting is unreliable.
How it Works:
Instead of relying on sort keys or OFFSET, this strategy tracks already seen record IDs and excludes them in subsequent queries.

This strategy tracks already returned IDs on the client or server side and excludes them in future queries, ensuring no duplicates are returned.
Recommended Practices:
- Limit the number of excluded IDs to a practical window (e.g., last 100–200) to keep query size under control.
- Use this only when keyset-based pagination isn't reliable (e.g., multiple sources with conflicting timestamps).
- If records come from multiple sources, ensure duplicates are filtered out server-side before storing excluded IDs, so only unique records are paginated and excluded in the next query.
Offset vs. Keyset vs. Exclusion: Summary Breakdown
| Feature | Offset-Based | Keyset-Based | Exclusion-Based |
|---|---|---|---|
| Pagination Logic | Skip N rows using OFFSET |
Fetch rows using a stable sort key (<, >) |
Exclude already fetched rows using NOT IN |
| Performance at Scale | Degrades with higher offsets | Remains constant with proper indexes | Slows down with large exclusion lists |
| Handling Data Mutations | Prone to duplicates/missing entries on inserts/deletes | Stable across data changes due to value-based cursor | Safe if excluded IDs are tracked correctly |
| Supports Jump to Page | Yes (e.g., page 10) | No (only sequential forward/backward) | No (cursor-based forward only) |
| Cursor Complexity | Simple page number | Encoded sort key + direction | List of excluded IDs |
| Index Usage | May ignore index at high offsets | Leverages indexes efficiently | Index on id required for efficient exclusion |
| State Management | Stateless on server | Stateless (with cursor) | Stateful — exclusion list must be tracked or encoded |
| Implementation Complexity | Easiest to implement | Moderate — requires encoded cursors and sort key guarantees | Higher — managing and persisting exclusion IDs |
| Ideal Use Case | Admin dashboards, exports, small data lists | Real-time feeds, timelines, high-throughput APIs | Infinite scroll, merged datasets without consistent ordering |
Extensible Pagination Architecture Using the Strategy Pattern
With clear guidance on when and how to use each pagination type, the next challenge was ensuring these strategies could be adopted consistently across services. This led us to design a clean, extensible framework using the Strategy Pattern.
This section walks through the key components of our implementation — from the shared interface to concrete strategy classes and the factory-based resolver.
Here’s a quick overview of how strategy selection works in our architecture:
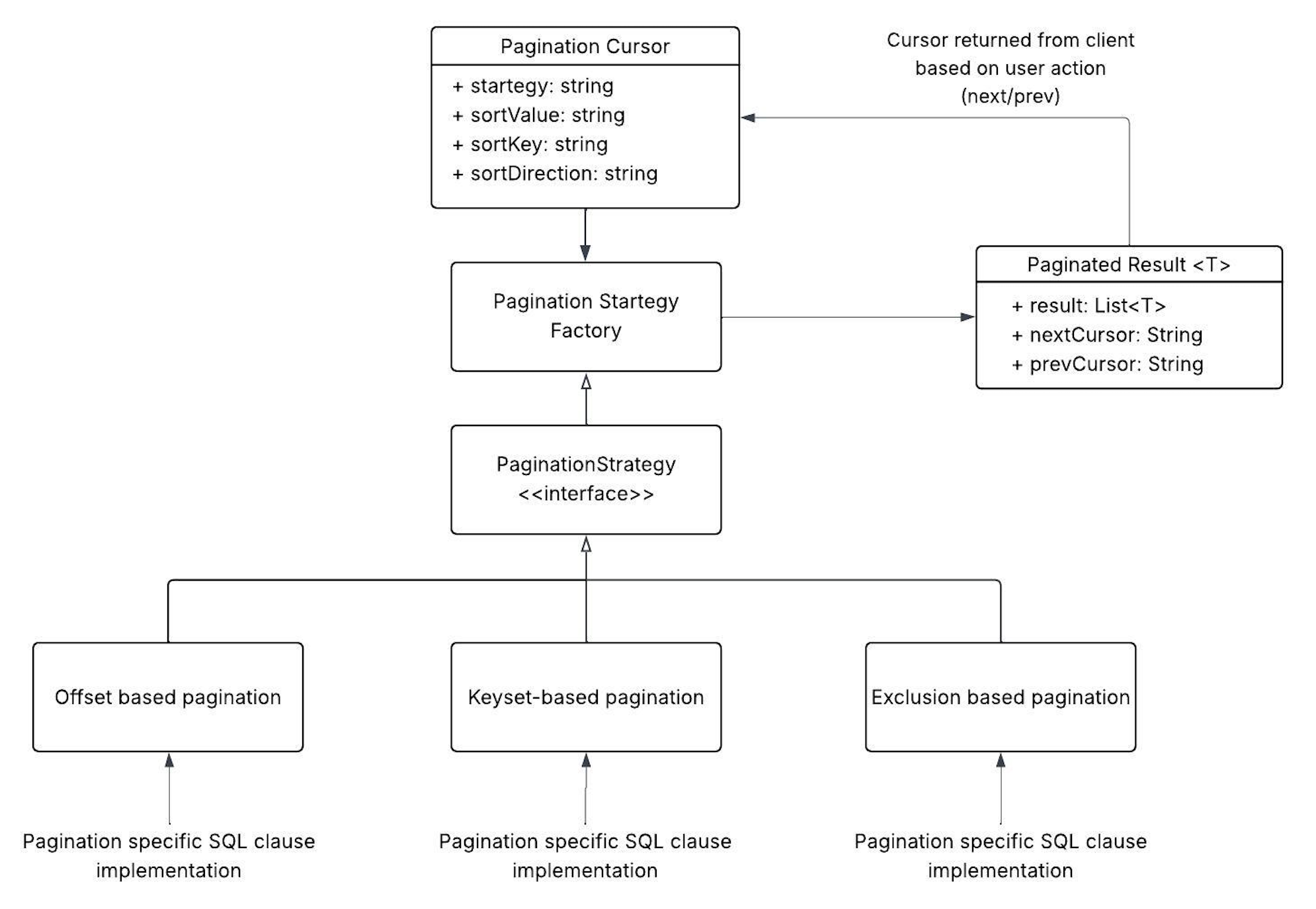
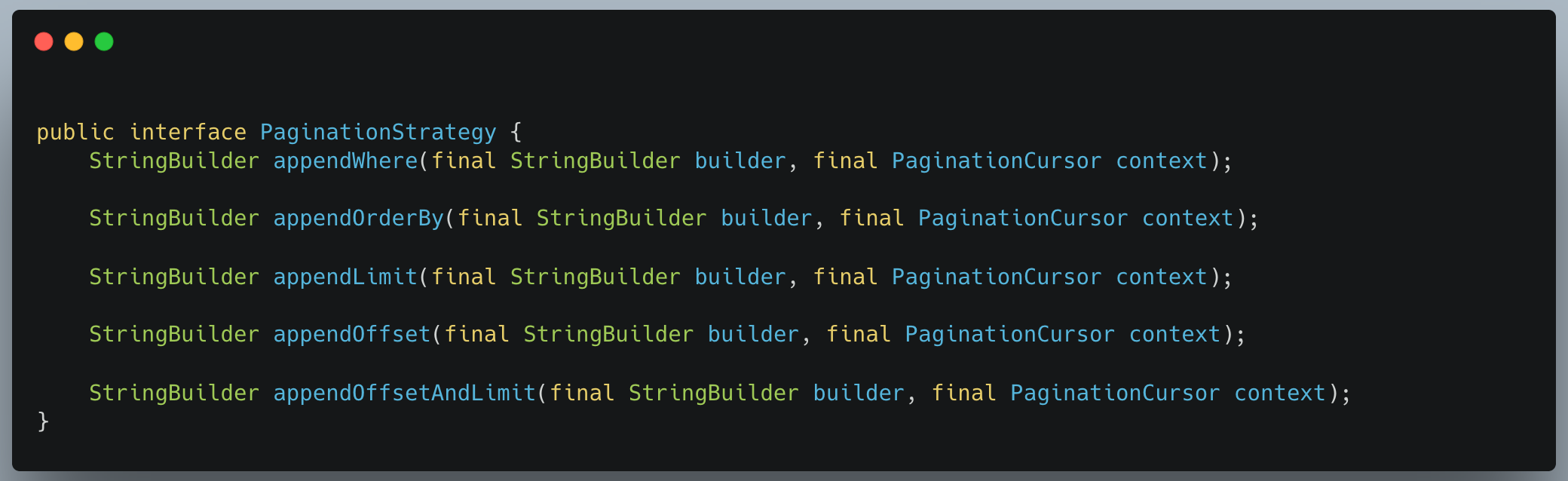
- Core Interface: All pagination strategies implement a common interface that defines methods for generating SQL fragments like
WHERE,ORDER BY, andLIMIT.
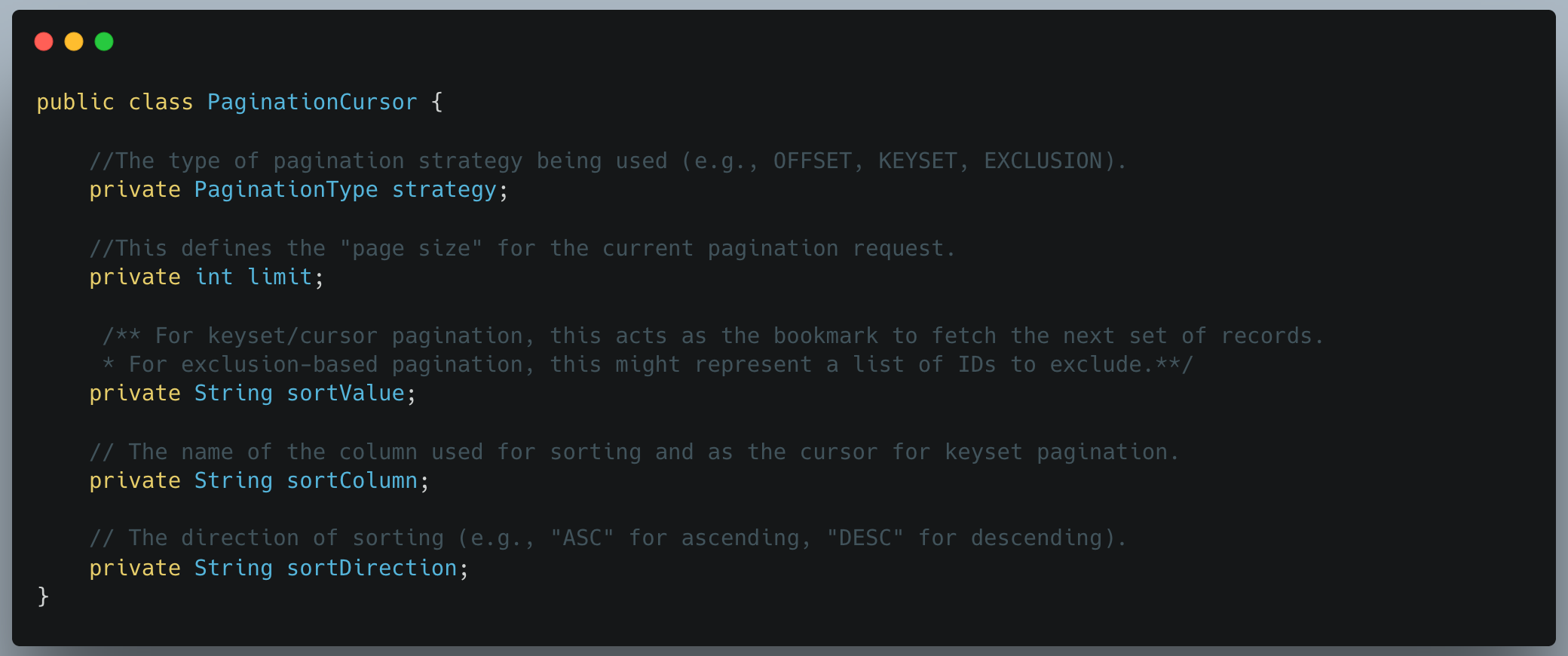
- PaginationCursor: Stateless Context Carrier: Pagination state is stored in a
PaginationCursor, which includes the strategy type, limit, sort key, and direction. This keeps the API stateless while allowing flexible reconstruction of pagination context per request.
The strategy resolver parses the cursor metadata and returns the appropriate implementation.
- Strategy Implementations: We use a
PaginationStrategyFactoryto dynamically select the right strategy at runtime, keeping the API code clean and reusable.
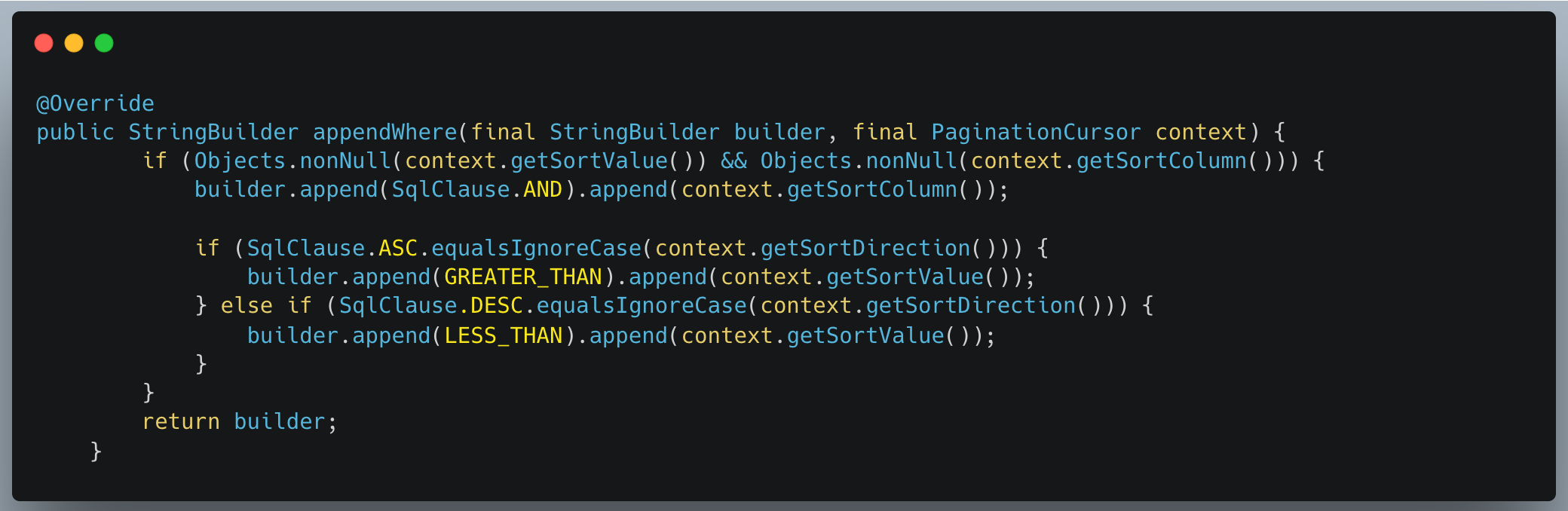
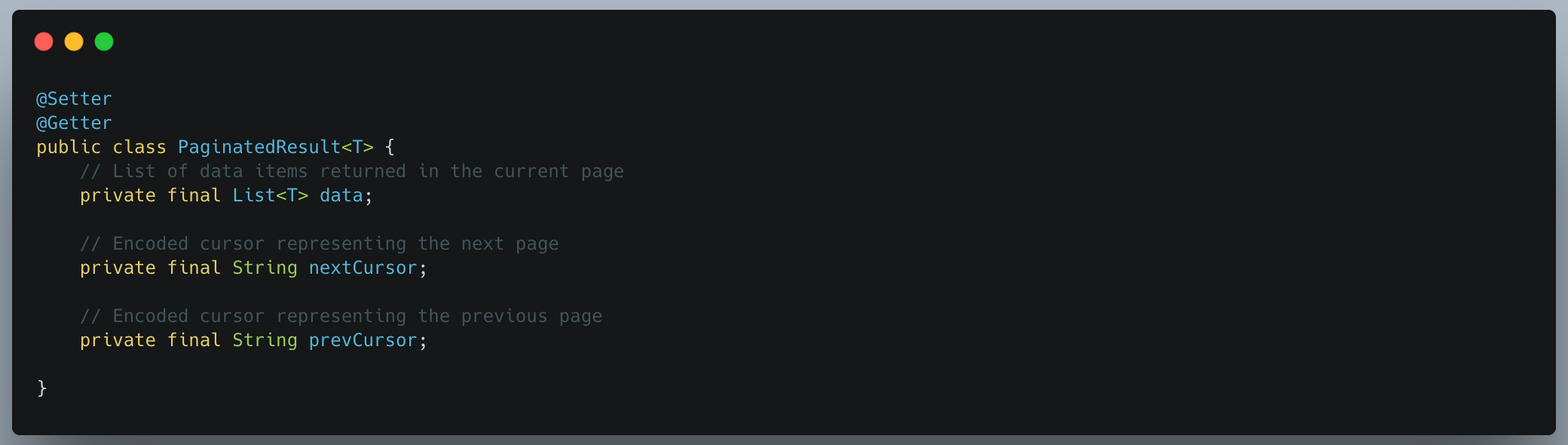
WHERE clause in KeysetBasedPaginationStrategy- PaginatedResult: To support cursor-based navigation in both directions, the paginated query result is wrapped in a PaginatedResult<T> class rather than returning just a list.This wrapper includes: data, nextCursor and prevCursor.
Result and Impact
This approach yielded tangible benefits across performance, scalability, and developer velocity:
- Performance Gains: High-traffic API latencies dropped by over 60% by avoiding inefficient
OFFSETand full count queries. - Infrastructure Efficiency: Database query load reduced by 20% and CPU utilisation improved by 30%, enabling better scalability as data volumes grow.
- Developer Experience: The plug-and-play framework lets teams implement appropriate pagination strategies with minimal effort and no code duplication.
- User Experience: End users now see smoother infinite scrolls, more consistent results, and improved responsiveness even under heavy data churn.
We validated these improvements through New Relic, which clearly reflected reduced response times and improved throughput across high-traffic APIs, as shown below:
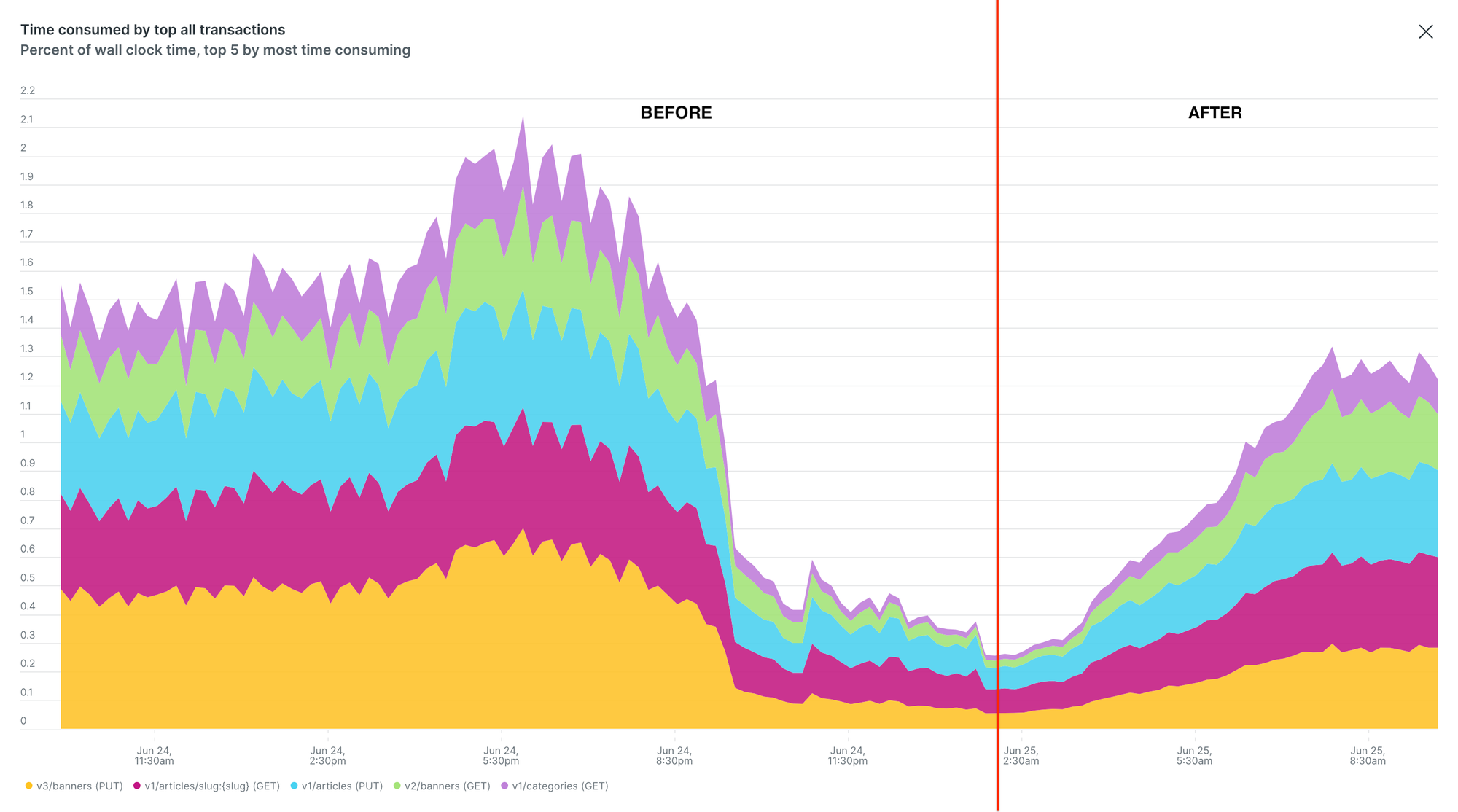
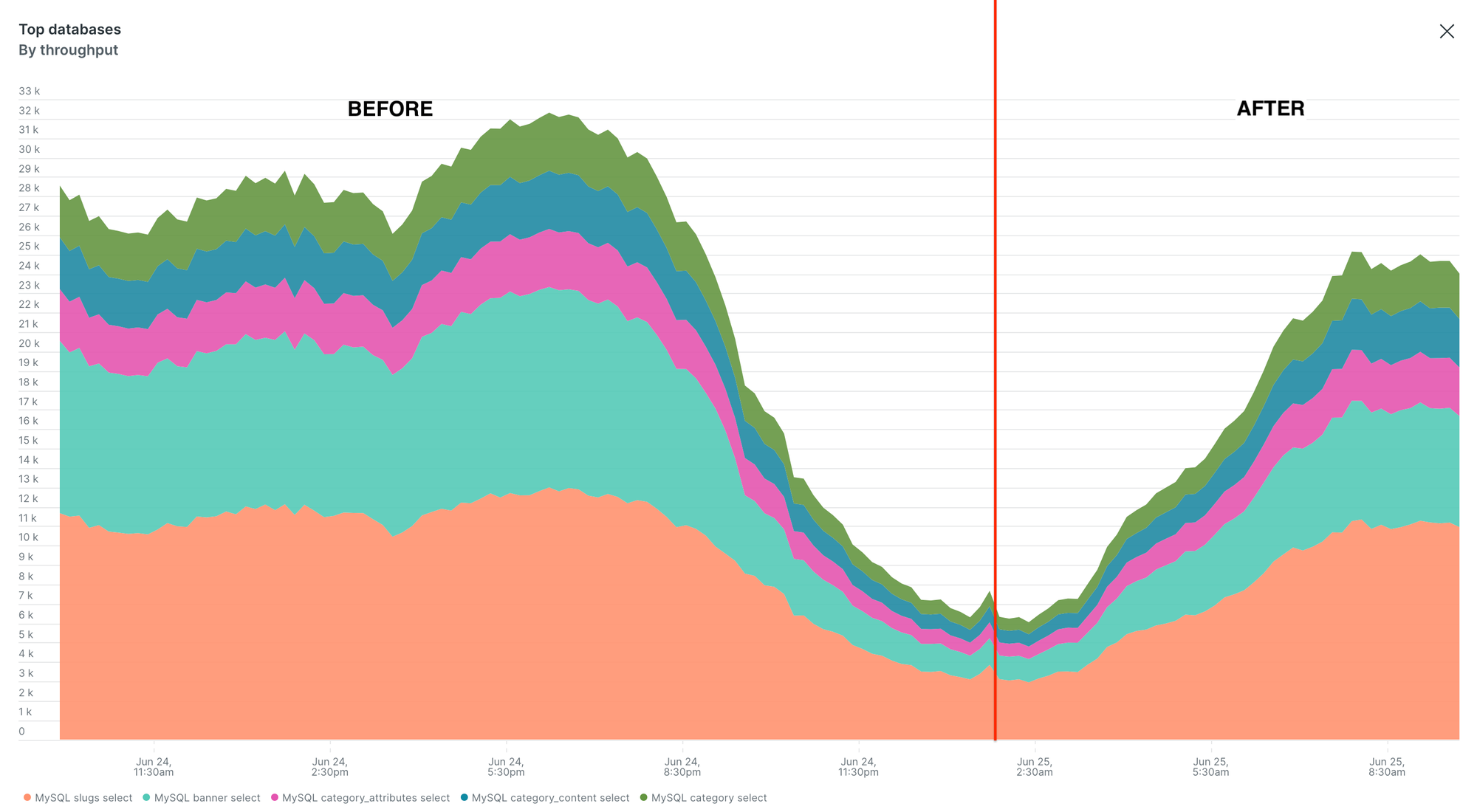
Pagination Improvement Led to Faster Transactions, Fewer Database Calls, and Better Throughput
Conclusion
With efficient query patterns, use of the strategy pattern, and alignment with real-world use cases, systems can achieve better performance, reduced duplication, and consistent pagination across services. This results in faster development cycles, more predictable behaviour at scale, and a smoother experience for both internal users and external clients. These patterns also make it easier to maintain and scale pagination logic as requirements evolve.
Join us
Scalability, reliability, and maintainability are the three pillars that govern what we build at Halodoc Tech. We are actively looking for engineers at all levels, and if solving hard problems with challenging requirements is your forte, please reach out to us with your resume at careers.india@halodoc.com.
About Halodoc
Halodoc is the number one all-around healthcare application in Indonesia. Our mission is to simplify and deliver quality healthcare across Indonesia, from Sabang to Merauke.
Since 2016, Halodoc has been improving health literacy in Indonesia by providing user-friendly healthcare communication, education, and information (KIE). In parallel, our ecosystem has expanded to offer a range of services that facilitate convenient access to healthcare, starting with Homecare by Halodoc as a preventive care feature that allows users to conduct health tests privately and securely from the comfort of their homes; My Insurance, which allows users to access the benefits of cashless outpatient services in a more seamless way; Chat with Doctor, which allows users to consult with over 20,000 licensed physicians via chat, video or voice call; and Health Store features that allow users to purchase medicines, supplements and various health products from our network of over 4,900 trusted partner pharmacies. To deliver holistic health solutions in a fully digital way, Halodoc offers Digital Clinic services including Haloskin, a trusted dermatology care platform guided by experienced dermatologists.
We are proud to be trusted by global and regional investors, including the Bill & Melinda Gates Foundation, Singtel, UOB Ventures, Allianz, GoJek, Astra, Temasek, and many more. With over USD 100 million raised to date, including our recent Series D, our team is committed to building the best personalized healthcare solutions — and we remain steadfast in our journey to simplify healthcare for all Indonesians.


